
Fuzzy-Based Knowledge Discovery from Heterogeneous Data in Planting Systems for Elderly LOHAS
2015-06-01 09:59:24HungChihHsuehJungYiJiangJenShengTsaiWenHaoTsaiKuanRongLeeandYauHwangKuo
Hung-Chih Hsueh, Jung-Yi Jiang, Jen-Sheng Tsai, Wen-Hao Tsai, Kuan-Rong Lee, and Yau-Hwang Kuo
Fuzzy-Based Knowledge Discovery from Heterogeneous Data in Planting Systems for Elderly LOHAS
Hung-Chih Hsueh, Jung-Yi Jiang, Jen-Sheng Tsai, Wen-Hao Tsai, Kuan-Rong Lee, and Yau-Hwang Kuo
—In this paper, we propose a knowledge discovery method based on the fuzzy set theory to help elders with plant cultivation. Initially, the fuzzy sets are constructed by using the feature selection and statistical interval estimation. The min-max inference and the center of gravity defuzzification method are then used to output a candidate pattern set. Finally, a pattern discovery is adopted to obtain the patterns from the candidate set for the cultivation suggestions by considering the frequency weight and user’s experience. In order to demonstrate the performance of our method in planting systems, we conduct a clicks-and-mortar cultivation platform, namely Eden Garden, for the elderly lifestyles of health and sustainability (LOHAS). The experimental results show that the accuracy rate of our knowledge discovery method can reach up to 85%. Moreover, the results of the LOHAS index scale table present that the happiness of the elders is increasing while the elders are using our proposed method.
Index Terms—Elderly LOHAS, fuzzy set, heterogeneous datalifestyles of health and sustainability.
1. Introduction
The World Health Organization reports that the proportion of the world population over 60 years old will reach 20%. Active aging, which is a process to enhance the health, participation, and security as people age, has become more and more important for aging population. There have been many active aging systems proposed for elders toparticipate leisure activities and lifelong learning that improve the health vitality and life quality of the elder. For example, the TV-based systems[1],[2]were developed for elders to play and learn by community interaction. In [3]-[5], the authors presented the smart home that provides health monitoring and the assistance for elders living independently at home. In [3], the authors designed the services to facilitate social interaction, which aims to reduce the negative impacts on elderly health status in their retirement life.
In order to help the elders use the active aging systems, it is necessary to provide the user-friendly interface and control suggestion services. However, it is not easy to give the good control suggestion since there are a lot of heterogeneous data generated from the systems. In [6], the authors addressed that the heterogeneous data, such as the naming difference, value difference, type difference, schema difference, and those heterogeneity of the structure and format, are difficult to analyze. Therefore, it is important to develop a method to offer the control suggestion for the active aging systems from the heterogeneous data. It has been discussed in different research fields like data exchange[7], information fusion[8],[9], and data integration[10],[11].
In this paper, a knowledge discovery method based on the fuzzy set theory is proposed to help elders with plant cultivation. We use the feature selection and statistical interval estimation to design the fuzzy sets. The min-max inference is adopted for the fuzzy inference procedure. The center of gravity defuzzification method is then applied to generate a candidate pattern set. Finally, we use the frequency weight and user’s experience to determine the patterns from the candidate set for the cultivation suggestion. In order to evaluate the performance of the proposed method in planting systems, a clicks-and-mortar cultivation platform is conducted, named as Eden Garden, for the elderly lifestyles of health and sustainability (LOHAS). The LOHAS index scale table is also used to evaluate the efficiency of our proposed method. The experimental results demonstrate that the accuracy rate of our knowledge discovery method is up to 85%. Moreover, the happiness of the elders is increasing by using our proposed method.
The rest of this paper is organized as follows. The details of the fuzzy-based knowledge discovery method are presented in Section 2. The Eden Garden is introduced to evaluate our method in Section 3, and the experimental results are also given in Section 3. Finally, the conclusion remarks are drawn in Section 4.
2. Fuzzy-Based Knowledge Discovery Method
The procedure of the knowledge discovery method, which consists of the fuzzy knowledge, inference engine, and defuzzification, is illustrated in Fig. 1.

