
数据挖掘在电信行业客户流失预测中的应用
2015-06-05 05:23:00张线媚西安思源学院工学院陕西西安710038
网络安全与数据管理 2015年15期
张线媚(西安思源学院 工学院,陕西 西安 710038)
数据挖掘在电信行业客户流失预测中的应用
张线媚
(西安思源学院 工学院,陕西 西安 710038)
客户流失是电信行业发展过程中所面临的一个严重问题,直接影响到运营商的企业效益。本文主要介绍了对电信行业客户流失情况进行数据挖掘的过程,改进了已有模型存在的缺乏灵活性、难以处理高维度数据的缺点,根据运营商的历史数据资料,利用SAS/EM模块对客户的固有特征和行为特征进行挖掘分析,采用决策树分类算法的CART算法建立了聚类分析模型和包括评估模块在内的一套完整的流失预测模型,能够直观地显示出流失客户的基本特征,并且可以对任意的数据集进行分析,有效提高了模型的普遍应用性和准确性。
客户流失;数据挖掘;决策树;CART算法;聚类分析;SAS/EM模块;客户流失预测模型
0 引言
在电信这个服务型行业中,客户关系管理工作直接关系着企业的经济效益、声誉和信誉,而在客户关系管理工作中,开发一个新客户的成本比挽留一个老客户的成本要高出很多倍[1]。
传统上国内外移动运营商认为新客户在最初两个月内流失的概率最大,大约为10%左右,所以运营商会建立一个呼叫中心,在客户使用移动电话一个月左右后,主动和客户联系[2],但这样的方法不切实际。因此,近年来好多电信运营商都开始建立客户流失预测模型。
目前主要的做法有采用 SPSS公司的 Clementine工具,使用节点连接的方式,分别用分类回归树(CART)算法和 C5.0算法建立流失预测模型[3]。还有一种采用Weka工具的决策树分类器,应用一趟聚类算法进行聚类分析,将分析后的簇群号作为新的特征增加到原数据集中,对新的数据建立决策树分类模型[4]。该模型准确率较高,但是模型考虑的变量因素比较少、数据量比较小,缺乏普遍性,对于客户流失的原因分析具有一定的局限性。
本文采用 SAS软件,在对大规模、高维度的历史数据引入属性选择、特征提取和特征选择的基础上,对数据进行处理,然后利用新的数据源建立包括模型评估在内的完整的流失预测模型。模型中添加了评估模块,可以对流失预测的结果进行检测优化,提高流失预测的准确率;克服了单一评价标准的缺陷,结合了是否流失和流失概率两个基本的评价标准;而且对于最终的预测结果有详细的报告存储路径,以便查看和应用于日后的市场运营策略的改进工作中,从而有效地采取挽留措施,减少客户的流失量,做好客户关系管理工作,提高企业的经营效益,获得企业持续经营的成功。
1 数据准备
要建立灵活、普遍性高的客户流失预测模型,必须采集大量的客户信息资源数据,同时需要对其进行数据的预处理,得到构建模型所需的数据形式。因此,在这个阶段需要对模型所需的原始数据 (训练数据和测试数据)进行分析处理,以便能充分挖掘出客户的关键性行为特征[5]。
1.1样本选择和数据描述
以某地区联通运营商的客户业务数据作为实验数据(包括训练样本集和测试样本集),该样本数据集中总共包含了 695 689条(包含正常客户和流失客户)记录,每条记录由33项客户基本信息和48项客户行为特征(12种业务,4个月,共48项)以及1项客户类别特征组成。
