
HEVC帧内预测Planar和DC模式算法的并行化设计
2015-06-22 14:39谢晓燕徐卫芳
电视技术 2015年5期
谢晓燕,徐卫芳,刘 帆
(西安邮电大学 计算机学院,陕西 西安 710061)
HEVC帧内预测Planar和DC模式算法的并行化设计
谢晓燕,徐卫芳,刘 帆
(西安邮电大学 计算机学院,陕西 西安 710061)
针对HEVC帧内预测Planar和DC模式算法的特点,提出实现这两种模式的并行化方法。该方法是通过分析推导Planar和DC模式算法之间的可并行性,以西安邮电大学自主设计的一款面向图形、图像应用的阵列处理器PAAG(Polymorphic Array Architecture for Graphics and Image Processing)平台为基础,采用最优的数据分配方式,合理地设计了多处理单元并行工作的算法程序。实验结果表明Planar预测模式和DC预测模式在多处理单元上的并行实现,相比于单核的串行运算速度分别提高了84%和81%,串/并行加速比分别达到6.34和5.44。该并行化算法减少了视频的编解码时间,其数据分配方案对于帧内预测算法在多核结构上的并行化研究也有一定的参考价值。
HEVC;帧内预测;并行化;数据分配;阵列处理器
高效率视频编码(High Efficiency Video Coding,HEVC)是由 ITU-T 和ISO/IEC 联合发布的新一代视频编码标准,它能显著提高视频压缩效率和视频流质量,并支持低带宽的网络,具有良好的网络亲和力。相比较现有的视频标准H.264/AVC,HEVC能够保证在同等视频质量下,减少50%左右的比特率[1]。HEVC标准中的帧内预测被认为是H.264/AVC标准中帧内预测的扩展,预测方法都是基于先前解码后的相邻空域边界样点进行预测。不同的是,H.264/AVC提供的预测模式有9种,而HEVC提供的预测模式多达35种,包括Planar与DC模式两种非方向模式,以及其余33种方向模式[2]。在HEVC标准中采用树状分层结构来表示编码单元大小,编码单元又可以进一步划分为预测单元(Prediction Unit,PU),PU的大小可分为4×4,8×8,16×16,32×32和64×64这5种。除了非定向预测模式中的Planar模式和DC模式会用于每个预测单元PU中,其余33个方向预测模式并不是都会用到[3-5]。所以对于使用频率较高的Planar模式和DC模式进行并行化设计,提高帧内预测的预测时间,对于视频编解码的实时性有着重要的意义。