
MEF融合HFF的戏剧视频关键情节自动提取
2015-07-02 00:31尚雪莲秦健勇
电视技术 2015年8期
尚雪莲,秦健勇
(新疆工程学院 计算机工程系,新疆 乌鲁木齐 830011)
MEF融合HFF的戏剧视频关键情节自动提取
尚雪莲,秦健勇
(新疆工程学院 计算机工程系,新疆 乌鲁木齐 830011)
为了更好地从戏剧视频提取关键情节,提出了一种基于音乐情感特征(MEF)融合人脸特征(HFF)的自动提取方法。首先,利用基于音频指纹技术的二级音乐情感识别方法进行音频识别,并利用人脸特征进行视频识别;然后,利用音频和视频识别得到的各元素获取关键情节值,从而提取关键情节;最后,提出了一种量化评估方法评估关键情节提取方法的一致性。在四个戏剧视频上的评估实验验证了该方法的有效性及可靠性,相比其他几种较新的提取模型,该方法提取效果更好。
音乐情感特征;人脸特征;视频关键情节;二级音乐情感识别;定量评估
当今大数据时代,如何获取简洁重要的视频和音频信息显得非常重要[1],关键情节的提取是常用手段。然而,由于需要考虑年龄、性别等很多因素,关键情节的提取成了非常具有挑战性的问题[2],因此,找到一种较好的提取视频关键情节的方法显得非常有意义。
针对情感识别,学者们提出了许多方法,例如,文献[3]提出了一种核典型相关分析算法(KCCA)的多特征(multi-fea⁃tures)融合情感识别方法。文献[4]利用情感激励曲线来精确地反应足球比赛的激烈情况也取得不错的效果。文献[5]利用Fisher准则与SVM的分层语音情感识别,文献[6]研究了二维激励-价数平面,文献[7]在此基础上定义了情感曲线,并进行视频情感描述,文献[8]运用面向观众的个性化方法对电影情感内容进行表示。低级的视听特征例如情感向量,特写镜头和声音能量被映射为一个激励值,音频数据的平均节距被映射为价数值[9]。由于视听特征和人类情绪感知之间存在语义差别,因此完全依赖于低级特征的关键情节提取的精确度被限制。其他低级特征例如颜色,情绪相关的中层特征例如大笑和尖叫[10]。心理学和电影学研究发现,人脸在社交中能够传达重要的信息(例如,眼睛注视的方向),而音乐可以激起听众的情感反应[11]。戏剧视频的导演经常通过使用配乐引导观众的情感到达高潮,在一个连续帧序列中的男演员和女演员的出现通常表明了戏剧的巅峰时刻(这个序列越长,情结越强烈)[12]。
