
基于深度特征学习的藏语语音识别
2015-05-08 00:55刘晓凤徐晓娜许彦敏
东北师大学报(自然科学版) 2015年4期
王 辉,赵 悦,刘晓凤,徐晓娜,周 楠,许彦敏
(中央民族大学信息工程学院,北京100081)
基于深度特征学习的藏语语音识别
王 辉,赵 悦,刘晓凤,徐晓娜,周 楠,许彦敏
(中央民族大学信息工程学院,北京100081)
根据听觉语音学的知识,提出使用稀疏自动编码器在MFCC特征基础上进行深度学习,提取了深度特征模仿听觉神经的稀疏触动信号,有利于HMM模型语音识别精度的提高.实验结果显示,学习到的深度特征较MFCC特征在藏语语音识别正确率方面有明显提高.
深度特征学习;稀疏自动编码器;藏语语音识别;MFCC特征
0 引言
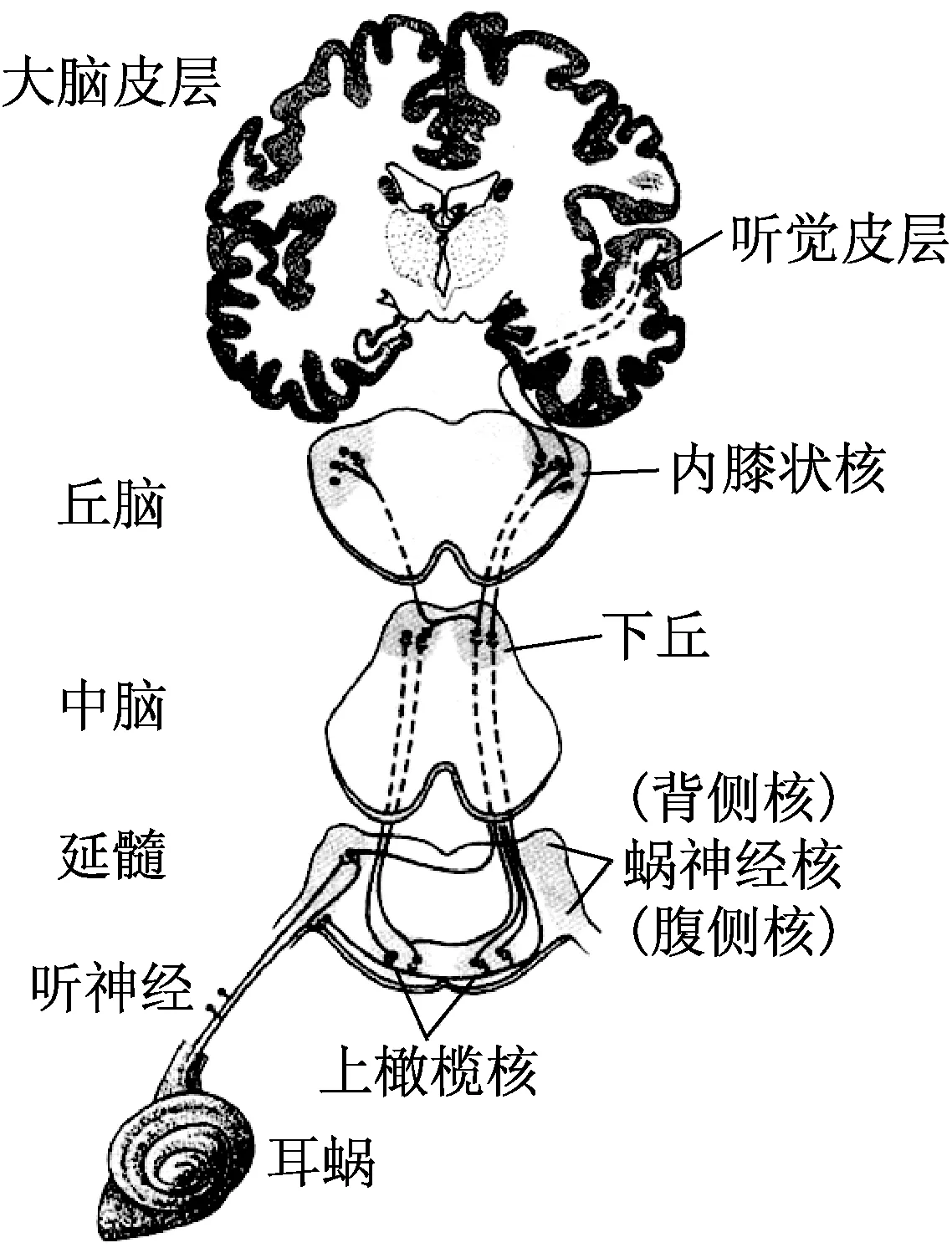
图1 声音传入听觉中枢过程
根据听觉语音学、心理语言学理论及人耳构造知识可知,耳蜗实质上相当于一个滤波器组,耳蜗的滤波作用是在对数频率尺度上进行的;耳蜗中有一个重要的部分称为基底膜,在基底膜之上是柯蒂氏器官,它相当于一种传感装置,耳蜗内的流体速度变化,可影响柯蒂氏器官上的毛细胞膜两边电位变化,在一定条件下造成听觉神经的发放和抑制,最后声音经听神经传入大脑的听觉中枢完成语音的感知功能.[1]其过程如图1所示.
