
现代汉语词汇历时检索系统的建设与应用
2015-04-21 08:43:50荀恩东饶高琦谢佳莉黄志娥
中文信息学报 2015年3期
荀恩东,饶高琦,2,谢佳莉,3,黄志娥,4
(1. 北京语言大学 大数据与教育技术研究所,北京 100083;2. 北京语言大学 语言科学院,北京 100083;3. 厦门国家会计学院,福建 厦门 361005;4. 福州应用技术大学 人文学院,福建 福州 350118)
现代汉语词汇历时检索系统的建设与应用
荀恩东1,饶高琦1,2,谢佳莉1,3,黄志娥1,4
(1. 北京语言大学 大数据与教育技术研究所,北京 100083;2. 北京语言大学 语言科学院,北京 100083;3. 厦门国家会计学院,福建 厦门 361005;4. 福州应用技术大学 人文学院,福建 福州 350118)
词汇是语言系统中最具活力的子系统。在语言演化的过程中,词汇的历时变化是语言学、历史学、社会学等多学科所关注的信息。我们收集了时间跨度约为60年的同质新闻语料。基于自然语言处理技术我们开发了现代汉语词汇历时检索系统。基于该平台可以利用频率、累积和与累积频率等方法从微观和宏观的角度上对词汇的语义、语用等方面进行研究。
历时信息;词汇演化;历时计算;语料库
1 引言
词是语言中有意义,能独立运用的最小单位,也是最能够体现语言生活变迁的语言单位。每一个词都有在其所属语言社团中独特的发展过程。从微观上说,一个词语包括其使用情况的历时信息,可以反映特定时间乃至特定领域在不同时期所受到关注的情况。从宏观上讲,整个词汇的丰富程度是语言生活情况的重要体现,从一个侧面反映了社会变迁和人民生活的变化。每个时间断面上的词汇都带有以往的语言历史,是共时和历时的混合产物[1]。
计量语言学关注今天的词汇始于哪个历史时期,还关注现在词汇的使用状况是如何形成的。语言的历时信息同样为计量史学所关注。而利用计量史学方法进行的观念史研究,则更注重特定词语的历时使用变化。金观涛、刘清风[2]使用晚清至民国有影响力的报刊杂志一亿两千万字作为数据源,通过表达同样观念的不同词在不同时期使用频率和上下文特征的研究,观察并分析了100个中国现代政治术语的形成和发展,在史学界引起很大反响,但是其史料库规模和选材偏执也引起了争议[3]。刘长征运用1981~2009年共29年的《深圳特区报》进行了新词语监测和词语生命力的研究[4]。涵盖面更广的语料库如LIVAC则收集泛华语地区的新闻语料四亿字,在共时性和历时性上都有突出贡献[5]。在囊括两岸三地新闻语料的基础上,持续更新,在此基础上发布港台京沪双周、全年名人榜,热词榜等信息,并对两岸三地的词汇使用异同做出了定量的分析。LIVAC新闻语料库建设始于1995年,历时仅17年。对于语言现象的变迁,这样的跨度还略显不足。谷歌公司2010年上线的服务Google Books N-gram Viewer,利用其数字化的520万册图书制作了可实现五元文法的词汇历时查询[6]。覆盖了1800~2000年间两个世纪的语料。但其汉语图书量较少,未对语料进一步分类,且有效的查询跨度少于200年。此外,图书对于现实语言现象的变迁存在一定的滞后。