本文提出了一种基于音乐情感特征融合人脸特征的关键情节自动提取方法,设计了一种新颖的二级情感识别方法和采用音频指纹技术提高配乐情感识别精确度的方法,此外,还提出了一种新的距离量度方法,可以以定量的方式评估算法对于关键情节提取的性能,实验结果验证了本文方法的有效性及可靠性。
1 音频特征提取
将戏剧视频分为音频信号和视频信号分别进行处理,针对音频信号,系统首先检测配乐的出现,然后采用著名的MIRtoolbox[13]进行配乐的音乐情感识别。
1.1 二级情感识别方法
利用二级情感识别方法[14](见图1)避免了语音信号和环境噪声的干扰,戏剧视频中,语音信号和环境噪声经常与音乐混合在一起,还没有一种音乐情感识别系统可以处理含有噪声的音乐。假设含有所有配乐的唱片被用于戏剧视频中,即当戏剧视频发布后,可获得原始声道,音乐情感识别是对来自唱片中的音乐进行操作,而不是输入的音频信号。由于输入的音频信号可能已被语音信号和环境噪声所污染,而语音信号和环境噪声通常降低情感识别的精确度,因此,情感识别是在纯净的数据上进行操作的。此外,对于给定的唱片,利用音频指纹[13]检测每一个配乐出现和每一个别演奏的特定部分的配乐。
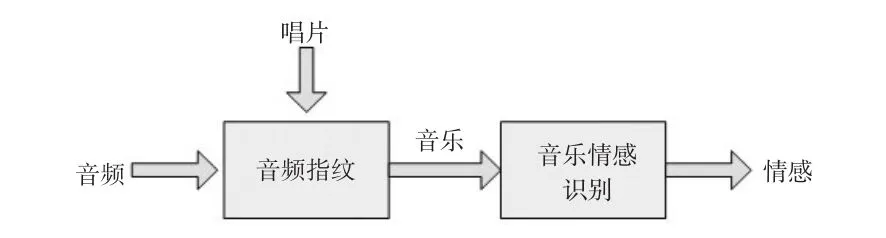
图1 二级音乐情感识别方法
1.2 音频指纹识别
作为一个基于内容的信号,音频指纹已被用于识别音频样本[15]。两个音频分段的相似性由匹配的哈希值个数决定,一个表示输入音频分段,另一个表示配乐唱片的音频分段。根据相似性值判断输入的音频分段是否为音乐,用于这个二值决定的阈值非常重要,因为它决定了音乐检测的精确度。
本文提出了一种适应性技术,利用输入音频分段的低短时能量比ρ可以自动决定阈值。低短时能量比 ρ的计算为

式中:sgn(·)表示符号操作,对于积极的输入,输出1;对于消极的输入,输出-1。eˉ为平均短时能量;N为时窗中帧总数。en表示第n帧的短时能量值。如果音频信号有较高的 ρ值,则拥有更加安静的帧。一般情况下,语音信号拥有比音乐信号更加安静的帧,因此可以利用 ρ值从音乐中区分语音。
