
企业微博粉丝的特征挖掘——以天猫腾讯微博为例
2015-07-12 07:51唐晓波
信息资源管理学报 2015年3期
唐晓波 邱 鑫
(1.武汉大学信息资源研究中心,武汉,430072; 2.武汉大学信息管理学院,武汉,430072)
1 引言
1.1 研究背景与意义
伴随着微博的走俏,越来越多的企业陆续在微博中开辟官方账号。在国际上,Twitter专门开设了“品牌频道”,企业可以在该栏目中构建品牌页面,向用户发送各种促销和活动信息,实现企业的品牌推广。国内企业微博的发展也十分迅速。2009年10月,欧莱雅开通新浪官方微博;2010年3月,戴尔官方微博“@戴尔中国”在新浪正式启动。除此之外,用友软件集团、凡客诚品、长安福特、中国移动、中国电信、柒牌服饰等品牌通过自营或外包的方式运营企业微博[1]。另一方面,微博用户对企业官方微博的关注度越来越高。《2012中国微博蓝皮书》指出,有八成以上的微博用户关注了企业官方微博,平均关注7.96个。关注产品类别官微的微博用户,对微博平台上的电子商务信息更为主动和积极,有60.74%的用户会到电商网站进一步了解和行动;直接点击微博上的产品信息的用户也接近6成;56.16%的用户会进入到相关产品/品牌的官方网站[2]。
企业微博对目标群体越有价值,对其掌控力也就越强[3]。一个包含过多垃圾信息的微博,不仅达不到吸引粉丝的作用,还有可能被既有粉丝取消关注。然而不同的群体,对信息的需求可能不同,同样一条微博信息,对一些粉丝而言是有价值的信息,而另一些粉丝可能视其为无用的垃圾信息。通过对用户特征进行分析,企业可以更好地理解用户,发现用户的行为规律。基于这些理解和规律,企业微博博主可以制定相应的策略,进而有效利用微博进行产品推广和培养用户忠诚度。本文以天猫腾讯微博为例,主要探讨三个问题:①什么样的用户更倾向于关注企业微博;②不同社会信息的群体的偏好是否不同;③不同社会信息的群体倾向于关注哪些方面的微博。
1.2 研究现状
国内对企业微博的研究主要集中在企业微博营销、消费特征、广告策略、影响力、公关、内容、应用等方面。林锦国等研究了企业官方微博的帐号特征和行为特征,考察了用户的响应行为和信息传播规律,建立了影响力扩散回归模型[4];胡婷婷将传播学和消费社会理论相结合,对企业微博消费特征进行初步探究[5];王荟博等分析并论证了微博广告价值维度对顾客购买意愿的影响[6];郝晓玲等运用主成分分析法归纳了5种企业微博的主要影响因子[7];王丽敏等研究分析了企业微博公关的现状、存在的不足,并重点论述了企业微博公关的发展策略[8];张娜娜研究了企业微博用户发布微博的行为特征以及微博内容形式与内容分类的特征[9];黄晓斌等分析了微博客特点,探讨了微博客在企业竞争情报中的应用[10]。而国外的研究主要集中在企业微博的知识共享、企业微博的价值探讨、使用微博的意愿研究等方面。Müller等通过案例研究了一个经常使用微博的组织能更快的进行知识共享和改善网络[11];Barnes等对人们持续使用微博的意愿做了调查研究[12];Schöndienst等对企业微博在企业中被采纳的情况进行了研究[13]。
在上述研究中,国内外学者比较关注企业微博本身的营销、传播、价值、影响力等方面,但对于关注企业微博的粉丝特征的研究却很少涉及。本文对企业微博粉丝的人口分布和行为特征进行深度挖掘,探讨其中的规律,增进对企业微博粉丝的深入了解,改进企业微博的内容,促进企业信息的传播。
1.3 研究方法
利用八爪鱼软件在2014年4月抓取和收集天猫腾讯官方微博的粉丝的信息,获取的信息包括“按听众者数排名”的前400名粉丝和“按微博等级排名”的前400名粉丝的基本个人信息和标签信息。其中基本个人信息,即人口分布信息,包括粉丝的生日、地域、行业。标签信息,即行为特征,是粉丝对自己兴趣或特征的标注。
将企业微博粉丝特征分为人口分布特征和行为特征两个方面。使用java代码并结合Excel对获取的信息进行预处理,利用知网中的WordSimilarity合并同义词,数据分析和可视化的工具分别是SPSS、Ucinet。
2 企业微博粉丝的人口分布特征
一方面,存在一些粉丝既在“按听众者数排名”的前400名粉丝中,又在“按微博等级排名”的前400名粉丝中,另一方面,一些粉丝的信息是不完整或无效的,因此需要在所得的800条粉丝信息中去除重复和无用的粉丝信息。将处理后得到的762条有用的粉丝信息,从年龄、地域、行业三个方面挖掘腾讯天猫官方微博粉丝的人口分布特征。
2.1 年龄
粉丝在天猫官方微博中填写自己生日时超过50%的人倾向于显示星座,对注明年份的粉丝进行统计分析,分成“60后”,“70后”,“80后”,“90后”,“00后”五个年龄段,粉丝的年龄统计图如图1所示。不难看出,在年龄分布中,天猫腾讯微博的粉丝里“80后”“90后”占有非常大的比例。由中文互联网数据中心[14]对各大B2C电子商务用户解读的数据表明,现在“80后”是网购的主力军,这在本文中也得到了验证。同时可以看出“90后”是潜在的天猫消费主力。天猫官方微博可以将粉丝主要定位于年轻群体。针对这些“8090后”消费者的特征进行营销,提高天猫官方微博的关注度。
2.2 地域
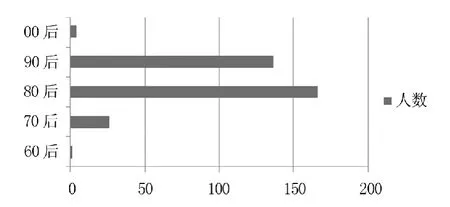
图1 企业微博粉丝的年龄分布图
根据获取的粉丝所在地信息,按照一线、二线、三线、四线城市将企业微博粉丝分类。经统计分析,发现在天猫腾讯微博粉丝的地域分布特征(如图2)。三线城市的粉丝最多,接近粉丝总数的1/3,其次是二线城市。在《淘宝及天猫网购消费者特征及行为分析》[15]的报告中将会员注册lP所在城市划分等级,发现天猫会员均以二、三线城市居多。综上可知,天猫微博粉丝的地域分布与天猫注册会员的地域分布,基本保持一致。另外,在官方微博上,四线城市的粉丝数目也是不容小觑的。因此,天猫官方微博在保持对二线、三线地区粉丝的关注的同时,可以加强对四线城市粉丝的营销力度。