(1)客户基本信息:主要是客户资料数据。客户基本信息数据是客户的静态数据(如表1所示),相对来说比较稳定,但是由于这些数据在客户入网填写时会包含大量的缺失值,甚至是假的错误的信息,所以需要进行大量的数据清洗和转换工作。
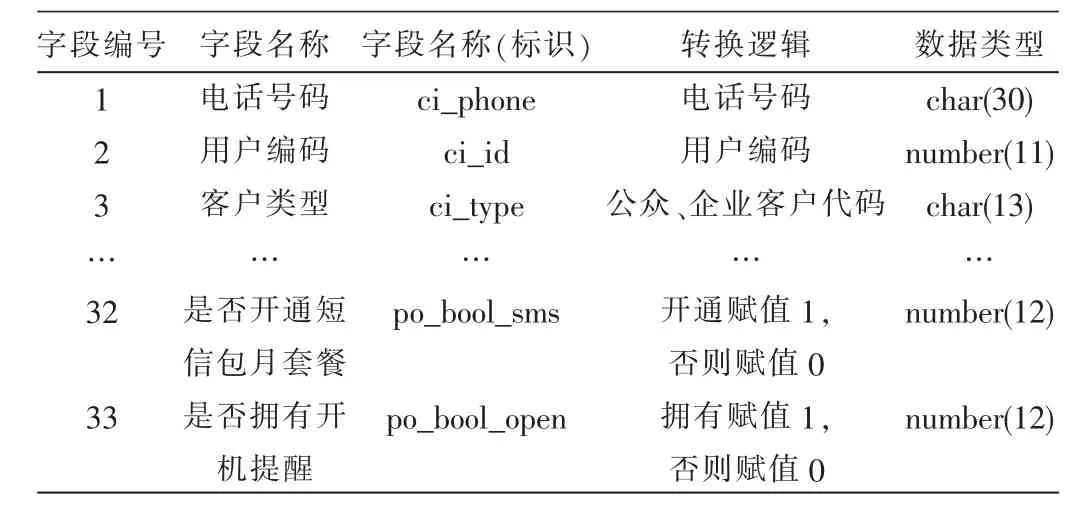
表1 客户基本特征表
(2)客户消费行为特征:主要是客户在过去4个月的消费行为数据。客户消费行为特征的每条记录包含了客户在过去4个月的消费情况,包括12个基本消费行为,所以该样本总共包含了 48(12×4=48)项数据记录,如表2所示。
(3)客户类别特征:主要用来标注客户的状态。实验样本数据集中包含了一个可以判定类别信息的类别特征(如表3所示),根据类别信息可以知道每个客户的基本状态。

表2 客户消费行为特征表(一个月份)

表3 客户类别特征
1.2数据预处理
数据预处理的效果会直接影响到模型的性能和流失预测的结果,一方面,通过对数据格式和内容的调整、完善,可以使得建立的模型更简单、准确,而且便于理解;另一方面,可以根据整理好的数据的特点以及不同算法的要求,选择合适的执行算法,从而降低算法的时间和空间复杂度。为了克服已有模型存在的缺乏灵活性缺陷,此处的数据预处理是根据数据的属性特点分开进行,主要包括数据清洗、特征构造和特征选择等过程[6]。
(1)数据清洗
主要是补全缺失的数据、处理不一致的数值、除去错误的数据。例如:如果某条记录中存在大量的缺失值,而且这些数据很难用正常的方法来补全,则可以考虑删除整条记录数据;又或者记录数据的某项缺失,在不影响整体样本数据集的情况下,可以考虑用均值来补全缺失值。
(2)数据转换
主要包括构造新的衍生特征信息和对连续型数据进行规范化。在采集的数据信息中,消费行为特征只有过去4个月的消费记录,这几个特征不能充分体现客户在这4个月以及将来的消费情况。所以,在对数据集进行处理时,对于12项月消费行为的记录采用了构造衍生特征的措施,构造了24项月均消费信息和月均消费趋势的信息。例如:
月均消费行为:为过去4个月的费用的平均值,表示为mb_fee,即:

月消费趋势:为过去4个月的消费记录中后2个月的总消费与前2个月的总消费的比值,表示为trend_fee,即:
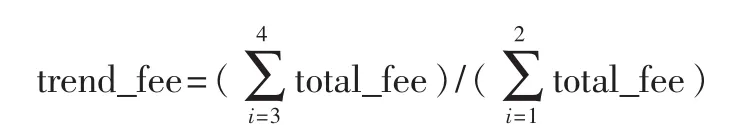
(3)特征选择
这个步骤将会直接影响到分类预测模型的性能。通过选择相关性强的特征,从原始数据集中删除不相关或者相关性很小的特征项,保留与目标特征相关性大的特征项,可以减少样本的维度,从而大大减少计算量,降低时间和空间的复杂度,简化学习模型。
经过对数据进行预处理,最终整理了高维度、大规模的、用于实验数据集的样本,总共包含了 631 590条记录,每条记录包含33项客户基本信息和114项客户消费行为特征 (构造的24项月均消费行为特征、24项月均消费趋势特征和17项通话行为特征、21项不同时段通话频率行为特征、20项服务消费行为特征以及8项手机上网行为特征)以及1项类别特征,总共148项。
2 建立模型
