
社交博客用户分层与话题演化研究——以MetaFilter Music版块为例
2015-03-07 12:01杜海燕叶光辉
信息资源管理学报 2015年4期
杜海燕 叶光辉
(武汉大学信息管理学院,武汉,430072)
社交博客用户分层与话题演化研究——以MetaFilter Music版块为例
杜海燕叶光辉
(武汉大学信息管理学院,武汉,430072)
[摘要]结合时序分析、聚类分析与复杂网络分析,对社交博客用户分层及话题演化进行了分析。依据用户在社交媒体中的活跃程度,设置关联强度阈值和比例,提取核心用户群体。统计各年度整个用户群体关注的热点话题,对比核心用户群体关注的热点话题,评估核心用户群体对热点话题衍生的影响大小。实证分析可知核心用户群体对热点话题衍生具有显著影响,长尾效应使得非核心用户群的影响也不能忽视。
[关键词]社交博客话题演化MetaFilter用户分层
1引言
作为Web2.0时代的典型代表,博客发展经历了传统博客、社交博客、微博三阶段。传统博客为每一个用户提供了表达的独立空间,微博则为所有用户提供了表达的公共空间。社交博客介于二者之间,是传统博客向微博过渡的中间形式,因此也被叫做轻博客。随着社交媒体的迅速发展和互联网博客数量的急剧增长,微博、社交博客等已经成为互联网上一种重要的信息源,将用户从原来单纯的信息接收者变成接收和发布信息的完全参与者,从而让社会走进全民记者时代。相较于微博,社交博客不受140字符限制,能够集成更为丰富详实的内容,减弱微博内容随意性大、有价值信息极度分散等负面影响,同时社交功能也比较完善,能够满足不同主题用户的社交需求。微博与社交博客话题提取结合各自的平台特征、用户群而在话题内容上有所差异,但在相关提取方法等(包括自然语言处理、复杂网络分析等)则大体一致。
社交博客自身的大众特性,使得任何个人或团体、组织可通过微博随时随地随心地发布任意类型的内容和观点,有时候不可避免地充当了谣言流言、虚假消息的传播工具。巨大的用户基数和通畅的社交网络使得虚假消息可以迅速得到广泛传播。虚假消息的传播,不仅会误导人们做出错误的选择,甚至可能影响一个社会团体至整个社会,引起社会性的反应。为帮助政府部门监控舆论走向,了解民意,从海量社交博客资源中识别热点用户和话题成为新的研究热点。文献调研发现,目前热点用户研究主要集中在意见领袖[1]挖掘,如尹衍腾等[2]提出了一种结合用户关系和用户属性的意见领袖挖掘方法,并通过数据验证了该方法的准确和高效;蒋翠清等[3]从影响力、支持力等方面刻画意见领袖,构造话题参与者的属性矩阵,通过加权平均得到各用户的综合评价,最后发现了话题的意见领袖;Xu等[4]尝试利用内容和网络分析相结合的技术方法,对Twitter平台上政治行动网络(Political Activism Network)中的意见领袖进行了识别,并以Wisconsin Recall Election事件为例说明了该方法的有效性;Zhang等[5]设计了一种基于K派系聚类的社群抽取及意见领袖挖掘的算法,并以天涯社区为例,实证了该算法的可行性。热点话题与热点用户具有很强的关联关系,但该关系不一定是线性的、同步的,目前热点话题研究主要围绕微博语料来展开,常用的话题抽取及挖掘方法包括分类聚类方法[6]、LDA模型[7]、自动摘要[8]等,通过社交博客来提取热点话题的研究工作还没有引起重视。