可见,进行语言历时信息研究,尤其是词语历时信息的研究,需要大规模、长时间跨度的语料。我们收集了时间跨度57年的某省日报语料,为汉语词汇的历时信息提供了良好的基础。在第二节中,我们将介绍历时新闻语料的构成。对于特定词语的微观研究,频次、频率和频序是计算语言学中的使用的经典表征形式。在对宏观语言现象的历时研究中,采用前N%频率累积和(TNFA)与总词表前N%累积频率历时分布(TNFD)两种可计算指标对词汇使用丰富程度和高频词汇来源的历时分布进行表征。这些可计算特征将在第三节中进行讨论。基于这几项表征,搭建了现代汉语词汇历时检索系统(Diachro-nic Retrieval for Modern Chinese Word)。在线上开放数据为广大研究者所用。第四节将介绍该系统的设计和原理。最后一部分简要列举了几项基于该系统的应用,并展望了未来的研究方向。
2 历时语料的构成
我们收集了自1949年11月创刊至2007年间的某省日报,全部语料7亿字。该语料时间跨度大,覆盖了共和国自成立以来的绝大部分历史,记录了期间的语言生活与社会生活的巨大变迁,对于各个学科的追踪研究具有格外高的研究价值。以年为单位,对语料进行整理。经过分词并去除标点符号、拉丁字母与低频命名实体等,共有328 000个词形。各时间段语料规模如表1和图1所示。可见, 随着时间的推移,语料规模逐渐扩大,在1996年前后达到最高峰,接近1970年最低点的两倍。这是报刊信息量加大,社会传媒发展的结果。

表1 各时间段语料规模统计表
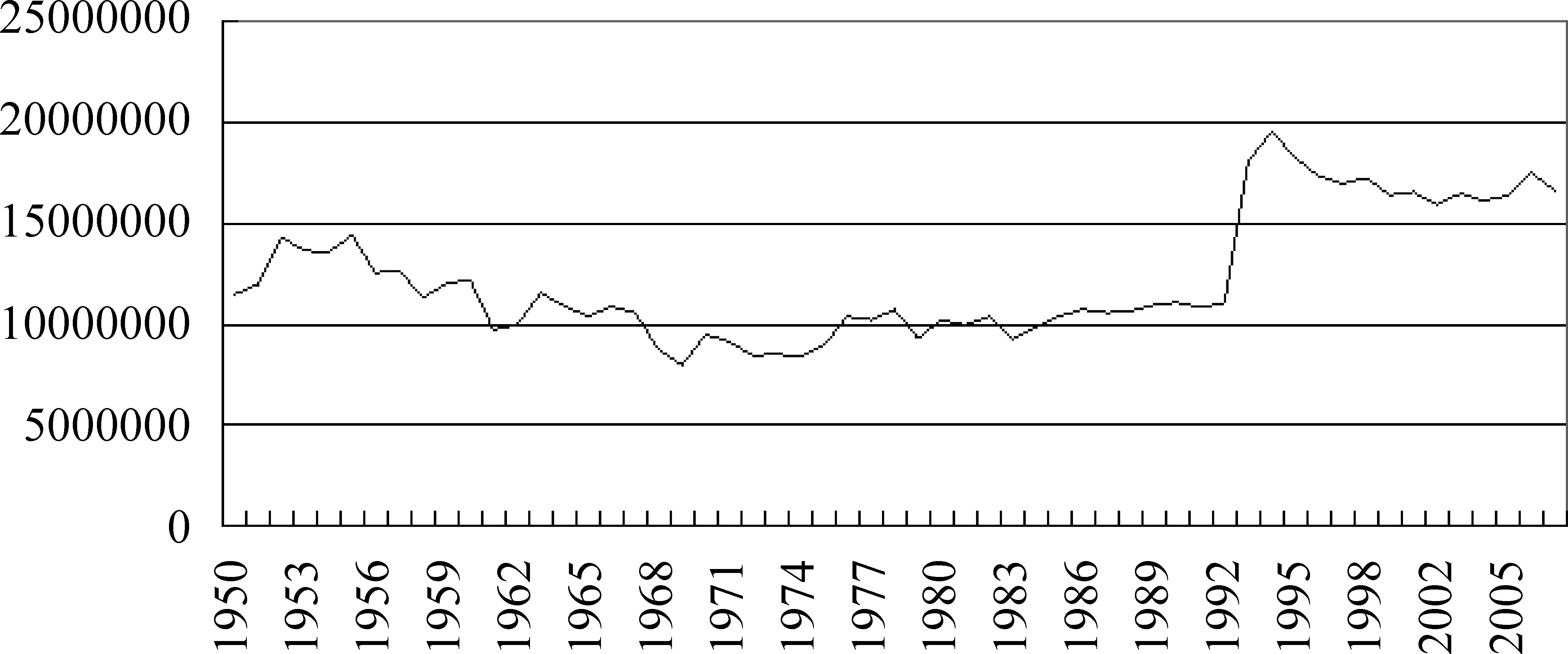
图1 各年份语料规模(字数)
3 词汇历时信息的表征方式
基于词语历时信息的研究,可以分为微观的对特定词语历史信息的分析、跟踪和宏观的对整个语言基于词语信息的历时研究。对于前者,频次、频率和频序是较为经典的表征方式。后者又分为基于词的历时语言丰富程度的度量与高频词历时分布的研究。基于词的历时语言丰富程度的度量,我们借用类似香农熵的思想,使用前N%频率累积和(TNFA)。高频词历时分布则用总词表前N%累积频率历时分布来加以描述。
3.1 微观词语历时信息的表征形式
词语出现的频次是语料中最能直接表征其使用情况的特征。由于不同时间段的语料规模不一,使用词语出现的频率作为衡量该词使用情况的标准显然更为科学。频率的定义如式(1)所示。
(1)
其中q(word)为词语word的频率,freq(word)是它在当年语料中出现的频次,Count为整个语料的全部词次数。