在语音识别研究中,由于美尔倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)模拟了人耳对声音频率的感知,反映了人耳的听觉特性,因此被广泛用来作为语音识别模型的输入特征,而大多数的识别模型采用了HMM (Hidden Markov Model)模型.目前,在藏语语音识别研究中,多数的研究者也是采用了这种浅层学习的建模方法,例如文献[2-4]采用了39维的MFCC特征,构建了藏语拉萨话的音素和声韵母HMM识别模型.浅层模型的一个共性是仅含单个将原始输入信号转换到特定问题空间特征的简单结构[5].考虑到人脑对语音识别的机理,这种浅层语音识别建模并不能模拟出人脑的语音识别机理,主要是未能反映出声音的频率如何转变为听觉神经的触动信号,因此基于浅层学习的语音识别系统的识别率仍有待提高.
尽管人们利用了人工神经网络模拟人脑的语音识别过程[6-7],但是受限于后向传播算法的梯度扩散、学习的局部最优和非稀疏性等问题,它不能够很好地模拟人脑语音识别的过程.
近年来,深度学习方法克服了传统人工神经网络训练中的缺点,采用无监督的学习机制和隐层神经元的稀疏性限制,建立了和模拟人脑进行分析学习的神经网络,更为合理地刻画了人脑的机制来解释数据.[8-10]因此,本文提出使用稀疏自动编码器(sparse auto-encoder,SA)在MFCC特征上进行深度学习,提取深度特征,以模拟声音频率转化为听觉神经稀疏触动信号的过程,即代表人耳听觉特性的MFCC特征,经过稀疏自动编码器转化为稀疏听觉神经信号,最后传入代表听觉中枢的HMM模型,实现语音识别.
本文描述了基于深度特征学习的语音识别系统框架,介绍了一种简单而有效的深度学习方法——稀疏自动编码器,给出了基于深度特征学习的藏语语音识别声学建模算法.
1 基于深度特征学习的语音识别系统
目前,已有的基于MFCC特征和HMM模型的语音识别系统采用了如图2所示的框架.
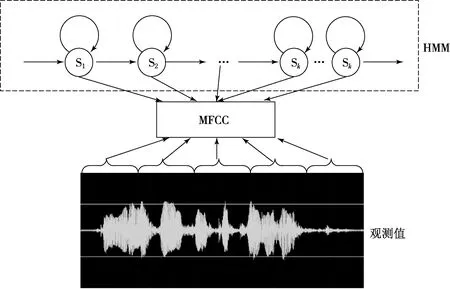
图2 基于MFCC特征和HMM模型的语音识别系统
该系统将语音的MFCC特征作为HMM模型的输入观测特征,建立各个语音类别模型,它属于浅层学习,并没有模拟出人脑分析和解释输入数据的过程.
另一种语音识别方法采用了人工神经网络和HMM模型构建声学识别模型,如图3所示.该系统中神经网络由包括输入层、隐层、输出层组成的多层网络,只有相邻层节点之间有连接,同一层以及跨层节点之间相互无连接,这种分层结构比较接近人类大脑的结构.但是传统的神经网络的训练采用反向传播的方式进行,其迭代训练于整个网络,随机设定初值,计算当前网络的输出,然后根据当前输出和真实类值的差去改变前面各层的参数,直到收敛.这种训练方式的主要缺陷:受初值设定影响较大,容易陷入局部最优和过拟合[11];残差传播到最前面的层会变得太小,出现梯度扩散;隐层神经元的触发不受稀疏性制约,因为人脑虽有大量的神经元,但对于某些声音只有很少的神经元兴奋,其他都处于抑制状态,因此每层神经元的触发信号应该是稀疏的.