基于前人基础研究工作及不足,本文将构建社交媒体环境下的语义网络,利用复杂网络和社交网络分析指标及方法,分层识别社交博客用户,提取和挖掘热点主题演化路径,并梳理热点用户及主题之间的关联关系,寄望为相关政府部门舆情监控工作提供思路。
2研究方法
2.1 研究对象及数据来源
结合引言陈述,可知用户及话题是本文重点研究的两类对象,但目前国内围绕微博话题的研究较多,而有关社交博客话题研究较少,这一方面是由于国内社交博客平台较少,且相比微博,用户活跃度不高;另一方面社交博客平台数据开源获取性差,结构化程度不高。藉此,本文选择国外知名社交博客网站MetaFilter的Music版块作为数据来源。MetaFilter是美国目前较有影响力的社交博客平台,其开放性好,注册用户数量多,博客活跃程度高且社交活动数据可开源获取(http://stuff.metafilter.com/infodump/)。本文以其Music版块为示例,获取从2009~2013年的相关数据(对于分年度展示的内容,常以2009年数据为示例)。Music版块数据表与公共表(如username、favorites)之间的参照关系参见图1。
2.2 研究思路
社交博客用户分层与话题演化研究目的在于从不同语义元素(如主题、评论、标签、类别等)构成的融合了多维语义关系(如评论、标注、分类、发表等)的元网络中提取出舆情分析需要的用户及话题。根据用户在社交平台中的活跃程度(以相应指标来量化),将用户进行分层聚合,形成不同的用户群体,不同用户群体的影响力存在差异,这种差异体现的一个重要方面就是话题的热度。因此本文社交博客话题将从两方面来展示,一是以时间为轴,说明话题的时序演进。二是以用户群体为分类指标,揭示不同用户群体关注的主题。通过一定方法,对比不同参照系下的主题差异,描述用户与话题之间的关联关系。社交博客用户分层与话题演化步骤主要包括:
(1)用户分层研究:利用Music版块内用户与不同节点元素形成的语义关系(如用户评论关系、用户标注关系等)构建社会网络,分层识别2009~2013各年度社交用户及其群体。不同用户群体对社交网络的影响力不同,其在社交网络中话语权也存在较大差别,用户群体划分的合理与否将对话题识别、用户与话题之间关联关系梳理等内容产生较大影响,藉此用户分层研究将采用聚类分析与复杂网络分析相结合的方法。
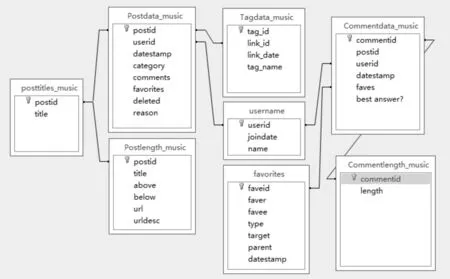
图1 MetaFilter中Music版块的数据集结构解析[9]
(2)话题演化分析:话题时序分析,揭示不同时期用户关注主题的分布情况。该部分将利用话题与不同节点元素之间的关系(如话题发布、话题评论等)构建社会网络,利用时序分析与聚类分析相结合的方法,判断2009~2013年话题演化的趋势,分析结果将作为用户与话题之间关联关系分析的参照数据。
