
云环境下基于SLA的工作队列调配算法研究
2015-06-21 12:43:09王启明
系统仿真技术 2015年4期
王启明,甘 泉
(平顶山学院计算机科学与技术学院河南平顶山 467000)
云环境下基于SLA的工作队列调配算法研究
王启明,甘 泉
(平顶山学院计算机科学与技术学院河南平顶山 467000)
云计算环境下,工作任务的调度和计算资源的分配受到SLA的约束。不同的工作任务要求不同的QoS,采用具有SLA参数的约束条件,对任务划分优先级,形成优先级队列。在对该任务分配计算资源时,采用资源等级队列的方法,分配合理的工作节点已完成任务。
云计算;SLA;工作队列;调度算法
1 引 言
在云计算平台应用的各种技术中,资源调度算法是一个很关键的技术。因为它负责把任务分配到工作节点中运行,云计算平台性能的好坏主要体现在任务分配的合理程度。现有资源调度算法很多,一些经典的算法如Min-min算法、遗传算法、WQR算法(WQ的改进算法)和LATE算法等。这些算法有各自的特点,但也存在不足。
有学者提出一个优先级工作队列资源调度算法[1]。该算法是在WQ算法的基础上,加入工作节点模糊评级策略。该算法用运行任务的平均完成时间对工作节点进行评级,避免了根据硬件信息进行评价的困难。工作节点选择算法通过顺序查找等级队列,在找到的等级中随机选择工作节点,然后把任务分配给工作节点运行。工作节点等级迁移算法通过同级比较和异级比较的过程,使等级队列逐渐完成。
资源调度过程中,考虑到云计算的服务质量,云计算服务提供商通过与客户签订SLA(Service-Level Agreement)将非本地的网络资源以更具有针对性,更高速更廉价的方式提供给用户,并根据SLA中所签订的内容来保证各自利益。由于云计算环境下计算中心本身的大规模性,服务器之间可能存在的异构性,节点之间可能存在负载不均的现象,这将严重威胁到机器性能,从而用户的服务质量不能得到保证,服务提供商还需根据SLA内容缴纳违约罚金[2]。所以在云计算环境下如何建立有效的负载均衡机制合理利用网络资源以保证SLA成为必须考虑的研究内容。
2 经典资源调度算法分析
2.1 Min-m in算法
Min-min算法的思路是:优先调度长度最小的任务和优先分配任务给任务完成时间最小的工作节点[3]。其目的是优化多个任务的总体完成时间,并面向批处理任务的情况下而提出的资源调度算法。算法运行的基础是先要获得每个任务在各个工作节点上运行的时间和任务的长度,因此,每调度一个任务都要遍历一次所有的工作节点,这对于规模大的云计算平台,效率低,开销大。同时,由于任务被分配给性能最好的那些工作节点,没有被分配到任务的节点则处于闲置状态,该算法还存在负载不均的问题[4]。
2.2 遗传算法
遗传算法的思路是:假设有m个任务,n个工作节点,进行染色体编码和解码,表示出任务的总完成时间,适应度函数设计为:
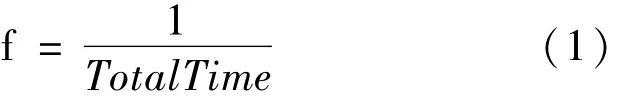
染色体会通过一定的交叉和变异的操作而变化,经过多次迭代运算,可以找出一个使任务的完成时间最短的解[5]。
由于遗传算法得出最优解的过程需要反复迭代多次,时间和空间开销比较大;再者,这个算法和Min-min算法一样,需要每个任务在每个工作节点上的完成时间的ETC矩阵,这个矩阵是很难获得的。因此,遗传算法不是一个在实际的云计算平台中适合的资源调度算法。
2.3 WQ算法和WQR算法