根据经验观察,利用 ρ值和匹配的哈希值个数确定自适应阈值,ρ值和其相对应的阈值如表1所示,ρ值范围被平均分成5个范围,指定每个范围内的不同阈值。从表1可以看出,阈值随着 ρ值的增加而增加。本文提出的阈值避免了可能的错误匹配,因此在音乐检测时取得了更加精确的结果。
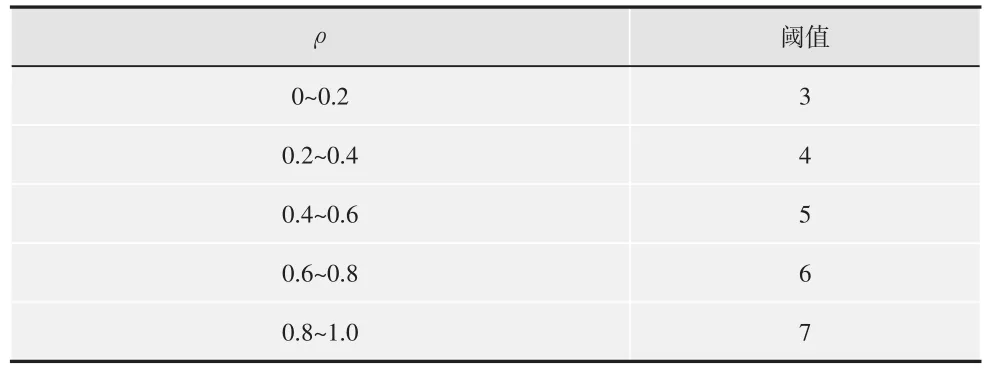
表1 自适应阈值与低短时能量比的关系
1.3 音乐情感识别
利用MIRtoolbox[13]预测音乐分段的情感值,情感值的预期模块数据集由110个电影音乐的音频序列(每一个序列平均被110个人所注释)组成。提取一些音乐特征(音质、协调、韵律等),采用多元回归算法学习音乐特征和情感值之间的关联。利用回归模型训练每一个情感维度。
2 人脸特征提取
文献[16]研究表明,视频中人脸表情通常可以获取观众的注意并激起观众的情感,下文描述了本文系统如何利用人脸作为特征进行戏剧视频的关键情节提取。
2.1 人脸
戏剧视频的关键情节场景通常是人物之间的交流,故人脸的表情是一个用于关键情节提取的重要的候选特征。在视频关键情节的上下文中,人脸尺寸与其重要性关系不大。因此,使用人脸特征进行关键帧提取。图2所示为“没有玫瑰的花店”的关键情节,人脸尺寸却明显不同,故将注意力转移到每帧上显示的人脸数量。

图2 戏剧“没有玫瑰的花店”的两个关键情节帧
每帧的关键情节初值设为帧中检测到的人脸数,如图3所示为人脸关键情节值的计算图解。接着,将每一帧的初始值传播给相邻帧。最后,每一帧的初值与它的相邻帧的初值相加构成最终的初值,由于求和过程实际上是一个短暂的平滑操作,因此该值被称为平滑值。
2.2 特写镜头
将特写镜头当作一个特征用于关键情节提取,研究发现,较短的特写镜头比别的拍摄方式更能唤起观众的情感[5],表明较短的特写镜头通常是戏剧视频关键情节场景的一部分。因此,本文方法在关键情节提取过程中检测短的特写镜头和长的特写镜头。
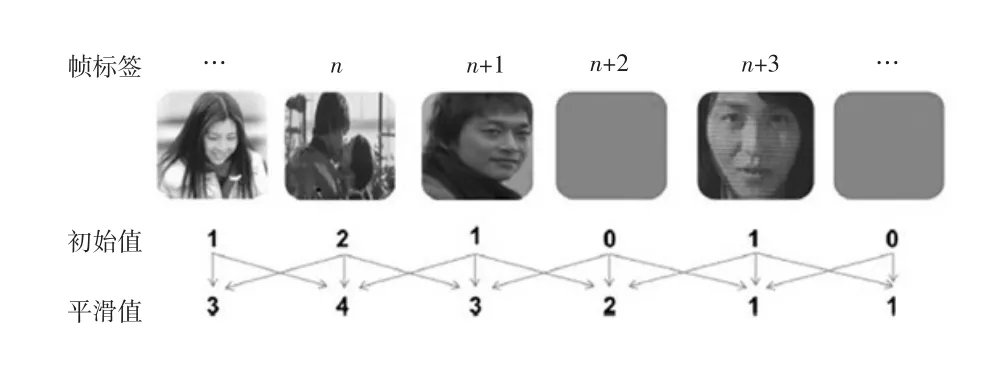
图3 在戏剧“没有玫瑰的花店”上人脸关键情节值计算图解
将镜头强度作为关键情节的候选者,并通过指数函数建模,使用sk表示第k个镜头中一帧的关键情节强度,使用nk-pk表示特写镜头

