
Hadoop在数据挖掘中的应用研究*
2015-07-12 17:17李校红张秀芳
新技术新工艺 2015年4期
李校红,张秀芳
(西安欧亚学院,陕西 西安710065)
Hadoop在数据挖掘中的应用研究*
李校红,张秀芳
(西安欧亚学院,陕西 西安710065)
随着互联网和计算机技术越来越广泛的应用,数据量也在迅速增长,如何在海量数据中快速挖掘到有价值的信息成为数据挖掘研究的重点。本文分析了Hadoop云计算平台,设计了基于Hadoop的数据分析系统,提出了基于MapReduce的K-均值空间聚类算法。
Hadoop;数据分析系统;K-均值空间聚类算法
随着科学技术和Hadoop技术的不断发展,数据挖掘在大数据处理中的作用越来越重要,在企业数据领域起着十分重要的作用[1]。在Hadoop平台上,通过分布式文件系统(HDFS)实现超大文件的容错和存储,应用MapReduce编程模式实现数据的计算。数据挖掘中应用Hadoop的关键问题是怎样实现传统数据挖掘算法的并行化,通过研究传统的数据挖掘算法并根据算法的自身特点,研究其是否能够实现并行化。如果算法能够实现并行化,根据MapReduce编程模式,可将这种算法移植到Hadoop平台上,并行、高效地完成数据挖掘任务[2-3],实现大量信息的高效处理。
1 Hadoop云计算平台
Hadoop是一个应用软件平台,用来编写和运行处理大规模数据。Hadoop 集群搭建好之后,先通过HDFS将大数据安全、稳定地存储分布到集群中的多台机器内,再利用MapReduce模型对数据集进行处理。和高端服务器相比,在处理大数据时应用集群处理可以降低成本,所以,在数据挖掘中应用Hadoop将有更加宽广的发展前景。
Hadoop的核心设计思想是HDFS和MapReduee。存储式分布式计算的基础是存储,HDFS为分布式计算存储提供底层支持,其具有下述基本特点:1)集群的命名空间是单一的;2)数据具有一致性;3)数据具有冗余性。
MapReduce是一个软件架构,其主要作用是对大规模数据进行并行运算。在进行数据处理时,MapReduce作业会先把输入的数据分割成数据块,这些数据库相互独立,然后以键值对形式将这些数据块输给Map函数进行并行处理,生成中间键值对集合,由MapReduce列表库保存这些集合,并将集合中所有具有相同中间key值的中间value值传递给Reduce函数,Reduce函数接收这些集合,合并value值,产生一个value值集合,最后生成输出数据。
2 基于Hadoop的数据分析系统设计
具有代表性的数据挖掘系统部分模块需要很大的计算量,部分模块不需要较大的计算量,而基于Hadoop的数据分析系统,要充分应用Hadoop的集群特征,对需要巨大计算能力的模块的存储要求和计算进行扩展,扩展到Hadoop集群的各个节点上,然后应用集群的存储和并行计算能力进行相关数据的挖掘。在对系统进行设计时,采用分层设计思想,底层应用Hadoop对大数据量进行存储、处理和分析,在高层可以通过接口实现底层存储和计算能力的调用。结合具有代表性的数据模型和上述基本设计思想,应用分层思想,从上向下,最上层为交互层,每层透明调用下层接口,交互层实现系统和用户之间的交互。从上到下分别为:交互层、业务应用层、数据挖掘平台层、分布式计算层,最底层应用Hadoop实现文件的并行计算和分布式存储功能。各层之间相互独立,互不干扰,可以提高系统的扩展性。系统模型如图1所示。
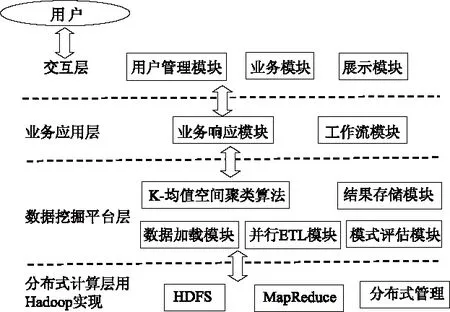
图1 基于Hadoop数据挖掘系统模型
基于Hadoop的数据挖掘系统的流程如下。
1)存储。在基于Hadoop的数据挖掘系统中,文件和数据的存储使用HDFS实现。HDFS的数据吞吐量很高并且容错机制能够很好地实现,能够提供各种操作命令接口和API接口,应用HDFS原始大数据的存储空间更加充足,可存储临时文件,为数据预处理和挖掘过程提供输入数据,同时HDFS中也保存输出数据。
2)计算。该系统中对数据进行计算时应用MapReduce,将数据挖掘系统中的计算任务发布到集群中的各个节点进行并行计算,在计算时应用函数。MapReduce的伸缩性和扩展性良好,可屏蔽分布式计算层,通过提供编程接口快速实现各种算法的并行方式。
3 基于MapReduce的K-均值空间聚类算法
空间聚类分析是聚类分析研究的重要组成部分,其在数据处理中的应用越来越广泛。目前,基于MapReduce的K-Means并行化算法及优化算法已经较为成熟。
由K-Means空间聚类算法的描述可知,其主要计算新的聚类中心和聚类中心与每个样本的空间距离。对于样本和聚类中心空间距离的计算,可以完全独立进行操作,实现并行计算,但计算新的聚类中心是部分独立操作;因此,可以先对部分聚类信息进行计算后再汇总,这样前半部分可以应用MapReduce框架实现并行计算。每次迭代中算法执行的操作相同,因此基于MapReduce的K-均值空间聚类算法的实现只需要在每次迭代中执行相同的Map和Reduce操作即可,其中,为了提高MapReduce并行计算模型的数据处理效率,需先将数据进行预处理,实现数据的按行读取,快速提取有用信息,这些有用数据即为Map函数的输入数据。