因为本案例主要应用两种模型来进行数据挖掘,所以在建立模型时需要考虑可实施性来建立合理的模型。在这里采用SAS/EM模块来搭建整个模型,将聚类分析模型和流失预测模型布置在同一个工作区中,两个模型各自执行不同的功能,最终完成对数据的挖掘工作。所建立的模型如图1所示。

图1 客户聚类分析和流失预测模型
2.1聚类分析模型
聚类分析模型通过对客户的合理划分来反映客户的整体特征,根据划分后的类别簇群来判断不同客户的固有信息及消费特点。
从聚类分析模型的显示结果(如图2所示)可以看出,所有的客户被分为10个簇群,从各个簇群的类别分布情况来看,有6个簇(簇1、簇2、簇4、簇5、簇8、簇9)的客户基本是由正常客户组成,其他4个簇的客户基本是由流失客户组成,而且通过与每个特征分布的均值对比,可以发现10号簇群的差异性最大[7-8]。
2.2流失预测模型
对数据进行聚类分析是流失预测的基础,目的是将客户划分为不同的类别,这样可以在不同的客户群体上进行预测分析,从而根据各记录的类别编号判定流失客户的所属类别。所以在进行流失预测分析之前,将每条记录所在的类别编号作为一项特征添加到实验数据表中,用于流失预测建立模型的数据集中总共包含了150项特征(148项基本特征+1项聚类编号+1项目标特征)和631 590条数据记录。选取其中2/3的数据作为训练集,剩余1/3的数据作为测试集,这样分开预测主要是后面便于检测预测模型的准确度。

本案例使用SAS/EM的决策树分类节点作为客户流失预测的基本工具,选用决策树分类算法中的分类与回归树(Classification and Regression Tree,CART)算法构建聚类分析模型,该算法采用Gini系数来度量对某个属性变量测试输出的两组取值的差异性,采用“最佳评估值”方法来进行树剪枝。
在 SAS/EM模块流失预测模型的分析结果中,图 3为混淆矩阵,直观显示训练集和测试集的预测数据结果,图 4为 Gini系数均方误差曲线图,通过训练集和测试集Gini系数的均方误差曲线对比来反映模型的误分率情况。
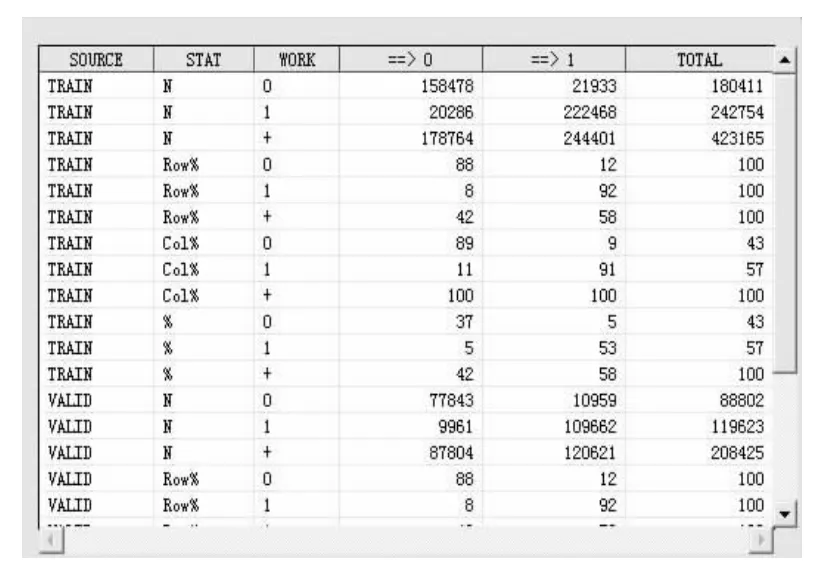
图3 混淆矩阵图

图4 Gini系数均方误差曲线图
如图5所示为流失预测的树状图,显示决策树深度为3,从顶部开始,直到获得了最佳分类结果时才停止分支,当其达到最佳结果并且获得了按同一规则分类的客户时,便会在底部出现叶子节点。每个叶子节点的产生所依据的最重要的变量依次为[9]:客户平均每个月的总消费(MB_TOTAL_FEE)、月均本地通话次数(CS_LOCAL_COUNT)和月均新业务费(MB_NEW_FEE)等。
下面根据图5所显示的规则,结合聚类分析模型的应用来说明被分类为流失客户的一个分支节点,流失客户基本上具备以下特点:
(1)平均每个月的总消费小于 0.015元,流失概率为94.5%;
(2)平均每个月本地通话次数小于 0.125,流失概率为95.2%;
(3)平均每个月的新业务费小于 6.25元,流失概率为96.0%。
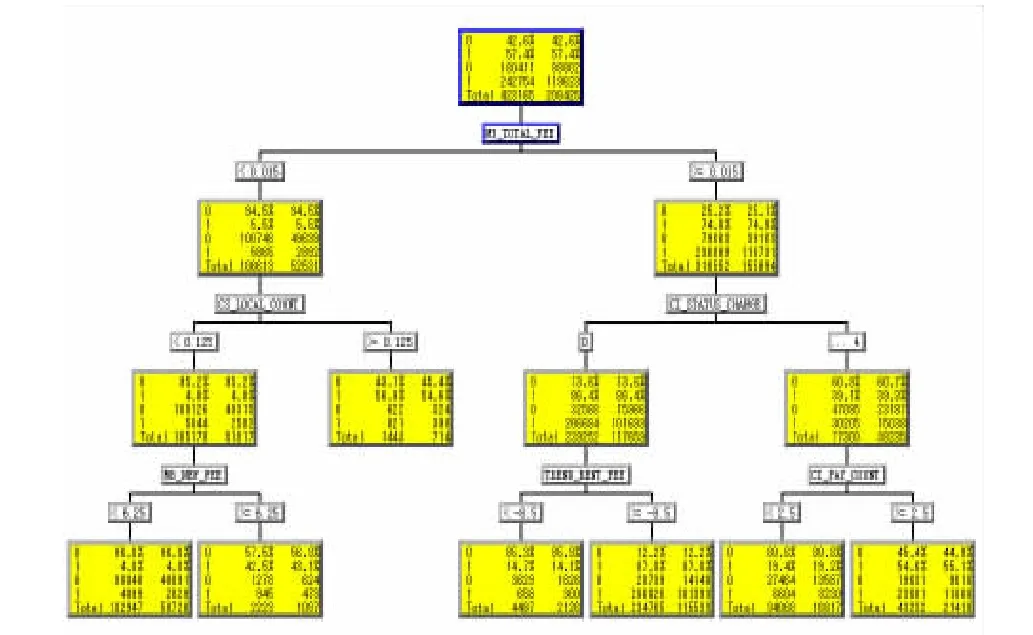
图5 流失预测模型的树状结构图
3 模型的评估与应用