式中:pk表示第一帧的下标,nk表示第k个镜头的最后一帧。从中可以看到,特写镜头越短,sk的值越大。为了获得面向短时和长时特写镜头都高的值,计算sk到平均关键情节强度的距离,从而获得特写镜头的关键情节值。即第k个镜头中任意帧的关键情节值s^k通过下式获得

2.3 动作强度
动作向量包含强度和方向信息,不同于动作方向,动作强度是关键情节较好的指标之一,与特写镜头类似,戏剧视频中的关键情节场景不一定包含快速动作的帧;含有缓慢动作的帧却可能是关键情节的一部分。因此,在关键情节提取过程中同时考虑含有快速和慢速的动作帧。
含有快速和慢速动作的帧的检测由两个步骤组成。第一步,计算在第k帧中所有图像块的归一化平均动作强度ak。

式中:vk(i)表示第i个图像块的动作向量;I表示所有动作向量的总数;Vk表示帧中最大的动作向量。由此可见,平均动作是归一化的最大的动作向量。
第二步,表示含有快速和慢速动作的帧并且抑制含有平均动作的帧,通过下式计算戏剧视频中第k个帧内的关键情节值。

3 关键情节提取
图4显示了本文提出的系统的流程图。对于给定的戏剧视频,系统分别处理输入的音频和视频信号。系统首先提取视听特征并利用上述方法计算每个特征的关键情节值。然后线性组合戏剧视频的每个第二帧中关键情节值去获得全部的关键情节值,并用H表示。最后,系统提取那些关键情节值大约阈值的视频分段。这个阈值是系统根据关键情节序列的期望值自动生成的。
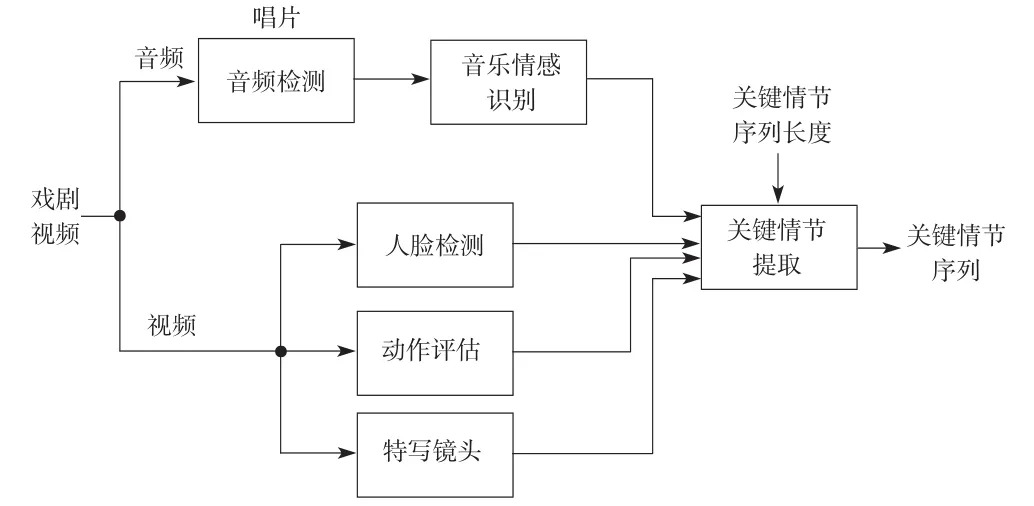
图4 用于戏剧视频的关键情节提取系统
全部的关键情节值是由4个关键情节值权重的和求得。
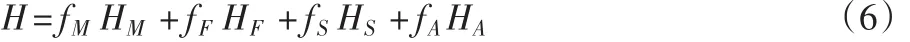
式中:HM,HF,HS和HA分别表示音乐情感、人脸、特写镜头和动作强度的值,而 fM,fF,fS和 fA是其相应的权重值。在本文的系统中,这4个权重都被归一化到[0,1],并且所有权重之和为1。本文实验中,4个权重被简单地设置为[0.3,0.3,0.2,0.2]。
4 关键情节的定性评估
