
基于数据挖掘技术的移动通信话务预测模型
2015-07-03 09:43任君明
电信工程技术与标准化 2015年6期
任君明
(中国移动通信集团广东有限公司江门分公司,江门 529000)
随着4G网络的快速发展,移动通信业务的形态、结构和客户行为逐步发生转变,如何基于历史话务数据对未来业务量进行准确预测,并以此指导网络投资规划、建设运营和市场营销,这是目前运营商无线网络规划工作的一个重要研究课题。通过数据挖掘技术,建立科学的预测模型,能为话务预测带来更高的精度,相比传统粗放的曲线拟合、趋势外推等预测方法更精准化,对运营商网络精准规划和市场精确营销具有重要指导意义。
话务预测是依据话务量历史数据和现有信息,建立恰当的数学模型对未来的话务量进行预测。话务预测按时间周期可分为短期、中期和长期预测;按业务类型可分为话音业务话务量预测和数据业务流量预测。话务预测流程包括数据收集、数据预处理、预测模型建立、预测误差分析等步骤。
数据挖掘(Data Mining)是数据库中的知识发现(Knowledge Discover in Database),基于大数据分析挖掘,从海量数据中揭示出隐含的有潜在价值的信息。数据挖掘通过遗传算法、决策树方法、模糊集方法和神经网络方法等,实现关联分析、偏差检测、聚类分析和趋势及行为预测等功能。数据挖掘的基本过程主要有数据筛选、数据预处理、数据挖掘、数据分析与同化等步骤。
本文使用的主要建模工具:一是SPSS Statistics 19.0,用于话务统计数据的预处理,以及回归分析模型、ARIMA时间序列模型的建模和分析;二是MATLAB 7.0,用于BP神经网络模型的建模和分析。
1 话务预测模型
本文选取某市2010~2013年每月晚忙时月均话务量统计数据,通过对2010~2012年话务量进行数据挖掘,分别建立回归分析预测模型、BP神经网络预测模型以及ARIMA时间序列预测模型等3种预测模型,并以2013年的实际话务数据作为测试验证,探析3种模型预测数据与实际话务数据之间的误差。本文采用的主要原始数据如表1所示。

表1 某市2010~2013年月均晚忙时话务量数据表(单位:Erl)
1.1 回归分析预测模型
回归分析预测法是在分析自变量和因变量相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量。
使用SPSS Statistics软件的回归分析模块,对2010年1月至2012年12月的月均忙时话务量数据进行回归分析,从话务量分布图来看,话务数据的变化趋势并非呈线性变化,而是出现多个不同拐点,故选择SPSS的“曲线估计”功能建立非线性回归分析预测模型,将话务量作为因变量,将日期序列作为自变量。通过对比分析,采用指数函数曲线拟合度较高,对2013年1~12月的话务量变化趋势进行预测,得出指数回归分析预测模型:
y=60049.571e0.008x
对回归方程进行相关性检验:回归方程的方差分析表明,F=121.326,显著水平为0.000,相关系数R2为0.771,该模型具有一定的拟合程度。