WQ(Workqueue)算法的思路是:对任务是按照FIFO的原则调度,先提交的任务最先调度,而对于工作节点的选择则是随机进行。每当有工作节点空闲的时候,WQ算法就立即分配一个新任务给它。
WQ算法的过程很简单,它虽然这种方法在局部的时间内不是最优的,但在较长的时间跨度内,由于性能高的工作节点完成任务速度快,算法分配给性能高的工作节点的任务数量总体偏多。因此WQ算法在降低任务的平均完成时间方面有不错的性能。它避免了Min-min算法和遗传算法固有的缺点。WQ算法运行过程中,不需要获取详细的工作节点信息和任务信息,没有复杂的运算过程,在云计算平台负载较高时,算法有很突出的性能。WQ算法的缺点是,由于算法是随机选择工作节点,当云计算平台负载较低时,所选择的工作节点性能有很大的不确定性。
WQR(Workqueue with Replication)算法是WQ算法的改进型,它在WQ算法原理的基础上,对每一个调度的任务都同时在多个工作节点上运行,以获得更好的任务完成时间。WQR算法在异构的云计算平台上具有良好的性能。WQR算法过程同样简单,它也不需要获取工作节点和任务的信息,是一个可行的算法。WQR算法改善了在云计算平台负载较低的情况下的性能。WQR算法的缺点是对资源的消耗比较大。
2.4 LATE算法
LATE算法的思路是:用任务迁移的方法解决较慢的任务。在Hadoop中,一个工作会被划分为多个任务,然后把这些任务分配给闲置的工作节点运行。但有时会把任务分配给性能比较低的工作节点,由于这个工作节点完成任务耗时长,因此成为整个工作完成的短板。LATE算法通过把这个任务重新分配给另外一个工作节点运行的方法来避免这个问题。LATE算法用ProgressScore来评价任务的进度,从而选择哪一个任务重新运行。
LATE算法的过程简单,而且改正了Hadoop默认算法的缺点,在异构的云计算平台上有很好的表现。它通过评估任务的剩余完成时间决定某个任务是否需要重复执行,减少了无谓的资源浪费。是一个可行的资源调度算法。这个算法的缺点是,当一个任务被调度到另外一个工作节点重复执行时,该任务需要从原点重新执行。这种任务的迁移也没有考虑到网络负载的因素,可能造成事倍功半。
3 基于QoS约束的负载均衡问题
服务等级协议SLA是关于服务供应商与客户间签订的一份合同,其中定义了服务类型、服务质量和客户付款等方面的内容,同时也包含了关于供应商提供的服务达不到服务等级协议时,供应商应对用户进行的赔偿等内容[6]。服务等级协议SLA就是服务供应商和用户之间经过协商达成的一系列的目标,其主要目的是为了达到和维持一定的服务质量(QoS)。
随着云计算技术的发展,越来越多的关于云计算的应用将投入使用,所以,如何保证云计算的安全性问题也得到了广泛关注,而如何保证云计算的服务质量,也将成为云计算继续发展的重要前提。因此,在用户与云供应商签订合同时,也更加关注服务等级协议SLA。在服务等级协议SLA中,需要清晰的写明能够提供的各项服务参数指标,以及服务达不到要求时的违约责任,从而更好地保证用户的权益。SLA中规定了服务的响应时间,数据的安全保障等QoS的内容,以及计费付费模式等等,因此SLA是评判云服务的标准,也是提供商最关注的环节之一。所以提高云计算的服务质量尽量降低SLA违约风险是研究的重要内容。但是对于云计算这样大规模集群式的服务器模式以及云计算基础设施的异构性以及服务类型的多样性,导致系统中有些节点处于重载,与此同时,另一些节点处在轻载甚至空闲状态,重载节点响应速度急剧下降,系统无法提供服务,SLA违约。所以,部署一个有效的负载均衡策略对于保障云计算服务SLA来说,是至关重要的。
