
基于分段向量模型的Web医疗咨询数据检索
2015-04-29 00:44:03郭成伟丁祥武
智能计算机与应用 2015年1期
关键词:信息检索
郭成伟 丁祥武


摘 要:Web上存在大量极具价值的医疗咨询数据。本文提出了一种基于分段向量模型的Web医疗咨询数据检索方法。根据Web医疗咨询数据的结构特点构造分段向量模型,然后将咨询数据按此模型表示。对两分段向量,用不同方式计算各分段的相似度,最终通过计算分段相似度加权和的方法产生更加准确的检索结果。在真实Web医疗咨询数据集上的实验结果验证了本文所提方法在提升检索结果准确率方面的有效性。
关键词:Web医疗咨询数据;信息检索;分段向量模型;TFIDF算法;分段加权
中图分类号:TP301 文献标识码:A 文章编号:2095-2163(2015)01-
Abstract: Web medical consultation data of great value is in explosive growth. This paper proposes a Web medical consultation data retrieval strategy based on segmented vector model. Firstly, the paper constructs the segmented vector model in accordance with its own structural characteristics of Web medical consultation data, then represents consultation data using this model. For two segmented vectors, the similarity of each segment is calculated in different ways. Finally, the paper gets more accurate retrieval results by calculating weighted sum of segmented similarity. The experiment results conducted on real world Web medical data sets indicate that the presented strategy can improve the precision of retrieval results efficiently.
Keyword: Web Medical Consultation Data; Information Retrieval; Segmented Vector Model; TFIDF Algorithm; Segmented Weight
0引 言
Web已成为世界上最大的信息数据源,如何从海量Web数据中检索用户感兴趣的信息已成为工业界和学术界日益关注的一个重要研究方向。医疗则一直是与人们切身相关的核心热点话题,时下,即有61%的美国成年人正通过互联网咨询健康建议[1]。另以国内有问必答网为例,每2小时内就会新增近两千条医疗咨询数据。综上分析可知,研究大规模医疗咨询数据的检索技术必将具有重要的应用价值和实际意义。
文本是信息的最重要载体之一,文本相似度计算即是信息检索中的重要手段和实现基础。传统的文本相似度计算方法及其改进算法则是基于向量空间模型[2]的,其中是将每篇文档表示成向量。TFIDF算法[3]就是一种计算文档中词项权重的经典算法,该算法简单有效,然而该算法却仅是统计词项在文档集中出现的频率信息,而忽略了在文档内容标识上发挥重要作用的关键词[4]。同一个词项对不同领域中文档的标识能力不同,以医疗领域为例,与病症、药物相关的词项对文档的标识能力比其它词项更大。在这种情况下,基于TFIDF算法的文本距离度量方法并不能反映文档的真实距离。现举一例如,在语句“服用拉西地平片可能会引发头痛、心悸等现象”中,”拉西地平片”为药物名,”头痛”、”心悸”为症状名,这些关键词项比其它词项将包含更大的医疗信息量,即使词项”服用”或”引发”与关键词具有相同的TFIDF值,但这些词项的重要程度也明显不如关键词。此外,医疗咨询数据还具有一定的结构化特点,如包含性别、年龄、地区、症状描述、药物使用情况等属性项。研究中通过对Web医疗咨询数据进行统计分析,发现不同属性项对检索结果贡献的重要性也各有不同,因此,不能用传统的TFIDF算法计算所有词项的权重。
针对上述问题,本文提出基于分段向量模型的Web医疗咨询数据检索方法。首先,根据Web医疗咨询数据的结构特点,构造分段向量模型,然后将咨询数据按此模型给出明确表示。对两分段向量分别计算对应分段的相似度,最终通过计算分段相似度加权和的方法产生更加准确的检索结果。本文在真实的Web医疗数据集上进行实验,验证了本文所提方法在提升文本相似度准确率方面的实用性和有效性。
