
MR—DC:基于MapReduce的轻量级数据压缩策略
2015-04-29 00:59:18田波丁祥武
智能计算机与应用 2015年1期
田波 丁祥武

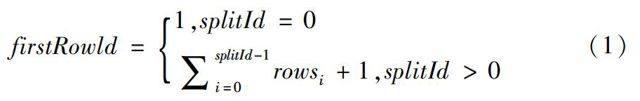

摘 要:大数据平台Hadoop为追求通用性,牺牲了对结构化大数据的处理性能。为此,提出了一种Hadoop平台上的针对结构化数据的压缩存储策略。首先,针对多种不同的数据类型,结合轻量级压缩算法的特点,设计了多种数据类型的压缩数据页;然后,设计了基于HDFS的页式行列混合存储结构;最后,设计并实现了基于MapReduce的MR-DC数据压缩策略,将数据压缩存储到设计的存储结构中。在大规模数据仓库基准数据集上的实验结果验证了提出的策略能够显著减少结构化数据的存储量,从而为提高后续的数据分析处理性能打下基础。
关键词:数据压缩;Hadoop;压缩数据页;行列混合存储结构
中图分类号:TP311 文献标识码:A 文章编号:2095-2163(2015)01-
Abstract: Taking account of generality, the big data platform Hadoop sacrifices process performance for structured data. This paper presents a data compression strategy based on Hadoop for structured data. Firstly, considering different data types, combined with characteristics of lightweight compression algorithms, this paper designs a variety of types of compressed data page. Then, the paper proposes the hybrid storage structure of compressed data page based on HDFS. Finally, the paper designs and implements the MR-DC data compression strategy to compress and store big data into the proposed storage structure. Experimental results on large-scale data warehouse benchmark datasets demonstrate the effectiveness of the proposed strategy in reducing the storage amount of structured big data, so as to improve the data analysis processing performance subsequent.
Keywords: Data Compression; Hadoop; Compressed Data Page; Hybrid Storage Structure
0 引 言
信息社会已进入大数据时代,如何高效地存储和分析大数据,给数据驱动型企业带来了巨大的挑战[1]。数据压缩技术充分利用数据冗余,设计巧妙算法对数据进行重新组织或编码,从而减少数据存储量,提高数据的处理效率,是数据分析型应用中重要的研究内容。
列存储技术[2]在物理上将关系中的元组按属性拆分,同一属性的数据连续存储。由于同一属性的数据通常具有较大的冗余,且存储位置物理上相邻,能够极大地提高数据压缩率,减少数据存储量,进而减少查询时的I/O开销,而且提高数据分析应用的查询处理性能。
作为大数据处理领域事实上的标准,Hadoop被广泛应用于存储和处理大规模数据集。Hadoop是MapReduce计算模型的开源实现,并以分布式文件系统HDFS[3]和分布式计算框架MapReduce[4]为核心。HDFS设计的目的是为了存储大数据,但在数据管理领域中十分重要的数据压缩方面,却只提供了通用的压缩算法如DEFLATE、GZip、BZip2、LZO等[5],并且只支持文件级、块级、记录级压缩,而忽略了列存储技术在数据压缩存储方面的优势。MapReduce计算框架对问题采用分治的思想,数据分散到多个DataNode上,多个TaskTracker并行读取数据进行计算,这对大数据处理则更为有效。但MapReduce读取HDFS上的数据时只能整个数据块顺序扫描,读取粒度太大,且读入了大量不必要的数据,延长了Hadoop集群多用户的等待时间。
针对上述情况,本文提出了一种基于MapReduce的轻量级数据压缩策略MR-DC。首先,针对多种不同的数据类型,结合轻量级压缩算法的特点,设计了基于HDFS的多种数据类型的压缩数据页;然后,设计了基于HDFS的页式行列混合存储结构;最后,提出并实现了MR-DC数据压缩策略,将数据压缩存储到设计的存储结构中。基于以上设计,即可达到减少数据量,提高Hadoop对结构化大数据的处理性能之目的。
1 相关工作
1.1数据压缩