4 基于SLA的任务队列
4.1 优先级任务队列设计
在作业分类器中设计从用户服务等级协议信息到作业优先级的映射机制。提取服务等级协议中四个主要的服务参数(可用性、响应时间、资源弹性和违约罚金)的指标值。对参数的指标值进行等级分类设计,将每个服务参数分为三个类别,具体的分类设计,如表1所示。
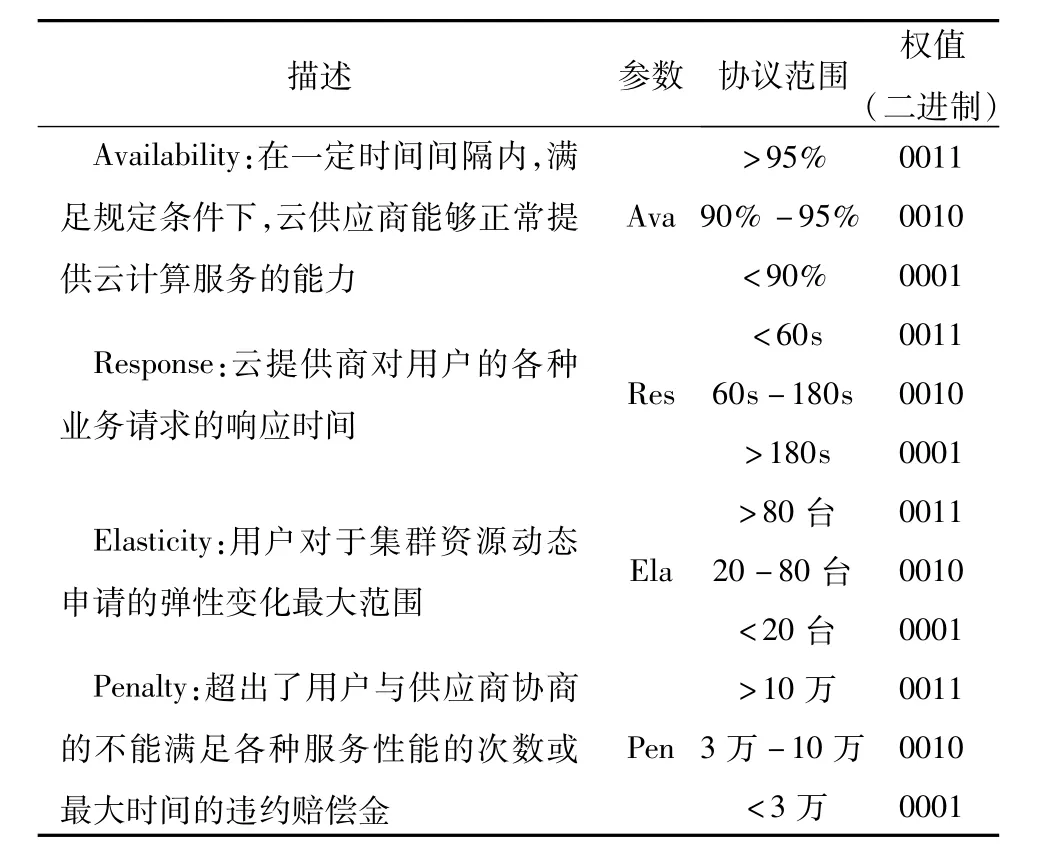
表1 SLA服务权值表Tab.1 The SLA service weight value table
在基于SLA的作业优先级机制中,作业i的优先级设为NICE,其取值为:
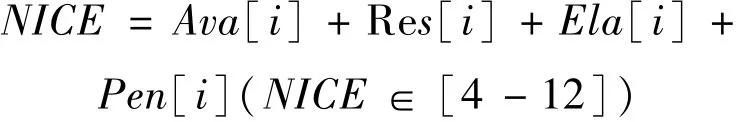
其中,NICE值越大,优先级越高,反之,优先级越低。作业按照优先级NICE值形成优先级队列。一段时间内,若有相同NICE的作业出现,则按照FIFO的算法排列在相同NICE的作业后。
4.2 作业数据结构设计
任务队列是待处理的任务的FIFO队列,此队列中的任务是最小不可再分的,是分配给工作节点处理的最小单位。任务定义为
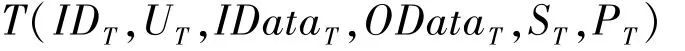
其属性说明如下:
IDT为任务的编号;
UT为任务的所有者标识,通过这个所有者标识可以区分调度的优先级;
IDataT为需要处理的数据,调度算法可以通过把任务分配给有本地数据的工作节点,避免了网络传输数据带来的开销,从而优化云计算平台的网络负载;
ODataT为处理完成后的数据;
ST为任务状态,云计算中的工作节点的稳定性参差不齐,因而会出现任务不能正常运行,通过标示任务的状态,从而为此类任务重新调度时,可以更先调度并赋予更高性能优先级的工作节点,以便迅速完成;
PT为任务费用,由于云平台中不同的工作节点需要不同的处理费用,通过表示任务可付的费用,当调度时可以分配一些与之相适应成本的工作节点,这对于减少云计算平台运行成本至关重要[1]。
5 基于SLA的工作队列资源调度算法设计
5.1 主要实体数据结构
5.1.1 工作节点
工作节点是处理任务的单位,即任务分配的对象,是计算资源和存储资源的提供者。云计算中,大量采用虚拟化技术,每一台计算机可以虚拟出一个或多个个工作节点。因此实际工作节点的数量可以大大多于实体机器的数量。工作节点定义为其属性说明如下:
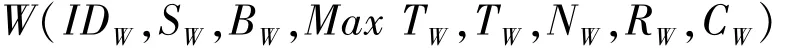
IDW为工作节点编号;
SW为工作节点可以提供的存储资源的大小,作为工作节点选择的一个重要依据;
BW为工作节点网络带宽,工作节点选择的一个重要依据;
MaxTW为工作节点最大同时运行的任务数量,不同性能的工作节点设置不同的最大任务数量,工作节点的负载也是通过使用此属性来标识;
TW是记录在工作节点上运行的任务的总时间,此值是通过累加任务运行的时间得出;
NW为在工作节点上运行的任务的总数量,此值是通过累加任务的数量得出,把TW/NW得出的平均运行时间来表示工作节点的快慢,从而间接地评价了工作节点的性能;
RW为工作节点的级别,工作节点的分级是以在此工作节点上运行任务的平均完成时间为基础,平均完成时间越小,级别越高,从而更优先调度。此值只能由工作节点迁移算法更改;
CW为工作节点的使用费用,与任务中的PT配合使用,为任务的分配提供选择依据,从而达到最小使用成本的目的。
5.1.2 等级队列