本文引入了深度学习机制,通过自下而上的逐层无监督预训练(认知过程)和自上而下的权重调优(生成过程)获取语音输入数据的深度特征,学习避免了传统神经网络陷入局部最优、梯度发散和非稀疏性等问题.深度学习方法让认知和生成达成一致,保证了生成的最顶层表示(高层特征),能够尽可能正确地复原底层的结点(低层特征),也就是说高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现数据的语义或者意图.而抽象层面越高,存在的可能猜测就越少,就越有利于分类.比如顶层的一个结点表示某个字(词),那么所有该字(词)的语音应该激活这个结点,并且这个结果向下生成的语音应该能够表现为一个大概的字(词)语音.本文使用了一种简单而有效的深度学习方法(稀疏自动编码器)来学习深度特征,模拟人脑听觉神经对语音的感知信号,进而再将信息汇集到HMM模型进行语音类别的区分.
基于深度学习的语音识别系统框架见图4,其中深度特征提取器利用稀疏自动编码方法构建,语音类别校验器是基于HMM的语音识别模型.
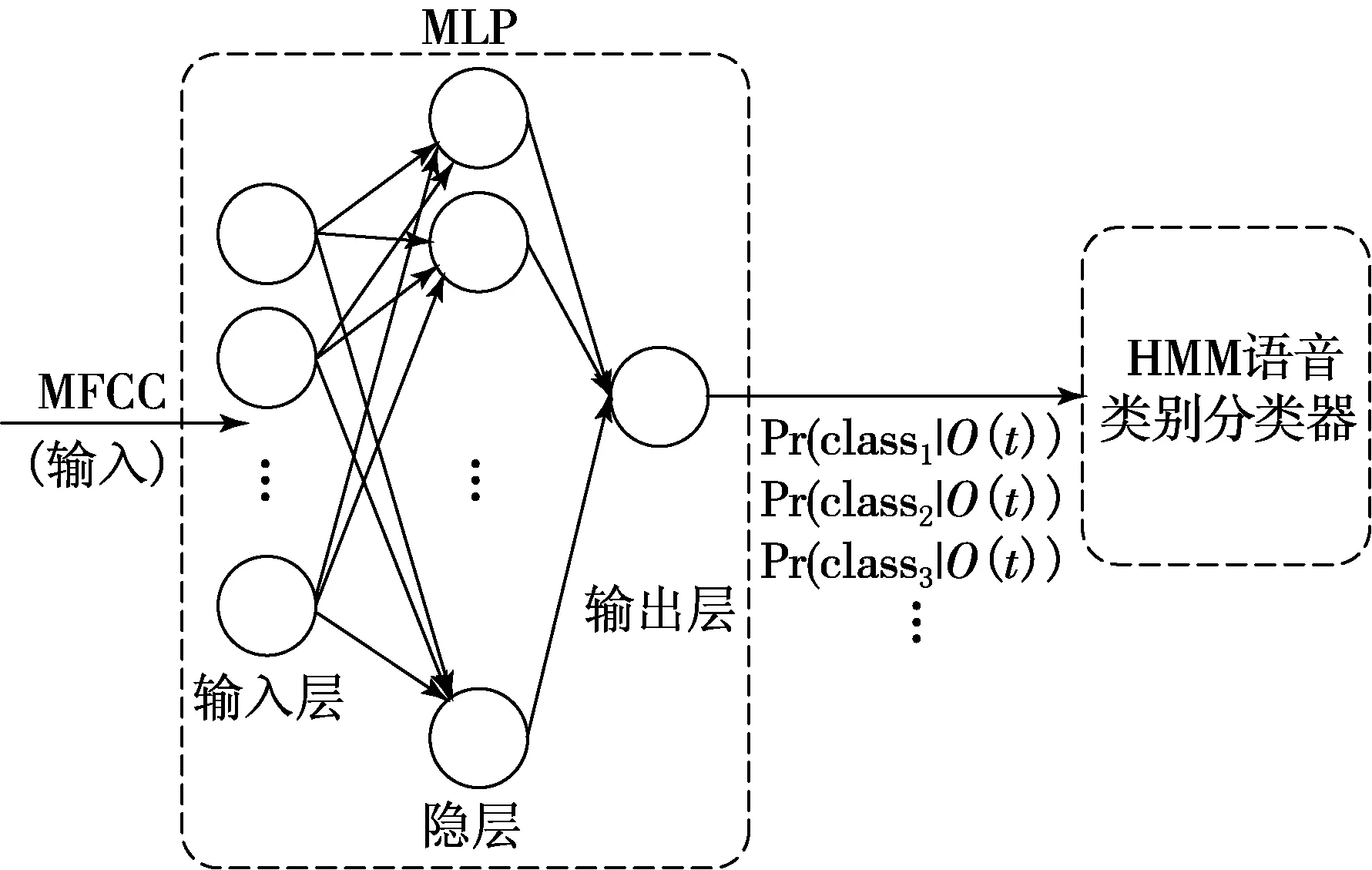
图3 基于MFCC特征、人工神经网络和HMM的语音识别系统
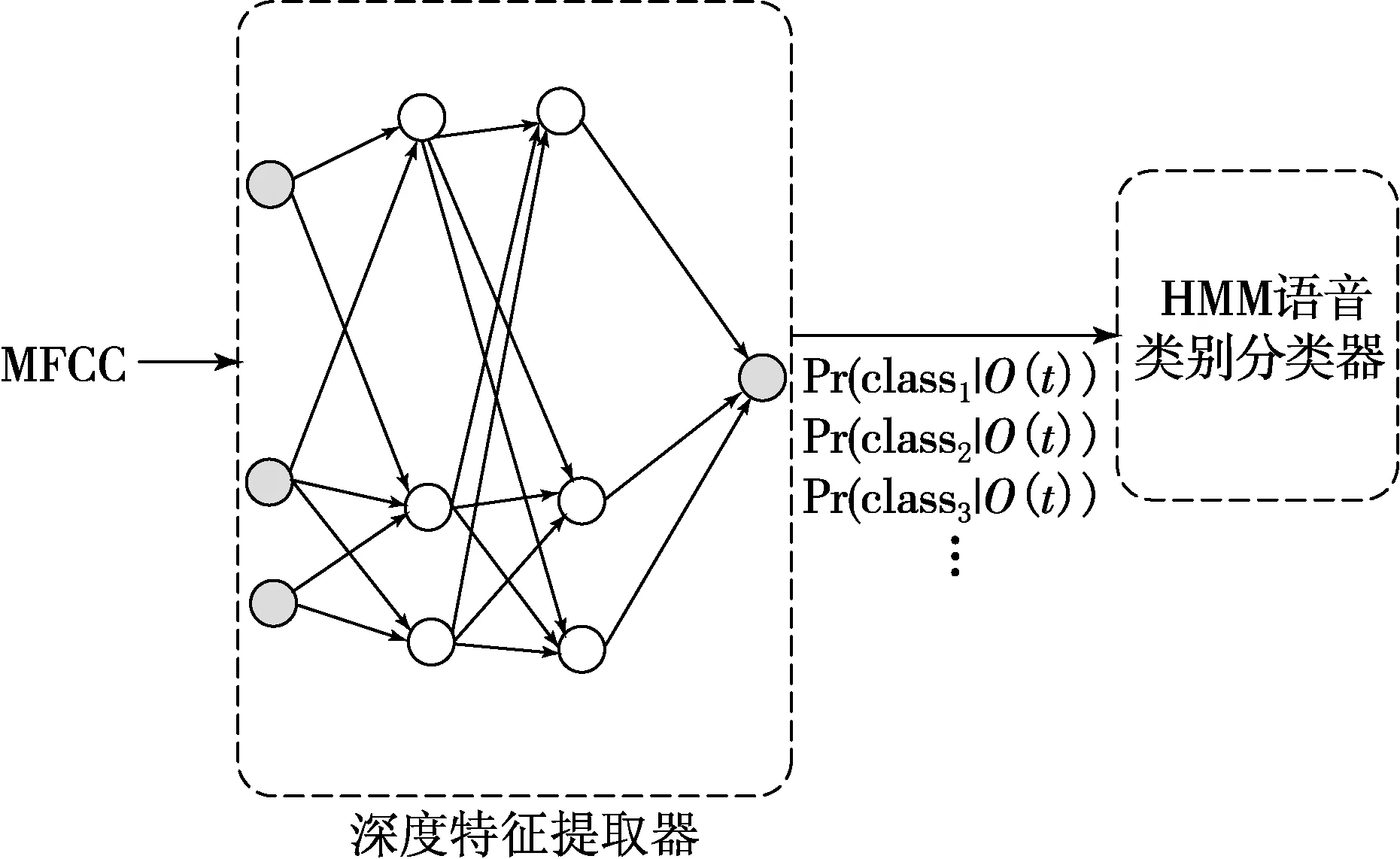
图4 基于深度特征学习的语音识别系统
2 稀疏自动编码器
稀疏自动编码器是一种无监督的学习算法,它让输出值等于输入值.首先介绍只含1个隐层的稀疏自动编码器(见图5),然后再介绍栈式稀疏自动编码器(见图6).