图2 企业微博粉丝的地域分布统计图
2.3 行业
在获取的762个有用粉丝信息中,行业种类包括37种:公务员类、电子通信技术、计算机·网络、金融、经营管理、新闻出版、医疗卫生、市场·公关、个体经营、建筑、酒店、贸易、美术·设计、美容保健、娱乐业、工业生产、务工人员、自由职业者、在校学生等。
通过统计分析,将这些行业按照粉丝从事频次从高到低排列,并选取排名靠前的十名行业进行分析。如图3所示,在天猫微博粉丝中从事计算机·网络的粉丝所占比例最高,其次是在校学生和自由职业者。通过综合比较可知,天猫微博粉丝从事的行业以技术类、学生、服务类为主流。
3 用户社会信息下的行为特征挖掘

图3 企业微博粉丝从事行业的分布统计图
粉丝的标签信息是粉丝对自己的兴趣、特征的标注,是一种对标签的选择行为,因此本文将其定义为粉丝的行为特征。用户的社会信息指的是用户在现实的社会生活中所具有的各种相关信息特征,如性别、年龄、地域、政治面貌、职业等等。用户社会信息相似度指不同用户的社会信息相似的程度;用户之间的社会信息越相似,社会信息相似度就越高[16]。结合企业微博粉丝的年龄、地域、行业等信息对粉丝分类,有利于基于粉丝基础信息的精准营销。
层次聚类[17-18]是生成一系列嵌套的聚类树来完成聚类,它能过滤掉孤立点,识别大小不一的聚类,灵活控制不同层次的聚类粒度,具有较强的聚类能力。本文采用的是层次凝聚聚类算法计算出每个粉丝所属的类,类间距离计算采用的是平均距离法。公式如下:

在聚类过程中,选取相似度值最大的两个簇进行合并,直到所有的簇间的相似度小于阀值0.2,此时将企业微博粉丝按照社会信息分成如图4所示的T1、T2、T3三个较大群体,不同形状表示不同的类。分别对这三个群体进行个性化的行为特征挖掘。
根据图4所示的三个大群体,对应有三个大群体的标签信息TAG1’、TAG2’、TAG3’。分别对这不同社会信息三个大群体的标签信息进行剖析,挖掘不同群体的行为特征,提取有价值的信息,为进行个性化营销提供依据。图5是对企业微博粉丝标签信息进行处理的框架图。
3.1 数据清洗
将获取的标签TAG的文本数据进行预处理,如去除噪音数据、规范化处理等,确保文本集中数据的有效性,以减少无关数据对实验结果造成的干扰。本文从三个方面进行数据清洗:
(1)英语单词的大小写统一,统一为大写;
(2)剔除形容词、乱码词;

图4 企业微博粉丝社会信息的层次聚类

图5 企业微博粉丝标签信息处理过程
(3)存在一些标签词词频不高,但对应有多个同义词,例如:“旅游”、“旅行”、“远足”。为避免这类词被当作低频词滤去,利用知网Hownet中的WordSimilarity计算词语的相似度,合并同义词。
将处理后的规范的标签与T1、T2、T3三个大群体进行映射,构成TAG1’、TAG2’、TAG3’三个基于粉丝群社会信息的标签集。
3.2 特征标签词的提取
标签集TAG1’、TAG2’、TAG3’代表的是三个具有不同社会信息的群体的标签。为了了解不同社会信息的群体的文本属性,分别对三个标签集进行特征词提取:
(1)计算词频
词频(TF)=某词在某一粉丝的标签集中出现次数
考虑到每个粉丝的标签集个数不同,为了便于不同标签集的比较,进行“词频”标准化。

(2)计算逆文档频率

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。log表示对得到的值取对数。
(3)计算TF-lDF
TF-lDF=词频(TF)×逆文档频率(lDF)
通过“词频”(TF)和“逆文档频率”(lDF)计算出每个标签词的TF-lDF的值。某个标签词在群体中的重要性越高,对应TF-lDF值就越大。所以,排在最前面的几个词,就是TAGi’(i=1,2,3)的关键词。本文提取TF-lDF值大于0.5的标签作为群体的特征标签词,分别构成TAG11’、TAG22’、TAG33’三个标签集。按照特征词的TF-lDF值从大到小排名,选取排名靠前的三个群体的部分特征标签词如表1所示。
3.3 标签聚类
为了识别可能存在的一些相关标签组或标签群,需要对标签集合进行统计分析。词共现模型是基于统计方法的自然语言处理研究领域的重要模型之一[19]。若存在几个单词经常在同一窗口单元中共同出现,则它们在一定程度上表示该文本的语义信息。因此,将标签词共现概念与关键词集共同组成的向量来表示文本特征更能反映文本的内容和语义。

表1 不同社会信息的群体特征词
将三个群体的标签表示为TAGi={tagi1,tagi2,……}(i=1,2,3),tagik指TAGi中的第k个标签。TAGi有lD号为1到n的粉丝,tagik可以用n维空间向量表示,tagik=(ui1,ui2,……,uin),如果群体里第k个粉丝标注了tagik标签,就在向量的第k个位置标注1,即uik=1;如果未标注tagik标签,就在向量的第k个位置标注0,即uik=0。这样,每个标签都可以表示成空间向量。tagik的空间向量的维度等于群体Ti中的粉丝数。本文用余弦相似度来计算标签的相似度。
假设存在两个标签tagia=(ui1,ui2,ui3,……),tagib=(ui1’,ui2’,ui3’,……),则tagia和tagib的相似度为:

计算两个标签词的余弦相似度,值越大就表示这两个标签词的相似度越高。如果存在sim(tagia,tagib)的值比较大,则标签tagia与标签tagib的相似度比较高,即(ui1,ui2,ui3,……)与(ui1’,ui2’,ui3’,……)相似度较高。而在同一个群体里,标注这两个标签的是同一个群体,所以当 (ui1,ui2,ui3,……)与 (ui1’,ui2’,ui3’,……)相似度很高时,则表明标注标签tagia的粉丝群与标注标签tagib的粉丝群相似度很高,因此这两个标签被同一个粉丝标注的频次很高,即标签tagia与标签tagib的共现的频次很高。
因此,本文首先用向量tagik=(ui1,ui2,……,uin)分别表示每个群体TAG11’、TAG22’、TAG33’里的标签词,利用SPSS计算在群体内部标签词两两之间的相似度。为了获得标签之间的关系的子集,便于发现粉丝行为特征,利用UClNET中的Subgroup子群分析将三个群体的标签信息进行聚类并可视化,节点表示标签词,节点的大小表示标签词的权重大小,表1中特征词的TF-lDF值即是标签词的权重,表示节点间的关联,关联度是两标签之间的余弦相似度。通过对聚类效果的比较,选取相似度大于0.32的关联比较合适。
通过分析并挖掘TAG11’中的标签词,群体1中企业微博粉丝的行为特征表现在两个方面(如图6),一个是线上活动,围绕着“上网”有音乐、游戏、QQ、唱歌、营销、电影、数码、论坛、微博等;另一个是线下活动,包括旅游、粉丝、苹果、动漫、美剧、书、美食等。对于该群体,企业微博博主可以依据这些标签,个性化地给这类粉丝推荐他们感兴趣的产品。比如在介绍旅游时,可以偏向推荐一些旅游书籍和当地美食。
群体2粉丝的标签信息聚类为5类,可视化结果如图7所示:第1类主要粉丝身份的定位,包括“文艺青年”、“明星”、“新国货”以及各类明星粉丝等;第2类是网购、营销类;第3类偏好电视剧、运动、美食和游戏等休闲活动;第4类倾向于静态的比较宅的活动,有“睡觉”、“上网”、“QQ”、“学习”、“音乐”、“发呆”等;第5类是与文字有关的,有“书”、“小说”、“情感语录”等。根据这五类标签信息,微博博主对群体2的粉丝群提供个性化的信息如明星、游戏、网购、美食、音乐和文字类等,投其所好,为粉丝提供实质的有价值的信息。
同样,群体3的粉丝标签信息聚类为4类,可视化结果如图8所示:第1类是网络休闲娱乐,包括微博、电影、游戏、数码等;第2类是健康养生;第3类与企业相关,涉及到理财、互联网、电子商务等;第4类是生活类,有旅游、美食、运动、粉丝。
3 结论与展望
3.1 研究结论
通过数据分析和文本挖掘,本文从企业微博粉丝人口分布特征和行为特征两方面对企业微博粉丝进行了研究分析。