(3)用户与话题关联关系分析:该部分内容将结合(1)(2)来展开,以时间为连接点,采用话题重合度与加权余弦相似度指标来集中判断用户、时间、话题三者之间的关系,说明用户与话题之间关联程度及方向。
3研究发现
3.1 社交博客用户分层
社交博客用户分层的本质就是聚类,聚类分析通过预设的算法量化了一段时期内社会语义网中的各个类群集合及其特征,其常用分析方法包括系统聚类、K-means、多维尺度分析等,聚类结果呈现方式包括树形图、冰柱图和战略坐标图。本文采用复杂网络及其可视化工具来进行聚类分析,其分析步骤包括:
(1)获取用户评论数据,生成用户关系网络:通过数据库表间的多表连接操作,可获取2009~2013各年度用户关系网络,其规模参见表1。
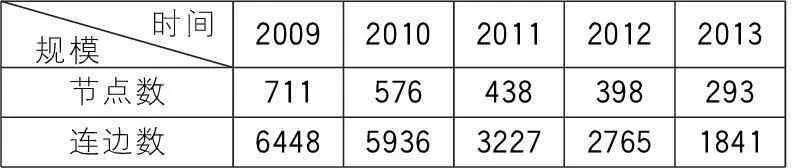
表1 各年度Music版块用户评论关系
(2)生成复杂网络:利用txt2pajek格式转换工具将数据库导出的记录形式的文本数据转换为复杂网络分析的.net文件,实际上完成了从邻接表到网络的转化,其网络“核心-边缘”结构利用pajek自带的可视化工具可大致呈现,参见图2。
(3)筛选核心用户群:如果用户间关联强度阈值设置为0,以2009年Music版块用户关系网络为例,获取的用户群体有80个,其中单节点群体有22个。这种形式获取的用户群同质性比较高,群体之间的差异性较低,因此为筛选核心用户群必须提升用户间关联强度阈值。本文假定“核心用户群体”集合占对应年度用户集合的比例为1%。利用VosViewer工具,通过不断调整用户关联强度阈值,可获取2009、2010、2011、2012和2013年的“核心用户群体”集合,参见表2,集合大小分别为7、6、4、4和3。

图2 Music版块2009年用户关系网络“核心-边缘”结构[9]
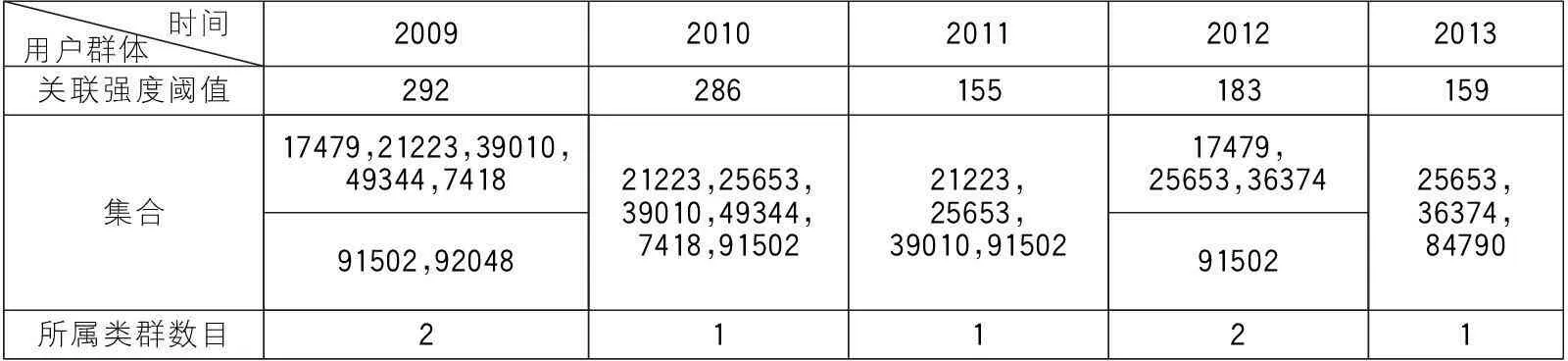
时间用户群体20092010201120122013关联强度阈值292286155183159集合17479,21223,39010,49344,741891502,9204821223,25653,39010,49344,7418,9150221223,25653,39010,9150217479,25653,363749150225653,36374,84790所属类群数目21121
注:表2中“集合”一行部分单元格进行了拆分,用于表征不同类群。数字代表用户的userid。
3.2 社交话题演化分析
tag是大众分类法的产物,用户标注的tag反映了用户关注的主题,也反映了一段时间内社交博客中的热点话题,为此笔者以用户标注的tag为基础数据,对社交话题时序演化情况进行了分析。
