
工业防危系统中规则引擎的设计及优化
2015-07-18 13:36刘健房志奇康卫
物联网技术 2015年5期
刘健++房志奇++康卫

摘 要:规则引擎是业务规则管理系统的核心环节,它通过模式匹配器实现事实库与规则库的快速匹配,因此,一个准确高效的模式匹配器决定了这个规则引擎的整体性能。将规则引擎应用在工业防危系统中,同时利用位图矩阵算法对规则引擎的模式匹配器进行优化,从而使得规则引擎准确高效的工作。实验结果表明在相同条件下,位图矩阵算法相对于直接匹配的方法效率平均提高了88.04%。
关键词:工业防危系统;规则引擎;模式匹配器;位图矩阵
中图分类号:TP393 文献标识码:A 文章编号:2095-1302(2015)05-00-03
0 引 言
随着工业化水平的不断提高,控制技术难度逐渐增加,工业生产系统变得越来越复杂,一旦发生工业生产安全事故,将会造成极其严重的后果。因此,近年来工业生产过程中的安全问题受到了广泛关注。为了降低企业生产过程中的安全隐患,减少企业安全事故的发生,防危系统被应用在电力、水利、核工业、石化、冶炼等领域。
目前大多数学术和工业都是针对如何提高规则引擎的匹配效率进行研究。Rete算法是一种用于产生式系统的高效模式匹配算法,通过在内存中建立一个Rete网络,以空间换取时间,充分共享匹配结果,从而实现高效匹配[1]。Drools是采用JAVA实现的一种基于Rete算法的面向对象的规则引擎,同时利用XML的Conditons→Consequence节点表达If-Then句式[2]。在本文的研究中也是采用XML文件来存储If-Then形式的专家规则。庞伟正等人[3]在Rete算法、Rete-OO算法的基础上提出了一种改进的 Rete网络结构, 并对运用此 Rete 网络来执行推理任务的过程进行了优化,明显提高了匹配效率。
本文将规则引擎应用在工业防危系统(例如,石灰石锻烧系统)中,它的工作效率对这个系统的整体性能起到了至关重要的作用。因此,我们的工作重点是优化匹配算法,在保证匹配准确率的前提下,最大限度的提高规则引擎的匹配效率。
1 规则引擎介绍
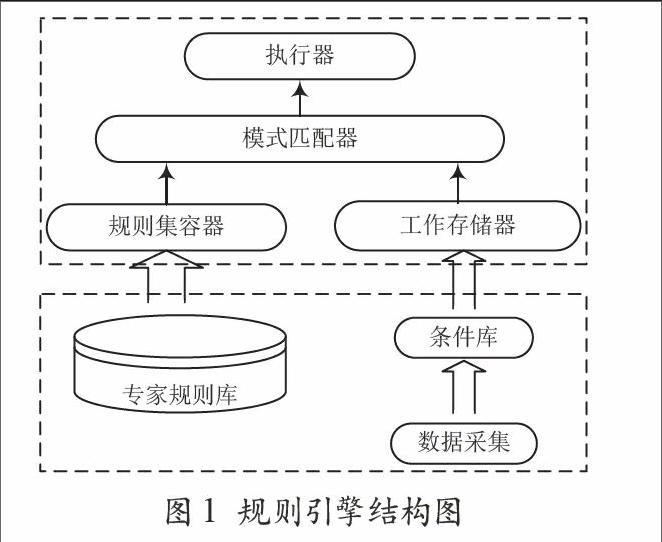
规则引擎的主要功能是实现事实库与规则集的匹配,然后执行那些由当前数据对象激活的专家规则。规则引擎的结构图如图1所示。它主要包括规则集容器、工作存储器、模式匹配器和执行器[4]。数据采集模块能够得到对象的数据值,根据数据值通过条件库模块获得对象所对应的状态,将“对象→状态”加载到工作存储器。
图1 规则引擎结构图
2 规则引擎功能模块
由于匹配器的性能决定着规则引擎的整体性能,我们的研究主要是针对匹配器性能的优化,因此需要详细介绍匹配器的设计原理、工作模式等。
2.1 工作存储器
工作存储器存储当前系统中的事实库,每条事实由对象名和状态构成,每条事实能够为模式匹配器提供匹配条件。同时,工作存储由条件库模块以及数据采集模块支撑。如图2所示,为了简单处理,在我们仿真系统中共设置a-f 6个对象,它们分为开关量和模拟量:如果是开关量,那么采集的数值只有0(关闭)和1(开启);如果是模拟量,它们的值分布在0~800之间,如果超过这个范围系统会给出警告。然后把对象名和数据传给条件库模块进行匹配,系统中条件库模块总共分为9个区域,分别对应低危险、低临界、低警告、正常、高警告、高临界、高危险、关闭和开启,并且每个区域都有自己对应的取值区间。
2.2 规则集容器