在大数据环境下,数据仓库应用需要处理的数据量十分巨大,导致了查询时大量的磁盘I/O。但CPU处理速度与磁盘访问发展的不平衡,可使得磁盘I/O成为查询处理的性能瓶颈。而数据压缩技术减少了数据存储量,相比之下,读取压缩后的数据显然能够减少磁盘I/O次数,从而能够提高查询效率。
数据压缩是数据管理领域长期关注的研究内容,压缩能够减少数据存储量,节省I/O带宽,提升I/O密集型应用的处理效率,被广泛应用于文本、图像、音频、视频等数据。常用的压缩算法很多[6-8],如字典编码、游程编码、空值压制、位图编码、增量编码、LZ系列编码等。主流的基于行存储的RDBMS如Oracle、IBM DB2、Microsoft SQL Server等主要采用字典编码、空值压制等方法实现压缩。在列存储系统中,同一列的数据存储在物理上相邻的位置,对其进行压缩取得了更好的压缩率。典型的列存储数据库系统如C-Store[2]等主要采用字典编码、空值压制、游程编码等进行压缩。
然而,不同的数据类型适合的压缩方法不同,即使是同一列的数据,其数据分布特征也影响到压缩的效果。因此,对压缩策略选择的研究也随着压缩技术的发展而获得了重大进展。在压缩策略选择上,Abadi等人通过建立决策树[8]的方式,判定一列数据选用何种压缩算法;文献[7]则提出了一种区级压缩模式下的基于学习的压缩策略选择方法,同时考虑数据类型和数据的局部分布特点,对不同列甚至同一列不同分区的数据采用不同的压缩算法,取得了较好的效果。
1.2行列混合存储结构
2001年,Ailamaki提出了PAX (Partition Attributes Across)技术[9],将大的数据块切分为多个小数据区,每个数据区存储表中一个属性列的值,提高了查询的效率。Abadi等人提出并实现了C-Store[2]存储架构,数据在底层采用列存储方式,而上层查询按照行存储的方式执行,存储层和查询层之间则借助Tuple Mover实现数据迁移。孙林超等人通过研究列存储技术的特点,提出了一种行列混合存储[10]数据库系统的设计方案,在存储层设计独立的行存储引擎和列存储引擎,采用早物化技术,在数据读出来之后,将列表转换为行表,再以行的形式完成后续处理。He等人提出了基于HDFS的RCFile[11]存储结构,一张表的数据被水平划分后依次存储在多个HDFS block,每个block内数据被再次水平划分,存储到多个行组,每个行组存储若干行数据,行组内数据采用列存储的方式进行存储。
行列混合存储结构结合了行存储和列存储各自的优点。与列存储相比,混合存储结构保证了一条记录在一个存储单元内,因而避免了元组重构时数据跨网络节点传输,并且能够减小查询开销;与行存储相比,混合存储结构局部仍然采用列存储,能够避免无关列的读取,因而能够加快查询处理速度。
2MR-DC数据压缩策略
2.1页式行列混合存储结构
HDFS将数据按大的数据块来组织,默认情况下,MapReduce计算框架将整个数据块作为输入分片来进行处理。Hive的行列混合存储格式RCFile引入了行组的概念,将行组作为基本的数据存储单元,但在对数据的压缩上,只采用了单一的GZip压缩算法来压缩所有列,而未能考虑数据类型和分布特征。为此,研究考虑将压缩数据页存储结构引入到HDFS,使得HDFS块上的数据按页组织,这样在每个块上可以对不同列的数据采用不同的压缩算法,不同列的数据存储在不同数据类型的压缩数据页中。由于页结构的引入,可以方便地为列值关联对应的rowId,这是RCFile所不具备的。
基于以上考虑,文中设计了基于HDFS的压缩数据页行列混合存储结构。基本的思路是,先将一张大表的数据按行划分,然后将每个划分的数据选择合适的轻量级压缩方法进行压缩,并将压缩数据存储到设计的压缩数据文件中。在每个压缩数据文件中,数据按列的顺序依次存储到相应类型的连续多个压缩数据页中。每个压缩数据文件大小略小于HDFS块大小,保证可以存放在一个HDFS块中。压缩数据文件的存储组织结构为页式行列混合存储结构,如图1所示,首先存储压缩数据文件头页,然后依次存储第一列、第二列直至最后一列的数据,每列数据对应连续若干个压缩数据页。
压缩数据文件头页中存放该压缩数据文件的元数据信息,主要有元数据头信息(MetaDataHeader)、与页相关的元数据信息(PagesMataData)、与列相关的元数据信息(ColumnsMetaData)、与字典相关的元数据(DictionariesMetaData)和与位图相关的元数据(BitMapMetaData)等。压缩数据页主要用于存放压缩状态的数据,元数据(MetaData)部分存放该页的起始行号(firstRowId)、行数(rowsNum)、数据类型(dataType)、占用字节数(itemLen)、是否压缩(isCompressed)、压缩方法(CompressMethod)以及剩余空间(freeSpace)等信息,而数据Data部分存放了该页存放的压缩数据。由于页通常不是恰好装满,因此需要进行填充,Fill中保存的是freeSpace字节大小的0。
在本文设计的压缩数据文件存储结构中,定位到任意数据页或者读取任意一页中指定索引位置的数据的时间复杂度均为O(1)。在查询操作时,一旦确定了选中的RowId集合,即可根据压缩数据文件头页的元数据信息,快速过滤掉不需要的页。在大数据环境下,减少大量不必要的磁盘I/O显然能够显著提升查询的效率。