(1)tag分布规律:MetaFilter数据集中有描述post title和tag的数据表,其中post title相当于被标注的对象,tag表示对象的标注词。以Music版块为例进行了分析,可得出以下结论:①tag在其对应主题中的title keywords中出现的次数为1407,占posttitles_Music与tagdata_music连接获取记录数(18741)的7.5%,而CiteULike中的比例为31.97%[10]。这种差别主要源于两方面原因:一是MetaFilter用户更为多元,而CiteULike用户多为从事科研活动的人员,信息素养相对较高;二是MetaFilter标注对象多为自然语言文本,随意性比较大,而CiteULike中标注对象为学术资源。②出现title keywords的tag共有985个,最高频次为50,tag分布情况参见图3。依据图3,发现tag使用频次及分布符合幂律,这与Chen等通过CiteULike分析结果基本一致[10],但CiteULike中tag分布的倒J曲线要更陡峭,这说明CiteULike中用户tag标注用词更为集中,MetaFilter中tag用词更为广泛,这与①中分析也形成了参照。
(2)主题可视化分析:在posttitle中tag使用频次及分布规律分析的基础之上,利用可视化工具Vosviewer,笔者接着以tag为视角透视了用户主题标注的演化,为与3.1分层用户群相对照,Music版块中tag数据被切分到五个周期:2009、2010、2011、2012和2013,2009年热点社交话题参见图4。图4中mefiMusicchallenge、guitar、cover等音乐形式是2009年Music版块社交用户关注的重点话题。
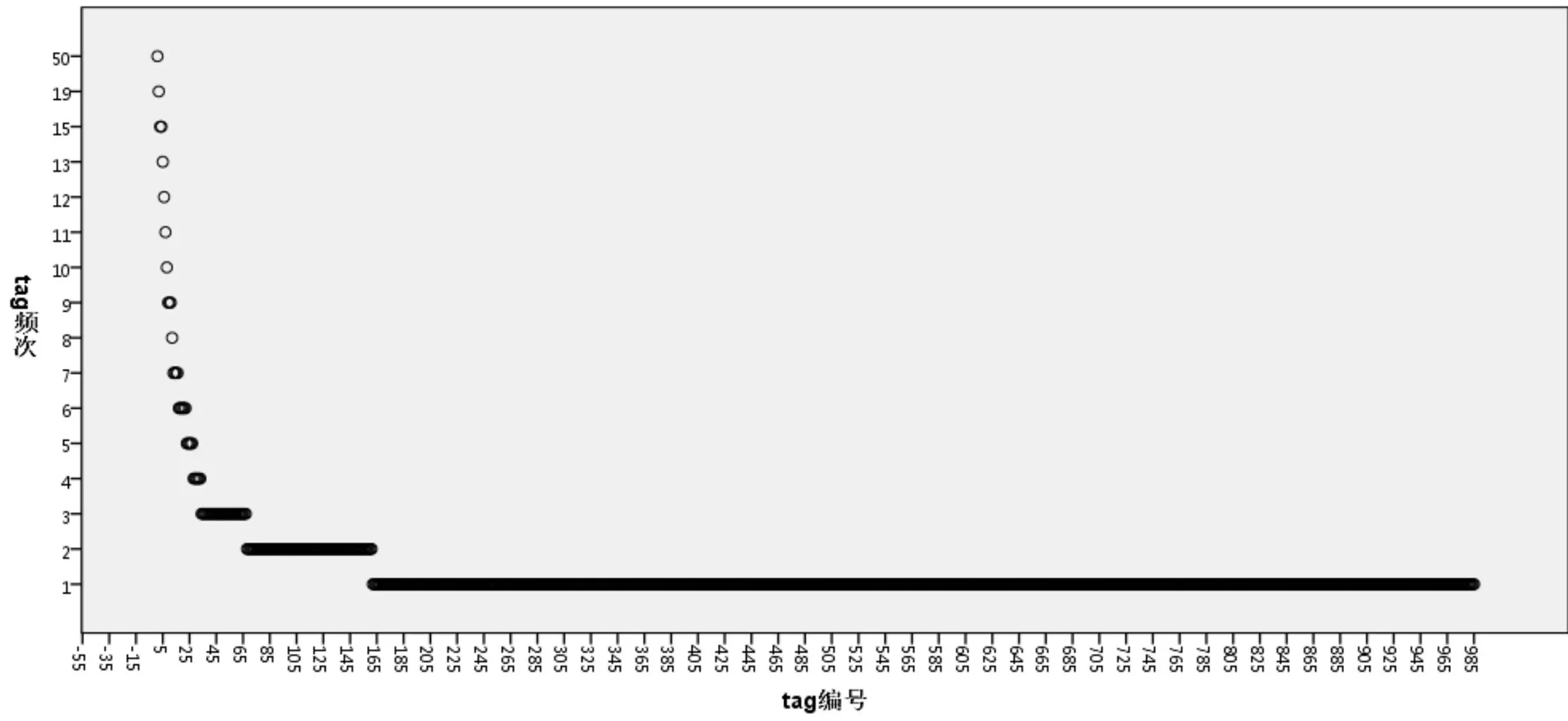
图3 tag使用频次及分布规律

图4 2009年热点话题分布态势
(3)热点话题时序分布:除了2009年以外,笔者还对2010~2013年社交用户关注的10大重点音乐话题进行了统计按照当年热度排序结果参见表3。
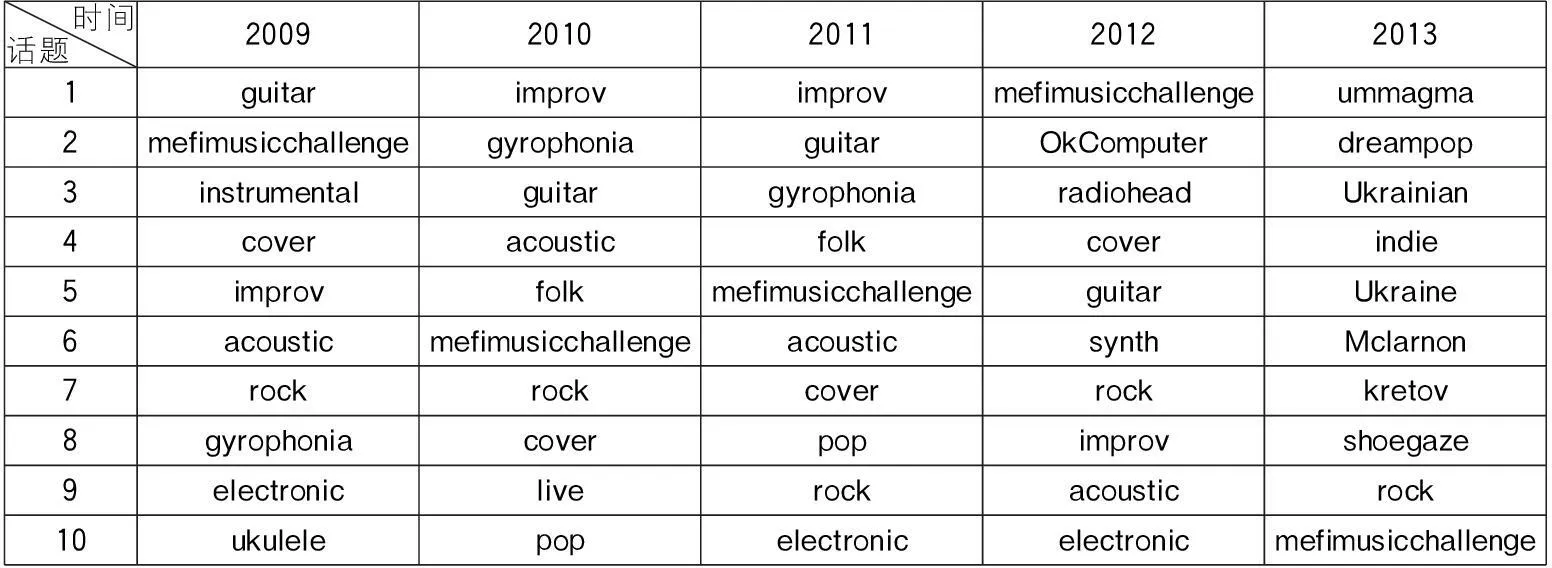
表3 2009~2013用户标注热点话题演化过程
(4)热点话题演化结论:通过图4及表3分析可发现,用户主题标注基本符合版块特色,主要围绕音乐类型或器材(如guitar、pop、rock、contrabassoon等)、音乐活动或表演形式(mefimusicchallenge、improv、solo等)、音乐专辑或团体(如thechrismasablum、cover pop等)、音乐主题(如vampire、love等)等来展开。随着音乐形式的不断发展,用户主题标注也在不断演化。以MetaFilter力推的音乐形式mefimusicchallenge为例,其在不同年份的热度起伏不定,在2009、2012年最为流行,在2010~2011年热度不减,但被更多个性且独立的音乐形式(如improv、gyrophonia)所超越,但依旧是用户关注的重点。2013年则排名垫底,呈现出明显的下滑趋势。
3.3 社交博客用户与话题间的关联
3.3.1关联分析背景