目前对于HEVC的帧内预测的研究主要集中在3个方向:一是对预测模式的判断进行研究,提出各种快速算法[6-9];二是根据帧内预测算法提出相应的结构,加速视频编解码过程[4,10];三是根据宏块划分的结构特点来设计帧内预测的并行化方案[11-13]。而本文通过对帧内预测模式中的两种特殊模式(Planar预测模式和DC预测模式)的算法进行并行化研究,进一步缩短帧内预测所需时间,并且这对于加速帧内预测在多核结构上的进一步并行也有实际意义。
1 Planar模式和DC模式的算法研究
1.1 Planar模式的算法研究
Planar预测模式主要用于图像纹理相对平滑而且有相对渐变过程的区域,其预测方法是使用与当前块待预测像素对应的上、下、左、右4个方向的相邻边界上的像素值作为参考像素值,通过线性插值和求平均计算,得到当前块的预测值。Planar模式预测公式为
predsamples[x,y]=(nS-1-x)×p[-1,y]+(x+1)×
p[nS,-1]+(nS-1-y)×p[x,-1]+(y+1)×
p[-1,nS]+nS)>>(k+1)x,y=0,1,2,…,nS-1,
k=lb(nS)
(1)
式中:predsamples[x,y]为当前块的预测值;nS为当前PU的宽度(注:nS是一个变量名,详见HEVC标准,有时也写成W,都是代表预测块的宽度);x为待测像素的横坐标;y为待测像素的纵坐标;p[nS,-1]为上方参考像素的值;p[1,nS]为右方参考像素的值。
对式(1)拆分合并可推导出
predsamples[x,y]=(nS×p[-1,y]+(x+1)×
(p[nS,-1]-p[-1,y])+nS×p[x,-1]+
(y+1)×(p[-1,nS]-p[x,-1])+nS)/2nSx,
y=0,1,2,…,nS-1
(2)
可将式(2)中nS,x+1,y+1视为加权系数,那么对式(2)求解只需要2步:1)求解中间值p[nS,-1]-p[-1,y]与p[-1,nS]-p[x,-1],如图1所示,最右边列(RightColumn)和最下边行(BottomRow)即为中间值。2)对所得中间像素点值和已知像素点值进行加权。
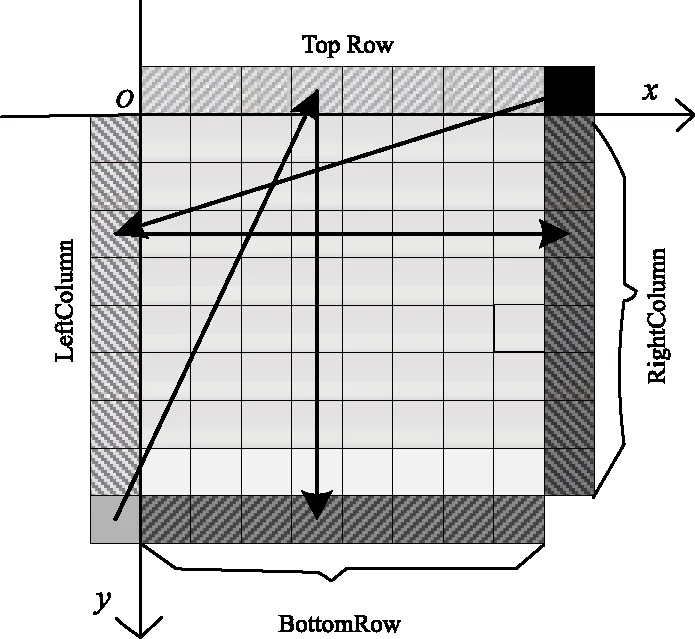
图1 Planar模式的中间值求解
1.2 DC模式的算法研究
相比于Planar预测模式,DC预测模式主要用于图像平坦纹理平滑,且没有太多渐变的区域。预测方式为:首先将当前块上方已解码块的最后一行参考像素与当前块左侧已解码块的最右一列参考像素求均值,作为中间变量dcVal,如式(3)所示

(k+1),k=lb(nTbS)