本文第1节介绍本文相关工作;第2节详细介绍改进的文本相似度计算模型,包括Web医疗咨询数据的收集、数据预处理、中文分词处理以及算法实现;第3节给出本文所述方法的实验验证;最后是总结和展望。
1相关工作
1.1TFIDF算法及其改进
文本相似度计算过程中特征项的权重计算对结果有较大的影响,TFIDF算法是计算特征项权重的重要算法之一,由Salton[3]首次提出。TFIDF算法的核心思想是:一个词在特定的文档中出现的频率越高,说明该词在区分该文档内容属性方面的能力越强(TF);一个词在文档中出现的范围越广,说明该词区分文档内容属性方面的能力越弱(IDF)。信息检索领域广泛地使用TFIDF算法计算特征项权重,其经典计算公式为:
其中,表示特征项在文档中出现的次数,表示特征项的逆文档频率,N表示文档总数,表示出现特征项的文档数。
TFIDF算法简单有效,但却并不具有普适性。传统TFIDF算法将文档集作为整体来考虑,忽略了特征项在类间和类内的分布情况。张玉芳和陈小莉等人[5]即针对类间、类内分布偏差,把信息增益公式引入文档集中,并随即提出了基于信息增益的TFIDF算法TFIDFIG。而在TFIDFIG的基础上,李学明和李海瑞[6]等人则引入信息熵的概念,同时提出了一种基于信息增益与信息熵的TFIDF 算法TFIDFIGE,实际上进一步提升了文本分类结果的准确率。然而,此类算法均为考虑文档中信息的结构特点,同时又忽略了特征项的领域意义,有鉴于此,本文在传统TFIDF算法的基础上,提出了针对Web医疗咨询数据的检索方法。
1.2Web医疗咨询数据检索
搜索技术在医疗领域的作用日益显著,源于可用医疗信息量的迅速增长,其中包括特定患者的信息(如电子健康记录)以及基于知识的信息(如科学文章)[7]。人们渴望获得医疗信息,但已有的网页搜索引擎并不能很好地处理有特殊需求的医疗搜索查询。医疗信息检索者通常不能准确地描述自身问题,而且对医疗专业术语也并不熟悉。这就使得查询语句可能很长,对病情症状的描述也多倾向于口语化。Gang Luo和Chunqiang Tang等人[8]提出了专门针对医疗信息检索的搜索引擎MedSearch,该引擎能够去除查询中的停用词,并从查询中提取重要的、具有代表性的关键词来精简查询,如此则不仅提升了查询速度,也提高了检索结果的质量。不准确的搜索结果还可能会增加人们的焦虑。I. Stanton和S. Leong等人[8]研究了如何从自由格式的医疗搜索查询中发现潜在的专业医疗术语,藉此将医疗查询映射为专业术语,而不是直接改善排名算法。另有S. Hsieh和 Wen-Yung Chang[10]等人利用Google AJAX Web搜索引擎的返回结果估算两个生物医学术语的语义相似度。再有ShARe/CLEF eHealth Evaluation Lab (SHEL) 于2013年提出了医疗疾病信息检索的共享任务,Yaoyun Zhang和Trevor Cohen[11]等人又为检测有关疾病的查询和网页之间潜在的语义相关性,而相应提出了基于分布式语义的语义向量模型。
2计算模型
本节首先介绍Web医疗咨询数据的预处理,然后分析了传统TFIDF算法不适合处理Web医疗咨询数据的原因,进而提出了基于分段向量模型(Segmented Vector Model, SVM)的Web医疗数据检索方法并给出其算法实现。
2.1Web医疗咨询数据的预处理
本文采用真实的Web医疗咨询数据作为实验数据集,首先将网页源码下载到本地,然后用HTML解析器解析其内容。网页源码集,其中m表示源码集大小。有问必答网是国内最大的医患交流平台,选择该网站中与高血压相关的咨询数据作为研究对象,获取得到208 110条高血压咨询数据。
HTML文本是一种半结构化的文本,由标签和内容组成,根据标签位置编程抽取中目标数据,可得记录集,其中对应,即为解析结果。对任意的,主要由以下字段构成:记录编号recordid、用户性别gender、年龄age、地区location以及病情描述,其中gender、age、location字段为基本数据类型,既可以存储在传统数据库中做一般性查询分析,也可以存储在文本中用作其它分析。而病情描述字段则由连续中文字符串组成,为文本型数据,尽管也可以将其作为一个字段导入传统数据库中,但并无实际意义,无法对其做查询分析,同时也不能计算彼此之间的相似度,因而需对其实施进一步的操作处理。
为使检索结果更精确,对中字符串类型数据分别提供一定处理,对属性gender、age、location来说,处理方式如下:gender值域为{0, 1, -1},男性为1,女性为0;age字段按年龄段划分,其值域为{0, 1, 2, -1},年龄段划分遵从联合国世界卫生组织标准: 44岁以下为0,45岁至59岁为1,60岁以上为2;location字段按地理大区处理,将省份或者城市转换为对应的地理大区,大区集合为{华北,华中,华东,华南,西北,西南,东北,港澳台},依次用数字0-7表示,地理区划标准参照百度百科,location值域为{0, 1, 2, 3, 4, 5, 6, 7, -1}其中-1表示用户未设定值或值错误。
