
LDA模型下文本自动分类算法比较研究——基于网页和图书期刊等数字文本资源的对比
2015-03-07 12:01李湘东
信息资源管理学报 2015年4期
李湘东 潘 练
(1.武汉大学信息管理学院,武汉,430072; 2.武汉大学信息资源研究中心,武汉,430072)
LDA模型下文本自动分类算法比较研究——基于网页和图书期刊等数字文本资源的对比
李湘东1,2潘练1
(1.武汉大学信息管理学院,武汉,430072;2.武汉大学信息资源研究中心,武汉,430072)
[摘要]本文以信息资源管理中的网页、图书期刊的书目或题录信息等主要数字文本为对象,使用概率主题模型(LDA)建模,通过对比分析KNN、类中心向量法、SVM等三种常见的分类算法所产生的不同分类效果,研究数字文本资源管理中的自动分类特性。实验表明LDA模型下三种分类算法的分类正确率基本都能达到80%左右,SVM算法分类准确率相较另两种算法大约高0.7~22%左右。本文的结论可为数字文本分类系统使用LDA对文本建模时选择合适的分类算法提供一定的依据。
[关键词]LDA数字资源书目信息自动分类分类算法
1前言
信息技术的迅猛发展和网络的普及应用产生了海量的信息数据,因此,研究与开发高效准确的信息资源分类系统和技术,以实现对大规模信息资源进行科学的组织管理显得尤为重要。随着信息资源数字化的深入发展,网页、图书的书目信息、期刊论文的题录信息甚至全文等大部分信息资源通过数字化的形式存储和传输,并以文本的形式保存下来,形成数字文本资源等信息资源管理的主要对象。文本分类就是指在带有类别标签的文本集合中,根据每个类别的文本子集合的共同特点,找出一个分类模型,以便在后续过程中将未标识文本映射到已有类别的过程[1]。近年来有关文本分类的研究集中在文本表示和分类算法两个方面。文本表示是将自然语言文本这一非结构化的数据转化为结构化可处理信息的过程,即文本的形式化处理的过程。文本表示方法通常采用向量空间模型VSM( Vector Space Model);随着研究的深入,研究者们试图利用统计方法的基本思路即挖掘文本的主题信息来拓展模型的种类, 其中典型的代表是由Deerwester 和Dumais 等人提出的隐含语义索引(LSI)[2]方法及其对应的概率化改进版PLSI[3]。LSI方法因其降维作用较为显著,在文本分类应用中得到了较为深入的研究,其缺点是最终的分类性能受损且模型的参数空间和训练数据呈正比变化,因此对大规模或动态增长的语料库进行建模时十分不利[4]。面对这些问题,研究者借鉴近年发展起来的概率图模型理论和方法, 提出了一系列主题模型(Topic Models) , 主要是以LDA( Latent Dirichlet Allocation)[5]为代表的系列模型。另一方面,分类算法作为构建分类模型的基础,由于直接影响了分类的效率和效果,成为文本分类的主要问题之一,受到研究人员广泛的重视和关注。
由于文本分类算法的优劣决定了文本分类最终效果的高低,比较不同分类算法所得的分类结果就显得十分必要。本文针对网页、图书和期刊论文等主要数字信息资源,抽取来自图书馆OPAC的图书书目信息、来自电子期刊数据库的期刊题录信息,并使用公开语料库的网页实验材料为参照对象,在统一的文本表示即概率主题模型(LDA)的基础上,分析和比较了三种常用的分类算法(K近邻分类、类中心向量、支持向量机)对这些信息资源开展文本分类时的特性,希望通过这些实验研究,分辨出不同分类算法的优劣与特点,为信息资源管理中数字文本资源的自动分类等相关研究的实际应用以及分类算法的选择提供参考来源和依据。
2国内外研究现状