Fig. 1. Procedure of the fuzzy-based knowledge discovery.
2.1 Fuzzy Knowledge
The general knowledge extraction methods were considered about key-word association, morpho-syntactic categories of words and latent semantic in the documents[12]-[14]. Those purposed methods were all considered about textual contents in documents, but they did not find some implicit knowledge of textual contents in documents. In the following, we will discuss the feature selection. The key factors for plant cultivation are temperature (T), humidity (H), and light (L). Feature selection is an important step to identify the nominal features and numerical features because the factors are depicted in text or numeric. We define the nominal features and construct the expert table with the term-value relation. The nominal features and numerical features are selected from the input data. Each nominal feature is assigned with a value or an interval according to its original description in the data. However, we find some missing values. In order to ensure the data integrity, we use the common way “case substitution” to deal with the problem.

2.2 Interval Estimation


whereis the table value of student distribution[15],is the sample mean,denotes the estimation ofμ,nmeans the number of samples, and 1-αrepresents the degree of trust.
Finally, we get the (1-α)100% confidence interval as

whereis the lower bound of the interval andis the upper bound of the interval. The statistics interval estimation is used to identify the range of the fuzzy membership function. Theiis a linguistic variable,pis the attribute of fuzzy membership function of the linguistic variable, anddenotes the mode of fuzzy number which is equal to
The fuzzy set design is presented as follows. We define three universal sets as the inference model according to the above procedure. They areT,H, andLas shown in (4), which are mentioned in sub-section 2.1. There are five specific fuzzy sets of each universal set shown in (5) to (9).

2.3 Inference Engine
In the following, we will discuss the degree calculation. According to [16], the term frequency represented the importance of a word or term in the data. But in this paper, to know the importance of each fuzzy variable in the data, we consider the occurrence times as the representative of a fuzzy variable. Let NBs, NSs, ZOs, PSs, and PBs represent the term-value sets of {NB, NS, ZO, PS, PB}. Therefore, the representative of fuzzy variable is regarded as an alpha-cut degree for the fuzzy reasoning process in the fuzzy set. The alpha-cut degree denotes the membership degree of a fuzzy variable, as shown in (10):
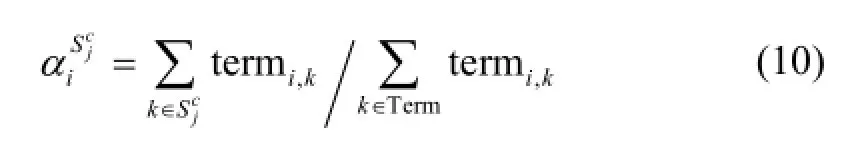

According to the above description, we calculate the occurrence times of each fuzzy variable from each data set and regard it as a membership degree in the fuzzy set. We then perform the fuzzy reasoning process according to the degree shown in (11):

whereαis the membership degree in the fuzzy set andBmeans the fuzzy set of each fuzzy variable. TheB'denotes the inference result of each fuzzy set. After the fuzzy reasoning process, the union ofB'is obtained to infer the final resultB*as shown in (12). The final inference result in the right of Fig. 2 is the union inferring from five fuzzy sets.


Fig. 2. Example of inference results.
2.4 Defuzzification
In order to extract implicit knowledge and generate the candidate pattern, we aim to make fusion of the previous results in this section. The suitable value of the final result can be obtained via the defuzzification process which converts the union fuzzy set into a crisp value. In other words, this crisp value represents the implicit knowledge from the data. We design three universal sets as the inference model, so each data can get three crisp values in this procedure. Finally, we combine the three crisp values as a candidate pattern. In this section, we make the fusion via the center of gravity defuzzification method, as shown in (13):