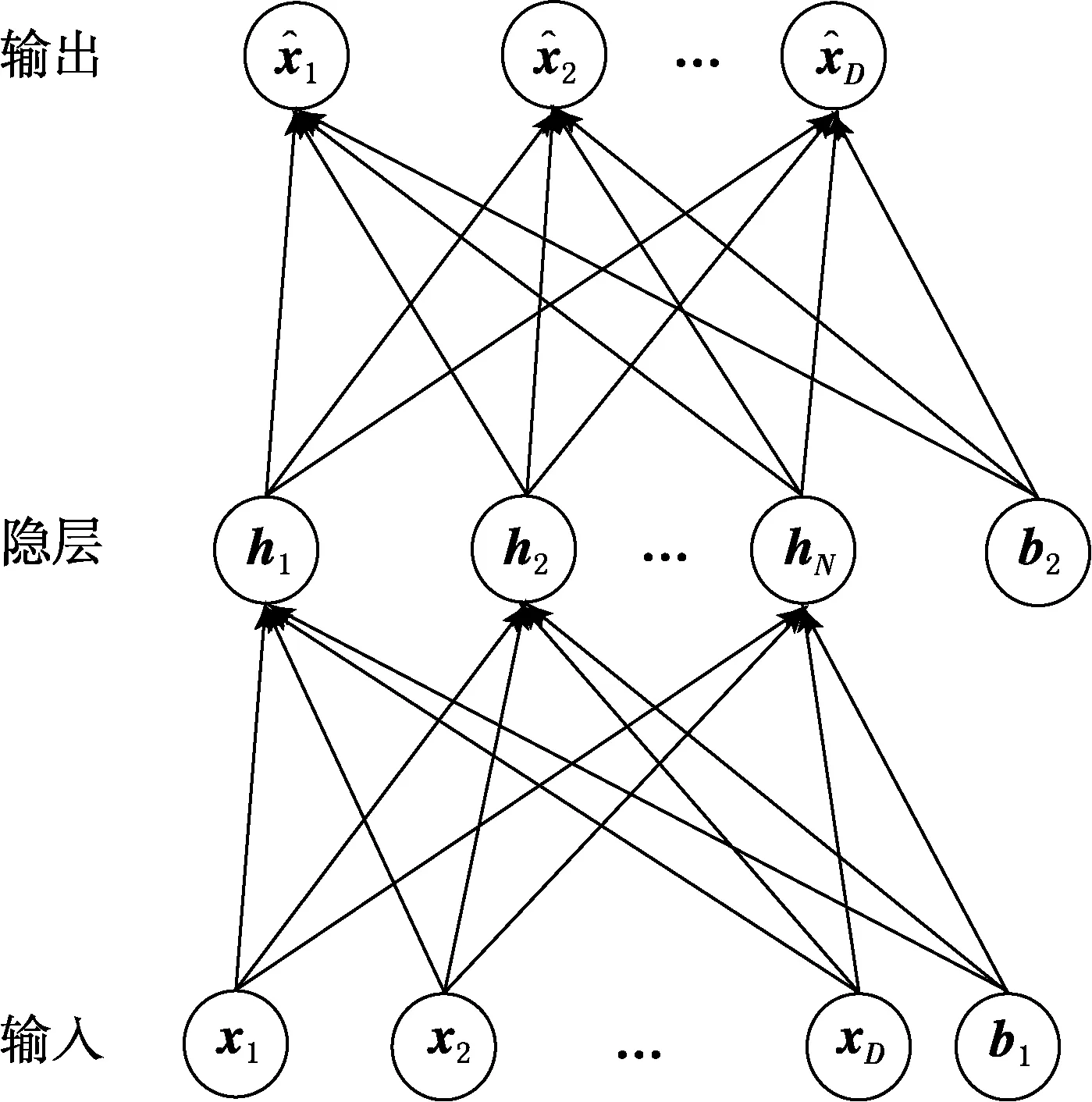
图5 含1个隐层稀疏自动编码器
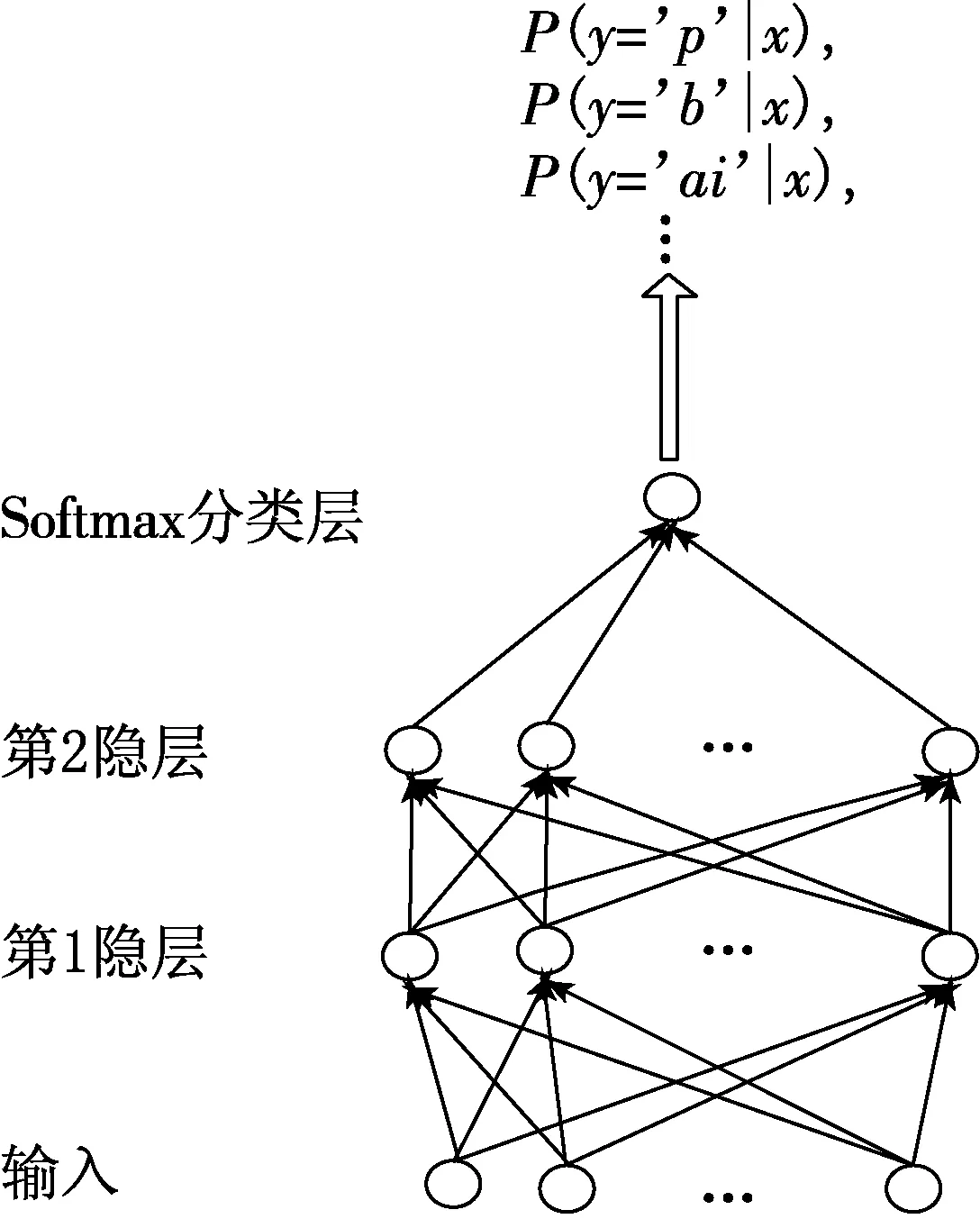
图6 含2个隐层的栈式稀疏自动编码器
设输入向量x∈RD,隐向量h∈RN代表深度特征,输入层和隐层之间的映射关系为
h=σ(W(1)x+b(1)).
