
内存网格调度方法分析
2015-06-23 16:25:32卢俊文崔建峰庄蔚蔚谢小竹
厦门理工学院学报 2015年3期
卢俊文,崔建峰,肖 蕾,庄蔚蔚,谢小竹
(厦门理工学院计算机与信息工程学院,福建厦门361024)
内存网格调度方法分析
卢俊文,崔建峰,肖 蕾,庄蔚蔚,谢小竹
(厦门理工学院计算机与信息工程学院,福建厦门361024)
内存网格研究目的是在物理内存不足之时,各个节点之间共享物理内存.在分析内存访问速度、U-disk访问速度、网络带宽的基础上,提出了一种网格内存调度方法及内存管理框架.在某个网格节点内存不足之时,网格节点可以共享各个节点之间的内存,从而提高内存容量.通过分析其他节点内存读取时间、U-disk读取时间、与本地硬盘读取时间的差异,决定是否采用其他网格节点的内存或者U-disk内存.实验表明,提出的内存网格扩展了内存容量,减少了内存替换概率,提高了性能.
内存;内存网格;调度方法;网格数据库;时间延迟
随着应用程序的功能越来越复杂,计算越来越多,不仅对CPU提出了更高的要求,而且对内存的容量也提出了挑战,内存不足经常导致程序无法运行.解决内存不足的最好方法是增加物理内存,但是这种方法有许多弊端,关闭机器,对内存进行更换或增加内存,但是由于计算机内存插槽数量有限,还有一些计算机由于受保修等限制,不允许自行打开机箱.相对这些问题,更难的是内存读取速度与硬盘读取速度之间的差距[1].
相关学者在对内存访问速度,U-disk访问速度,网络带宽分析的基础之上,提出了很多解决方法. IMDB(Memory database system)是一种常驻内存数据库,其将需要访问的数据库存在内存之中,使多个处理器能共享同一个内存,并按智能方法实现共享.文献 [2]等探讨了智能电网中,网格内存的内存分配和回收方法.文献 [3]介绍了一种在集群之中,各个节点之间利用网格内存共享方法,这种方法对内存密集型作业非常有利,但对非内存密集型作业没有太好的表现[4].随着web技术的房展,RAM Server和Net Server被用来在共享多余的物理内存.Windows Vista介绍了一种新的增加内存的方法Windows ReadyBoost,该技术可将用户的可移动存储器当做内存,U-disk提高内存容量,而不需要打开机箱,这种方法主要还是基于机器自身配置进行扩展,并未考虑到附近节点内存供应情况.文献 [5]分析了网格延迟因素,对网格内存的影响.文献 [6]提出了一种基于服务的内存共享框架-DPRG(Distributed paging RAM grid).他在研究大规模内存共享属性和特性的基础之上,设计了优化算法访问网格资源[7],其算法主要集中在内存的读取优化方面进行的.文献 [8]通过分析访问数据的时空本地性,分析了高效的内存管理方法.现有的方法主要缺陷是并没有考虑到内存网格节点之间的连接带宽及网格节点本身可以提供的U-disk扩展.本文在分析网格内存连接带宽、U-disk读取速度等影响因素基础之上,提出一种基于共享物理内存的调度方法,实现各个网格节点多余内存之间的共享,以减少内存访问及替换的次数,增加内存再次访问的概率,提高计算的速度和能力.
1 内存网格的可能性分析
研究发现,硬盘由于旋转速度不同,延迟范围从5~35 ms,而RAM延迟范围在52~255 μs.物理内存的访问速度是硬盘的访问速度数百倍.网络延迟大概数百μs,而对于局域网,速度更快.此外,硬盘及可移动闪存 (U-disk)的访问速度基本差不多.Windows ReadyBoost是一种利用可移动闪存来增加内存容量的方法,把U-disk的空间当作系统内存使用,使用ReadyBoost技术可以使随机磁盘读取性能原则上较传统的硬盘提高80~100倍.因此,设计一个内存网格是可能的.