不同的数据类型适用的压缩算法不同,压缩后的数据表现形式也不尽相同,故针对每种数据类型,设计了相应类型的压缩数据页存储结构。这些数据页包括CompressedCharDataPage、CompressedVarCharDataPage、CompressedIntDataPage、CompressedLongDataPage、CompressedFloatDataPage、CompressedDoubleDataPage、CompressedDateDataPage。
2.2MR-DC数据压缩策略
本小节主要研究如何将已有的数据压缩算法应用到3.1节设计的页式行列混合存储结构上。为此,首先研究了一些常见的轻量级数据压缩算法,然后设计了将数据按照已有的压缩算法压缩后存储到压缩数据页的算法,并在此基础上提出并设计了MR-DC数据压缩策略,包括两个阶段。
阶段1主要的任务是确定出每个划分中的行数,并为每行数据关联对应的RowId。该过程使用MapReduce实现。Map任务统计对应的Input Split中记录的行数,输出键值对为(splitId, rows)对,Reduce任务将键值对结果输出到HDFS上。这样,当后续MapReduce任务处理任意输入分片时,该split中的firstRowId的计算公式为:
阶段2主要的任务是数据压缩、压缩数据文件组装、持久化。分别对应到MapReduce作业的Map、Reduce、OutputFormat三个处理阶段。具体地,Map任务的主要工作是读取数据,调用相应的压缩算法,对数据按列进行压缩,对每列数据输出多个压缩数据页。根据预处理阶段的输出结果,容易计算当前Map所处理的输入分片的firstRowId,从而为每个记录关联真实的RowId。Reduce任务的主要工作是将Map压缩好的数据页整理、组装成一个完整的压缩数据文件并输出,OutputFormat负责将组装好的压缩数据文件持久化到HDFS上。基于MapReduce的数据压缩的Map过程的伪代码描述如算法1所示。
算法1大体上分为两个阶段,数据项的按列收集和多个列的相应页链的压缩,分别对应步5~11和步12~19。步2从HDFS上读取表的相关元数据信息,步4初始化数据项集合,为每一列创建一个对应数据类型的数据项链表,步5~11循环将每一行的数据收集到对应的数据项链表上。步14通过自学习,确定该列适合的压缩算法,对压缩方法的选择算法参考文献[7-8]。步15将该列的数据按上一步确定的压缩算法进行压缩,返回压缩数据页链表,步17则将压缩后的数据页链中的页依次写到输出中。
Map和Reduce之间的Partition过程,其输入是Map的输出,输出是Reduce的输入,作用在于确定将哪些压缩数据页交给一个Reduce处理。本文中Partition的设计策略是将每个Map压缩好的数据页交由一个Reduce处理。当Map任务对数据进行压缩之后,数据通过网络传递给Reduce任务,Reduce任务主要负责收集Map压缩好的数据页,并将其组装成顺序正确的压缩数据文件,而后按照该文件中定义的输出格式将数据写到输出流。数据压缩的Reduce过程的伪代码描述如算法2所示。
步1~3创建相应的空对象作为容器,步6将压缩页依次添加到压缩数据页链中,步7~9对压缩文件头页中相应的元数据状态信息进行更新(update)。例如,每处理一个页,压缩数据文件头页中MetaDataHeader的pageNum将执行加1操作,PagesMetaData中将会增加一条元数据信息记录该页的起始行号和该页的行数;若处理的页是新的列,ColumnsMetaData中将增加一条元数据信息记录该列的列名、列类型、是否压缩、压缩方法等相关信息。步11~12将压缩数据文件头页和压缩数据页链组装成压缩数据文件并输出。
3 实验与分析
3.1实验环境
实验使用的开发环境为Eclipse INDIGO,使用的Hadoop版本为1.0.2,HDFS副本因子设置为默认值3,Hive版本为0.11.0。Hadoop集群采用9台相同配置的节点,其中1台作为NameNode和JobTracker节点,其余8台作为DataNode和TaskTracker节点。各个节点配置均为Intel? Core? i7-3770 CPU@3.40GHz,内存8GB,SATA3硬盘容量500GB,操作系统CentOS 6.4。
实验数据来源于工业界和学术界都普遍采用的大规模基准数据集TPCH。TPCH中共有八张表,其为雪花模式,实验中主要使用的是事实表part表、lineitem表和orders表。实例数据集的大小由增量因子SF控制。当SF=1时,lineitem表的数据量为6 000 000行。
3.2实验结果及分析
3.2.1 压缩算法选择的评估
实验1采用本文提出的压缩策略将part(sf=10)、lineitem(sf=10)、orders(sf=10)三张表压缩后存储到本文设计的压缩数据页行列混合存储结构中,以对压缩方法选择策略进行评估。压缩方法及对应列如表1所示。其中,主要使用了游程编码RLE、位图向量编码BE、简单字典编码SDE、差量编码DE。表中的其他列未压缩。
从表1中看出,本文所提出的对数据分块压缩、在压缩时自动选择合适的压缩算法是行之有效的。这些列的数据分布特征与所采用的压缩算法的适用情形匹配。
3.2.2存储量的比较
实验2采用本文提出的压缩策略将part(sf=10)、lineitem(sf=10)、orders(sf=10)三张表压缩,对比三张表压缩存储时(COMP)占用的存储量和未压缩数据(NONE)占用的存储量。图2给出了三张表在两种策略下的存储量比较结果。