文本分类算法一般基于引入和改进机器学习领域的成果,使文本分类进入基本可实用的阶段,目前常用的分类算法有:类中心向量、K近邻分类(以下简称KNN算法)、朴素贝叶斯算法、神经网络、支持向量机(以下简称SVM算法)、决策树算法等。不同算法的特点性质各不相同,已有许多国外学者使用外文语料库对各种算法的特性进行研究,如Yang和Liu选用路透社发布的Reuters-21578语料库,对五种分类算法进行了评估,得到结论是SVM的分类效果与KNN和朴素贝叶斯相比更优[6]。基于同样的语料库,文献[1]总结了前人的结论,并在文献中对四种分类算法进行对比,以F1值的对比结果来看,SVM仅高出KNN算法约4%左右,而类中心与朴素贝叶斯结果相近但较前两者准确率更低。Zu和Ohyama从Reuters-21578语料库中选取五类材料,比较了五种基于欧几里得距离的分类算法的分类正确率,结论发现在维数较多(450-600)的情况下,基于RBM核的SVM分类比线性SVM和其他分类法取得了更好的分类效果[7]。Chen与Bogen使用1954~2011年ACM元数据和Ensemble中一系列真实数据,比较了如KNN和朴素贝叶斯等分类法的准确率和分类效率,比较下发现KNN算法能更好帮助完成对训练集对分类器的训练,并在此基础上提出了一种使用现有数据来构建分类器的方法[8]。国内研究方面,陈立孚、周宁等人使用9种不同中文语料,比较了KNN算法和SVM算法,得到SVM算法分类效果更好的结论[9]。周文霞采用了复旦大学自然语言处理实验室提供的基准语料对几种分类算法进行了测试,这一基准语料分为20个类别,得到的结果是SVM和KNN明显优于贝叶斯,且这三种分类法得到的F1值都比类中心向量法高[10]。陈琳等人使用搜狗公开语料,从分类效果和运算时间两个角度综合而全面比较了KNN、贝叶斯和SVM三种分类算法的分类效果,认为从综合角度考虑,SVM算法效率更好[11]。张野等人针对搜狗语料库,分别使用六种不同特征选择方法和不同的分类维度,比较了KNN算法和SVM算法,也得出SVM明显要优于KNN的结论[12]。
然而以上的研究都是基于传统的向量空间模型,基于其他模型的相关研究相对较少,如2007年刘美茹利用潜在语义索引(LSI)进行特征提取和降维,并结合SVM算法进行多类分类,实验结果显示与向量空间模型结合SVM方法和LSI 结合KNN方法相比,取得了更好的效果[13]。目前也还没有文章结合概率主题模型(LDA),基于图书信息和期刊题录信息等真实数据来对比不同分类算法的分类效果,为信息资源管理领域的数字文本寻找合适的分类算法提供依据,本文希望能弥补这一缺失。
3相关分类工作的原理
3.1 文本分类的一般步骤
文本分类一般包括文本预处理、特征项选择、文本表示、分类算法的选择、分类效果评价等过程,主要是由训练阶段和测试阶段这两部分组成的,训练阶段主要是通过给定的训练集和分类模型,通过采用文本预处理和特征选择等一系列方法来形成适用的分类器,测试阶段是通过训练阶段生成的分类器,判断分类文本所属的类别,并将其归至某一类别的过程。
3.2 文本分类算法
3.2.1K近邻分类法(KNN)
KNN算法也称为K近邻分类法(K-nearest neighbors),其基本思路是计算新文本与训练集其他文本的距离值(即相似度),得到距离最接近或相似度最高的K个文本,通过这K个文本所属的分类来判断待分类文档的类别。K近邻分类法操作简单方便,当向训练样本集中加入新的文本时,不需要重新训练,算法效率较高[14]。
3.2.2类中心向量
类中心向量法,也称为Rocchio分类算法或相似度计算法,其基本思想是根据算术平均为每一个类别的文档集生成一个代表该类别的中心向量,利用待分类文档与每个类别的中心向量的相似度大小来完成分类。