(1)
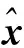
(2)
求得.其中W(2)∈RN×D是解码矩阵,b(2)∈RD为解码偏置向量.新的非线性特征可以通过最小化有稀疏约束网络的损失函数
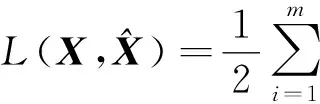
(3)
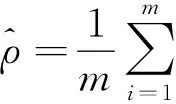
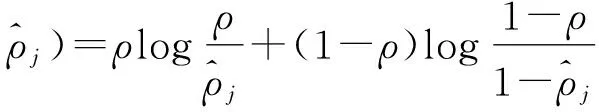
(4)
栈式稀疏自动编码器是由多个单层稀疏自动编码器组成的神经网络,其前一层稀疏自编码器的输出作为后一层稀疏自编码器的输入.对于一个含有n层的栈式稀疏自动编码器,h(n)代表第n层的深度特征.
为了得到更好的实验结果,我们在栈式稀疏自动编码器的最顶层加上一个softmax分类节点,作为语音类别层,将该层的类别后验概率作为学习得到的高层特征输入HMM模型.
3 基于深度特征学习的藏语语音识别声学建模算法
使用逐层贪心训练算法训练稀疏自动编码器的参数,主要有预训练和微调两步.预训练中使用无标签的数据样本,采用无监督的方法训练第1层网络,获得参数W(1,1),W(1,2),b(1,1)和b(1,2),然后网络第1层将原始输入转化成由隐藏单元激活值组成的向量.把上层输出的向量作为第2层的输入,继续训练得到第2层的参数W(2,1),W(2,2),b(2,1)和b(2,2).对后面的各层采用同样的策略,即将前层的输出作为下一层输入的方式依次训练.预训练后,利用带标签的数据,使用后向传播算法对稀疏自动编码器的所有层参数同时进行微调.
利用含2个隐层的栈式稀疏自动编码器模型提取输入语音数据特征的算法描述如下:
(1) 使用无监督的方法,基于输入语音数据U的MFCC特征训练稀疏自动编码器的第1隐层网络参数,并用训练好的参数计算出隐层的输出,将其作为输入语音数据的深度特征h(1);
(2) 把步骤(1)的输出特征h(1)作为稀疏自动编码器第2层的输入,采用步骤(1)同样的方法得到第2层深度特征h(2);
(3) 把步骤(2)的输出特征h(2)输入到softmax分类层,训练softmax分类器,以便输出语音类别的后验概率;
(4) 使用输入数据U的类别标签微调具有两层隐层加softmax分类层的稀疏自动编码器各层参数;
(5) 输出训练好的稀疏自动编码器;
(6) 把原始数据U输入到训练好的稀疏自动编码器,获得语音类别的后验概率输出,然后把后验概率作为HMM模型的输入观测值,训练各语音类别的HMM模型.
4 实验结果
评估了在MFCC特征基础上使用稀疏自动编码器提取深度特征并用于藏语孤立词语音的识别.在实验中比较了MFCC特征、单层稀疏自动编码器、两层稀疏自动编码器和多层感知器神经网络(multi-layer perceptron neural networks,MLP neural netwoks)的输出特征训练HMM模型的识别结果.
本文采用了2个数据集:第1个是34类藏语音素的音频数据集,其中每类音素读7遍,前5遍作为训练数据集,后2遍用于测试,该数据集为无噪音语音数据;第2个是包含270句话的藏语连续语音数据集,从中提取了29类藏语单音素数据进行训练和测试.
所有语音数据的采样频率为8 000 Hz,提取以32 ms为帧长,10 ms为帧移的39维MFCC特征(12维滤波器输出加上一维对数能量及其一阶差分和二阶差分).稀疏自动编码器和MLP输入层含有39个节点,隐层节点数都设为100个,隐层节点为sigmoid型.稀疏自动编码器的稀疏值惩罚度权重β=3,稀疏性参数ρ=0.1,权重衰减系数λ=0.003.表1给出了藏语语音识别的实验结果.

表1 藏语语音识别的正确率 %
从表1的实验结果可以看出,使用MLP在MFCC特征基础上提取的新特征和传统的MFCC特征相比,在识别性能方面有明显地提高.其中,在34个音素数据集上识别率提高了25%;在29类藏语音素数据集上的识别正确率提升了4.22%.然而,使用稀疏自动编码器在MFCC特征基础上提取深度特征进行语音识别的正确率,更高于使用MLP提取新特征识别的正确率.实验证明,与MFCC特征相比,虽然MLP神经网络模拟了人脑的语音识别过程,识别率有了明显提高,但是考虑到其本身存在梯度扩散、非稀疏性等缺点,其识别效果不如深度学习方法.本文使用的稀疏自动编码器在MFCC特征基础上进行深度学习,很好地模拟了人脑听觉神经对语音信号的稀疏触发过程,学习得到的深度特征更能提高HMM模型的语音识别精度.