笔者将聚类分析与复杂网络分析相结合,按照时间顺序对Music版块核心用户群进行了分层处理。同时,结合时序分析与复杂网络分析,统计了各年度用户关注的10大话题,并按照热度高低进行了排序,参见表3。两种形式都是以时间为参照对象,分别说明了用户群体随时间的演化规律和社交话题的迁移变化。
(1)2009~2013年用户群体的演化可以通过用户角色迁移来体现:userid为91502和25653的用户,长期活跃于社会网络中,能够适应主题和时间的变化;userid为7418、21223、49344、36374和39010的用户,他们在一段连续时间内(最少为两年)比较活跃,适应性较好;userid为92048,84790和17479的用户,他们稳定性较差(不超过两年且非连续),随时间和主题变动比较大,迁移性比较强。
(2)同理,社交话题的迁移通过表3也可以清晰地展现出来。有些音乐形式如mefimusicchallenge、guitar、improv、cover、rock等长期活跃于Music版块,是广受用户欢迎的音乐形式;有些音乐形式如acoustic、gyrophonia等在一段时间内比较流行,之后热度逐渐消退。
但上述分析方式无法考察核心用户群体对热点话题的影响程度,为此笔者将逐年提取核心用户群体关注的热点话题,与当年整个用户群体关注的热点问题进行对比分析。如果二者表现出一定程度的一致性,则说明核心用户群体的影响力对当年热点话题的产生具有较大程度的影响。如果二者表现出较大程度的差异性,则说明核心用户群体的影响力对当年热点话题产生的贡献度不高,热点话题产生具有一定的偶发因素,与较为分散的非核心用户群体关联性更强。
3.3.2关联分析过程
依据3.3.1关联背景分析,本文提取表2核心用户群标注的话题信息,采用3.2社交话题抽取方法,将tag关联强度阈值控制与聚类分析相结合,获取2009~2013年核心用户群标注的10大话题,参见表4。
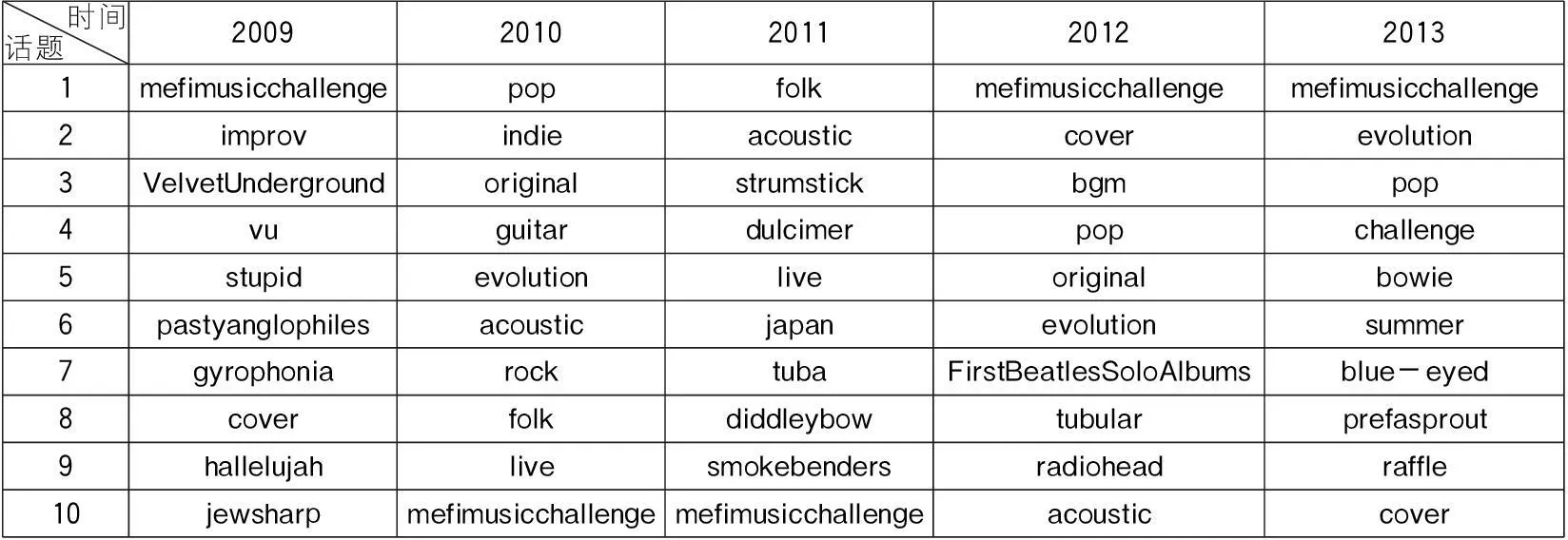
表4 2009~2013核心用户群标注话题演化过程
将表3和表4统计结果进行对比,对比算法采用话题重合度和加权余弦相似度计算,计算过程建立在“核心用户群与整个用户群体关注热点越高的主题一致性越好,则二者相似度越高”这一假设基础之上,这一方面是为了规避单一采用话题重合度所造成的系统误差,误差源于没有考虑话题热度的影响或将所有话题热度定义为一致;另一方面也是为了从话题内容角度更加清晰地量化核心用户群体与整个用户群体话题相似度。
基于上述假设,算法过程可描述为:
(1)统计各年度热点话题重合的数量,并计算话题重合度。
(2)单采用话题重合度来评测核心用户群对热点话题的影响还不够,基于“表3和表4热度越高的主题一致性越好,则相似度越高”这一考虑,笔者还采用加权余弦相似度计算方式来进一步完善对比方法。按照热度顺序分别赋予各年度热点话题一定权重,热度最高的话题权重为10,逐次递减1,则热度最低话题权值为1。