After defuzzification, a candidate set for suggestions is obtained. And we will find the topksuggestions in the candidate set for users. For this purpose, the pattern frequent weight is proposed as the criteria to determine which candidate pattern is better. The pattern frequent weight in this paper is defined as

where the numerator represents the number of specific patternskin the sample set; the denominator represents the total number of patterns in the sample set.
3. Experimental Results
In order to demonstrate the performance in planting systems, we conduct our method on a clicks-and-mortar cultivation platform named Eden Garden for the LOHAS. Moreover, the LOHAS index scale table is used to evaluate the efficiency of the proposed method.
3.1 System Scenario and Architecture of Eden Garden
The system combines the virtual garden with the reality. Users can directly download the Eden Garden App via the mobile phone or tablet to remotely control the greenhouse. The user interface simulates the physical planted garden by the Android developer and the sensor nodes are taken to realize remote control. Then users can manage an exclusive plant garden through a simple temperature control, watering, and dimming operation interface as shown in Fig. 3 and Fig. 4. The system architecture of Eden Garden is shown in Fig. 5. The knowledge discovery is used for the plant cultivation suggestions. If the application service sends a request to the knowledge discovery service, it will analyze the relevant topic data from the Internet to offer suggestions.

Fig. 3. System scenario of Eden garden.

Fig. 4. Use case of Eden Garden.
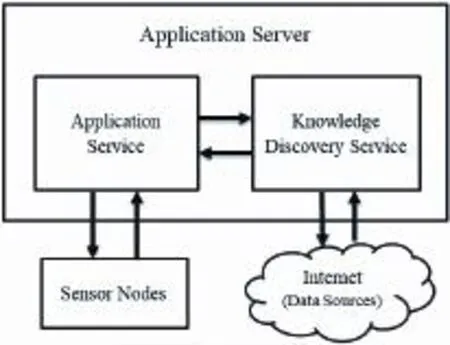
Fig. 5. System architecture of Eden Garden.
3.2 ExpertJudgment
The experimental design is presented as follows. In order to evaluate the effective of the proposed knowledge discovery method, we use the accuracy to assess the effectiveness of the discovery results in this section. In addition, we use the expert judgment results as the validation answers. To begin with the experiment, we invite 40 volunteers to fill in the expert questionnaire shown in Table 1. Those volunteers, who are from the Department of Agronomy and the Department of Horticulture, National Chung Hsing University, have practical experience in agronomic cultivation and expertise in crop science. Therefore, experts determine whether the extraction results of the proposed system with a hybrid data process (complete data and incomplete data) is within the allowable range or not, and then score the judgment results with the 5-point scales (strongly disagree=1, disagree=2, general=3, agree=4, strongly agree=5). Moreover, if experts have a convinced answer after judging the result, they will fill the answer in another option.

Table 1: Example of expert questionnaire
The experiment judgment results of the expert questionnaire are shown in Table 2 and Fig. 6. The results of the expert questionnaire demonstrate that the average expert satisfaction score is more than three points. It means that the temperature, humidity or light are attained a good score of expert satisfaction. According to the Fig. 6, we know that 81% experts agree with the extraction results which are within the allowable range (above general), and 52% experts give positive affirmation of our extraction results (above agree). Only 19% experts think that extraction results are inappropriate (below disagree).

Table 2: Results of expert questionnaire

Fig. 6. Statistical ratio of expert score.
Finally, we adopt the expert judgment result which are within the acceptable range as the validation answers. The allowable range of temperature is set as 2°C, the allowable range for humidity is set as 10%, and that of light is set for 1 h. Then, we can evaluate the accuracy of the following process including the complete data process and hybrid data process (complete data and incomplete data) according to the expert judgment. The experiment results are shown in Table 3.