另一种表征词语使用状况的方式是特定词语在当年词表中的排名,如果该词表是按照频率降序排列的话,这种排名被称作频序[8]。相对于频率,这项指标更能反映出一个特定词语在当年相对于其他词语的使用情况,显示出其在整个语言生活中所占的地位。
3.2 基于词语信息的宏观语言现象表征
3.2.1 基于词语信息的历时语言丰富程度度量
词形数的增减从一个方面反映了语言生活的丰富程度。而更具有说明力的指标是香农熵。香农熵的公式如式(2)所示[9]。
(2)
其中W为语料中的全体词汇,设共n个词,wi为第i个词。p(wi)为第i个词在语料库中出现的概率。熵值的增高表明所有词间使用频率的差异较小,系统趋于平均和混乱。熵值的降低则表明词语使用的频率并不那么平均。图2为各年词的熵值变化。与图1类似,在1970年前后落到谷底,而随着改革开放的开始而逐渐回升。香农熵的计算中带有词语使用的概率信息,较词形数变化,可以更全面地反应语言生活的丰富度。

图2 各年语料的词熵变化
香农熵的计算是基于当年全部词汇进行。我们提出一种更加直观而灵活表现语言丰富程度的方式——年内前N%累积和。其定义如下: 每年词表中的词目,按频率降序排列,累积频率(也被称作覆盖率)达到N% 时的词数Y。
(3)
式(3)中Y代表年内topN累积和,即达到累积频率时词的个数;q(w)为词表中词w的频率,词表按频率大小从大到小排练;N为待选定的累积频率。
显然,当达到指定累积频率所需的词越多(即频率累积的越慢),表明词汇使用的越分散,丰富程度越高。反之亦然。图3为1950~2007年的年内前30%累积和。与图2类似, 只是更为明显。词汇使

图3 年内前30%累计和
用的丰富程度改革开放前总体低于改革开放后,文革十年是一个明显低谷。这符合我们的生活直觉与传统语言学对语言发展的认识[10]。
3.2.2 基于词语分布的高频词历时分布描述
我们使用总词表前N%累积频率的历时分布来描述高频词的来源,定义如下: 使用全部语料形成的总词表,按照频率降序排列,当累积频率达到N%时,该范围内的词语[式(4)~(5)]在各年中出现频率之和[式(6)]。以前50%为例,总词表中按频率降序,当频率累积到达50%时,共有t个词。这t个词在1959年中,出现频率之和,即为1959年对总词汇的贡献情况。这一指标表征了高频词的历时性分布与构成。
(6)
前N累积和中公式(4):N为待选定的累积频率;q(wi)为全部语料形成的总词表中词wi的频率,词表按频率降序排列;公式(5): S是从总词表中按照频率从大到小取词,其累积频率达到N时所取出词组成的集合。公式(6):p(wi)为wi在某一年(横坐标所指示的年份)中出现的频率,将公式(5)上所取出的集合S里所有的词累加得到的频率和即为当年语言对总高频词汇的贡献和Y。
图4是总词表前50%累积频率的历时分布直方图。从变化幅度上可以看出该项指标对词汇历时分布的敏感性。同时,也可以看出改革开放后的词语使用对总词汇中使累积频率达50%的词汇有更重要的贡献,即改革开放后的词语使用对今天的影响更大。