1.2 BP神经网络预测模型
BP(Back Propagation)神经网络属于多层前馈网络,以误差逆传播算法进行训练,学习和存储“输入-输出”模式映射关系,采用最快速下降法,通过反向传播调整网络权值,使误差最小。BP神经网络模型包含输入层、隐含层和输出层。本研究应用MATLAB编写代码,对BP神经网络预测模型进行建模和仿真。
1.2.1 BP模型核心算法
(1)采用2010、2011年月均话务量为训练集输入数据,2012年月均话务量为训练集输出数据。
(2)使用newff()函数创建BP神经网络,隐含层设置17个神经元,输出层为1个神经元,隐含层的传输函数为tansig,输出层的传输函数为purelin,训练函数为traingdx,使用带有动量项的自适应学习算法,网络的权值学习函数为learngdm。相关核心代码:net=newff(minmax(P),[17,1], {'tansig','purelin'},'traingdx','le arngdm')
(3)调用train()函数进行训练。
(4)将2011、2012年月均话务数据用作测试集。
(5)使用sim()函数对2013年月均话务量进行仿真预测,输出结果。
1.2.2 预测结果分析
通过建立BP神经网络模型并进行仿真预测,在进行201次迭代后,学习精度MSE就达到了0.004 814 2,达到低于0.005的目标,学习速度较快。BP神经网络模型对历史话务数据、预测数据具有较好的拟合度,预测结果与实际值偏差不大,本模型中平均绝对百分误差MAPE为2.99%,控制在5%以下,对于中短期话务预测,该预测模型和预测结果可用。
1.3 ARIMA时间序列预测模型
ARIMA模型为自回归求和移动平均模型(Autoregressive Integrated Moving Average Model),用数学模型描述预测对象随时间产生的数据序列的变化规律和行为,模型考虑季节变动、随机波动、趋势变动和循环变动等综合因素,识别后的模型能通过时间序列过去值以及现在值进行未来值的精确预测。
本研究运用SPSS Statistics建立ARIMA预测模型,应用“时间序列建模器”,设置因变量为“话务量”,选择模型为“ARIMA模型”并考虑“季节”因素,将评估日期设置为2013年12个月,设定预测值变量为“P_预测值”,选择要显示的R方拟合度量和统计量等图表,建立ARIMA模型:ARIMA(0,0,0)(1,1,0)。MAPE为1.71%,对2013年各月份话务量的预测误差如表2所示。ARIMA时间序列预测模型对历史话务数据具有非常好的拟合度,预测结果与实际值误差小,预测精度高,对于中短期话务预测,该预测模型和预测结果可用。
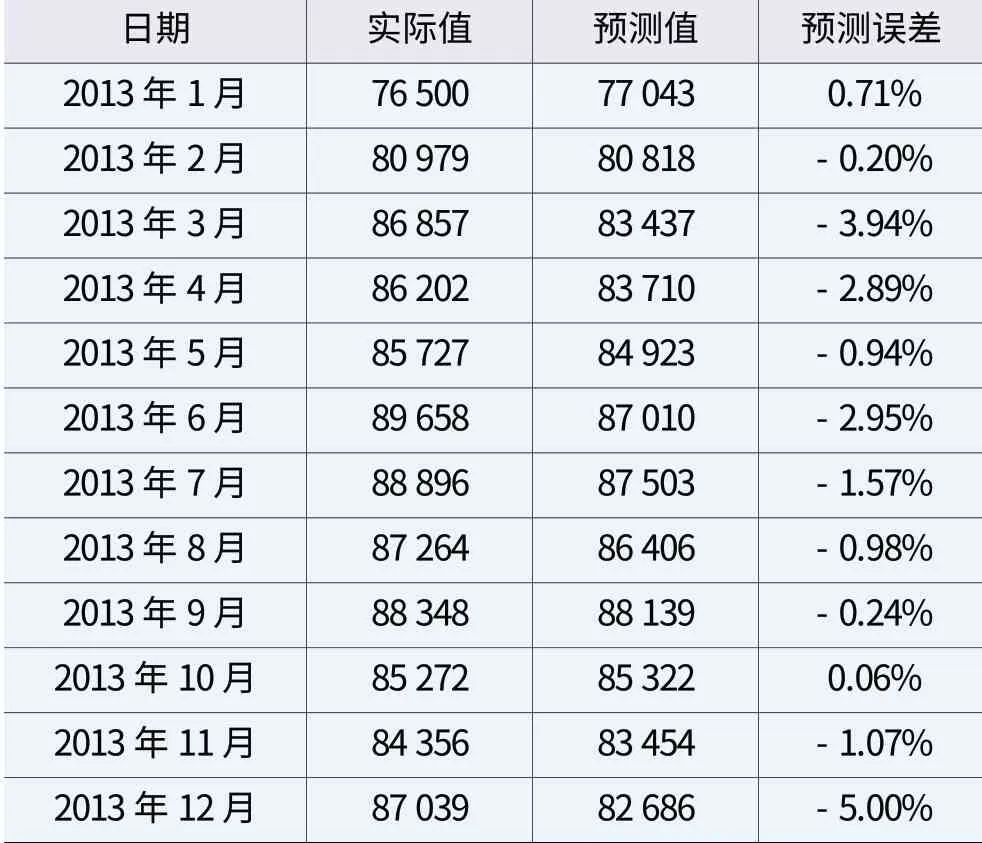
表2 ARIMA模型预测误差对比表
1.4 3种预测模型对比分析
1.4.1 误差对比