从预测模型的目标分类来看,目标客户主要分为2类(正常客户和流失客户),应用CART算法来进行流失预测分析,那么Gini系数的最大值为0.5。理想的分类应该尽量使样本输出变量取值的差异性总和达到最小,即“纯度”最大,也就是使得输出变量的取值差异性下降最快,“纯度”增加最快。从图4所示的Gini系数均方误差曲线图来看,曲线的下降速度很快,而且Gini系数的均方误差取值很小,也就是说,建立的流失预测模型性能很好,接近理想的分类。
对已知客户状态的数据利用模型来进行预测分析,将得到的预测结果和实际客户的状态进行对比,可以计算出预测的准确度。流失预测模型的评估结果如图6所示,计算出准确度为 96.8%,从整个模型的预测结果和评估结果来看,建立的客户流失预测模型比较接近理想模型,具有一定的实践意义。
4 结束语
本文应用数据挖掘技术,采用聚类分析和决策树分类算法对电信行业中的客户流失情况进行了分析。利用SAS/EM模块,在建立了分类模型后,应用 CART算法建立了客户流失预测模型,结合2种模型的预测结果,对流失客户所具备的基本特征做了总结,并且对建立的流失预测模型进行了评估测试和优化。建立的这套完整的模型改进了现有流失预测模型缺乏灵活性、难以处理大规模高维度数据的缺陷,有效地提高了模型的准确性(准确性高达 96.8%)和普遍应用性。

图6 流失预测模型的评估结果
[1]刘飞.我国通信企业客户流失预测研究综述[J].企业科技与发展,2011(7):273-275.
[2]夏国恩.客户流失预测的现状与发展研究[J].计算机应用研究,2010,27(2):151-153.
[3]师江波,胡建华.基于数据挖掘的电信客户流失预测分析[J].山西电子技术,2009(1):48-50.
[4]蒋盛益,王连喜.面向电信的客户流失预测模型研究[J].山东大学学报(理学版),2011,46(5):77-81.
[5]李阳,刘胜辉,赵洪松.数据挖掘在电信行业客户流失管理中的研究与应用[J].电脑知识与技术,2010,6(3):518-521.
[6]吴志勇,戴曰章,鞠传香.数据挖掘在电信客户流失中的应用[J].山东理工大学学报(自然科学报),2007,21 (5):28-31.
[7]蒋盛益,李霞,郑琪.数据挖掘原理与实现[M].北京:电子工业出版社,2011.
[8]杨池然,仲文明,周志勇.SAS9.2从入门到精通[M].北京:电子工业出版社,2011.
[9]MACLENNAN J,Tang Zhaohui,CRIVAT B.Data mining with Microsoft SQL Server 2008(2nd edition)[M].北京:清华大学出版社,2010.
The application of data mining to client churning prediction in telecom
Zhang Xianmei
(School of Industry,Xi′an Siyuan University,Xi′an 710038,China)
