
Motion cue based pedestrian detection with two-frame-filtering①
2015-04-17 06:27LvJingqin吕敬钦
High Technology Letters 2015年3期
Lv Jingqin (吕敬钦)
(Institute of Image Processing and Pattern Recognition, Shanghai Jiaotong University, and Key Laboratory of System Control and Information Processing, Ministry of Education of China, Shanghai 200240, P.R.China)
Motion cue based pedestrian detection with two-frame-filtering①
Lv Jingqin (吕敬钦)②
(Institute of Image Processing and Pattern Recognition, Shanghai Jiaotong University, and Key Laboratory of System Control and Information Processing, Ministry of Education of China, Shanghai 200240, P.R.China)
This study proposes a motion cue based pedestrian detection method with two-frame-filtering (Tff) for video surveillance. The novel motion cue is exploited by the gray value variation between two frames. Then Tff processing filters the gradient magnitude image by the variation map. Summations of the Tff gradient magnitudes in cells are applied to train a pre-detector to exclude most of the background regions. Histogram of Tff oriented gradient (HTffOG) feature is proposed for pedestrian detection. Experimental results show that this method is effective and suitable for real-time surveillance applications.
pedestrian detection, two-frame-filtering (TFF), Tff magnitude vector (TffMV), Histogram of Tff oriented gradient (HTffOG), SVM, video surveillance
0 Introduction
Pedestrian detection is an important precursor for many computer vision applications, such as intelligent video surveillance and image annotation. Though pedestrian detection is a challenging task due to variable appearance and pose, prominent progresses have been published[1,2]for pedestrian detection on image. Such works study detection on image by densely extracting powerful feature (such as HOG and LBP) and SVM training, and good results have been achieved. However these methods are time-consuming, furthermore their performance can be improved by adding motion information. Therefore such methods are still not suitable for video surveillance. In recent years, a few works exploit motion information for video pedestrian detection. In Ref.[3] the detection performance is improved significantly when optical flow based feature is combined, but the detection speed is decreased. In Ref.[4] the motion information is exploited by image differencing, and as an early work the detector is trained based on sums of absolute differences and gray value in rectangles. Methods combined with edge templates and foreground cues[5,6]can obtain good performance in video surveillance scenes with relatively rapid speed.
In surveillance scenes most people are walking, and stand-up people will walk away later. By this observation, a motion cue based pedestrian detection method with two-frame-filtering is proposed to detect moving pedestrians in surveillance scenes. The novel motion cue is exploited by the variation of pixel’s gray value between two adjacent frames, instead of foreground cues which may obtain undesirable inaccurate foreground in crowded scenes. Then Tff processing filters the gradient magnitude image of the current frame through the variation map by constraining the magnitude less than the variation value for each pixel. Consequently, the Tff gradient magnitude of the background region is suppressed substantially, and contours of moving targets are highlighted relatively. Summations of the Tff magnitudes in cells are concatenated into Tff magnitude vector (TffMV) and utilized to train the pre-detector by SVM to exclude most of the background regions rapidly. To represent pedestrian’s appearance, histogram of Tff oriented gradient feature is proposed and utilized to train the pedestrian detector. Experimental results and analysis indicate that our detection method is effective and suitable for real-time surveillance applications.
The structure of this paper is as follows. Section 1 introduces Tff processing, TffMV as well as HTffOG. In Section 2, the detection method is described. Experimental results are presented in Section 3. Finally, the method is concluded in Section 4.
1 Tff processing and HTffOG
1.1 Tff processing
For surveillance scene, motion cue can be exploited from two frames. Firstly, Tff processing computes the variation map of the scene. Given two adjacent frames It+1and It, difference dIt+1(x) of pixel x is calculated
(1)
where g is a normalizing factor. The gray value variation map Vt+1(x) is computed as
(2)
The result map Vt+1(x) which simply captures pixel’s variation across frames contains the valuable motion cue of the scene. If dIt+1(x) is large enough, it is most likely produced by motion or illumination changing. The normalizing factor g is set to 25 in our experiments by obtaining better effects of variation maps for several randomly selected frames.