(3)
式中:nTbS为变换块的大小(nTbS是一个变量名称,不是3个变量,详见HEVC标准);x′,y′分别为像素点的x,y坐标。HEVC标准规定当前块的第一行第一个像素的坐标为[0,0]。然后根据中间变量dcVal分别求出p[0,0],p[x,0],p[0,y]以及p[x,y]
predSamples[0,0]=(p[-1,0]+2×dcVal+p[0,-1]+
2)>>2
(4)
predSamples[x,0]=(p[x,-1]+3×dcVal+2)>>2,
x=1,2,…,nTbS-1
(5)
predSamples[0,y]=(p[-1,y]+3×dcVal+2)>>2,
x=1,2,…,nTbS-1
(6)
predSamples[x,y]=dcVal,x=1,2,…,nTbS-1
(7)
可见,DC模式先预测待预测块的第一行的第一个像素值predSamples[0,0];然后依次预测出待预测块的第一行与第一列像素,即predSamples[x,0]与predSamples[0,y];最后预测出待预测块剩余的所有像素值。求解顺序如图2所示。
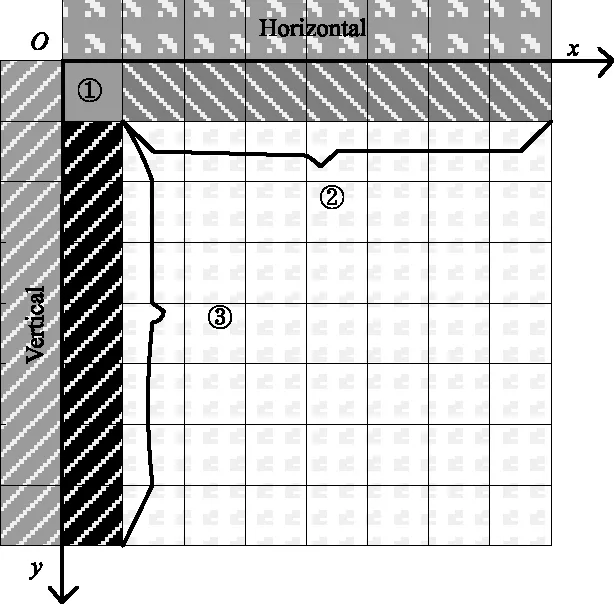
图2 DC模式的求解顺序
2 Planar和DC预测模式的并行化
2.1 PAAG仿真平台
PAAG是面向图形图像处理的轻核阵列机,能够实现高效的线程级、数据级和操作级的并行运算。其体系结构由多个处理器簇组成,每个簇包含16个处理器单元(Processing Elements,PE),这16个处理单元通过近邻互联组成4×4的二维阵列。根据视频算法分析,视频标准中对宏块处理的最小单位是4×4,或者以此为基数进行成倍增加。因此,PAAG的基本簇结构对视频算法的并行化有独特的优势,这也是许多此类阵列机在处理视频算法中的优势所在。PAAG体系结构中,每行、列处理器分别对应有行控制器(Row Controller,CRi)、列控制器(Column Controller,CWj),每个行控制器和列控制器都带有自己的程序存储,可以把一行或一列处理单元重构成SIMD模式,用来实现行、列的数据加载和并行运算。PAAG结构如图3所示,其中CR0~CR3、CW0~CW3分别为行、列控制器,Cluster Memory是簇存储器,用来存储数据和程序,Cluster Controller是簇控制器,用来协调整个系统的工作[14]。PAAG当前的设计最多可支持4 096个PE(PE数量是可配置的),每个PE都有4个方向的共享存储,通过它们可以向PE周围的4个方向共享数据,实现数据的通信。