此外,中病情描述字段为文本型数据,由连续中文字符串组成,也需对其进行中文分词处理。针对病情描述字段中可能包含的病症(symptom)及服用药物(drug),从Internet收集并整理了相应的症状字典dict_symptom和药物字典dict_drug。其中,dict_symptom中的词项主要来源于华商网的症状库及百度知道,共计条目6 485种。dict_drug中的词项主要来源于同仁堂药品目录、中药药材名称大全及其它药品名称大全,共计条目4 702种。停用词表主要来源于哈工大停用词表及通过观察记录集自行添加的停用词,共计条目1 411个。对记录做分词处理时,字典中的词项不会被分割,而停用词表中的词项将会被移除。本文选用复旦大学FudanNLP分词工具处理病情描述字段,经分词可得病情描述集,其中对应的病情描述字段,由一系列中文词项构成,词项间用空格分开。中所有词项构成词项集。
2.2检索模型
2.2.1 TFIDF模型及其缺陷
向量空间模型是一种简便、高效的文本表示模型,对于文档集,构建向量来表示文档d,中每个分量用TFIDF算法计算。文档相似度可用对应向量的余弦相似度来表示,文档a与文档b的相似度计算公式如下:
TFIDF算法在计算中各分量值时仅考虑文档d中词项的频率信息,然而同一个词项对不同领域中的文档的标识能力却各有不同,在医疗领域中,与病症、药物相关的词项比其它词项包含的信息量更大。例如,在语句s={服用 拉西地平片 引发 头痛 等 不良反应}中,“拉西地平片”为药物名,即使计算词项权重时发现词项“服用”与“拉西地平片”具有相同的TFIDF值,后者所包含的医疗信息量也明显大于前者,所以基于TFIDF算法的文本距离不能反应两条医疗咨询记录间的真实距离。经研究分析发现symptom和drug包含的医疗信息量即明显大于gender、age、location及其它无意义词项。因此,传统的将整条记录作为TFIDF算法的输入进行相似度匹配的方法难以满足现时的检索要求。为此,本文提出了基于分段向量模型的Web医疗咨询数据检索方法。
2.2.1 分段向量模型的建立
记录由基本类型的数据和文本型数据组成,将表示成向量,令,用向量表示中基本类型的数据,用向量表示中的文本型数据,的不同部分对该记录的标识能力有所差异,本节目标是用一种明确的方式对进行划分,即将划分为多个分段向量。假设中包含个基本类型的字段,则将每个字段都作为一个单独的分段处理,即,其中为一维向量,分量值等于字段值。此外,对中非结构化的文本数据进行划分时还需依赖于字典库。字典库,其中为一个字典,k个字典的类型均不相同。分段规则如下:将中出现在字典中的词项作为一个分段保存在中,将中没有出现在字典库中的词项保存在中,这样便将划分为k+1个分段,得,其中为文本型数据,本文基于向量空间模型用向量表示,中各分量采用TFIDF算法计算,从而有。经过以上处理,由(m+k+1)个分段构成,向量,至此分段向量模型得以建立。
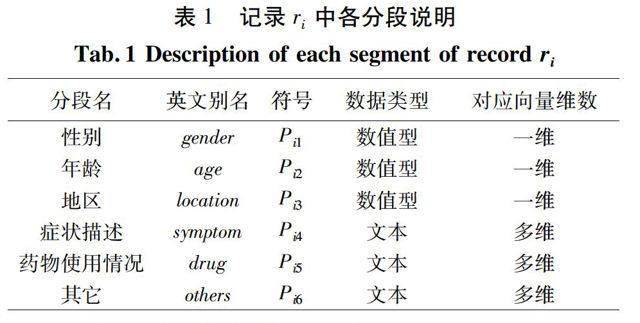
本文中,经预处理后,记录由用户的基本信息和病情描述组成,基本信息包括gender、age、location三个字段,为基本类型,即可将划分成三个分段,得,顺序与前三个字段一一对应,均为一维向量,分量值等于字段值;病情描述由一系列已分词的中文词项构成,为文本型数据。首先,对做分段处理,令,其中k为分段数。本文中,字典库包含dict_symptom和dict_drug两个字典,即可将划分成3段,分段依次为symptom、drug以及others,对应symptom字段,对应drug字段,对应others字段。将中出现在dict_symptom中的词项保存于symptom分段中;将中出现在dict_drug中的词项保存于drug分段中;用others保存中除去前2段后的剩余部分。例如,={服用 拉西地平片 可能 引发 头痛 心悸 等 现象},经分段后,保存中所有与症状相关的词项,即={头痛 心悸},相应地, ={拉西地平片}, ={服用 可能 引发 等 现象}。接着,将表示成向量,中各分量值采用TFIDF算法计算。为方便后续说明,对任意一条医疗咨询记录,令由6个分段组成,对分段的说明如表1所示。
2.2.2 基于SVM模型的检索策略