For illustrative purpose, the results of Tff processing on two frames are shown in Fig.1. In the variation map Vt+1(x), the background is suppressed substantially, while moving targets are highlighted relatively, which indicates that the motion information is successfully extracted into the variation map.

Fig.1 Original image, variation map, magnitude image and Tff magnitude image (from top to bottom)
In some cases, motions of some local body parts are tiny. In the variation map, such parts are usually thin and weaker. To strengthen the variation of such parts, Vt+1(x) is improved as
(3)
Secondly, the gradient magnitude Gt+1(x) of the current frame It+1is calculated using [-1,1] derivative mask. Then magnitude Gt+1(x) is divided by coefficient g as in Eq.(1). Next it is cropped by the same way as Eq.(2).
The gradient cue characterizes the appearance of the scene, and the variation map exploits the variation parts around moving objects. In order to obtain good features for detection, to integrate the merits of both cues is an advisable way. As the variation map and the magnitude image are calculated in similar ways, Tff processing filters the gradient magnitude image of the current frame through the variation map
(4)
1.2 TffMV and HTffOG
The notable HOG densely extracts histograms of oriented gradient in each cell on a grid of pedestrian window. It captures the appearance and shape information which enable detector to discriminate pedestrians from complex background. Given the Tff magnitude image, the proposed TffMV and HTffOG are extracted in a similar way as HOG. The pedestrian window (96×48 image window) is divided into a 16×8 grid and a 15×7 grid (with cell size of 6×6), as shown in Fig.2. The appearance of pedestrian window can be represented by extracting feature from each cell. Cells of one grid are located at the center of 2×2 neighboring cells of the other grid. Therefore this pair of grids can provide abundant information.
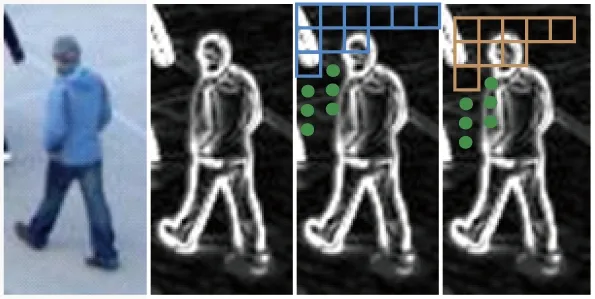
Fig.2 Illustration of two grids for calculating HTffOG
In the Tff magnitude image, magnitudes of moving people’s contour are high, while magnitudes of most of the background are close to zero. The summation of magnitudes in a cell represents the appearance of the cell. TffMV is extracted by concatenating the summation of pixels’ magnitudes in every cell. Before calculating the summation, the Tff magnitude image is filtered by a 5×5 averaging filter to reduce aliasing between cells. Consequently, the pedestrian windows can be discriminated from the background ones using TffMV.
Local appearance and shape can be often characterized well by the distribution of local region’s gradients. To obtain better and sufficient representation, a histogram of oriented gradient is constructed for each cell. Firstly, each pixel’s magnitude is voted bilinearly to histograms of 2×2 neighboring cells according to the distances between the pixel and the cell centers. Next the histogram can be calculated by voting each magnitude to two adjacent orientation bins linearly according to its gradient orientation. HTffOG is the concatenation of all the 233 histograms of oriented gradient, resulting in a vector of 2097 dimensions. Due to the merits of Tff magnitude image, HTffOG can extract moving pedestrian’s appearance better than the traditional HOG for video surveillance.
In order to alleviate lighting changing problem and imbalance of gradient magnitude among cells, histogram normalization is performed. The histogram of oriented gradient v is normalized for each cell
(5)
For general normalization, α is a constant whose value is 1. Consequently, histogram vnis irrelevant to ‖v‖1after normalization. In our method, α is set to 1/3 by experience, and M is set to the evaluated mean summation of Tff magnitude in every cell from the training data. Therefore the informative Tff magnitude cue ‖v‖1is partly preserved in vn.
2 The detection method
Linear SVM is adopted to train the pre-detector and the pedestrian detector with TffMV and HTffOG respectively. The detection process is based on scanning a 96×48 model window over the input image at discrete positions (with step size equal to cell size). Detectors are applied to classify each scanned window as a pedestrian candidate or background with TffMV or HTffOG. Background windows will be rejected by the detectors.