Table 3: Accuracy of extraction results
According to the results, we find that incomplete data provides the useful information for our model. It enhances the extraction accuracy and confirms that our proposed method can deal with the problem. Furthermore, we adopt the allowable range, and we calculate the average bias by

where the numerator of (15) is the arithmetic difference between the extractive value and the allowable value; the denominator represents the extractive value.
3.3 LOHAS Index Discussion
In this experiment, we assess the mental LOHAS index of elders via the LOHAS index scale table[2]. Moreover, we modify the table[17]to meet our system scenario and present a user experience feedback table which is designed to collect the feedback from the elders. An example of the table is shown in Table 4. The table is modified by the postgraduates of psychology and nursing staff who have psychological research background and more experiences in the elderly health care. And then users fill the table with the 5-point scales (strongly disagree=1, disagree=2, general=3, agree=4, strongly agree=5). According to the two tables, we observe the change of metal index after elders using the Eden Garden system and the users’ perception of the system. There are nine focus groups which include seven males and eight females in this experiment. The age of these members is between 57 and 79. We extend the age range forward to 57 because retirement groups are considered as the potential senior citizens. Each member fills the pre-test of LOHAS index scale table (do not use the system before taking the test) and the post-test of LOHAS index scale table (use the system for two weeks). And each member also fills the user experience feedback table after they experience the system firsthand. Therefore, each member will receive an interview for 1 h to 2 h and we will help them for filling the questionnaire on the side. In particular, for the elders, who live alone or whose physical and mental states are more unsound, we will meet regularly to be concerned with them.

Table 4: User experience feedback table
After the interviews, we get some information about their family situation, physical and mental states. There are twelve elders whose children do not live with them in many years for working, where two elders living alone (one is unmarried and the other is widowed). There are three elders whose children live with them (two elders of them are widowed). About the health and mental status, there are two elders in limited mobility, and there are two elders with bipolar disorder and short amnesia. From the above description, we think that these elders need something to increase their mental index. In addition, the telic theory mentions that everyone has an implicit demand target. When they reach the target, it would bring happiness for them. Therefore, we will observe the change of the LOHAS index through the post-test table, and according to the results to determine whether our system can enhance the mental index of elders or not. Finally, we use the statistical analysis software—Statistical Product and Service Solutions (SPSS) to analyze the pre-test and post-test tables as shown in Table 5 to Table 7. There are fifteen elderly interviewees filling the LOHAS index scale table and we collect fifteen complete LOHAS index scale tables for analysis. The pre-test tables’ reliability is 0.858 for Cronbach’s alpha and 0.885 for Cronbach’s alpha based on standardized items as shown in Table 5. And the post-test tables’ reliability is 0.962 for Cronbach’s alpha and 0.960 for Cronbach’s alpha based on standardized items as shown in Table 6. The standardized terms are given by experts and shown as subject1 to subject42. Cronbach’s alpha is a measure of reliability, when the Cronbach’s alpha is close to 1, the reliability will be better. Table 6 shows that the internal consistency of the LOHAS index scale table is increased after elders use the system.
Moreover, in Table 7, different subjects are the different mental indexes. Take subjects 8 (“I am living without feeling presence”), 16 (“I am important for others”), 17 (“I usually feel happy”), 22 (“I feel that no one can rely on”), and 29 (“I am pleasure to help others”) as the examples. It can be seen that the mental indexes are increasing after using the system according to the subjects 16, 17, and 29 in Table 7, which receive good scores. These subjects describe about the sense of presence (subject 16), intrinsic positive emotions (subject 17), and extraversion (subject 29). And the proposed system also reduces the melancholy of elders according to the subject 8 and 22, which is in the reverse scale (strongly disagree=5, disagree=4, general=3, agree=2, strongly agree=1). In [18], the authors defined that the happiness was made by the overall assessment of life satisfaction and the feelings of positive/negative emotional intensity. The subjects 16, 17, and 29 are the positive emotional assessment results and the subjects 8 and 22 are the negative emotional assessment results (The higher reverse scale score, the lower degree of agree for negative emotion). The post-test LOHAS index scale table denotes the life satisfaction assessment results and Cronbach’s alpha for the post-test LOHAS index scale table is 0.962. Therefore, we can infer that the happiness would raise after users contact with the system according to above descriptive results.