对于相同的戏剧视频,对本文方法生成的关键情节序列和被测试者提供的主观结果的一致性进行了评估。一致性越高,表明系统性能越好。每个被测试者都在看完全部的戏剧视频后才写下他们对于戏剧中关键情节的观点,使用文字描述故事单位级别上的关键情节(例如,“男主角跪下向女主角求婚”)并为每一个关键情节打分。类似地,通过本文系统提取的每一个视频分段的值为视频分段中H的总和。
为了测量一致性,通过下式计算关键情节序列与被测试者给出的文本描述之间的距离D
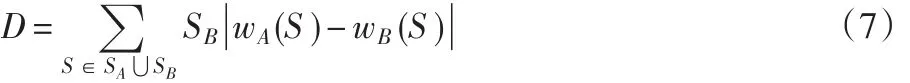
式中:A表示关键情节序列;B表示关键情节的文本描述;SA是序列A中的故事单元的集合。S属于故事单元SA⋃SB,而wA(S)返回序列A中故事单元S的值。如果故事单元S不属于序列A,则wA(S)的值设为0。对于特别的关键情节样式的所有值,无论是视频分段类型的序列,还是文本描述,都将被归一化。D的值在0与2之间,当A和B完全相同时,D的值为0。
5 实验
5.1 数据集
测试数据集包含4个戏剧视频:没有玫瑰的花店(用FS表示)、最后的朋友(LF)、零秒出手(BB)和紧急救命(CB)。4个视频分别描述4个不同的故事:例如,FS是浪漫的戏剧,而CB是医学的戏剧。4个戏剧视频关键情节的文本描述分别从13、13、16和12个被测试者的测试中得到。
5.2 二级音乐情感识别方法的定量评估
为了评估利用二级音乐情感识别方法在关键情节提取上的有效性,将情感识别系统作用于由唱片提供的音乐和输入音频上,产生相应的关键情节序列,计算获得关键情节序列和有被测试者提供的关键情节的距离D,提取性能见图5。
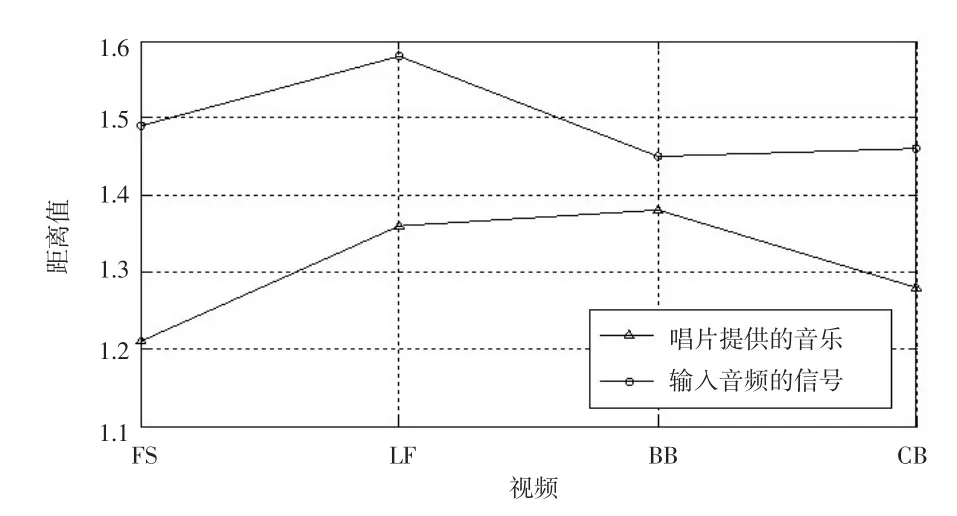
图5 情感识别进行关键情节提取的性能
从图5可以看出,二级音乐情感识别方法通过避免语音信号和环境噪声的干扰有效增强了关键情节提取的精确度,二级方法对于戏剧视频 FS和 LF更加有效。因为这两个戏剧视频中使用的歌曲大多是轻柔的和平静的,轻柔的歌曲通常含有较低的能量,很容易被噪声干扰。因此,在唱片歌曲上运行情感识别可有效增加关键情节提取的精确度。
5.3 综合系统的定量评估
计算关键情节序列和由被测试者给出的关键情节之间的距离D,利用文献[6]提出的基准系统进行视频分段的提取获得了相同的值,因为它们仅仅是对视频的均匀采样。文献[9]的甲骨文系统在使用由被检测者给出的一系列关键情节时提出了更低的距离下界。