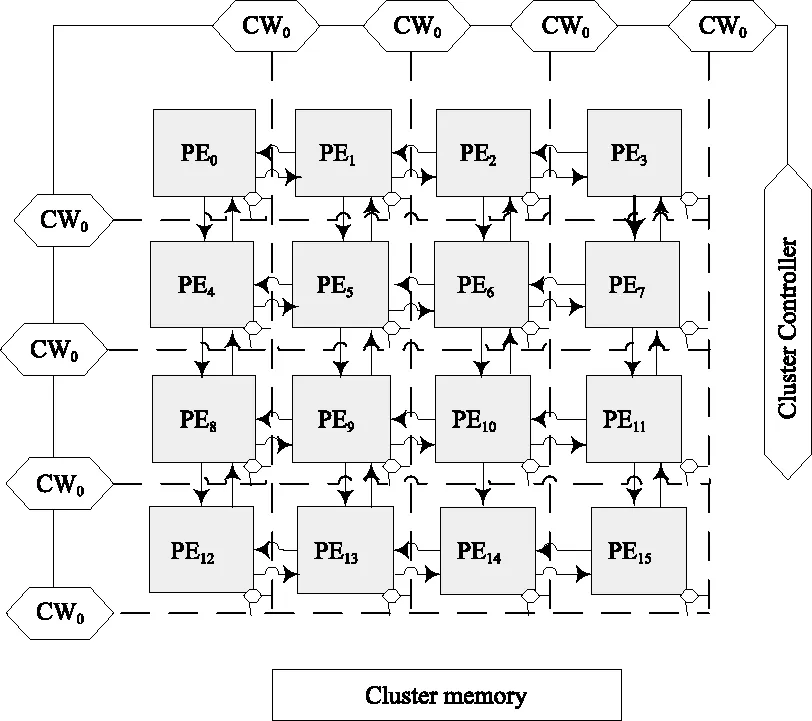
图3 基本簇结构
PAAG IDE(Integrated Develop Environment)是PAAG根据自身硬件结构设计的一套完整的集成开发环境,它可以实现对各种图形图像处理算法并行化的硬件实现进行仿真。它集成了精确的硬件时钟计算、汇编器、程序性能统计与分析以及完整的调试模块,本文设计的并行化算法在该平台上进行验证。
2.2 Planar模式并行化方案
本文基于PAAG的Planar预测模式的并行化思想是:将N×N预测块划分为多个4×4的小块,这是根据PAAG的结构所确定的,对于不同结构的多核处理器划分方式可以不同。通过最优的数据分配方式,将参考像素加载到PAAG结构中的16个PE中,通过16个PE的并行工作,快速计算出像素预测值。
以8×8的预测块为例,首先将8×8的块分成4个4×4的区域,以便于能充分利用16个PE并行计算。如图4所示,整个Planar模式预测通过依次计算出区域1~4的像素来完成。
数据分析:由公式可推导出,参考像素A0~A7分别用于且只用于行坐标为0~7的像素的预测,即A0只用于行坐标为0的像素的预测,A1只用于行坐标为1的像素的预测等。故对顶部参考像素即A0~A7,使用行加载方式。相同地,B0~B7分别用于且只用于列坐标为0~7的像素的预测,故对最左边列的参考像素B0~B7使用列加载方式。行列加载方式如图5所示。
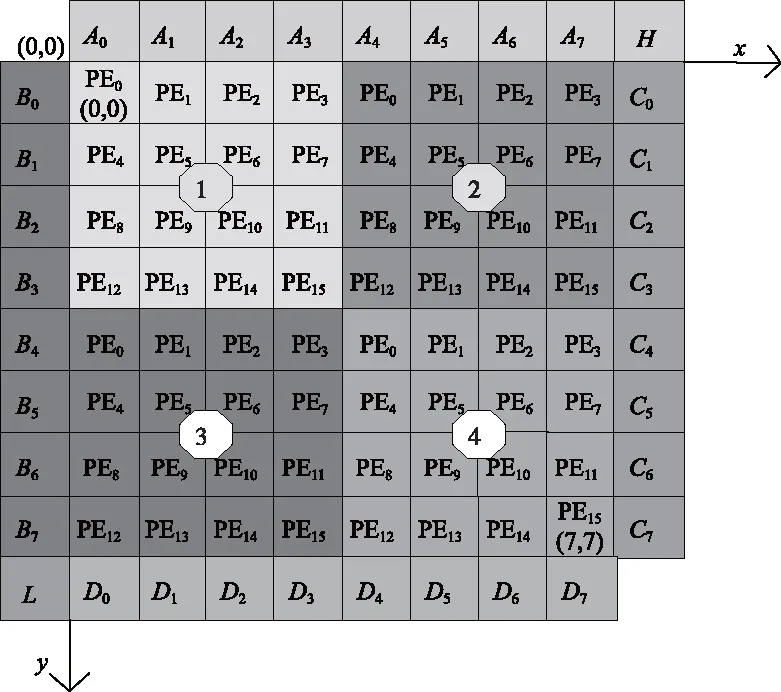
图4 Planar预测模式参考像素的加载
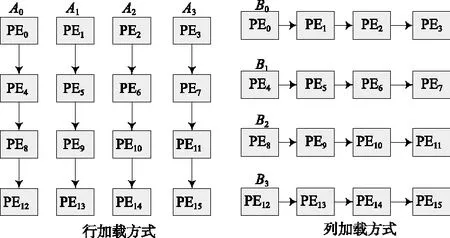
图5 行、列加载方式
第一步,对区域1并行化处理。区域1像素的预测,只需加载参考行像素A0,A1,A2,A3和H,以及参考列像素B0,B1,B2,B3和L。将参考像素按照图6所示的方式和顺序进行分配加载(图中①②③④⑤⑥表示加载顺序):1)按行加载方式加载参考行像素A0,A1,A2,A3;2)按列加载方式加载参考列像素B0,B1,B2,B3;3)按行加载方式加载参考行像素H;4)按列加载方式加载参考行像素L。这样分配数据的目的是使各个PE得到其所需的数据即可,不会加载到各PE计算用不到的数据(例如PE0计算p[0,0]就用不到参考像素B1),同时也减少了PE间数据访问时间。数据加载完成后,16个PE根据式(2)的第一步并行计算,即可得出图4中区域1预测所需的中间值C0~C3以及D0~D3。求差操作得到中间值后,每个PE都得到了其用于预测所需数据,然后根据式(2)第二步进行相应的加权、移位操作,16个PE并行计算出图4所示的区域1的预测值。