图4 总词表前50%累计频率历时分布
4 现代汉语词汇历时检索系统的设计与实现
基于上一部分所讨论的几种表征词语历时使用状况的要素,我们设计了现代汉语历时检索系统,提供在线词语查询和语言丰富度计算。我们将所收集语料,按照来源时间,以年为单位分割。使用北京语言大学研发的GPWS(通用自动分词系统)对其进行分词和命名实体识别[11]。经过此步骤后即可抽取出各年的词表与总词表。通过全文检索系统对全部语料建立了倒排索引,并在索引中加入时间标记。基于此,计算所有词在各年和全部时间段的频次、频率、频序与累积频率(覆盖率),形成支撑服务的后台数据。系统设计流程图如图5所示。
在用户界面图6中,用户在下拉框选择历年或全时高频词的覆盖率(如前20%,前30%等等),可通过高频词历时分布统计从宏观上观察语言使用状况。在检索框中输入待查询词语,检索词语历时信息(历年频次、频率、频序)以直方图和折线图的形式可视化显示。在直方图或折线图上点击某特定年份,便可获得当年待查询词的使用实例。以查询词为中心,上下文窗口为20个字,显示检索结果实例,方便研究者在统计数据之外能更详实直观的了解特定时间点上的语言现象。
5 系统应用与未来工作
现代汉语历时检索系统自2012年5月初上线以来,展现出了较高的实用性与可用性。期间进行了一次语料扩充(延伸为1951~2012年)和两次用户界面改版。用户的高频查询主要是新词和公共领域相关概念两方面。由于报刊新 闻语料的特点, 本系统主要功能体现是后者。对于新词,如“宅女”、“忽悠”等随着经济文化事业产生的词, 不如网络语料反应快,但可以通过实时的新语料抓取来得到部分满足。公共领域相关概念有环保、减肥、听证会等。单个词语使用的变化,从一个侧面揭示了一类社会问题、社会现象发生发展以及受关注的过程。而这类词总数的增多和使用频率的增加,表明了公共空间作为社会发展标志,从无到有、从小到大的过程,是符合生活直觉和社会发展规律的[12]。

图5 系统设计流程图

图6 用户界面
2002年,教育部发布了《第一批异形词整理表》[13],对338个异形词对进行了整理和规范。异形词的整理工作需要照顾到语言事实并充分考虑文化传承,在大时间跨度上的统计分析是十分重要的。以“身份-身分”为例。“身份”为推荐词形。从图7中可以看出,两者长期稳定共存(两者都一直使用,无间断),但是“身份”在1961年及其后均占据了绝对优势。该异形词对的选择都得到了“大数据实证”上的支持。对于未涵盖的词对,以“交待-交代”为例,从图8中可以看出在70年代以后两者频率降低并逐渐趋同。

图7 身份-身分频率变化图

图8 交待-交代频率变化图