5 总结
本文应用稀疏自动编码器提取深度语音特征,在藏语孤立词语音识别应用的实验中,这种深度学习方法提取的语音特征比MFCC特征和MLP特征能更好地模拟声音频率信号转化为听觉神经稀疏触动信号,使语音识别模型的性能有了进一步地提升.
以后我们将使用更大规模的数据集,测试藏语连续语音识别的准确率,进一步验证语音深度特征学习方法的有效性.
[1] 韩纪庆,张磊,郑铁然. 语音信号处理[M]. 北京:清华大学出版社,2013:11-12,24-25.
[2] 裴春宝. 基于标准拉萨语的藏语语音识别技术研究[D].拉萨:西藏大学,2009.
[3] MENG MENG.藏语拉萨话大词表连续语音识别声学模型研究.[J].计算机工程,2012,38(5):189-191.
[4] 徐慧. 基于隐马尔科夫模型的拉萨话语音拨号技术研究[D].西北民族大学,2013.
[5] MORGAN N,BOURLARD H. Continuous speech recognition[J]. Signal Processing Magazine,1995,12(3):24-42.
[6] DEDE G,SAZLI M H. Speech recognition with artificial neural networks[J]. Digital Signal Processing,2010,20(3):763-768.
[7] FU G. A novel isolated speech recognition method based on neural network[C]//Proceedings of the International Conference on Information Engineering and Applications (IEA) 2012,Springer:London,2013:429-436.
[8] SIVARAM G S V S,NEMALA S K,ELHILALI M,et al. Sparse coding for speech recognition[C]//Acoustics Speech and Signal Processing (ICASSP),Texas:IEEE,2010:4346-4349.
[9] AHMADI S,AHADI S M,CRANEN B,et al. Sparse coding of the modulation spectrum for noise-robust automatic speech recognition[J]. EURASIP Journal on Audio,Speech,and Music Processing,2014(1):1-20.
[10] O’DONNELL F,TRIEFENBACH F,MARTENS J P,et al. Effects of architecture choices on sparse coding in speech recognition[M]//Artificial Neural Networks and Machine Learning-ICANN,Springer:Berlin Heidelberg,2012:629-636.
[11] SUN ZHI-JUN,XUE LEI,XU YANG-MING,et al. Overview of deep learning[J]. Application Research of Computers,2012(8):2806-2810.
(责任编辑:石绍庆)
Deep feature learning for tibetan speech recognition
WANG Hui,ZHAO Yue,LIU Xiao-feng,XU Xiao-na,ZHOU Nan,XU Yan-min
(School of Information Engineering,Minzu University of China,Beijing 100081,China)
HMM models based on MFCC features are widely used by researchers in Tibetan speech recognition. Although the shallow models of HMM are effective,they cannot reflect the speech perceptual mechanism in human beings’ brain. In this paper,It is proposed to apply sparse auto-encoder to learn deep features based on MFCC for speech data. The deep features not only simulate sparse touches signal of the auditory nerve,and are significant to improve speech recognition accuracy with HMM models. Experimental results show that the deep features learned by sparse auto-encoder perform better on Tibetan speech recognition than MFCC features and the features learned by MLP.
deep feature learning; sparse auto-encoder; Tibetan speech recognition; MFCC features
1000-1832(2015)04-0069-05
10.16163/j.cnki.22-1123/n.2015.04.015
2014-12-12
国家自然科学基金资助项目(61309012);教育部人文社科基金资助项目(12YJA630123);中央民族大学一流大学一级学科资助项目.
王辉(1961—),男,教授,主要从事机器学习、数据挖掘、语音识别研究.
TP 391;TN 912.34 [学科代码] 520·20
A
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
客联(2022年2期)2022-04-29
学苑创造·A版(2022年3期)2022-03-29
童话世界(2020年17期)2020-07-25
商洛学院学报(2020年4期)2020-07-08
人民珠江(2019年4期)2019-04-20
铁路计算机应用(2018年5期)2018-06-01
西藏研究(2017年3期)2017-09-05
初中生世界·七年级(2017年5期)2017-06-10
西藏研究(2016年5期)2016-06-15