C.R提出的DPRG[9]包含5种网格节点和2种页面访问服务.网格节点 (available node,busy node,head node,user node和intermediate node)只有一种状态,并且通过页面服务,可以从一种状态变成另外一种状态.页面服务基于OSGA(open grid service architecture)[10],为所有网格节点提供统一的访问接口.实际上,网格节点状态的改变,需要交换数据,可能导致带宽的浪费,而且状态转变难以控制.为解决上述问题,本文提出的内存网格如图1所示.其中,RGD(RAM grid database)负责记录各个网格节点的空闲内存,GRSC(grid RAM scheduling center)负责网格内存的调度工作.当一个网格节点拥有足够多的空闲物理内存,先向RGD注册,然后才能为其他用户提供内存服务;当一个网格节点需要回收内存,GRSC将立即作出相应动作,对分配的内存进行调度,保证回收尽快执行.
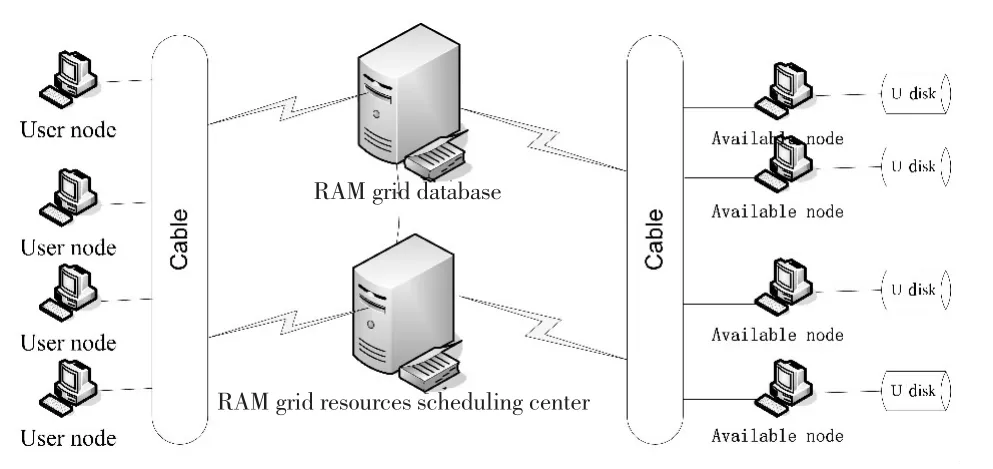
图1 内存网格构架Fig.1 A RAM grid architecture
对于User node及Available node的定义如下:
User node:指自身内存不够,利用其它节点内存的网格节点.
Available node:指自身拥有足够多的内存资源.这些物理内存包括RAM及U-disk.每个节点监控自己的内存利用率,并基于内存供需状况,决定自身内存共享原则.网格节点向RGD汇报自身状况,并拥有不共享自身内存的权限.
2 网格内存共享调度框架
基于上节分析,内存网格能提高网格节点的内存表现.当网格节点需要更多内存,GRSC负责从其他网格节点借调更多内存,满足网格节点需求.内存网格的逻辑视图如图2.

图2 网格内存调度构架Fig.2 Framework of memory scheduIing
对于每个网格节点,LR(local record)记录给其他网格节点提供的内存页面情况.当某个网格节点内存不足时,这个网格节点可能从其他节点获得更多物理内存.如果一个网格节点获得更多物理内存,那么这些被分配的内存就被这个网格节点独占.有时,从其他节点获得物理内存并不是一种好的方法,不能提供网格节点表现.定义一个共享的内存页面范围延迟如下:

Tnett表示网络延迟,Tnetd传输延迟,Disksize表示硬盘容量,Speednet表示网络带宽.在本文,基于局域网的研究[9],Tnett=5 μs,Tnetd=3.0 ms,Disksize=4 kb;Speednet=8 MB/s(1~125 MB/s)
本地硬盘的读取时间为:
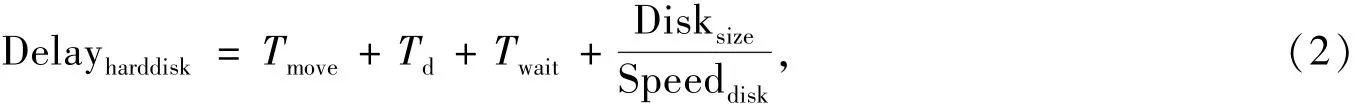
Tmove表示硬盘查找时间,Td表示硬盘转半圈的时间,Twait表示硬盘访问邻数据块的延迟,Disksize表示硬盘块的容量,Speeddisk表示硬盘读取速度.对于典型的硬盘[9],其参数取值如下:Tmove=4.9 ms,Td= 3.0 ms,Speeddisk=80 MB/s,Twait=0.2 ms,Disksize=4 KB.