在程序运行的开始首先需要解析XML文件,将解析出来的规则加载到内存中的规则集容器中。另外,在专家规则制定时,需要处理冗余、冲突等错误,然后将化简后的最终结果存储到XML文件中。因此,在规则引擎匹配得到要执行的规则结论时,一般规则引擎需要处理可能存在的冲突问题,而在系统中是将这些处理放在了专家规则库的制定过程中,所以得到的规则结论都是最简的且不存在冲突等问题的,当然要考虑规则结论执行的优先级问题。
图2 工作存储器结构
2.3 模式匹配器
模式匹配器是规则引擎中的核心组件,它联系着工作存储器和规则集容器,完成事实条件在规则集容器中的匹配工作,同时将匹配成功的规则结论传送给执行器,供其完成相应的操作。
在我们的规则引擎系统中实现了三种匹配算法,位图矩阵匹配,二阶矩阵匹配,直接匹配。
如表1所示,给出了规则集示例,各个条件之间都是并且的关系,用&&表示,那么就会有If(a低危险 && b开启 && c高临界 && f高危险),Then 结论A。
表1 规则集示例
结论 条件
a b c d e f
A 低危险 开启 高临界 无关 无关 高危险
B 无关 关闭 低警告 无关 正常 无关
C 低警告 无关 低临界 高临界 无关 正常
2.3.1 直接匹配
在规则库的制定过程中,会用&&对规则条件部分进行切分,例如规则1可以切分成“a低危险”,“b开启”,“c高临界”,“无关”“无关”,“f高危险”,然后存储到XML文件中。在直接匹配过程中,规则引擎首先会将XML文件之前保存的这些切分元素加载到二维数组中,然后从工作存储器中得到采集点a,b,c,d,e,f 所对应的状态,将这些采集点对应的状态与这个二维数组依次比对,并将匹配成功的规则结论返回给执行器。在直接匹配算法中采用的是字符串间的直接比较,由于某些规则与采集点无关,所以在比较每个采集点时,首先判断规则与这个采集点是不是无关,然后再判断两者之间的关系。因此,如果规则集中有规则N条,那么总共的比较次数是12*N次。
如表2所示,为了形成规则集矩阵,需要对规则条件做一下转换。表的第一行对应的是状态,第二行是各个状态所对应的数值。那么表1中的规则集就可以转换成表3所示的二阶矩阵。在规则库制定过程中,将这个二阶矩阵存储到XML文件中。
表2 规则条件转换
状
态 关
闭 开
启 低
危
险 低
临
界 低
警
告 正
常 高
警
告 高
临
界 高
危
险 无
关
转换 0 1 2 3 4 5 6 7 8 9
表3 规则集矩阵
结论 条件
a b c d e f
A 2 1 7 9 9 8
B 9 0 4 9 5 9
C 4 9 3 7 9 5
2.3.2 二阶矩阵匹配
规则引擎首先从XML文件中将这个二阶矩阵加载到一个二维数组中,然后从事实库中调出采集点a,b,c,d,e,f所对应的状态,并根据表2将各个状态转换成对应数值,与二阶矩阵数组进行比较。直接比较采用的是字符串间的比较,每次要比较的字节数较多,而二阶矩阵是字符间的比较,每次只比较一个字节,比较的字节数要少很多。同样,如果规则集中有规则N条,那么二阶矩阵总的比较次数也是12*N。
将表3转换成位图矩阵,如表4所示。表4的左栏对应0~8九个状态,然后分别用这些状态与表3中的值进行比对,遇到相同值或者9那么对应的结果都为1,否则为0。例如,状态0与表3中的a所对应的值(2,9,4)进行比对,那么结果就应该是(0,1,0);与b所对应的值(1,0,9)进行比对,那么结果就是(1,1,0)。同样,在规则库的制定过程中,就将这些值依次存储到XML文件对应的节点上。
表4 位图矩阵
状态 条件
a b c d e f
0 010 110 000 011 101 010
1 010 101 000 011 101 010
2 011 100 000 011 101 010
3 010 100 100 011 101 010
