
基于Lucene全文检索系统的设计与实现*
2015-07-10 01:11周敬才胡华平
计算机工程与科学 2015年2期
周敬才,胡华平,2,岳 虹
(1.61070部队,福建 福州 350003;2.国防科学技术大学计算机学院,湖南 长沙 410073)
1 引言
近年来, 信息技术的快速发展加快了企业信息化的进程, 同时也促进了企业的发展,随着企业信息的大量增加, 电子文档数目也急剧膨胀, 如何在海量信息中快速、准确、全面地查找企业所需的信息资料已成为信息检索研究领域内的一个热门课题。全文检索技术是一种非常高效的信息检索技术,它使人们可以在各种文本中快速检索到所需内容,极大地提高了海量数据检索的效率。
Lucene[1]是Apache软件基金会Jakarta项目组的一个子项目,是一个纯Java编写的开放源代码的全文检索工具[2],程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。近几年,学者对基于Lucene全文检索的应用研究层出不穷,如行业应用[3,4]、图像视频检索[5]、全文检索技术研究[6~13]以及Web应用[14~18]等。文献[6~10]通过改进中文倒排序方法,提升了索引检索效率;文献[11,12]分别在中文分词器方面进行比较和优化,提高了中文分词的准确度;文献[13]研究了Lucene与MySQL在检索性能方面的差异;文献[14]基于.Net、文献[15~18]基于Servlet分别设计实现了Lucene全文检索系统,但这些系统在文档解析类型、中文分词、数据显示等功能上存在一定的不足之处,此外系统在实现上更多是实验测试,没有经过海量数据的实际检验,系统实用性方面略显不够。

Figure 1 Architecture of system图1 系统结构
本文在前述Lucene各项应用研究的基础上,结合轻量级JavaEE应用框架SSH(Spring+Struts+Hibernate),提出了一种基于模型-视图-控制器MVC(Model View Control)分层思想[19]的全文检索模型,能够较好地支持各类通用文档格式的高效解析,有效改进了中文分词算法,提升了中文分词的准确度,增加了检索结果高亮显示的人机交互方式;设计并实现了一套面向海量文本数据的全文检索系统,系统较好地实现了海量文本数据的快速索引和检索,且已经投入实际应用。此外,本文提出基于MVC模式的Web全文检索模型,适合于门户网站以及企业内部海量文本资源的检索,通过简单灵活的二次开发,可以快速集成到C/S和B/S模式的信息系统。
2 系统结构
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
本系统具有建立索引、处理查询返回结果集、增加索引、优化索引结构等全文检索核心功能,外围由结构化数据管理、文件上传下载管理等不同应用功能组成。本系统结构如图1所示。索引引擎、查询引擎、文本分析引擎以及各种外围应用子系统等共同构成了本系统。
本系统包括文件上传模块、文档解析模块、分词模块、索引创建模块、数据检索模块、数据显示模块及文件下载等模块,各模块工作流程如图2所示。
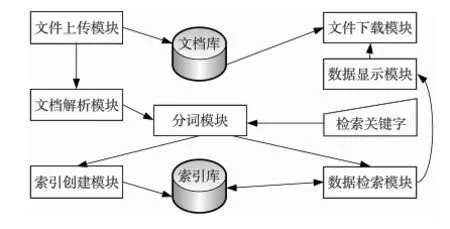
Figure 2 Workflow for each module in system图2 系统各模块工作流程
3 关键技术
3.1 基于MVC模式的Web全文检索模型
MVC已是一种应用广泛的标准设计模式,该模式将软件系统划为三个主要部分,即模型-视图-控制器。本文在基于MVC模式分层思想的基础上,提出了基于MVC模式的Web全文检索模型。如图3所示,该模型在表现层完成文档各类相关数据的显示、查询等功能;业务层完成文档增、删、改、查、上传、下载、全文检索等功能的业务逻辑管理;应用中间层以组件方式提供文件持久化、上传下载以及全文检索核心功能;数据层则实现了结构化数据入库、各类文档以及文件索引的本地化存储。

Figure 3 Full-text search model based on MVC图3 基于MVC模式的Web全文检索模型
3.2 中文分词器的改进
在Lucene 内部提供了几个分词工具,如WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyzer及StandardAnalyzer等分析器。但是,这些分析器中除了StandardAnalyzer具备部分中文分词功能外,其他几个分词器基本都是针对西方文字而开发的。当前应用于Lucene 的中文分词器主要有IK_CAnalyzer、PaodingAnalyzer、MMAnalyzer(JE分词)和CJKAnalyzer。CJKAnalyzer是Apache一个基于Java 语言的开源子项目,是一款针对中日韩语系的分词工具包,该工具包提供了三种分词方法:ChineseAnalyzer、CJKAnalyzer和SmartChineseAnalyzer。SmartChineseAnalyzer中文分词功能支持度相对较强。本文重点比较了SmartChineseAnalyzer、PaodingAnalyzer、MMAnalyzer三种中文分词器,以“全文检索技术设计与实现”为例,测试结果如表1所示。
从表1中可以看到,SmartChineseAnalyzer在性能上稍微优于PaodingAnalyzer,但分词结果后者则更为出色,本系统从分词效果、性能、扩展性以及可维护性来综合考虑,采用PaodingAnalyzer,通过扩展org.apache.lucene.analysis软件包,用庖丁分词器有效改进了中文分词效率与准确度。