如果Delaygrid>Delayharddisk,网格节点就不能从其他网格节点内存获得资源.因为此时,其他网格节点的内存,并不能真正提高需要内存的网格节点的表现.
在内存网格之中,需要面对的一个难题是U-disk能自由出入,因此,一些物理内存需要交换数据.内存网格不可能大到能为所有网格节点提供足够多的内存.因此,可以利用内存页面替换策略来替换掉不用的内存页面.常用的替换策略包括FIFO(first-in first-out),LRU(least recently used)和OPT(optimal replacement algorithm).OPT难以实现,因此,在模拟实验中,我们在内存网格中测试FIFO策略.
当一个available node需要物理内存时,它先向GSRC申请,GSRC负责将内存信息迁移到其他available nodes,并在RGD中进行记录.以这种方法,保证本地资源的最高利用权限.为了保持LR和RGD的一致性,当GSRC改变RGD中的记录时,LR也及时更改内存页面记录.
3 结果与分析
假设一个作业需要从一个数组A获得数据,A包含1 000个元素,每个元素A[i]的大小是一个内存页面的大小,假设内存有300个页面,内存替换策略采用FIFO.对于网格内存,如果一个网格节点发现一个需要读或者写的页面不在内存之中,先从LR中查找,如果有记录,那么根据LR从网格内存访问.如果没有足够多的内存空间,用FIFO策略对页面进行替换,并且被替换掉的页面存于内存中,假设每个网格节点提供100,200,300,400,500个页面,我们将比较内存和内存网格在不同方面的表现.
表1显示,内存网格能减少内存访问及替换次数,同时,增加了内存再次访问概率.这表明内存网格不但为网格节点提供物理内存,而且提高了计算能力,因为缺页需要CPU进行管理调度.

表1 内存和内存网格对比1TabIe 1 Difference of RAM and grid RAM(case 1)
第二个模式试验研究网格节点的表现,假设一个网格拥有100,300,700,900内存页面,网格内存提供500个内存页面.页面替换算法采用FIFO.表2显示,物理内存具有关键作用,随物理内存的增加,替换次数明显减少.当物理内存大于需求时,网格内存并没有作用.
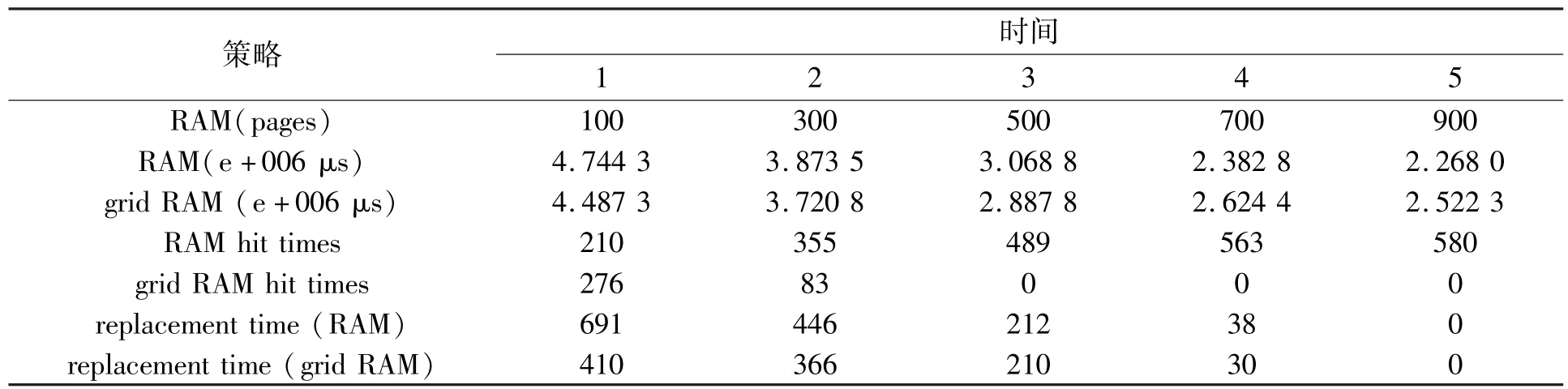
表2 内存和内存网格对比2TabIe 2 Difference of RAM and grid RAM(case 2)
4 结语
本文提出了一种内存网格构架,当内存不足时,网格节点可以共享各个节点之间的内存,从而提高内存容量.内存网格以物理内存及U-disk为调度资源,在所有网格节点之间共享.本文的页面替换策略是FIFO,如果能预测下一个访问页面,能进一步提高网格内存的表现.这将是进一步研究的方向.近年来,内存网格也被一些实际系统所采用,如多通道处警系统[11],磁盘缓存系统[12]等.随着云计算[13]的发展,如何在云节点之间共享内存将是一个待解决的难题.