4 110 100 010 011 101 010
5 010 100 000 011 111 110
6 010 100 000 011 101 010
7 010 100 001 111 101 010
8 010 100 000 011 101 011
在位图矩阵匹配过程中,首先将这个位图矩阵加载到一个字符型三维数组中,再从事实库中获取各个采集点所对应的状态数值,然后进行与运算。值得注意的是,三维数组中只要有一个是0,那么就不需要再往下比对了,运算的最后结果确定是0。例如,事实库中a,b,c,d,e,f所对应的状态向量为(0,0,4,3,5,2),对应的位图矩阵中的数值是V0:[0][1][0],V1: [1][1][0],V2:[0][1][0],V3:[0][1][1],V4:[1][1][1],V5:[0][1][0]。我们按照字节从低到高依次比较,由于V0的第一个字节为0,那么就不需要再往下比对了,结果的低位肯定是0,因此节省了比对时间。同理,第二字节结果为1,由于V0的第三个高字节也为0,则结果就是0。因此最后的比对结果是[0][1][0],第一个字节位对应结论A,第二个字节位对应结论B,第三个字节位对应结论C,只有结果不为0才能激活对应结论。因此,根据与运算结果,只能够激活B结论,并将其返回。
2.4 执行器
执行器能够执行匹配器返回的匹配成功的规则结论,并将执行结果返回给主程序,以便其采取相应操作。
3 实 验
3.1 实验环境介绍
这个规则引擎是在Ubuntu 12.04系统下用Qt语言编写的,规则库采用XML文件进行存储。在联想电脑上完成测试,电脑的CPU是 Intel? Core? 双核,主频是2.00 GHz,内存RAM是2 GB。
3.2 实验结果分析
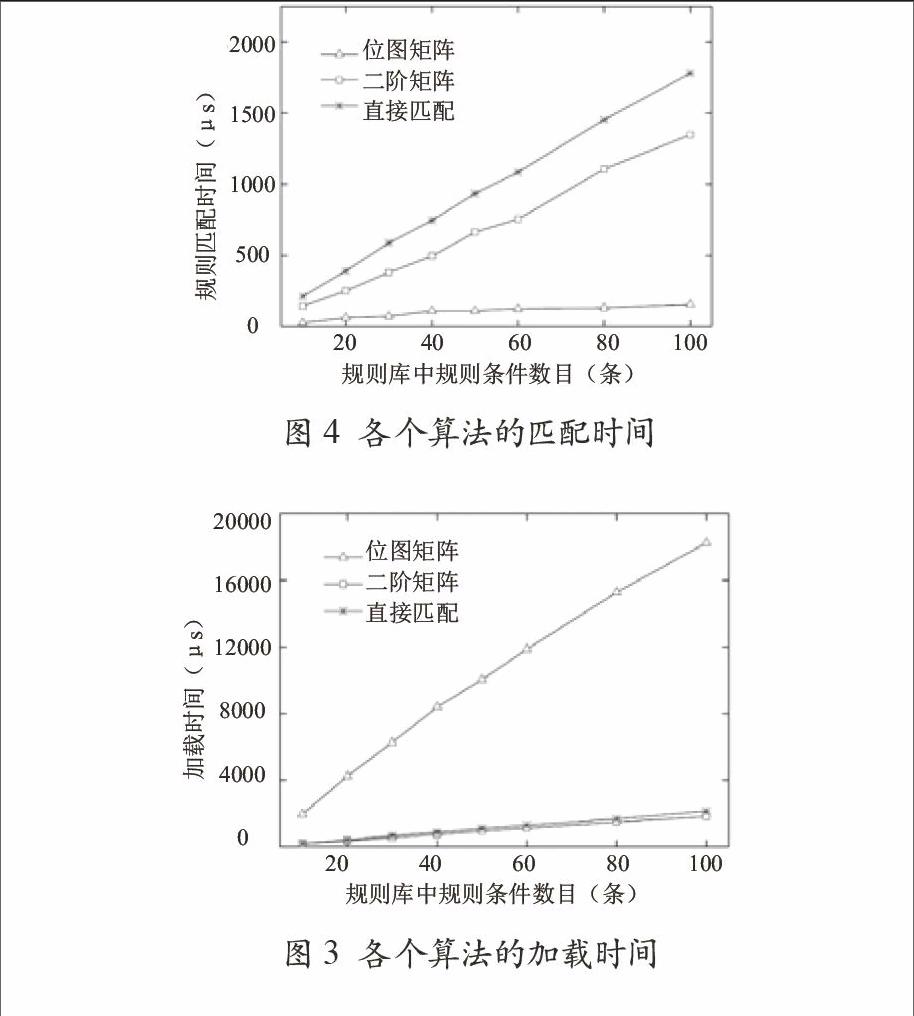
从图3中可以看出,随着规则条数的增加,加载时间基本呈线性增长,位图矩阵加载时间最长,二阶矩阵加载时间相对最短。但是,规则加载只是在程序最开始一次完成,在正常的后续运行过程中就不需要再加载。
图3 各个算法的加载时间
图4显示出在不同规则集大小的情况下,三种算法完成匹配所需的时间。在每个规则集下,三种算法都测试10次,然后取平均值,这样能够降低系统误差。从图4可以看出,随着规则集的增大,匹配时间呈线性增加,但是相对于另外两种算法,位图矩阵算法的匹配时间增长非常缓慢,直接匹配的方法增加最快。
图4 各个算法的匹配时间
综上所述,我们可以得出以下结论:
(1)规则加载时间随着规则条数呈线性增长,但是位图矩阵匹配时间增加相对缓慢;
(2)根据图4计算得出位图矩阵相对于直接匹配算法,匹配时间平均提高了88.03%。
4 结 语
本文针对工业防危系统设计实现了一套规则引擎系统,同时有针对性的对规则引擎关键环节——模式匹配器进行了优化,使得系统整体性能得到有效提高。
参考文献
[1] Charles L. Forgy. Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem[J]. Artificial Intelligence ,1982.
[2] PET ER L. Drools Usage Manual [ EB/ OL ]. http: / / drools.org / drools- manual- 2. 0 - beta - 13. pdf, 2004- 01-05.
[3]庞伟正, 金瑞琪, 王成武.一种规则引擎的实现方法[J].哈尔滨工程大学学报,2005,26(3):385-389.
[4]彭磊.规则引擎原理分析[J].福建电脑,2006(9):42-43.