(3)在确认各年度各个话题权重后,构建各年度热点话题特征向量,如2009年整体用户标注话题特征向量为V09=((guitar,10),(mefimusicchallenge,9),(instrumental,8),(cover,7) (improv,6),(acoustic,5),(rock,4),(gyrophonia,3),( electronic,2),(ukulele,1))。计算同年度整体用户热点话题特征向量与核心用户热点话题特征向量的相似度,相似度计算通过特征向量夹角余弦值来衡量,计算结果参照表5。

表5 整体用户标记话题与核心用户群标记话题相似度统计
3.3.3关联分析结论
由表5可获取关联分析相关结论,主要体现为:
(1)话题重合次数越多并不一定相似度越高。对比2009、2012与2010统计结果,2010年重合话题比例为70%,远高于2009年的40%和2012年的30%,但相似度为0.3740,低于2009年的0.4597和2012年的0.4286,这源于2010年统计的重合话题的整体热度排名要低于2009年和2012年,同时间接证明本文所做基本假设“热度越高的主题一致性越好,则相似度越高”是符合实际情形的。
(2)核心用户群标记的热点话题与整体用户标记的热点话题重合比例为36%,相似度值为0.3205,从数值分析的角度来讲,这说明核心用户群对整个社交博客热点话题的衍生具有一定的影响力,并不显著,但如果注意到本文分析的核心用户群占当年度整个用户群体的比例仅为1%,则可见核心用户群体对热点话题的影响是显著的。本文核心用户群比例设置相对严格,如果扩展核心用户群占整体用户群体的比例,则核心用户群体对热点话题的影响力将更加显著。
(3)核心用户群的对立面是非核心用户群,之前已经说明tag标注呈现幂律分布,由于互联网长尾效应的影响,通过数值分析可知非核心用户群对热点话题也有一定影响,是社交博客运营方不可忽视的重要群体,尽管其影响是分散的。
4结语
本文将时序分析、聚类分析与复杂网络分析相结合,对社交博客用户分层及话题演化进行了分析。社交博客用户分层依据用户在社交媒体中的活跃程度,评估不同用户群体对社交网络影响的大小,重点围绕核心用户群体来展开。之后,笔者又逐年分析了整个用户群体关注的热点话题,对比核心用户群体关注的热点话题,从而评估核心用户群体对热点话题衍生的影响大小。通过MetaFilter数值分析可知,核心用户群体对热点话题衍生的影响是显著的,但同时由于互联网长尾效应带来的影响,非核心用户群对热点话题衍生也具有一定影响,值得引起社交博客运营方的注意。同时需要注意的是,本文分析尚存在部分不足,主要表现为:分析数据主要来源于MetaFilter Music版块,由于不同社交主题领域的差异,其分析结果可能存在一定差异,因此需要进一步拓展主题分析领域,核实分析结论的应用面。参考文献
[1]Lazarsfeld P F, Berelson B, Gaudet H.The People’s Choice: How the voter makes up his mind in a presidential campaign[M].New York: Columbia University Press, 1948:1-178