第二步,对区域2并行化处理。由于第一步中B0,B1,B2,B3以及M和N均已加载到各对应PE中,因此在预测此区域时只需加载4个参考行像素A4,A5,A6,A7即可。对其按照行加载方式进行加载如图6。通过新加载的参考行A4~A7和第一步已加载的参考列像素B0~B3以及M和N,各PE可以根据式(2)第一步并行计算得到区域2的中间值D4~D7。此时,根据式(2)第二步对数据A4~A7、D4~D7、B0~B3和C0~C3进行加权、移位操作,即可得到区域2的预测值。
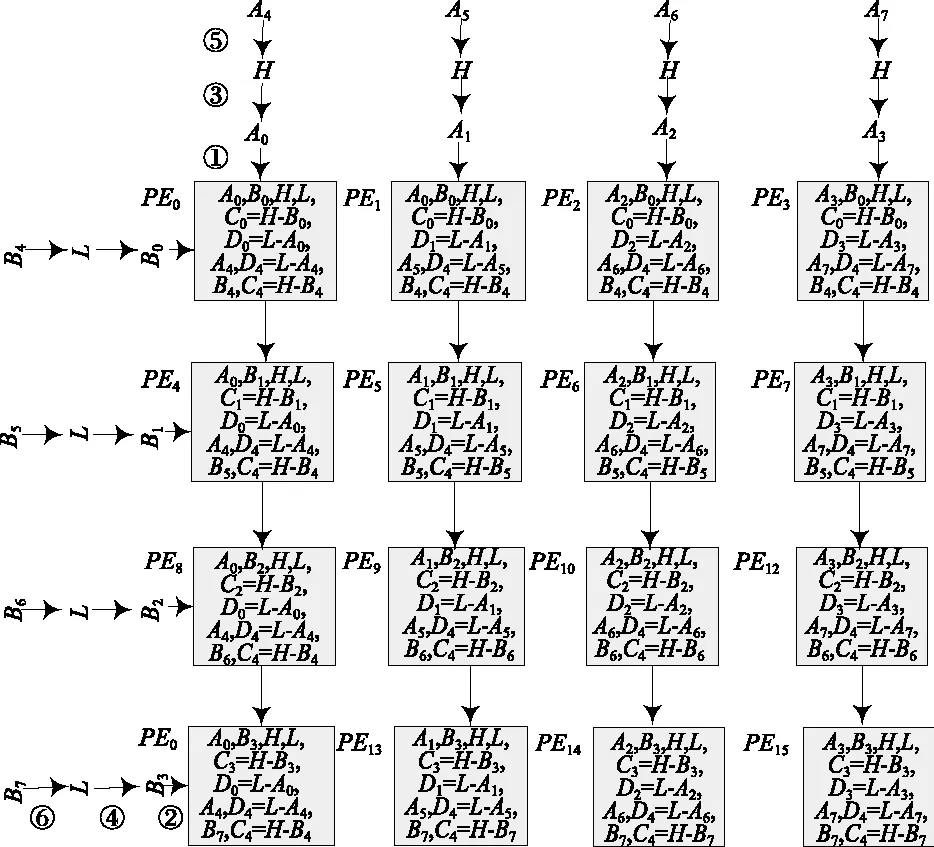
图6 数据加载顺序
第三步,对区域3并行化处理。按列加载方式加载参考像素B4、B5、B6、B7,如图6所示。通过新加载的参考行B4~B7和第一步加载的参考行像素A0~A3以及M和N,各PE根据式(2)第一步并行计算即可得到区域3所需中间值C4~C7。此时,各PE对已有数据并行操作即可得到区域3的预测值。
第4步,对区域4并行处理。由于区域4像素的预测所需参考行像素A4、A5、A6、A7和M,以及参考列像素B4,B5,B6,B7和N在前3步已加载完成,并且C4~C7和D4~D7均已求出,所以各PE根据式(2)第二步进行加权、移位并行计算,即可得到区域4的预测值。
通过这4步操作即可完成HEVC帧内预测8×8的Planar预测模式的并行化。在整个过程中,数据分配方式是最优的,每个PE的计算都无须调用其他PE的数据,节省了存储访问时间。并且在整个过程中16个PE都能充分并行起来,每一步所得的中间数据都能巧妙地被下一步操作使用。
2.3DC预测模式并行化
根据上文介绍的HEVC标准中DC预测模式的计算方法,本文基于PAAG的DC预测模式的并行主要思想是:根据式(3)~式(7),通过16个PE对32×32个像素进行并行求和计算得到中间值dcVal,然后将dcVal通过邻接互联的方式传递给全部16个PE,此时,每个PE中均有预测所需的参考像素值和中间值dcVal,即可并行求出对应的预测值。
具体实现方法可以分为两步:先求中间值dcVal,再求预测值。
数据分析:从公式可看出p(0,0)的预测值可由p(-1,0)和p(0,-1)得出,故对p(0,0)进行预测所使用的PE需要加载这两个像素。对于p(x,0)的预测只需要用到最左侧对应坐标值为(x,-1)的参考像素。对p(0,y)的预测只需要用到最上边对应坐标值为(-1,y)的参考像素。而对于除此之外其他的p(x,y)只需要求出中间变量dcVal即可。因此以32×32的预测块为例,将32个像素值进行分配,如图7所示,其中括号内的数字表示像素的坐标值。