等级队列为多个工作节点分级队列,队列中的工作节点根据平均任务完成时间来分级。等级队列的属性为

其属性说明如下:
NRQ为等级队列中分级数,分级数的多少直接影响着优先级工作队列算法的性能,分级数越多,本算法的性能越好,但算法的运行时间会越长。分级数由云计算平台的管理员来设置,平台中的工作节点性能差别越大,分级数应该越多,反之越少,当分级数为一时,本算法就退化为WQ算法[7];
MaxWRQ为每一个分级中最多包含的工作节点数,这个属性是由算法自动设置,通常每一级都分配相同数量的工作节点,以达到最好的平均性能;
QRQ为保存工作节点的队列数组,数组的大小为NRQ,每一个数组项都为工作节点的列表。本文中,默认设定最高级别为0级,最低级别为NRQ-1级。
5.2 资源调度算法
5.2.1 工作队列选择算法
调度算法把在任务队列中的任务合理地分配给工作节点,从而优化任务的平均完成时间和负载均衡[8]。工作节点的选择是指在数量众多的工作节点中选择特定数量的工作节点,为任务分配计算资源和存储资源。工作节点选择算法在待调度任务队列中选择一个任务,分配给某一个工作节点,工作节点的选择会根据工作节点的分级信息和数据的存储位置等信息为依据,而工作节点的分级信息是动态变化的,因此工作节点选择算法在调度每一个任务时都要读取一次分级信息。
5.2.2 算法流程设计
调度每一个任务前,都运行一次工作节点选择算法。时间复杂度为O(NRQ),NRQ为分级数。算法的流程如下:
(1)从任务队列中获取一个任务t,转到流程(2);如果队列为空,则退出算法;
(2)获取存储有任务输入数据的工作节点列表L。如果列表L中有工作节点w存在于待分配任务的工作节点分级集合中,并且w为待分配任务的工作节点中最高级别的,则把任务t分配给工作节点w,转到(1);如果没有,则转到(3);
(3)从i(i初始为0)级别开始获取当前级别上待分配任务的工作节点列表La,如果La为空,则设i=i+1,转到(4);如果La不空,转到(5);
(4)如果i大于Nrq-1,则等待直到收到待分配任务的工作节点信息,设置i=0,转到(3);
(5)从待分配任务的工作节点列表La中随机选择一个工作节点Wa,把任务t分配给工作节点Wa,转到(1)。
5.2.3 算法分析
这种算法优先把任务分配给存储有任务输入数据的工作节点[9],可以减少不必要的网络传输[10]。该算法用运行任务的平均完成时间对工作节点进行评级,避免了根据硬件信息进行评价的困难。工作节点选择算法通过顺序查找等级队列,在找到的等级中随机选择工作节点,然后把任务分配给工作节点运行。工作节点等级迁移算法通过同级比较和异级比较的过程,使等级队列逐渐完成。
6 结束语
本文研究了在SLA约束下的云计算平台中,云计算任务基于约束条件的优先级队列设计,和资源调度算法。在任务优先级队列设计中,对某些文献中的优先级队列设计进行了改进,文献中,SLA服务参数采用等级值{A,B,C}的方法设计,笔者经过演算认为,在用户服务等级协议与作业等级的映射表Mapping Table中,会出现Job Level重叠的情况,因此改为采用二进制权值的方法来标记参数。在资源调度算法中,考虑到云计算平台的计算负荷,采用复杂度适中的算法设计,更能够符合云计算平台的实际情况。当任务执行过程中,面临SLA违约的危险时,就要才用任务迁移的方法,任务迁移算法将作为后续研究内容。
[1] 叶毅峰.云环境下优先级工作队列资源调度算法研究[D].暨南大学,2013.