Client churning is a serious problem in the development of telecommunication industry,and it has immediate influence to the profit of a company.This paper mainly introduces the whole procession of data mining in client churning of telecommunication.According to the data in the provider′s database,by analyzing and mining the natural attribution and action attribution among the clients,we set up a clustering model and an integrated prediction model,including assessment module,which is based on CART algorithm of decision tree in SAS EM module for client churning.The new model improves the disadvantages of the existed models,such as lack of flexibility,unable to process data with high dimensionality,even shows the essential features of customers lost visually.Using this model can analyse arbitrary datasets effectively and it enhances the generational applicability and the prediction accuracy rate.
client churn;data mining;decision tree;CART algorithm;cluster analysis;SAS/EM module;direction model for client churn
TP393
A
1674-7720(2015)15-0099-04
张线媚.数据挖掘在电信行业客户流失预测中的应用[J].微型机与应用,2015,34(15):99-102.
2015-04-08)
张线媚(1987-),女,硕士,助教,主要研究方向:无线传感器网路及计算机应用、数据挖掘。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
现代园艺(2018年3期)2018-02-10 05:18:17
电力与能源(2017年6期)2017-05-14 06:19:37
中国市场(2016年44期)2016-05-17 05:14:40
新校长(2016年8期)2016-01-10 06:43:59
信息通信技术(2015年6期)2015-12-26 01:16:46
现代企业(2015年4期)2015-02-28 18:48:49
当代教育论坛(2014年1期)2014-11-10 02:42:58
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