Table 5: Pre-test case processing summary and reliability

Table 6: Post-test case processing summary and reliability

Table 7: Analysis results of post-test of LOHAS index scale table
Furthermore, we observe the users’ perception of the system through user experience feedback table. The simple descriptive statistics are shown in Table 4. According to the results, we know that a large majority of elders respond positively (above agree) to the survey questions “Do you enjoy the contact with Eden Garden?”, “Do you like to participate in group activity with Eden Garden?”, “Does Eden Garden make you feel better?”, “Do you think Eden Garden can improve your daily life?”, and “Do you feel relaxed operating to Eden Garden?”. About the questions“Do you enjoy the contact with Eden Garden?” and “Do you feel relaxed operating to Eden Garden?”, we find that most of elders feel fresh and is interested in Eden Garden. About the questions “Does Eden Garden make you feel better?”and “Do you think Eden Garden can improve your daily life?”, most of elders feel that Eden Garden can pass their boredom time of day, and explore the fun of operating game. These elders even think Eden Garden is might be a part of their life in question 7. In particular, the answer to the question “Do you like to participate in group activities with Eden Garden?” shows that most elders like to interact with their friends in Eden Garden and 80% of the elders respond that the favorite service in Eden Garden is chat. And 60% of the elders respond positively to the question “Do you enjoy one to one activity (e.g. plant cultivation suggestions) with Eden Garden?”, because they think that plant cultivation suggestions are useful when they play the plant cultivation game by themselves. And 40% elders respond with“General”, because they are not interested in plant cultivation. However, 20% of the elders respond negatively (below disagree) to the question “Are you comfortable with Eden Garden?”, because some of them are illiterate, so they feel anxious about the textual interface. And 67% elders respond negatively (below disagree) to the question “Do you feel concerned with the presence of Eden Garden?”, because they think that the tablet is approachable and simple to operating. Further, we evaluate our knowledge discovery service benefits for elders according to the questions “Do you think Eden Garden can improve your daily life?” and“Do you think that if there are no plant cultivation suggestions, it will cause the cultivation fail rate to increase?”. And we can observe that nearly 60% of the elders think that the knowledge discovery service can affect the plant yield results when they play the game. Wherein the question “Do you think if there are no plant cultivation suggestions, it will cause the cultivation fail rate to increase?” is responded with a higher score, because they will feel helpless and even do not know how to proceed with the cultivation when the system does not provide any guide. Most of the elders respond positively to the last question, because most elders believe that plants grow well will bring them a great accomplishment.
4. Conclusions
In this paper, a fuzzy-based knowledge discovery method for heterogeneous data is proposed to help elders with plant cultivation. We also realize our proposed method on a clicks-and-mortar cultivation platform for elderly LOHAS. The experimental results demonstrate that the accuracy rate of our knowledge discovery method can reach up to 85%. The results of the LOHAS index scale table denote that the elders’ happiness is increasing by using the platform. In the future, we will extend the proposed method to various active aging systems for improving the life quality of the elders.
[1] S. Chen, B. Mulgrew, and P. M. Grant, “A clustering technique for digital communications channel equalization using radial basis function networks,”IEEE Trans. on Neural Networks, vol. 4, pp. 570-578, Jul. 1993.