[1]BURGER D C,HYDER R S,MILLER B P,et al.Paging tradeoffs in distributed-shared-memory multiprocessors[C]// Proceedings of Conference on High Performance Networking and Computing.Washington D C:IEEE,1994:590-599.
[2]LEE S J,SHON T S.Physical memory collection and analysis in smart grid embedded system[J].Mobile Networks and Applications,2014,19(3):382-391.
[3]FEELEY M J,MORGAN W E,PIGHIN F H,et al.Implementing global memory management in a workstation cluster[C]//Proceedings of the fifteenth ACM symposium on Operating systems principles.New York:ACM,1995:201-212.
[4]ACHARYA A,SETIA S.The utility of exploiting idle memory for data-intensive computations[R].Santa Barbara:University of California at Santa Barbara,1998.
[5]HE X F,YANG X Y,LI R,et al.A novel delay-resilient remote memory attestation for smart grid,wireless algorithms,systems,and applications[J].Lecture Notes in Computer Science,2013,7992:88-99.
[6]CHU R,XIAO N,ZHUANG Y,et al.A distributed paging RAM grid system for wide-area memory sharing[C]//Proc of the 20th Int’l Parallel and Distributed Processing Symp.Rhodes Island:IEEE,2006:88.
[7]PATTERSON D A.Latency lags bandwidth[J].Communications of the ACM,2004,47:71-75.
[8]TOCZEK T.Stéphane mancini efficient memory management for uniform and recursive grid traversal,algorithmarchitecture matching for signal and image[J].Lecture Notes in Electrical Engineering,2011,73:27-51.
[9]CHU R,LU X C,XIAO N.A data prefetching algorithm for ram grid[J].Journal of Software(In Chinese),2006,17(11):2 234-2 244.
[10]FOSTER I,KESSELMAN C,NICK J,et al.Grid services for distributed system integration[J].Computer,2002,35(7):37-46.
[11]张卉,张素伟.于内存网格的多通道接处警系统的设计与实现 [J].计算机与现代化,2014(9):111-115.
[12]田甜,褚瑞,谢健聪.基于内存网格的磁盘缓存设计与实现 [J].计算机技术与发展,2011,21(4):1-4.
[13]JAMES A,CHUNG J Y.Business and industry specific cloud:challenges and opportunities[J].Future Generation Computer Systems,2015,48:39-45.
Research on Memory Distributing and Sharing of RAM Grid
LU Jun-wen,CUI Jian-feng,XIAO Lei,ZHUANG Wei-wei,XIE Xiao-zhu
(School of Computer&Information Engineering,Xiamen University of Technology,Xiamen 361024,China)
Based on the analysis of the speed of RAM and U-disk and network widths,we proposed an approach of physical memory sharing of grid nodes and RAM grid managing.Memory can be shared among grid nodes so that their storage capacity is enhanced.Through an analysis of the difference in access time between different grid nodes,the U-disk and the local hard disk,we can decide whether it is efficient to get free physical memory from other grid nodes or U-disk.Simulation test proves that the proposed grid extends RAM,reduces its rate of replacement,and enhances its performance.
memory;RAM grid;sharing;grid database;latency time
TP31
A
1673-4432(2015)03-0075-05
(责任编辑 晓 军)
2015-01-19
2015-06-18
卢俊文 (1981-),男,实验师,硕士,研究方向为嵌入式系统、网格计算.E-mail:jwlu@xmut. edu.cn
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
家庭影院技术(2020年7期)2020-08-24 08:18:10
家庭影院技术(2020年1期)2020-06-24 05:59:20
当代陕西(2019年13期)2019-08-20 03:54:22
西部广播电视(2015年2期)2016-01-15 02:05:40
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
电脑爱好者(2009年13期)2009-07-07 09:52:52
计算机应用文摘(2009年29期)2009-04-29 23:39:10