图7 DC预测模式参考像素的加载
数据分配加载完成后,通过PE的并行计算和相互间通信,即可在PE9和PE10中得到DC预测模式的中间值dcVal。
求预测值:计算预测块各点的预测值。首先,将PE9与PE10中计算得到的中间值dcVal传递到所有PE当中,数据传递方式和顺序如图8所示。
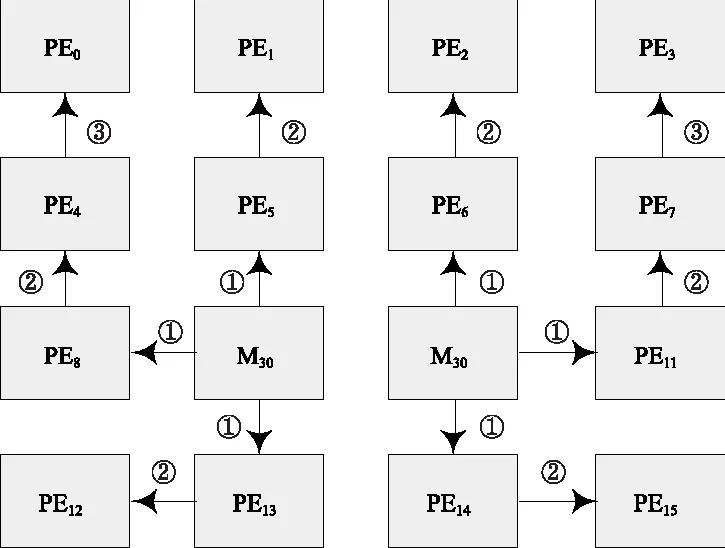
图8 中间值dcVal的传递方式流程图
图8中,PE9将中间值dcVal分别向上、左、下3个方向传递至PE5、PE8和PE13;然后PE5向上传递至PE1,PE8向上传递至PE4,PE13向左传递至PE12;最后PE4向上传递至PE0。PE10的传递方式与PE9的方式对称。中间值dcVal通过这三步传递即可到达所有的PE中,被用来对预测值进行计算。
同时也可以看到,数据传递和共享是非常耗时的,所以设计中尽量避免了数据共享和存取。
此时,PE0中已经加载了p[0,-1]和p[-1,0],故可直接计算得到预测值p[0,0]。PE0~PE15可一次计算出除p[0,0]外的和参考行像素对应的第一行31个预测值p[0,y],以及和参考列像素对应的预测块第一列31个预测值p[x,0]。其余预测值p[x,y]直接由中间值dcVal代替,并且已经存在于每个PE中。
这样,各PE根据中间值dcVal大小并行计算,即可得到当前块的所有预测值。
3 仿真验证与分析
1)为了检测本文Planar预测模式并行化方案的可行性和并行效率,将此方案映射到PAAG仿真平台PAAG IDE上。数据加载时间为44个时钟周期,整个并行计算完成需要241个时钟。
为了对比Planar预测模式在PAAG上并行计算的效率,仅使用单个PE,并且对相同大小的8×8的预测块进行Planar预测模式的串行计算仿真,得到串行计算下Planar预测所需时钟周期数。仿真结果表明,数据加载需要77个时钟周期,整个预测过程需要1 527个时钟周期。
经仿真验证,Planar预测模式串行计算预测值与并行计算预测值完全吻合。Planar预测模式串行计算仿真结果与并行计算时钟周期对比如表1所示。
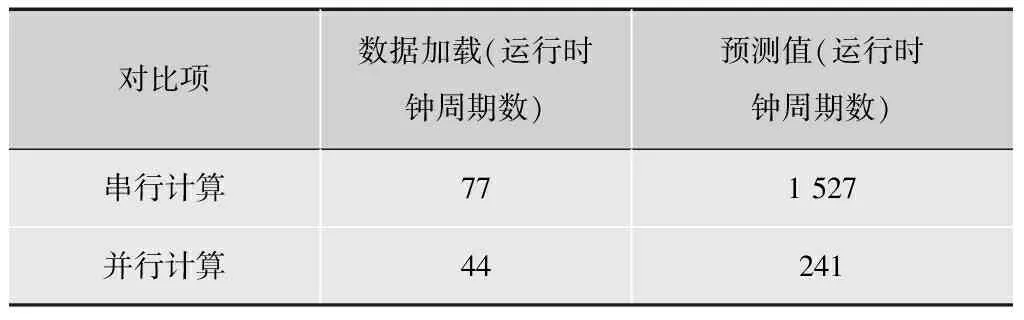
表1 Planar预测模式串/并行计算时钟周期 cycle