[2] A. I. G. Martínez, A. L. Morán, and E. H. C. Gámez,“Towards a taxonomy of factors implicated inchildren-elderly interaction when using entertainment technology,” inProc. of the 4th Mexican Conf. on Human-Computer Interaction, New York, 2012, pp. 51-54.
[3] M.-H. Fu, K.-R. Lee, M.-C. Pai, and Y.-H. Kuo, “Clinical measurement and verification of elderly LOHAS index in an elder suited TV-based home living space,”Journal of Ambient Intelligence and Humanized Computing, vol. 3, no. 1, pp. 73-81, 2012.
[4] L. Gibson, W. Moncur, P. Forbes, J. Arnott, C. Martin, and A. S. Bhachu, “Designing social networking sites for older adults,” inProc. of the 24th BCS Interaction Specialist Group Conf., Swinton, 2010, pp. 186-194.
[5] M. Morris, J. Lundell, and E. Dishman, “Catalyzing social interaction with ubiquitous computing: A needs assessment of elders coping with cognitive decline,” inProc. ofACM CHI’04 Extended Abstracts on Human Factors in Computing Systems, New York, 2004, pp. 1151-1154.
[6] P. Rashidi and D. J. Cook, “Keeping the resident in the loop: Adapting the smart home to the user,”IEEE Trans. on Systems,Man and Cybernetics,Part A:Systems and Humans, vol. 39, no. 5, pp. 949-959, 2009.
[7] L. Lu, “The meaning, measure, and correlates of happiness among Chinese people,” inProc. of the NSC: Part C, 1998, pp. 115-137.
[8] L. Cui, W. Zhang, H. Zhai, X. Zhang, and X. Xie,“Modeling and application of data correlations among heterogeneous data sources,” inProc. of the 2nd Int. Conf. of Signal Processing Systems, Dalian, pp. 413-416, 2010.
[9] S. R. Ganta, J. Kasturi, and J. Gilbertson, “An online analysis and information fusion platform for heterogeneous biomedical informatics data,” inProc. of the 18th IEEE Symposium on Computer-Based Medical Systems.Washington, DC, pp. 153-158, 2005.
[10] B. Wan, L. Yang, M. Hu, and Y. Ye, “An intelligent multilayered middleware model and heterogeneous spatial data fusion application study,” inProc. of Int. Conf. on Environmental Science and Information Application Technology, Wuhan, 2009, pp. 423-427.
[11] M. Dinsoreanu, L. Braescu, and A. Bacu, “Towards a semantic-driven automatic staging area design for heterogeneous data integration,” inProc. of ACM the 14th Int. Conf. on Information Integration and Web-based Applications & Services, New York, 2012, pp. 290-293.
[12] C. Chirathamjaree, “A data model for heterogeneous data sources,” inProc. of 2008 IEEE Int. Conf. on e-Business Engineering, Washington, DC, 2008, pp. 121-127.
[13] M. Rajman and R. Besançon, “Text mining-knowledge extraction from unstructured textual data,” inProc. of the 6th Conf. of Int. Federation of Classification Societies, Roma, 1998, pp. 473-480.
[14] J. Fan, A. Kalyanpur, D. C. Gondek, and D. A. Ferrucci,“Automatic knowledge extraction from documents,”IBM Journal of Research and Development, vol. 56, no. 3-4, pp. 5:1-5:10, 2012.
[15] F. Tian, X.-B. Han, and F.-B. Wu, “The heterogeneous data integration based on XML in coal enterprise,” inProc. of Int. Symposium on Computer Science and Computational Technology, Shanghai, 2008, pp. 438-441.
[16] Thet-distribution table. [Online]. Available: http://www.math.unb.ca/~knight/utility/t-table.htm
[17] G. Salton and C. Buckley, “Term-weighting approaches in automatic text retrieval,”Information Processing & Management, vol. 24, no. 5, pp. 513-523, 1988.
[18] R. Khosla, M. T. Chu, R. Kachouie, K. Yamada, and T. Yamaguchi, “Embodying care in Matilda: An affective communication robot for the elderly in Australia,” inProc. of the 2nd ACM SIGHIT Int. Health Informatics Symposium, New York, 2012, pp. 295-304.
[19] H. Alani, S. Kim, D. E. Millard, M. J. Weal, W. Hall, P. H. Lewis, and N. R. Shadbolt, “Automatic ontology-based knowledge extraction from web documents,”IEEE Intelligent Systems, vol. 18, no. 1, pp. 14-21, 2003.