Table 1 Comparison for three chinesewords segmentation analyzer
3.3 基于组件技术的多文档解析
Lucene只定义了一个抽象文档的结构Document,没有定义具体的数据源, 因此在各种应用中, 必须采用合适的转换器把数据源转换成相应的Document结构,才能实现文档解析。针对不同的文档格式,需要采用不同的组件或者软件包实现文档的相应解析,比如,利用HTMLParser组件实现对HTML格式的抽取,利用POI组件实现对MS Office文档的抽取,利用Xpdf组件及其中文补丁包实现PDF格式的文本抽取,而针对TXT文件直接使用Java的字符流来读取。本系统使用组件技术,通过抽象出文件解析工厂类,屏蔽了不同格式之间的解析差异,采用抽象接口和动态实例化的方法为用户屏蔽了各种文档格式间的差异性, 使其具有统一处理多种格式文档的能力,实现了对HTML、PDF、MS Office以及TXT等常规文件格式的文本内容透明抽取,文档解析过程如图4所示。

Figure 4 Parsing process for document图4 文档解析过程
3.4 数据显示模块
系统实现了类似Baidu、Google检索结果显示效果,即对关键字相同的词条进行高亮显示。Lucene的org.apache.lucene.search.highlight包中提供了关于高亮显示检索关键字的工具,通过构造的高亮格式对象,生成org.apache.lucene.search.highlight.highlighter实例;然后将检索结果中的文本内容进行切分,找到与检索关键字相同或相似的词条,将高亮格式加入到摘要文本中,返回一个新的、带有格式的摘要文本,在网页上即可呈现高亮显示结果。核心代码如下。
Document doc=hits.doc(i);
String text=doc.get(fieldName);
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("〈font color='red'〉", "〈/font〉");
Highlighter highlighter=new Highlighter(simpleHTMLFormatter,new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(text.length()));
TokenStream tokenStream=analyzer.tokenStream(fieldName,new StringReader(text));
String highLightText=highlighter.getBestFragment(tokenStream, text);
4 实验结果
系统部署环境如图5所示,服务端共部署四台服务器,Web服务器通过Weblogic 9.1提供高性能Web服务,数据库服务器采用Oracle10g对结构化数据进行存储,文件服务器主要将上传的文件集中存储,索引服务器保存上传文件生成的各类索引信息。

Figure 5 Deployment diagram for the system图5 系统部署图
系统当前已存储MS Office、PDF、TXT等各类文本信息达36 GB,索引服务器的CPU型号为Xeon E5-2603 1.8 GHz,内存为12 GB DDR3。以DOC、PDF、TXT三类文档为例,分别针对三类文档测试了100 KB以下、500 KB以下及1 MB以下三个不同大小文档的文本解析速度、索引建立速度与数据检索速度,测试结果如表2所示。测试结果表明,文件类型及大小决定了文本解析与索引建立的速度,但对数据检索速度影响不大,系统在实际应用过程中,基本能够满足用户文件存储及快速检索的需求,具备良好的稳定性与较高的应用价值。