给定一条查询语句query,query格式与记录相同,要计算query和的相似度,首先按上述方式对query进行分段,得,其中表示query的第个分段。用两种不同方式计算与不同分段的相似度,第一种方式为自定义的相似度计算方法,用于计算query和在基本类型数据部分的相似度,即计算query和在gender、age、location分段的相似度,第二种方式基于TFIDF算法,用于计算query和在文本型数据部分的相似度,即计算query和在symptom、drug、others的相似度,将分段表示成向量形式后,分段相似度等于两向量的余弦相似度。对分段相似度进行加权和计算,两者的最终相似度为各分段相似度的加权和,即得相似度计算公式,为:
式中,k=6,为第个分段的影响因子,为与的相似度,表示的第个分段。通过对Web医疗咨询数据的内容进行采样统计分析,发现分段symptom以及drug对检索结果的贡献大于gender、age、location以及others。为此,权重分配上令==0.4,====0.05. 可逐步调整以获取最优的权重分配方案.
计算时考虑两种情况:当时,对应分段gender、age、location,由自定义的相似度计算公式求得,见式(5);当时,对应分段symptom、drug、others,由基于TFIDF算法的文本相似度公式求得,见式(3)。对进行排序即可获得与query最相似的咨询记录。检索模型的算法实现见2.3节算法1。
式中,为值域的大小,如属性gender,其值域为{0, 1, -1},则= 3。式(4)主要思想是,当两个属性值已知并且相等时,其相似度为1;当两个属性值已知并且不相等时,其相似度为0;当有属性值为-1时,由概率知识得其相似度期望为1/(-1)。以gender为例,当两者同为0或同为1时,其相似度为1;当两者分别为0和1时,其相似度为0;当两者中出现-1时,其相似度为1/2。计算age分段的相似度时, = 4;计算location分段的相似度时, = 9。算法实现见2.3节算法2。
1.1算法实现
本文基于SVM模型的检索策略的具体实现算法如算法1所示:
上述算法中,步1对进行分段,partition()函数按照指定方式将分成6段。步2-10划分R并计算与各分段的相似度,函数计算与在分段gender、age、location的相似度,其算法实现见算法2, 函数计算与在分段symptom、drug、others的相似度,计算过程基于传统TFIDF算法,其算法实现见算法3。步11计算与各分段相似度的加权和,即得与的相似度. 步12对求得的所有相似度进行排序,sort()函数为排序函数,最后返回相似度最高的前N条记录。算法1用两种方法计算分段相似度,并可自定义各分段的影响因子,这种处理方法充分考虑了原始数据集的特征,相对传统方法更灵活。
本文用自定义的相似度计算方法计算与在分段gender、age、location的相似度,其算法实现如算法2所示。
上述算法中,当两个属性值与已知并且相等时,其相似度为1;当两个属性值已知并且不相等时,其相似度为0;当有属性值为-1时,由概率知识得其相似度期望为1/(-1)。
本文用传统的TFIDF算法计算与在分段symptom、drug、others的相似度,其算法实现如算法3所示。
上述算法中,步1对进行分割,split()函数按空格分割,得到词项数组terms。步2-8统计terms中各词项在中的出现次数。步9-12计算各词项的TFIDF值,其中映射表M保存C中所有词项的IDF值。词项TFIDF值的计算方法见公式(5)。mapQ和mapP保存与的词项及相应的TFIDF值。步15-19计算与词项的内积和。步20-22计算与的模,并用余弦相似度作为与的文本相似度。
其中,为词项term在中的出现次数,为R中出现term的记录数。
2实 验
2.1 实验环境与数据集
实验运行的硬件环境为Intel
从图3中可以看出,权重值的细微调整对RR的准确率影响不大,但整体上A越小,RR的准确率越高,即当赋予symptom和drug的权重值越大,SVM检索策略越有效。
2结束语
本文根据Web医疗咨询数据的特点,提出了一种基于分段向量模型的Web医疗咨询数据检索策略。按照数据结构特点构造分段向量模型,然后将咨询数据按此模型表示,进而计算两向量中各分段的相似度,最终通过计算分段相似度的加权和产生更加准确的检索结果。实验结果验证了本文所提策略可以有效提升Web医疗咨询数据检索结果的准确率。未来的工作将继续完善本文提出的检索策略,主要是优化权重分配策略并扩大检索策略的适用范围。
参考文献
[1]FOX S, JONES S. The social life of health information [J]. Pew Internet & American Life Project, 2009-12.
[2]SALTON G, WONG A, YANG C S. A vector space model for information retrieval[J]. Journal of the American Society for Information Science, 1975, 18(11): 613~620.