图6 群体1粉丝的标签聚类可视化图

图7 群体2粉丝的标签聚类可视化图

图8 群体3粉丝的标签聚类可视化图
在人口分布特征方面,主要对天猫微博粉丝的年龄、地域和行业进行研究。企业微博粉丝主要以“80后”、“90后”居多,因此天猫微博粉丝可以定位为“年轻群体”。粉丝中以“80后”为主力军,“90后”则是潜在的消费群体。天猫微博粉丝在三线城市中所占比例最大,其次是二线城市和四线城市,天猫注册会员中以二三线城市为主,与微博粉丝地域分布大体保持一致。此外,因为粉丝中四线城市所占比例也较大,天猫官方微博可以加强对四线城市的营销力度。而关注天猫微博的粉丝从事的行业以技术类、学生和服务类为主流。企业可以依据粉丝不同的的特征,制定个性化的营销策略。
在行为特征方面,主要是依据对粉丝标签信息的挖掘进而分析粉丝群体的特征。按不同的社会信息将企业微博粉丝分成三个群体,发现不同社会信息的群体表现出不同的偏好特征。群体1的标签信息,展现了其行为特征比较明显地分为线上活动和线下活动;群体2的标签信息主要体现其娱乐休闲的行为特征,按兴趣爱好分为追星、网购、户外运动、室内活动和文学类;群体3除了休闲娱乐,偏向于健康养生和企业理财。企业微博博主可以根据不同群体的偏好,有针对性地改进微博内容,使其更贴近潜在消费者的兴趣,提供个性化服务,建立自身用户群体,获取更多的市场份额。
3.2 研究展望
通过对企业微博粉丝群体的特征挖掘,本文从以下两个方面对其进行展望:
(1)挖掘粉丝群体的兴趣。根据用户社会信息将其进行分类,将具有相同背景的人划分为一个群体,进而对该群体进行特征挖掘。不同的消费群体具有不同的消费需求,只有投其所好,提供个性化的产品和服务,才能精准地做到市场地位和满足市场需求,另一方面个性化推荐也可以起到辅助用户决策。利用标签的聚类结果,企业可以智能向粉丝推荐用户感兴趣的标签,挖掘出粉丝最可能喜欢的商品。
(2)倡导官方微博粉丝群体营销理念。因为不同群体存在不同的兴趣点。如果只是盲目地推送热门话题,某个群体的粉丝可能对这个话题并不感兴趣,长此以往,会造成粉丝流失,这对企业而言是巨大的损失。企业可以根据不同的粉丝群体,依据其兴趣点,定制不同的策略,实现精准的个性化营销。
[1]百度百科.企业微博[EB/OL].[2014-05-12].http://baike.baidu.com/view/4611266.htm?fr=aladdin
[2]DCCl互联网数据中心.2012中国微博蓝皮书[EB/OL].[2014-05-12].http://www.dcci.com.cn/media/download/529592d3f496e761b42c2462925f88ec505d.pdf
[3]史光启.微博营销的十大技巧[J].销售与市场(评论版),2011(3):95-97
[4]林锦国,张若冉.企业官方微博特征及营销行为研究[J].情报杂志,2013(9):34-38,56
[5]胡婷婷.企业微博消费特征浅析[J].新闻爱好者,2013(4):64-66
[6]王荟博,戴志敏.微博广告信息与价值维度对顾客购买意愿的影响[J].企业经济,2013(11):94-97
[7]郝晓玲,陈轶杰.企业微博影响力指数研究[J].情报杂志,2013(7):64-68
[8]王丽敏,张汝霞.浅谈企业微博公关现状及发展策略[J].商情,2013(1):187-254
[9]张娜娜.企业微博内容和行为特征实证分析——以“新浪微博”为例[J].中国电子商务,2012(3):43-44
[10]黄晓斌,刘薇,等.微博客的特点及其在企业竞争情报中的应用[J].情报理论与实践,2012(5):1-4
[11]Müller J,Stocker A.Enterprise microblogging for advanced knowledge sharing:The references@BT case study[J].Journal of Universal Computer Science,2011,17(4):532-547
[12]Barnes S,Böhringer M.Modeling use continuance behavior in microblogging services:The case of twitter[J].Journal of Computer lnformation Systems,2011,51(4):1-10
[13]Schöndienst V,Krasnova H,Günther O,et al.Micro-Blogging adoption in the enterprise:An empirical analysis[C]//Proceedings of 10th lnternational Conference on Wirtschaftsinformatik.Zurich,Switzerland,2011:931-940
[14]DinK.如意淘&猎云网:数据解读各大B2C电子商务用户数据[EB/OL].中国互联网数据资讯中心[2014-05-12].http://www.199it.com/archives/109189.html
[15]苏秦.淘宝及天猫网购消费者特征及行为分析[EB/OL].[2014-05-12].http://classroom.eguan.cn/dingwei_147761.html
[16]陈春明,徐义峰.协同过滤算法中一种改进的相似性计算方法[J].桂林电子科技大学学报,2009(3):234-237
[17]Chuang S L,Chien L F.Taxonomy generation for text segments:A practical web-based approach[J].ACM Transactions on lnformation Systems,2005,23(4):363-369
[18]Chuang S L,Chien L F.Towards automatic generation of query taxonomy:A hierarchical query clustering approach[C]//Proceedings of the 2002lEEE lnternational Conference on DataMining,Maebashi City.Japan:lEEE Computer Society Press,2002:75-82
[19]曹恬,周丽,张国煊.一种基于词共现的文本相似度计算 [J].计算机工程与科学,2007(3):52-53,73
[20]阮一峰.TF-lDF与余弦相似性的应用(一):自动提取关键词[OL].[2014-05-10].http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
[21]刘军.整体网分析讲义-UClNET软件应用 (第二届社会网与关系管理研讨会资料)[C]//哈尔滨:哈尔滨工程大学社会学系,2007:87-131
[22]沈浩.第十二周:社会网络分析分析——每周一讲多变量分析[OL].[2014-05-10].http://shenhaolaoshi.blog.sohu.com/148753587.html
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
畅谈(2018年22期)2018-02-01
中国眼镜科技杂志(2017年13期)2017-08-16
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中国品牌(2015年11期)2015-12-01
Coco薇(2015年11期)2015-11-09