YE Yifeng.The Priority Workqueue Resource Scheduling Algorithm for Cloud Environment[D].Jinan University,2013.
[2] 王锐.云计算环境中基干SLA的负裁均衡机制研究[D].云南大学,2012.
WANG Rui.Research on Load-Balancing Mechanism Based on SLA in Cloud Environment[D].Yunnan University,2012.
[3] Armstrong R,Hensgen D,Kidd T.The relative performance of various mapping algorithms is independent of sizable variances in runtime predictions[J].In 7th IEEE Heterogeneous Computing Workshop,(HCW 98),1998,10(2):79-87.
[4] Freund R F,Gherrity M,Ambrosius S.Scheduling resources in multi-user,heterogeneous,computing environments with SmartNet[J].In 7th IEEE Heterogeneous ComputingWorkshop,(HCW 98),1998,10(2):184-199.
[5] 李建锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,31(1):184-186.
LI Jianfeng,PENG Jian.Task scheduling algorithm based on improved genetic algorithm in cloud computing environment[J].Journal of computer applications[J],2011,31(1):184-186.
[6] 张建.云计算服务等级协议SLA研究[J].电信网技术,2012,2(2):7-10.
ZHANG Jian.Research on cloud computing service level agreements[J].Telecommunications network technology,2012,2(2):7-10.
[7] Jing Lu,Meifang Shao.Relaxing Data Integrity in Cloud Computing Environment[J].International Journal of Digital Content Technology and its Applications,2012,6(13):241-249.
[8] 郑湃,崔立真,王海洋.云计算环境下面向数据密集型应用的数据布局策略与方法[J].计算机学报,2010,33(8):1472-1480.
ZHENG Pai,CUI Lizhen,WANG Haiyang A Data Placement Strategy for Data—Intensive Applications in Cloud[J].CHINESE JOURNAL OF COMPUTERS,2010,33(8):1472-1480.
[9] Alain Tchana,Laurent Broto,Daniel Hagimont.Approaches to Cloud Computing Fault Tolerance[R].IEEE CITS 2012-2012 International Conference on Computer,Information and Telecommunication Systems.2012:25-27.
[10] CloudSim.A Framework For Modeling And Simulation Of Cloud Computing Infrastructures And Services[EB/OL].2011.http://www.cloudbus.org/cloudsim/

王启明 男(1980-),河南鲁山县人,讲师,主要研究方向为软件工程、算法设计等。

甘 泉 男(1980-),安徽灵璧县人,讲师,主要研究方向为操作系统、算法分析等。
A Work Queue Scheduling Algorithm Based on SLA Under Cloud Environment
WANG Qiming,GAN Quan
(College of computer science and technology,Pingdingshan University,Pingdingshan 467000,China)
Under cloud computing environment,task scheduling and computing resources allocation is constrained by the SLA.Different tasks require different QoS,so the work queue is classified w ith constraints of the SLA parameter.Task is allocated on the computing resources by reasonable assignment of work node in the resource level queue.
cloud computing;SLA;work queue;scheduling algorithm
TP 312
A
河南省科技厅攻关项目(KJT142102210226)
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
军营文化天地(2018年2期)2018-12-15 17:39:08
产品可靠性报告(2017年7期)2017-09-05 09:49:12