[3]SALTON G, YU C T. On the construction of effective vocabularies for information retrieval[C]//ACM SIGPLAN Notices. New York:ACM, 1973, 10(1): 48-60.
[4]HU J, FANG L, CAO Y, et al. Enhancing text clustering by leveraging Wikipedia semantics[C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. Singapore:ACM, 2008: 179-186.
[5]张玉芳, 彭时名, 吕佳. 基于文本分类TFIDF方法的改进与应用[J]. 计算机工程, 2006, 32(19):76-78.
[6]李学明, 李海瑞, 薛亮. 基于信息增益与信息熵的TFIDF算法[J]. 计算机工程, 2012, 38(08):37-40.
[7]HANBURY A. Medical information retrieval: an instance of domain-specific search[C]//Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval. [S.l.]:ACM, 2012: 1191-1192.
[8]LUO G, TANG C, YANG H, et al. MedSearch: a specialized search engine for medical information retrieval[C]//Proceedings of the 17th ACM conference on Information and knowledge management. California,USA:ACM, 2008: 143-152.
[9]ATANTON I, LEONG S, MISHRA N. Circumlocution in diagnostic medical queries[C]//Proceedings of the 37th annual international ACM SIGIR conference on Research and development in information retrieval, Australia:SIGIR 2014,2014:133-142.
[10]HSIEH S, CHANG W-Y, CHEN C-H, et al. Semantic similarity measures in the biomedical domain by leveraging a Web search engine[J].Biomedical and Health Informatics IEEE Journal, 2013, 17(4):853-861.
[11]ZHANG Y, COHEN T, JIANG M, et al. Evaluation of vector space models for medical disorders information retrieval[J]. Proceedings of the ShARe/CLEF eHealth Evaluation Lab, 2013.
[12]HOW B C, NARAYANAN K. An empirical study of feature selection for text categorization based on term weightage[C]//Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence. [S.l.]:IEEE Computer Society, 2004: 599-602.
猜你喜欢
华东理工大学学报(自然科学版)(2025年1期)2025-02-26 00:00:00
吉林化工学院学报(2021年8期)2021-09-06 09:35:12
科教导刊·电子版(2021年30期)2021-01-03 17:32:37
电脑与电信(2018年11期)2018-02-16 05:41:16
山西青年(2018年5期)2018-01-25 16:53:40
新闻传播(2016年18期)2016-07-19 10:12:06
新闻传播(2016年11期)2016-07-10 12:04:01
现代计算机(2016年11期)2016-02-28 18:35:15
地理与地理信息科学(2015年4期)2015-10-13 08:29:20
河南科技(2014年11期)2014-02-27 14:10:19