[2]尹衍腾,李学明,蔡孟松.基于用户关系与属性的微博意见领袖挖掘方法[J].计算机工程,2013,39(4):184-189
[3]蒋翠清,朱义生,丁勇.基于UGC下的意见领袖发现研究[J].情报杂志,2011,30(10):82-85
[4]Xu W W, Sang Y, Blasiola S, et al. Predicting opinion leaders in Twitter activism networks: The case of the Wisconsin Recall Election[J]. American Behavioral Scientist, 2014, 58(10):1278-1293
[5]Zhang W,He H,Cao B.Identifying and evaluating the internet opinion leader community based on k-clique clustering[J]. Neural Comput & Applic, 2014(25):595-602
[6]蔡淑琴, 张静, 王旸,等. 基于中心化的微博热点发现方法[J]. 管理学报, 2012, 9(6): 874-879
[7]Sankaranarayanan J, Samet H, Teitler B E, et al. TwitterStand: News in tweets[C]//Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York:ACM, 2009, 42-51
[8]莫溢, 刘盛华, 刘悦,等. 一种相关话题微博信息的筛选规则学习算法[J]. 中文信息学报, 2012, 26(5):1-6
[9]李纲,叶光辉,张岩.“小众专家”特征识别——基于MetaFilter的实证分析[J]. 现代图书情报技术, 2015,31(6):71-77
[10] Chen Y, Ke H. A study on mental models of taggers and experts for article indexing based on analysis of keyword usage[J].Journal of the Association for Information Science and Technology,2014, 65(8):1675-1694
Research on User Classification and Topic Evolution in Social Blog: Empirical Analysis Based on Music Section in MetaFilter Dataset
Du HaiyanYe Guanghui