基于 MapReduce的 K-均值空间聚类并行算法主要包括2个处理部分:1)将簇类中心点信息文件初始化,并对数据集进行分割,使其成为M块,且大小规格相同,供并行处理;2)产生聚类结果,其实现过程是启动Map和Reduce任务对算法进行并行化计算,算法流程图如图2所示[4-5]。

图2 基于MapReduce的K-均值空间聚类算法并行流程
MapReduce计算过程每次迭代都要重新启动,每次计算过程不止包含1个Map和Reduce任务,每个Map任务都要对数据块信息和当前的聚类中心点信息文件进行读取。Map任务主要是计算各数据对象到簇类中心点之间的距离,然后根据距离最近原则将数据对象分配到距离最近的簇类中;Reduce任务是将各个簇类中的对象进行汇集,并计算寻找新的簇类中心点,对聚类过程进行判断,决定是否应该结束。这里增加了 Comebine任务,其作用是对各簇类的平均值进行分块计算,获得局部结果,再将其传输至Reduce任务,降低节点间的通信负荷。
l)Map函数设计。Map函数的任务是先从需要处理的文件中提取得到数据对象集,文件中每个对象占据1行,以W
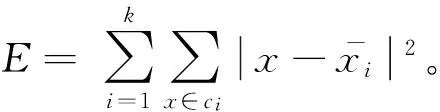
3)根据Reduce函数的输出结果得到新的聚类中心集合,并在HDFS文件系统中进行更新,然后比较本次的聚类中心和上一次执行任务所得聚类中心,如果前后2次聚类中心的变化在预先设定的阈值范围之内,则结束算法,停止迭代,输出最后的聚类结果;相反,以本次的聚类中心覆盖原有的聚类中心文件,参与下一次迭代。启动新一轮的MapReduce Job任务,直到算法满足收敛条件。
4 结语
本文对Hadoop平台的数据挖掘进行了分析,分析了基于Hadoop的数据分析系统,基于MapReduce的K-均值空间聚类算法进行了并行研究,改进该算法后,提高了数据挖掘的效率,尤其在当今数据规模不断增大的情况下,将会取得良好的效果,未来要加强空间聚类分析算法的研究,并拓展其实际应用范围。
[1] 韩隶炜,坎伯.数据挖掘概念与技术[M].北京:机械工业出版社,2008.
[2] 朱珠.基于Hadoop的海量数据处理模型研究和应用[D].北京:北京邮电大学,2008.
[3] 程莹,张云勇,徐雷,等.基于Hadoop及关系型数据库的海量数据分析研究[J].电信科学,2010(11):47-50..
[4] 李应安. 基于 MapReduce 聚类算法的并行化研究[D].广州:中山大学,2010.
[5] 郭鹏勃. 参数设计及CAD相似技术的整合研究[J].新技术新工艺,2014(9):94-96.
*陕西省科技厅资助项目(2013JM8023)
责任编辑李思文
AppliedResearchonDataMiningbasedonHadoop
LI Xiaohong, ZHANG Xiufang
(Xi′an Eurasia University,Xi′an 710065, China)
With the usage of Internet and computer technology more widely, the amount of data is growing rapidly, therefore, how to quickly tap into the vast amounts of data in data mining valuable information becomes focus of the researching fields. The paper analyzed the Hadoop cloud computing platform and designed Hadoop-based data analysis system, finally concluded K-means clustering algorithm space based on MapReduce.
Hadoop, data analysis system , K-means clustering algorithm space
TP 311
:A
李校红(1976-),女,讲师,主要从事网络通信、嵌入式、大数据等方面的研究。
2015-01-12
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
铁道通信信号(2019年5期)2019-10-10
军事运筹与系统工程(2019年4期)2019-09-11
时代金融(2018年15期)2018-08-28
电子制作(2018年11期)2018-08-04
电子技术与软件工程(2017年19期)2017-11-09
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
信息通信技术(2015年6期)2015-12-26