The proposed method contains three steps. Firstly, for each scanned window, TffMV is extracted and runs the pre-detector to classify each window. As a result, most of background windows will be rejected, and only a few windows classified as pedestrian candidate pass the pre-detector. Secondly, the discriminative HTffOG is extracted for each remnant candidate window. HTffOG vectors are fed to the pedestrian detector to classify these windows as pedestrian or not. Some nearby windows corresponding to the same pedestrians usually pass the pedestrian detector. Finally, all the remnant windows are merged to obtain exact pedestrian positions by the mean shift algorithm[8].
3 Experimental results
3.1 Implementation details
To evaluate the proposed detection method, the PETS 2009 dataset[9]is selected which includes many sequences recorded at 7 frames per second from a surveillance scene. The detectors are trained with cropped windows from sequence Time-14-03. 590 pedestrians’ windows (resized to 48×96) are cropped from Time-14-03 as positive training samples, and 5900 negative samples are cropped. The pre-detector and the pedestrian detector are trained by the public software LibSVM[10]. The method is tested after every tenth frame for Time-12-34, and after every fifth frame for Time-13-57. In Time-13-57, many people are in crowd and occlusion happens frequently. This sequence is challenging for the pedestrian detection task, while Time-12-34 is relatively easy. In surveillance scenes, people usually walk on a ground plane. A useful calibration technology[5]can be applied to determine the height of pedestrians at every image vertical coordinates. Then the method can run the detectors through a few scales instead of all scales.
3.2 The performance of the pre-detector
Fig.3 shows the output of the pre-detector at a single scanning scale. The 6×6 green patches are the centers of the candidate windows passed the pre-detector. Obviously, most of the background windows are precluded by the pre-detector. To evaluate the performance of the pre-detector, the number of passed windows per person in a frame (NPWP) is defined as a metric. Lower NPWP value indicates that more windows are precluded by the pre-detector. The evaluated average NPWP for Time-12-34 is 21.83. As shown in Table 1 in section 3.3, 85% of the persons are detected in this sequence. Therefore the real average value of NPWP for all the detected persons may be no more than 26. The number of the candidate windows of each frame is 18870. Therefore more than 18000 windows of the background are precluded by the pre-detector with a few computations.

Fig.3 Outputs of the pre-detector
TffMV is of only 233 dimensions, and thus the pre-detector can be very efficient to scan the image. HTffOG is of 2097 dimensions, while HOG is of 3780 dimensions. 18000 windows are precluded by the TffMV based pre-detector, and only less than 870 windows are required to calculate the HTffOG and send to
the person detector. As compared, our method can be nearly 15 times faster than HOG based detection method, which indicates that the method should be suitable for real-time detection.
3.3 Pedestrian detection results
Recently Bolme, et al. proposed the ASEF Filter based detection method[11], and Felzenszwalb, et al. proposed the part model detection method. Experimental results of both methods on PETS 2009 dataset were presented in Ref.[11]. For evaluation purposes, the results of our method are compared with results of these methods. Table 1 and Table 2 show the detection results of the proposed method and results extracted from Ref.[11]. Two detection results with different detection thresholds are given for each method.

Table 1 Results of sequence Time-14-03

Table 2 Results of sequence Time-13-57
For Time-12-34, the proposed method achieves a high recall rate 85.65% and a higher precision rate 96.91%. Our method performs better than the compared methods as shown in Table 1. In this sequence some people stand statically. If such kind of cases is not considered in statistics, the recall rate should be higher than 93%. Fig.5 shows the final results of three frames. In Fig.5, most of the pedestrians are detected well, except the person who stands statically in the first image.
For Time-13-57, our method results in a lower recall rate 62.85% and a high precision rate 89.43%, under difficulties that half-body occlusion and whole-body occlusion happen frequently. Compared with other methods with the same recall rates, our precision rate is higher. During the calculation of the recall rate, all the pedestrians including whole-body occluded pedestrians contribute to the recall rate; thus the recall rate should be higher actually.