就同一字/词而言,其使用和语义在漫长的时间流转中也会发生巨大的变化。以“炒”为例,1950年检出的45次使用中,全部为“把食物放在锅里加热并随时翻动使熟”,然而在1996年检出的245次中仅有101次为此义,其余为表示“频繁买卖”,或者是南方方言中表示解雇的“炒鱿鱼”,以及表示“扩大影响”。一个有趣的现象是南方方言中表示解雇的“炒鱿鱼”。在1980年代初进入新闻出版语言的时候共检出两次,均是在双引号中引用;在1993年17次检出中有11次在双引号中;而到了2004、2005年各有一次检出,均不在双引号中。期间所伴随的事件便是1999年开始修订的《现代汉语词典》最终收录了“炒鱿鱼”。
词语的历时信息体现了词语在语言社团中的使用,对语言社团中重大事件的发生有着很好的表现作用。词语取代现象还可以微观的体现出语言生活的许多变迁。以南朝鲜-韩国两词的频率查询为例。如图9所示, 南朝鲜在1960年前后出现使用高峰,恰好对应了冷战进入高潮,武装对峙白热化。韩国和南朝鲜的使用频率在1992年出现交叉。1992年之前,几乎不使用韩国这一称谓,之后则迅速停用了南朝鲜这一称谓。这一节点所标示的历史事件即中韩于1992年建立外交关系。图10为科学技术-科技的频率图,直观地显示出了“科技”取代“科学技术”的过程。
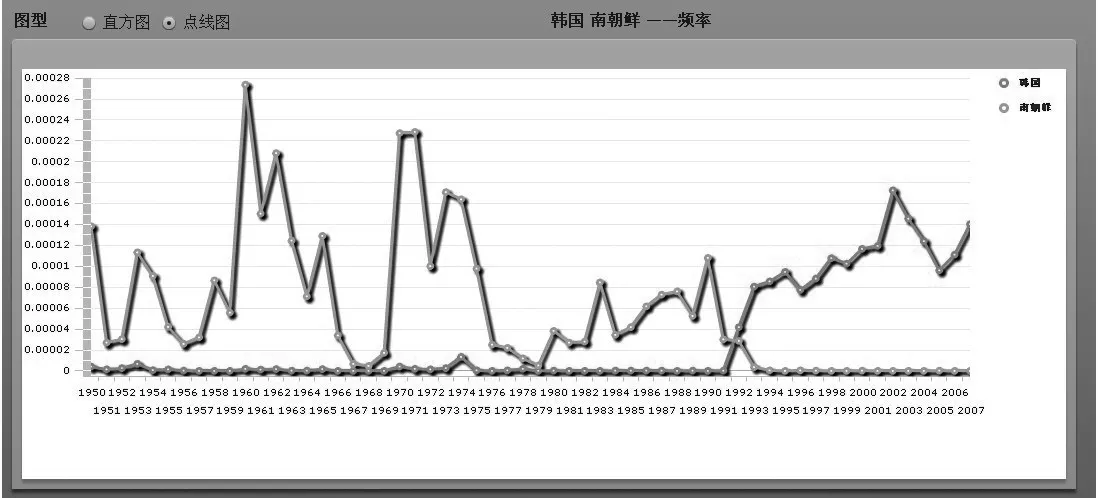
图9 南朝鲜-韩国频率图
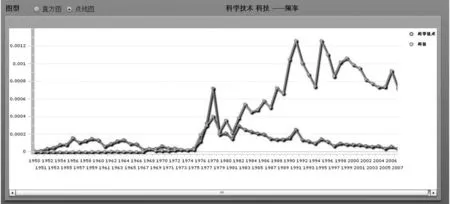
图10 科学技术-科技频率图
缩略语随着原短语使用的增长,自身使用也增长,基于人类交际的最省力原则,最终取代本词。基于社交网络、微博和Twitter的公共事件预测研究方兴未艾[14-16],与本系统探测事件发生和语言趋势的原理本质上类似,都是利用了群体智慧。历时的语料数据,尤其是词信息数据在何等程度上有助于语言使用情况的预测,乃至热点的追踪和挖掘,将是十分值得深入研究的问题。
许多词在不同时代有迥异的语义,其使用情况亦大为不同。我们通过历时语言实例的查询能够对其进行一定区分。在词语的研究方面上,现在的词语历时检索系统是面向词语使用情况的历时变化,等于说是基于一元语法(Unigram)的统计研究,怎样合理地注入更多上下文信息,利用报纸语料中版面、板块这一天然分类信息,提供分领域的查询和对比,提供更可靠的自动化分析也是未来的研究方向。
此外,基于统计的自动分词技术并不考虑语言的历时特性。前文示例中词语浅层特征在不同时间段上有着明显的差异,这是否可以对统计自动分词提供一定反馈?从资源建设上来讲,单一媒体作为语料来源,必然有其偏执,如何平衡的融合其他不同时间跨度上的语料;如何基于语料特点,寻找具有应用价值的衡量指标,这些都是在这套系统的研发过程中产生的新的学术问题,并期待系统的使用者和开发者共同进行更深入的研究与探索。
[1] 葛本仪. 词汇的动态研究与词汇规范[A]. 载《词汇学理论与应用》苏新春,苏宝荣主编. 北京: 商务印书馆. 2004.