由表1可见,Planar预测模式的并行实现,可以大大减少在单个PE上串行实现所需的数据加载时间以及预测所用的时钟周期数,并行算法的计算速度相比串行提高了84%,串/并行加速比达到6.34。仿真结果表明,此并行算法可以充分利用了PAAG结构的特点,有效提高了Planar预测模式的计算速度。
2)将本文提出的DC预测模式方案在仿真平台PAAG IDE上进行仿真。仿真结果表明,计算中间值dcVal需要62个时钟周期,完成DC预测模式的所有计算共需要146个时钟周期。
为了对比DC预测模式在PAAG上并行计算的效率,将相同大小为32×32的预测块在PAAG IDE仿真平台上进行DC预测模式的串行计算。仿真结果表明,中间值dcVal计算完成需要473个时钟周期。DC预测模式的预测完成共需要794个时钟周期。
同样地,DC预测模式串行计算的预测值与并行计算的预测值完全吻合,证明了本文DC预测模式并行方案的正确性。DC预测模式串行计算仿真结果与并行计算仿真结果对比如表2所示。

表2 DC预测模式串/并行计算时钟周期 cycle
由表2可见,DC预测模式的并行实现,可以大大减少在单个PE上串行实现所需的数据加载时间以及预测所用的时钟周期数,并行算法的计算速度相比串行提高了81%,串/并行加速比达到5.44,有效地减少了DC模式预测所需时间。
4 结束语
帧内预测是HEVC视频编解码中非常重要的部分,本文结合面向图形图像处理的阵列处理器PAAG的结构特征,提出了一种帧内预测Planar和DC模式算法的并行优化方案。在分析原有算法的基础上,将算法进一步拆分合并,提出适合并行化的算法步骤。通过最优的数据分配方式,将16个PE充分利用起来进行并行化计算,大大提高了计算效率。实验中发现,由于PAAG的邻接互联方式的限制,数据共享消耗时间较长,所提并行方案运算速度还有很大的提升空间。同时,本文提出的并行方案属于普适方法,接下来也将在类似的多核处理器架构上进行实验。
[1]SULLIVAN G J,OHM J R,HAN W J,et al.Overview of the high efficiency video coding (HEVC) standard[J].IEEE Trans.Circuits and Systems for Video Technology,2012,22(12):1649-1668.
[2]BROSS B,HAN W J,SULLIVAN G J,et al.Document JCT-VC-L1003,High efficiency video coding(HEVC)text specification draft 10[S].2013.