图6所示为4个视频上由3种不同方法产生的关键情节与被测试者给出的关键情节的标准距离差异。
从图6可以看出,利用2个特征的系统计算出的距离小于只使用一种特征的系统计算出的距离,即2个特征通过相互补充的方式从戏剧视频中检测关键情节。利用本文方法计算出的距离小于基准系统,即本文方法获取的关键情节序列与由被测试者给出的关键情节结果相比更具持续性。
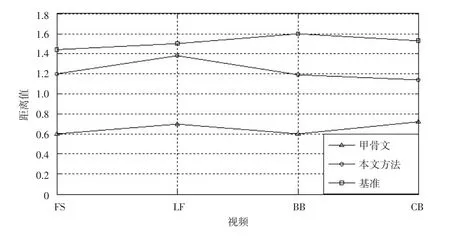
图6 各方法在4个戏剧视频上的性能比较
5.4 几种系统的定性评估比较
文献[5]利用隐条件随机场识别语义的强大功能,和情感激励模型来计算每一个可能的精彩镜头的情感激励值,然后小样本训练建立检测模型,来检测和获取精彩镜头。
本文要求被测试者观看用于第二个测试的关键情节序列,然后给出他们的主观分数,从而评估他们由关键情节序列所激起的感情强烈程度。分数范围设置在1~10之间。分数越高,表明被测试者被激起的感情越强烈。由于观看经验可能影响评估结果,将被测试者划分为2个相等数量的团体。第一个团体的被测试者已观看了完整的戏剧视频,而第二个团体没有观看过。4个戏剧视频分别有30,32,26和28个被测试者,将本文方法的提取结果与文献[5]模型、文献[9]模型、文献[13]模型进行比较,如表2~表5所示。
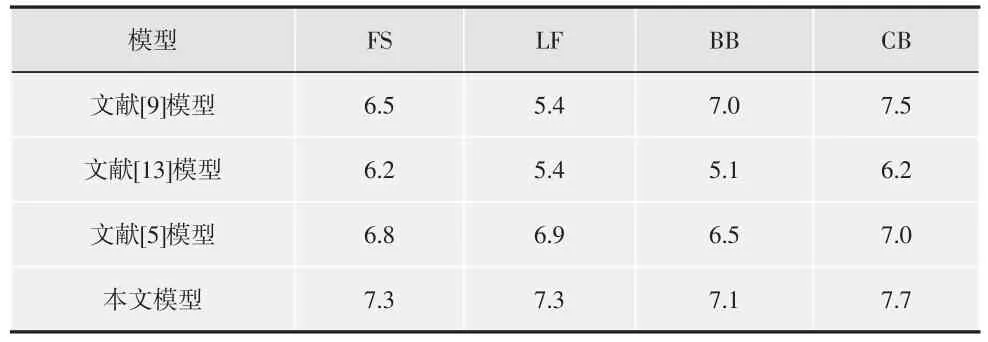
表2 4种系统的性能(单位为1)比较(第一团体)
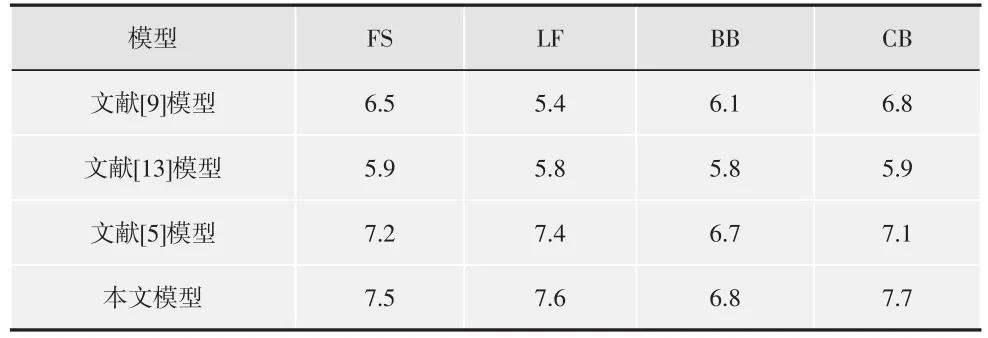
表3 4种系统的性能(单位为1)比较(第二团体)
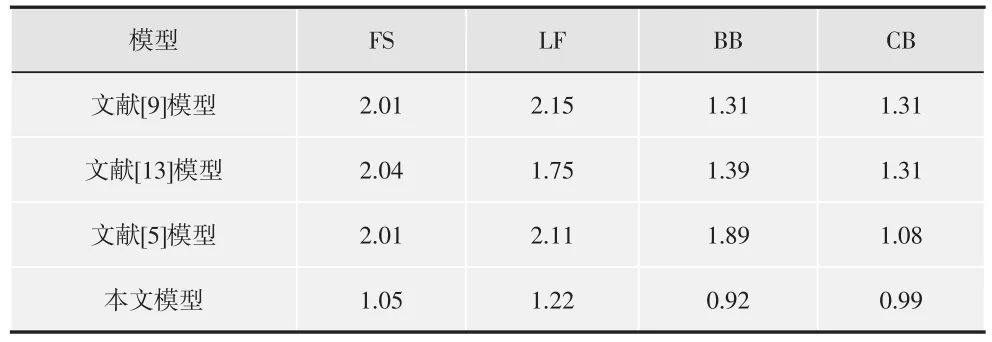
表4 4种系统的平均差异值(第一团体)
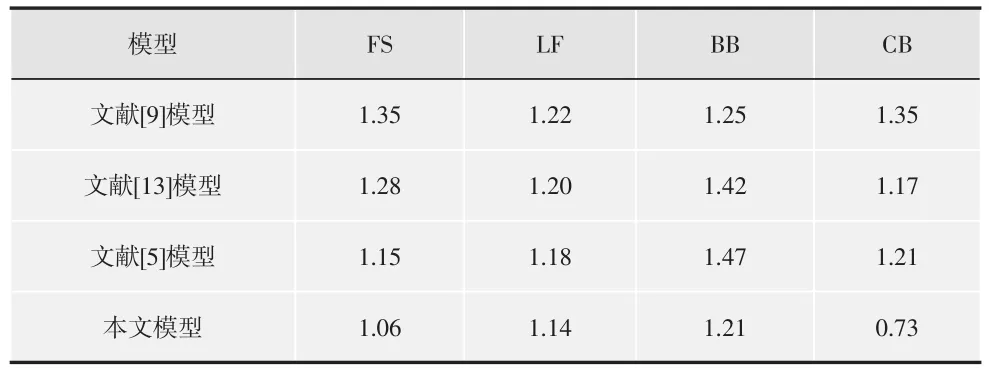
表5 4种系统的平均差异值(第二团体)
从表2~表5可以看出,2个被测试团体的测试结果均能验证本文模型在戏剧视频关键情节提取方面的有效性。表2和表3中的性能比较可以看出,本文系统最能激起被测试者的情感,即相比其他几种模型,本文提取的关键镜头更能让测试者情感发生强列变化。表4和表5表明了本文方法的稳定性和持续性,即本文方法提取的关键情节更能给予测试者长久稳定的情感变化。