(School of Information Management of Wuhan University, Wuhan 430072)
[Abstract]Combined with time series analysis, cluster analysis and complex network analysis, this paper analyzes user classification and topic evolution in social blog. Firstly, according to the user activity in the social media, the authors set the threshold of relationship intensity and extract the core users. Secondly, this paper does the statistics of the annual hot topics concerned by the whole community. Finally,with comparing to hot topics tagged by core users, empirical analysis shows that the core users has significant impact on the derivative of hot topics and non-core users should not be ignored for the long tail effect.
[Key words]Social blogTopic evolutionMetaFilterUser classification
(收稿日期:2015-09-18)
DOI:10.13365/j.jirm.2015.04.039
[中图分类号]G350
[文献标识码]A
[文章编号]2095-2171(2015)04-0039-08
[作者简介]杜海燕,女,硕士研究生,研究方向为网络信息资源管理;叶光辉,男,博士研究生,研究方向为信息资源组织与分析。
[基金项目]本文系国家自然科学基金青年项目“多因素融合下的微博话题可信度评估模型及实证研究”(71303179)、武汉大学自主科研项目“跨学科专家科研团队发现研究”(2014104010202)和2014年武汉大学人文社会科学青年项目“基于引证链接的网络文献可追溯性研究”研究成果之一,受到中央高校基本科研业务费专项资金资助。
猜你喜欢
消费电子(2021年6期)2021-07-17
科学与社会(2020年4期)2020-03-07
当代水产(2019年11期)2019-12-23
求知导刊(2019年17期)2019-10-18
作文通讯·高中版(2017年6期)2017-07-10
网络空间安全(2016年3期)2016-06-15
黑龙江史志(2014年12期)2014-11-24
中国有色金属(2014年23期)2014-03-13