[3]LAINEMA J,UGUR K.Angular intra prediction in high efficiency video coding(HEVC)[C]//Proc.IEEE 13th International Workshop on Multimedia Signal Processing(MMSP).Hangzhou,China:IEEE Press,2011:1-5.
[4]周巍,黄晓东,朱洪翔,等.HEVC帧内预测Planar和DC模式的VLSI架构设计与实现[J].计算机工程与应用,2014(12):34-37.
[5]张和仙.下一代视频编码标准HEVC帧间预测优化算法研究[D].西安:西安电子科技大学,2013.
[6]石飞宇,刘昱.一种HEVC快速帧内模式判断算法[J].电视技术,2013,37(11):8-11.
[7]成益龙,滕国伟,石旭利,等.一种快速HEVC帧内预测算法[J].电视技术,2012,36(21):4-7.
[8]ZHANG Hao,MA Zhan.Fast intra mode decision for high efficiency video coding (HEVC)[J].Circuits and Systems for Video Technology,2014,24(4):660-668.
[9]VANNE J ,VIITANEN M, HAMALAINEN T.Efficient mode decision schemes for HEVC inter prediction [J].Circuits and Systems for Video Technology,2014,24(9):1579-1593.
[10]KALALI E,ADIBELLI Y,HAMZAOGLU I.A high performance and low energy intra prediction hardware for high efficiency video coding [C]//Proc.22nd IEEE International Conference on Field Programmable Logic and Applications(FPL).Oslo:IEEE Press,2012:719-722.
[11]MRAK M,GABRIELLINI A,FLYNN D,et al.Parallel processing for combined intra prediction in high efficiency video coding[C]//Proc.18th IEEE International Conference on Image Processing(ICIP), 2011.Brussels:IEEE Press,2011:3489-3492.
[12]YAN C,ZHANG Y,DAI F,et al.Efficient parallel HEVC intraprediction on many-core processor[J].Electronics Letters,2014,50(11):805-806.
[13]ZHAO Yanan,SONG Li,WANG Xiangwen,et al.Efficient realization of parallel HEVC intra encoding[C]//Proc.IEEE International Conference on Multimedia and Expo Workshops (ICMEW),2013.San Jose,CA:IEEE Press,2013:1-6.
[14]李涛,肖灵芝.面向图形和图像处理的轻核阵列机结构[J].西安邮电学院学报,2012,17(3):41-47.
徐卫芳(1988— ),女,硕士,主研视频编解码算法研究,本文通信作者;
刘 帆(1986— ),硕士,主研图形图像与视频处理。
责任编辑:时 雯
Efficient Parallel Design of Planar and DC Mode in HEVC Intra Prediction
XIE Xiaoyan,XU Weifang,LIU Fan
(SchoolofComputer,Xi’anUniversityofPostsandTelecommunications,Xi’an710061,China)
A parallel processing method of realizing Planar and DC mode is proposed according to the algorithm characteristics of the two prediction modes in HEVC intra prediction.A parallel algorithm program is designed based on PAAG (Polymorphic Array Architecture for Graphics and Image Processing, an image array processor designed by Xi’an University of Posts and Telecommunications)processor platform by analyzing and deriving the parallelism of Planar prediction mode and DC prediction mode, adopting the best data distribution and making full use of multiple processing elements of PAAG.Compared with serial computing, the experimental results show that the parallel achievements of Planar prediction mode and the DC prediction mode on the processing elements reduce computing time of 84% and 81%, gaining speedups of 6.34 and 5.44 times, respectively.The parallel method significantly reduces the time of video codec and its data distribution schemes also have a certain reference value for the parallelization research of intra prediction algorithm based on multi-core structure.
HEVC; planar prediction; parallelism; data distribution; array processor
国家自然科学基金项目(61272120);陕西省自然科学基础研究计划项目(2013JC2-32)
TP311
A
10.16280/j.videoe.2015.05.002
谢晓燕(1972— ),女,硕士生导师,主要研究方向为服务计算;
2014-09-24
【本文献信息】谢晓燕,徐卫芳,刘帆.HEVC帧内预测Planar和DC模式算法的并行化设计[J].电视技术,2015,39(5).
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
国外核新闻(2020年8期)2020-03-14
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