此外,本文方法充分考虑了音乐情感特征、人脸特征这两个高级特征和特写镜头、动作强度这两个低级特征,这两个层次的特征具有相辅相成的作用,如在CB(医学戏剧)中,人脸不如在其他戏剧视频中有效,因为医学戏剧中的关键情节场景通常是带着口罩的扮演医生的男主角在进行手术的场景,降低了人脸检测的精确度和人脸在本系统中的有效性。在这4种方法中,文献[5]模型最复杂,考虑隐条件随机场、情感激励值和小样本训练问题,情感激励值明显逊色于本文方法,本文提出的4个元素涵盖了情感表达的所有可能情况,而文献[5]主要针对足球视频的精彩镜头,而忽略了其他情景。
6 结论
为了从戏剧视频提取关键情节,利用音乐情感特征和人脸特征之间的关系来进行关键情节的自动提取,采用一种新的二级情感音乐识别方法进行音频识别,并利用人脸特征进行视频识别,同时结合了特写镜头和动作强度特征,有效提高了音频和视频的识别性能。采用一种定性评估方法对关键情节进行评估,验证了本文方法的有效性,相比其他几种较新的提取方法,本文方法取得了更好的性能。
未来会将本文方法应用于其他的数据集上,改变初始参数设置,进行大量实验,并结合新颖技术,进一步改善关键情节提取性能。
[1] TRIPATHI V,MINU E.An Improved Algorithm(KPCA)For Face Recognition[J].Digital Image Processing,2012,4(1):27-32.
[2] VAN I M H,BAKERMANS-KRANENBURG M J.A sniff of trust:meta-analysis of the effects of intranasal oxytocin adminis⁃tration on face recognition,trust to in-group,and trust to out-group[J].Psychoneuroendocrinology,2012,37(3):438-443.
[3] 刘付民,张治斌,沈记全.核典型相关分析算法的多特征融合情感识别[J].计算机工程与应用,2014,50(9):193-196.