Table 2 Test results
5 结束语
本文在Lucene全文检索框架的基础上,扩展了文档解析功能,对各类常规文档格式具备更好的支持,改进了中文分词器,提高了中文分词效率,设计并实现了一个高效快速的全文检索系统。系统主要需要在两个方面进一步改进,一是进一步改进中文分词器,本系统仅将现有对中文支持较好的庖丁分词器集成到系统中,并未进行二次优化;二是系统在查全率上与其他同类系统没有明显优势,需要进一步改善。目前,该系统已应用到实际业务工作中较好地满足了常规业务需求。
[1] Xu Ye-qiang, Zhu Yan-hui, Li Chun-liang. The design and implementation of massive database full-text retrieval based on Lucene[J]. Journal of Hunan University of Technology, 2011,25(2):81-82.(in Chinese)
[2] Huang Jiang-ping, Huang Li-can, Xu Ling. Implementation of PDF full-text retrieval based on Lucene[J]. Industrial Control Computer,2012,25(5):103. (in Chinese)
[3] Xia Tian, Huang Wen, Ma Jun-tao, et al. Research and application fo Lucene in the academic information service platform construction[J]. Library and Information Service,2011,27(12):88-89. (in Chinese)
[4] Huang Kui, Zhu Xing-dong. The realization of the retrival model based Lucene in IETM[J]. Micro-Computer Information, 2011,55(21):106-109. (in Chinese)
[5] Jiang Xin, Yu Ping. Research and implementation of Lucene-based retrieval system of audio and vedio resources[J]. Computer Applications and Software, 2011,28(11):245-248. (in Chinese)
[6] Zheng Rong-zeng,Lin Shi-ping.Research of Chinese full texts inverted index based on Lucene[J]. Computer Technology and Development, 2010, 20(3):80. (in Chinese)
[7] Tsai Chih-Hao.MMSEG:A word identification system for mandarin Chinese text based on two variants of the maximum matching algorithm[EB/OL].[2000-03-12]. http://technology. chtsai.org/mmseg.
[8] Moffat A, Webber W, Zobel J.Load balancing for term-distributed parallel retrieval[C]∥Proc of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2006:348-355.
[9] Butlerm H, Rutherford J. Distributed Lucene:A distributed free text index for Hadoop[EB/OL].[2012-03-25].http://www.hpl.hp.com/techreports/2008/HPL-2008-64.pdf.
[10] Sajja K. Performance study of Lucene in parallel and distributed environments[D].Boise:Boise State University,2011.
[11] Peng Huan-feng.Design and implementation of Chinese words segmentation machine based on Lucene[J]. Micro-Computer & its Applications, 2011, 30(18):62-64. (in Chinese)
[12] Yi Tian-peng, Chen Qi-an. Comparison research of segmentation performance for Chinese analyzers based on Lucene[J]. Computer Engineering, 2012, 38(22):279-282. (in Chinese)
[13] Wu Dai-wen, Yang Fang-qi. The performance study of database full-text retrieval based on Lucene[J]. Micro-Computer Applications, 2011, 32(6):53-58. (in Chinese)
[14] Tang Tie-bing, Chen Lin, Zhu Wei-hua. Research and implementation of full text retrieval component based on Lucene[J]. Computer Applications and Software, 2010, 27(2):197-199. (in Chinese)
[15] Ding Zhao-gui,Jin Min.Research and implementation of personal search engine based on Lucene[J]. Computer Technology and Development, 2011, 21(2):105-108. (in Chinese)
[16] Zou Yan-fei, Yu Cheng-zun, Zhao Liang. Design and implementation of text search engine based on Lucene[J]. Computer and Modernization, 2011, 193(9):40-42. (in Chinese)
[17] Li Xue-li, Huang Li-can, Fan Chen-xi. Design and implementation of documents management system based on Lucene[J]. Industrial Control Computer, 2012, 25(10):87-88. (in Chinese)
[18] Li Yong-chun, Ding Hua-fu. Research and application of full text search based on Lucene[J]. Computer Technology and Development, 2010, 20(2):12-15. (in Chinese)
[19] Li Hai-feng. Study on application of MVC model architecture[J]. Automation & Instrumentation, 2013,165(1):4. (in Chinese)
[20] The apache software foundation.Apache Lucene-Query Parser Syntax[EB/OL]. [2010-06-18].http://lucene.apache.org/java/2_9_3/queryparsersyntax.html.
附中文参考文献:
[1] 徐叶强,朱艳辉,栗春亮. 基于Lucene的海量数据库全文检索的设计与实现[J].湖南工业大学学报,2011,25(2):81-82.
[2] 黄江平,黄理灿,徐玲. 基于Lucene的PDF文档的全文检索的实现[J].工业控制计算机,2012,25(5):103.
[3] 夏天,黄文,马骏涛,等. Lucene全文检索软件及其在学科信息服务平台中的应用[J]. 图书馆情报工作,2011,55(21):106-109.
[4] 黄葵,朱兴动. 基于Lucene的IETM系统检索器的设计实现[J]. 微计算机信息,2011, 27(12):88-89.
[5] 姜鑫,余平. 基于Lucene的音视频资源检索系统的研究与实现[J].计算机应用与软件,2011, 28(11):245-248.
[6] 郑榕增,林世平. 基于Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010, 20(3):80.
[11] 彭焕峰. 基于Lucene的中文分词器的设计与实现[J]. 微型机与应用,2011, 30(18):62-64.
[12] 义天鹏,陈启安. 基于Lucene的中文分析器分词性能比较研究[J]. 计算机工程,2012, 38(22):279-282.
[13] 吴代文,杨方琦.Lucene在数据库全文检索中的性能研究[J]. 微计算机应用,2011, 32(6):53-58.
[14] 唐铁兵,陈林,祝伟华. 基于Lucene的全文检索构件的研究与实现[J]. 计算机应用与软件,2010, 27(2):197-199.
[15] 丁兆贵,金敏. 基于Lucene的个性化搜索引擎研究与实现[J]. 计算机技术与发展,2011, 21(2):105-108.
[16] 邹燕飞,于成尊,赵亮. 基于Lucene的文本搜索引擎的设计和实现[J]. 计算机与现代化,2011, 193(9):40-42.
[17] 李雪利,黄理灿,范晨熙. 基于Lucene的文档管理系统的设计与实现[J]. 工业控制计算机,2012, 25(10):87-88.
[18] 李永春,丁华福.Lucene 的全文检索的研究与应用[J]. 计算机技术与发展,2010, 20(2):12-15.
[19] 李海峰.MVC模式架构的应用研究[J].自动化与仪器仪表,2013,165(1):4.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
信息安全研究(2016年4期)2016-12-01
现代计算机(2016年27期)2016-10-29
数字技术与应用(2014年12期)2015-05-04
东莞理工学院学报(2014年3期)2014-07-12