[2] 金观涛,刘庆峰. 观念史研究[M]. 北京: 法律出版社.2009.
[3] 张仲民. “局部真实”的观念史研究.《东方早报》2010年5月23日B05版.
[4] 刘长征. 基于动态流通语料库的新词语监测研究[M]. 北京: 世界图书出版社.2011.
[5] 邹嘉彦,邝蔼儿,陆斌,蔡永富. 汉语共时语料库与追踪语料库[J]. 中文信息学报,2011,25(6):38-45.
[6] Jean-Baptiste Michel, Yuan Kui Shen,Aviva Presser Aiden etl. Quantitative Analysis of Culture Using Millions of Digitized Books. Science 331, 176(2011); DOI: 10.1126/science.1199644.
[7] 李宇明. 权威方言在汉语规范中的地位[J]. 清华大学学报, 2004,5:24-29.
[8] 教育部语言文字信息管理司. 中国语言生活状况报告[M]. 北京: 商务印书馆,2009:525-534.
[9] 克劳德·艾尔伍德·香农. 《通信的数学理论》 (A mathematical theory of communication) 贝尔系统技术,1948,1:379-423.
[10] 叶蜚声,徐通锵. 语言学刚要(修订版)[M]. 北京: 北京大学出版社.2010.
[11] 宋柔,罗智勇.现代汉语通用分词系统(GPWS v3.5)http://democlip.blcu.edu.cn:8081/gpws/
[12] 尤尔根-哈贝马斯. 公共领域的结构转型[M]. 上海: 学林出版社.1999.
[13] 《第一批异形词整理表》,中华人民共和国教育部. 2002
[14] Shen Yu,Subhash Kak. A Survey of Prediction Using Social Media[C]. ArXive-prints. March, 2012.
[15] 路荣,张旸,杨青. 社交网络中新闻趋势的预测分析[J]. 中文信息学报. 2012,26(5):85-90.
[16] 洪宇,张宇,刘挺,李生. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报. 2007,21(6):71-87.
Diachronic Retrieval for Modern Chinese Word: System Construction and Its Application
XUN Endong1, RAO Gaoqi1,2, XIE Jiali1,3, HUANG Zhi’e1,4
(1. Institute of Big Data and Educational Technology, Beijing Language and Culture University, Beijing 100083, China; 2. Faculty of Linguistic Sciences, Beijing Language and Culture University, Beijing 100083, China; 3. Xiamen National Accounting Institute, Xiamen, Fujian 361005, China; 4. School of Humanities, Fujian Universitity of Technology, Fuzhou, Fujian 350118, China)
Lexicon is the most active and time sensitive sub system of a language. During the evolution of a language, diachronic changes in vocabulary are focused by linguist, historian and sociologist etc. We collected large scale of corpora with a large time span, and developed the system of Diachronic Retrieval for Modern Chinese Word with natural language processing technology. It provides search indexes on frequency, cumulative sum, cumulative frequency etc., for possible studies on the semantics pragmatics and other aspects of the word.
diachronic information; lexicon evolution; diachronic computing; corpus

荀恩东(1967—),通讯作者,教授,主要研究领域为语言信息处理、语言教育技术。E⁃mail:xunendong@blcu.edu.cn饶高琦(1987—),博士研究生,主要研究领域为计算语言学、语言规划。E⁃mail:raogaoqi@blcu.edu.cn谢佳莉(1988—),主要研究领域为语言信息处理、教育技术。
1003-0077(2015)03-0169-08
2013-04-08 定稿日期: 2013-07-9
国家自然科学基金(61300081,61170162);国家语委项目(YB125-42);国家高技术研究(863)发展计划(2015AA015409)。
TP391
A
猜你喜欢
汉字汉语研究(2021年1期)2021-06-11 01:14:58
汉字汉语研究(2021年1期)2021-06-11 01:14:56
英语世界(2021年13期)2021-01-12 05:47:51
红楼梦学刊(2019年5期)2019-04-13 00:42:36
汉字汉语研究(2018年3期)2018-11-06 07:03:08
海外华文教育(2016年1期)2017-01-20 08:21:58
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