从图2可以看出,三张表的原始数据占用的存储量大约是压缩数据的1.4~2倍。从整张表上看,压缩率并不高,是因为每张表只对其中的部分列进行了压缩。相比之下,Orders表压缩率最低,因为Orders表第9列的取值是字符串类型,该列数据占一条记录数据量的比例很大,但因为是随机取值的字符串而未进行压缩。而其他两张表由于压缩的列数较多,因此压缩后减少的存储量较多。
实验3考察SF=20时,对part表中适合采用轻量级压缩算法进行压缩的第1、3、4、5、7列进行压缩,比较压缩类型为不压缩(NONE)和压缩(COMP)情况下的存储量,图3给出了比较结果。
从图3可以看出,在列的数据分布特征比较明显的情况下,采用轻量级压缩算法对其进行压缩时节省存储空间的效果非常明显,压缩率达到了3.4%~33.2%。第1列未压缩和压缩后每个元素分别占4字节和1字节的空间,因此压缩后存储空间约为原来的25%。第3和4列采用位图编码,压缩率分别为3.4%、32.3%。第5、7列分别使用3个字节和2个字节的字典编码进行压缩,压缩率分别约为14%、20%。
4结束语
本文结合HDFS高扩展性的优点和MapReduce并行计算能力,从减少数据存储量并提高压缩效率的角度出发,设计了基于HDFS的压缩数据页行列混合存储结构,并提出了MR-DC数据压缩策略,将数据压缩存储到设计的页式混合存储结构中。从而能够减少数据的存储量,提高数据分析处理的性能。未来将继续完善本文提出的数据压缩策略,并考虑该存储结构上并行查询的实现,以及对MapReduce 框架进行优化。
参考文献:
[1] 孟小峰, 慈祥. 大数据管理: 概念, 技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-169.
[2] STONEBRAKER M, ABADI D J, BATKIN A, et al. C-store: a column-oriented DBMS[C]//Proceedings of the 31st international conference on Very large data bases. VLDB Endowment, 2005: 553-564.
[3] SHVACHKO K, KUANG H, RADIA S, et al. The hadoop distributed file system[C]//Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium on. New York, USA:IEEE, 2010: 1-10.
[4] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[5] LAI H, XU M, XU J, et al. Evaluating data storage structures of MapReduce[C]//Computer Science & Education (ICCSE), 2013 8th International Conference on. Colombo, Sri Lanka:IEEE, 2013: 1041-1045.
[6] WESTMANN T, KOSSMANN D, HELMER S, et al. The implementation and performance of compressed databases[J]. ACM Sigmod Record, 2000, 29(3): 55-67.
[7] 王振玺, 乐嘉锦, 王梅, 等. 列存储数据区级压缩模式与压缩策略选择方法[J]. 计算机学报, 2010, 8(33): 1523-1530.
[8] ABADI D, MADDEN S, FERREIRA M. Integrating compression and execution in column-oriented database systems[C]//Proceedings of the 2006 ACM SIGMOD international conference on Management of data, New York: ACM, 2006: 671-682.
[9] AILAMAKI A. A Storage Model to Bridge the Processor/Memory Speed Gap[C]/ High Performance Transaction Systems Workshop(HPTS). Asilomar, CA:[s.n.], 2001.
[10] 孙林超, 陈群, 肖玉泽, 等. 行列混合存储数据库系统的研究[J]. 计算机应用研究, 2013, 30(2): 480-482.
[11] HE Y, LEE R, HUAI Y, et al. RCFile: A fast and space-efficient data placement structure in MapReduce-based warehouse systems[C]//Data Engineering (ICDE′11), 2011 IEEE 27th International Conference on. Annover, Germany: IEEE, 2011: 1199-1208.