Hung-Chih Hsueh was born in Changhua in 1988. He received the M.S. degree in medical informatics from National Cheng Kung University (NCKU), Tainan in 2013. From 2011 to 2013, he dedicated to a research of elderly mental care promotion supported by NSC. Now, he is a computer engineer with the Department of Information Technology, United Microelectronics Corporation. His research interests include data mining, machine learning, knowledge discovery, social media, and health care.

Jung-Yi Jiang was born in Changhua in 1979. He received the B.S. degree from I-Shou University, Kaohsiung in 2002. He received the M.S and Ph.D. degrees in electrical engineering from Sun Yat-Sen University, Kaohsiung in 2004 and 2011, respectively. He works as a postdoctoral researcher at the Center for Research of E-life Digital Technology, NCKU, Tainan. His main research interests include machine learning, data mining, and information retrieval.

Jen-Sheng Tsai was born in Changhua in 1981. He received the M.S. and Ph.D. degrees in computer science and information engineering from NCKU, Tainan in 2006 and 2012, respectively. From 2011 to 2012, he was a visiting researcher with Heidelberg Collaboratory for image processing (HCI), Universität Heidelberg, Heidelberg. He is currently a postdoctoral fellow with the Center for Research of E-life Digital Technology (CREDIT) at NCKU. His research interests include multimedia security, multimedia cloud computing, computer graphics, embedded systems, and VLSI design technology.

Wen-Hao Tsai was born in Tainan in 1990. He received the B.S. degree in computer science and iformation engineering from NCKU, Tainan in 2012. He is currently pursuing the M.S. degree with the Department of Computer Science and Information Engineering, NCKU. His research interests include social networkanalytics, intelligent information analytics, and context-aware computing.

Kuan-Rong Lee received the M.S. and Ph.D. degrees in computer science and information engineering from NCKU, Tainan in 1995 and 2006, respectively. He is currently an associate professor with the Department of Computer Engineering, Kun Shan University, Tainan. His research interests include mobile computing, wireless sensor networks, cloud computing, and big-data analytics.

Yau-Hwang Kuo received his Ph.D. degree in computer engineering from NCKU, Tainan in 1988. Currently, he is the Dean of Colleage of Science, National Chengchi University (NCCU), Taipei. He is also the distinguished professor with the Department of Computer Science and Information Engineering, NCKU, and the co-director on ICT-enabled service area of National Networked Communication Program in Taiwan. In his career, Prof. Kuo is persistently active in the fields of academia, education accreditation, and government policy planning. He has served as the Deputy Executive Secretary of Science & Technology Advisory Group in EY, Director of Computer Center, MOE, Director of Computer Science and Information Engineering Program in NSC, and Director of ETPC, NSC. From 1999 to 2000, he was elected as the President of Taiwanese Artificial Intelligence Association. Prof. Kuo has also served as the editor for several international journals, and consulted for several research institutes and hi-tech companies. He has published more than 290 papers and 28 patents. His research topics include wireless broadband communication, cloud computing, computational intelligence, intelligent information analytics, and context-aware computing.
Manuscript received January 6, 2014; revised March 22, 2014. This work was supported by the NSC under Grant No. 100-2221-E-006-251-MY3.
H.-C. Hsueh, J.-S. Tsai, W.-H. Tsai, K.-R. Lee, and Y.-H. Kuo are with the Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan 70101. (e-mail: gangohong@ismp.csie.ncku.edu.tw; asheng@ismp.csie.ncku.edu.tw; whtsai@ismp.csie.ncku.edu.tw; leekr@ismp.csie.ncku.edu.tw; kuoyh@ ismp.csie.ncku.edu.tw).
J.-Y. Jiang is with the Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan 70101 (Corresponding author e-mail: jungyi@ismp.csie.ncku .edu.tw).
Digital Object Identifier: 10.3969/j.issn.1674-862X.2015.01.009
 Journal of Electronic Science and Technology2015年1期
Journal of Electronic Science and Technology2015年1期
- Journal of Electronic Science and Technology的其它文章
- Non-Supervised Learning for Spread Spectrum Signal Pseudo-Noise Sequence Acquisition
- Face Detection under Complex Background and Illumination
- Transformation of Voltage Mode Filter Circuit Based on Op-Amp to Circuit Based on CCII
- An Evolution, Present, and Future Changes of Cloud Computing Services
- Backlit Keyboard Inspection Using Machine Vision
- Efficient Slew-Rate Enhanced Operational Transconductance Amplifier