[4] 于俊清,张强,王赠凯,等.利用回放场景和情感激励检测足球视频精彩镜头[J].计算机学报,2014,37(6):1268-1280.
[5]同鸣,丁力伟,姬成龙.融合HCRF和AAM的足球视频精彩事件检测[J].计算机研究与发展,2014,51(1):225-236.
[6] YANG A Y,ZHOU Z,BALASUBRAMANIAN A G,et al.Fast-minimization algorithms for robust face recognition[J].IEEE Trans.Image Processing,2013,22(8):3234-3246.
[7] HANJALIC A,XU L Q.Affective video content representation and modeling[J].IEEE Trans.Multimedia,2005,7(1):143-154.
[8] 孙凯,于俊清.面向观众的个性化电影情感内容表示与识别[J].计算机辅助设计与图形学学报,2010,31(1):136-144.
[9]POTAPOV D,DOUZE M,HARCHAOUI Z,et al.Computer Vi⁃sion-ECCV[M].[S.l.]:Springer International Publishing,2014.
[10] 陈立江,毛峡.基于Fisher准则与SVM的分层语音情感识别[J].模式识别与人工智能,2012,25(4):604-609.
[11] ACAR E.Learning representations for affective video understand⁃ing[C]//Proc.the 21st ACM International Conference on Multi⁃media.[S.l.]:ACM Press,2013:1055-1058.
[12] 李雅倩,李颖杰,李海滨,等.融合全局与局部多样性特征的人脸表情识别[J].光学学报,2014,34(5):115-121.
[13] TIMMERS R,CROOK H.Affective priming in music listening:emotions as a source of musical expectation[J].Music Percep⁃tion:An Interdisciplinary Journal,2014,31(5):470-484.
[14]LARTILLOT O,TOIVIAINEN P,EEROLa T.A matlab toolbox for music information retrieval[M].Berlin:Springer,2008.
[15] HASAN H,ABDUL-KAREEM S.Fingerprint image enhance⁃ment and recognition algorithms:a survey[J].Neural Computing and Applications,2013,23(6):1605-1610.
[16] CHAN C H,TAHIR M A,KITTLER J,et al.Multiscale local phase quantization for robust component-based face recognition using kernel fusion of multiple descriptors[J].IEEE Trans.Pat⁃tern Analysisand Machine Intelligence,2013,35(5):1164-1177.
Automatic Highlights Extraction for Key Plot of Drama Video Based on Fusion of MEF and HFF
SHANG Xuelian,QIN Jianyong
(Department of Computer Engineering,Xinjiang Institute of Engineering,Urumqi830011,China)
Order to extract key plot of the drama videos,an automatic extraction for key plot based on fusion of music emotion features(MEF)and human face features(HFF)is proposed.Firstly,a two music-based emotion recognition method based on audio fingerprinting technology is used to do audio recognition,human face features is used to do video recognition.Then,the elements of audio and video identification are used to get access to key plot value to extract key plot.Finally,a quantitative assessment method is proposed to estimate the consistency of proposed method.The validity and reliability of the assessment has been verified by the quantitative evaluation on the four drama videos method,proposed method has better results than several other new extraction methods.
music emotion features;human face features;key plot;two music-based emotion recognition method; quantitative assessment
TP391
A
10.16280/j.videoe.2015.08.013
尚雪莲(1977—),女,硕士,讲师,主研图形图像处理、视频识别等;
2014-09-09
【本文献信息】尚雪莲,秦健勇.MEF融合HFF的戏剧视频关键情节自动提取[J].电视技术,2015,39(8).
国家自然科学基金项目(61371086);新疆工程学院基金项目(2014030415)
秦健勇(1978—),硕士,讲师,主研图像处理、机器学习等。
责任编辑:闫雯雯
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中国工作犬业(2019年2期)2019-03-06
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
发明与创新·中学生(2017年12期)2017-12-11
电子制作(2017年9期)2017-04-17
校园英语·下旬(2016年5期)2016-06-07
人间(2015年8期)2016-01-09