Fig.5 Results of three frames of Time-12-34
Fig.6 shows the final results of three frames for Time-13-57. Obviously, most of the pedestrians not occluded are detected well, while a few false positives and miss detections also exist. In the first image, there are two false positives on the upper left. The left one is produced between two pedestrians. The other one is produced by the upper-body of three pedestrians, and one miss happens among the dense crowds. In the second image, the pedestrian occluded by the billboard is detected well, due to the role of the motion cue and the discriminative HTffOG. In the third image, the upper left dense crowds are detected with high recall performance. Those persons overlapped with nearby ones are detected precisely. The above experimental results indicate that the proposed method achieves good performance for these two sequences.

Fig.6 Results of three frames of Time-13-57
4 Conclusions
This study has exploited the motion cue by effective Tff processing. Based on the Tff processing, discriminative TffMV and HTffOG are proposed. The pre-detector can preclude most background regions rapidly, and the pedestrian detector detects pedestrians from crowded scenes well. Experimental results indicate that our method is robust in complex scenes and suitable for real-time surveillance applications. Based on the proposed Tff processing, it’s meaningful to do research on more informative features, or develop methods to detect lower-body occluded pedestrians by combination with the body model[13]in the future.
[ 1] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, USA,2005. 886-893
[ 2] Wang X, Han T X, Yan S. An HOG-LBP human detector with partial occlusion handling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009. 32-39
[ 3] Walk S, Majer N, Schindler K, et al. New Features and Insights for Pedestrian Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010. 1030-1037
[ 4] Viola P, Jones M J, Snow D. Detecting pedestrians using patterns of motion and appearance. In: Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 2003. 734-741
[ 5] Zhe L, Davis L S, Doermann D, et al. Hierarchical part-template matching for human detection and segmentation In: Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 2007. 1-8
[ 6] Beleznai C, Bischof H. Fast Human Detection in Crowded Scenes by Contour Integration and Local Shape Estimation In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009. 2246-2253
[ 7] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, USA, 2001. 511-518
[ 8] Comaniciu D, Ramesh V, Meer P. The variable bandwidth mean shift and data-driven scale selection. In: Proceedings of the IEEE International Conference on Computer Vision, Vancouver, British Columbia, Canada, 2001.438-445
[ 9] Ferryman J, Shahrokni A. An overview of the pets2009 challenge. In: Proceedings of the IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Miami, USA, 2009. 25-30
[10] Chang C C, Lin C J. LIBSVM: a library for support vector machines. http://www.csie.ntu.edu.tw/~cjlin/libsvm, 2001
[11] Bolme D S, Lui M Y, Draper B A, et al. Simple real-time human detection using a single correlation filter. In: Proceedings of the IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Miami, USA, 2009. 1-8
[12] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, USA, 2008. 1-8
[13] Ramanan D. Learning to parse images of articulated bodies. In: Proceedings of the Conference on Neural Information Processing Systems, Vancouver, Canada, 2006. 1129-1136
Lv Jingqin, born in 1984. He is currently a PhD candidate at the Institute of Image Processing and Pattern Recognition, Shanghai Jiaotong University, China. He received his BS and MS in instrument science and technology from Harbin Institute of Technology, China, in 2005 and 2007, respectively. His research interests include visual surveillance, object detection, and pattern analysis.
10.3772/j.issn.1006-6748.2015.03.013
①Supported by the National High Technology Research and Development Program of China (No.2007AA01Z164), and the National Natural Science Foundation of China (No.61273258).
②To whom correspondence should be addressed. E-mail: lvjingqin@sjtu.edu.cn Received on Jan. 7, 2014, Zhang Miaohui, Yang Jie
 High Technology Letters2015年3期
High Technology Letters2015年3期
- High Technology Letters的其它文章
- Probability density analysis of SINR in massive MIMO systems with matched filter beamformer①
- An energy-saving scheduling scheme for streaming media storage systems①
- Design and analysis on four stage SiGe HBT low noise amplifier①
- Diversity-multiplexing tradeoff of half-duplex multi-input multi-output two-way relay channel with decode-and-forward protocol①
- Edge detection of magnetic tile cracks based on wavelet①
- Probabilistic data association algorithm based on ensemble Kalman filter with observation iterated update①