3种模型预测值与实际值的对比如图1所示,预测误差MAPE对比如表3所示,由此可见,回归分析模型平均绝对百分误差MAPE最大,达到3.33%;BP神经网络模型预测误差次之,为2.99%;ARIMA时间序列模型预测误差最小,仅为1.71%,ARIMA模型拟合度和预测精度在3种预测模型中最高。
1.4.2 适用场景
在话务量预测精度要求不高的场景,回归分析预测模型方便快捷,但其考虑的因素不够全面细致,虽能一定程度拟合历史数据并对未来数据做出预测,但误差相对较大,不适用于预测精度要求较高的场景。
BP神经网络模型预测精度比回归分析模型高一些,但BP模型也存在不足,对于隐含层神经元数量的设置,需多次对比试验才能确定较合适值,并且传输函数、训练函数及相关参数的选取也需反复试验对比,另外BP模型由于其固有特性,每次仿真运算后的预测结果都不尽相同,增加了研究难度和工作量。
相比之下,ARIMA时间序列预测模型在这3种模型中预测误差最小,对于预测精度要求较高的场景最合适。ARIMA模型对历史数据具有很高的拟合度,特别能精确反映数据变化的拐点和波动,并且模型还考虑了季节等因素,具有很高的预测精度,在移动通信行业话务量预测领域,具有较显著的优势,值得进一步推广应用。
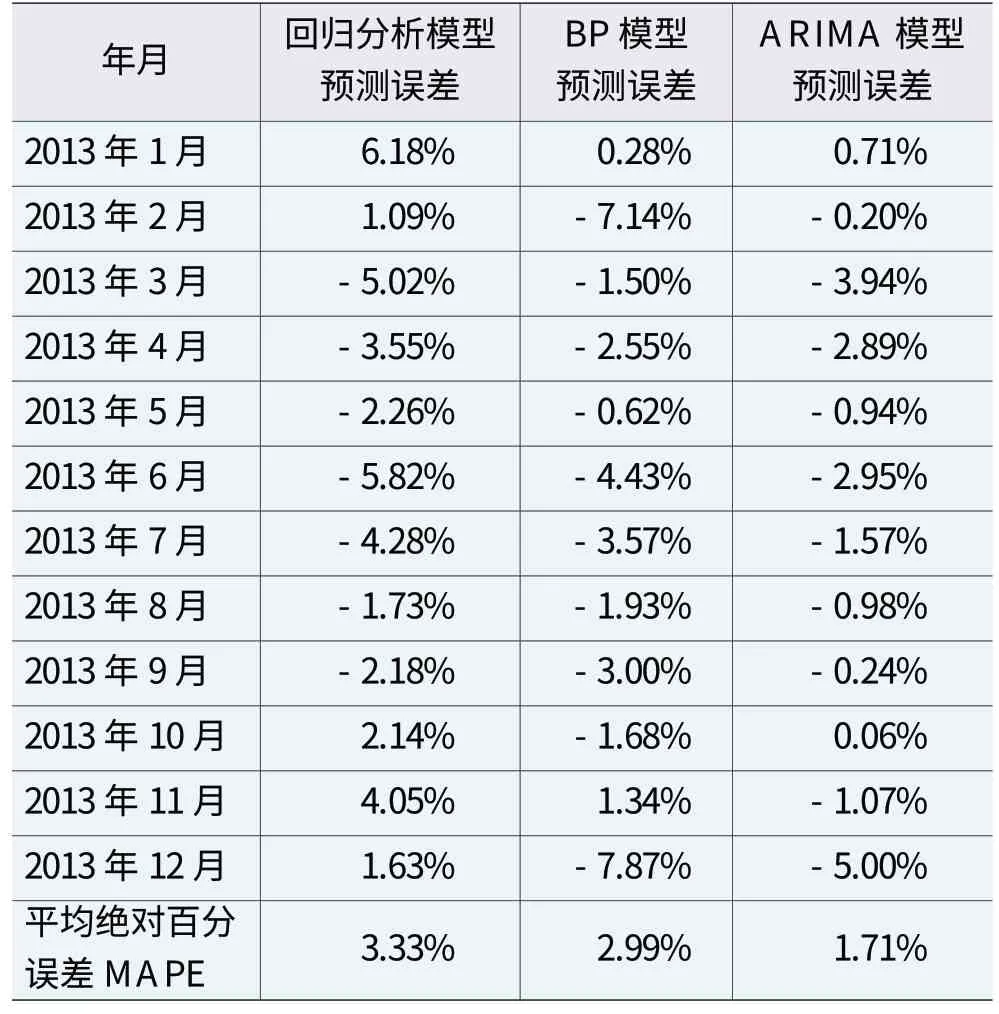
表3 3种模型预测误差MAPE对比表

图1 3种模型预测值与实际值对比图
2 智能话务预测管理平台架构
将话务预测模型实现信息化、自动化,能为话务预测管理工作带来质的飞跃。智能话务预测管理平台面向运营商网络运营、市场运营,以及网络规划、分析和优化人员,提供网络规划管理、话务预测管理和市场营销管理支撑等功能。系统从整体分成3层:数据仓库、业务逻辑层和应用层。基于数据挖掘技术的智能话务预测管理平台系统架构如图2所示。

图2 智能话务预测管理平台系统架构图
3 结语
本文主要结合数据挖掘技术,建立了回归分析预测模型、ARIMA时间序列预测模型和BP神经网络预测模型,通过对比发现ARIMA时间序列模型的平均预测误差最小,预测精度最高,值得运营商在话务预测工作中推广应用。随着移动互联网以及4G业务的不断丰富,话务量已不单单局限于传统话音通话产生的业务量,手机上网等数据业务流量所占比重已日益加大,本研究提出的3种话务预测模型,同样适用于数据业务流量的预测。本文还提出了基于数据挖掘技术的智能话务预测管理平台架构设想,为提升话务预测管理工作的高精度化、自动化、智能化和信息化提供了有价值的参考。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
新商务周刊(2019年24期)2019-12-22
信息技术时代·中旬刊(2019年1期)2019-10-21
中小企业管理与科技(2019年3期)2019-03-07
电力与能源(2017年6期)2017-05-14
湖南邮电职业技术学院学报(2016年1期)2016-10-18
中国交通信息化(2016年11期)2016-06-06
信息通信技术(2015年6期)2015-12-26
移动通信(2014年6期)2014-07-09
智能系统学报(2013年1期)2013-01-28