计算待分类的文本向量与各个类别向量的关系值有欧几里得距离和余弦相似度两种算法。Rocchio 算法对于那些类间距离比较大而类内距离比较小的类别分布情况能达到较好的分类效果,而对于那些不满足这种“良好分布”的分布情况,Rocchio 算法的分类效果可能会比较差[15]。
3.2.3支持向量机(SVM)
支持向量机(Support Vector Machine)建立在统计学习理论和结构风险最小原理基础之上的[16],是一种将不可分的有限样本从低维特征空间中变换到高维特征空间来提高其可分类性的算法。
支持向量机是基于线性可分情况下的最优分类面提出的。它在特征向量空间中找到一个决策面(decision surface),这个面能“最好”地分割两个分类中的数据点,为了定义“最好”分割,支持向量机引入两个分类的分类间隔(margin)的定义:即两个决策面之间的距离[17]。当分类间隔越大时,分类效果越好的,即为好的分类模型。
3.2.4分类器性能评估
为了更好地评价文本分类器的性能,国际上广泛采用微平均和宏平均相结合的评价准则,并使用查准率(Precise)、查全率(Recall)和F1值来对比算法的优劣。本实验采用常用的将查全率和查准率结合起来的性能评价方法即微平均Micro_F1值和宏平均Macro_F1值,计算公式如下:
(8)
(9)
其中,R代表的是类别的查全率,定义为正确判别为正例的测试样本的个数占正例样本个数的比例,查全率仅与弃真样本的个数相联系,弃真样本数越高,查全率越低;而P代表类别的查准率,代表了正确判别为正例的测试样本的个数占判别为正例样本个数的比例,在同一簇分类器中,二者关系式相互制约[18]。 F1综合考虑并计算查全率和查准率以及它们的偏向度。另外,宏平均容易受小类的影响,微平均容易受大类的影响,其中,k是类别数,Ti,Ci,Ni分别表示第i类中分类正确的文本个数、分到第i类中的文本个数和第i类中实际包含的文本个数。
3.3 LDA模型
LDA 模型是一种对离散数据集(如文档集)建模的概率增长模型。它的理论基础是假设文档是由若干个隐含主题构成,而这些主题是由文本中若干个特定词汇构成,文档中的句法结构和词语出现的先后顺序被忽略。如图1所示,假设文档集合(顶部大圆)可以分成若干隐含主题(实心圆),而隐含主题又由若干特定词汇构成(底部小圆)。
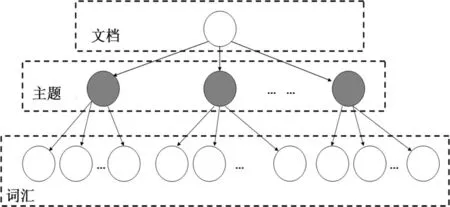
图1 LDA隐含主题的拓扑结构示意图
图2所示,LDA 模型是一种典型的有向概率图模型,它拥有三层生长式贝叶斯网络结构,依次为文档集合层、文档层和词层。LDA 模型由文档集合层的参数(α,β) 确定,α代表文档中隐含主题间的相对强弱,可理解为获得文本集中以前主题被抽样的次数,β代表所有隐含主题自身的概率分布,可理解为见到文本集中的特征词以前从主题抽样获得的特征词频数,两个超参数一般设置为α= 50 /T,β= 0.01[4]。随机变量θ代表文档层,其分量代表目标文档中各隐含主题的比重。词层中Z表示文档分布在每个词上的隐含主题比例,W是目标文档的词向量表示形式。
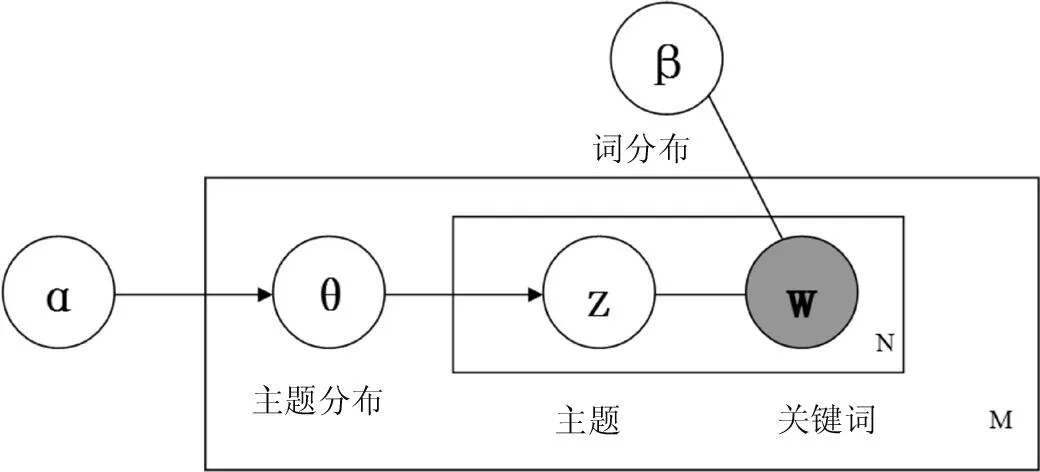
图2 LDA模型图
用于文档集主题建模的LDA主题模型的符号定义如下:
(1)词是文本数据的基本单元,是用{1……V}索引的词表的分项。词表中的第V个词用一个V维的向量W表示,其中对于任意μ≠v,WV=1,Wμ=0;
(2)用d={w1,w2,w3……wn} 表示文档,wn是文档序中的第n个词;
(3)D是M个文本的集合,对于给定的文本集D,表示为D={d1,d2,d3.....dM}。
构建并使用LDA 模型的核心问题是隐含变量分布的推断[19],即获得目标文档内部隐含主题的构成信息。LDA概率主题模型生成文本的过程如下:
(1)对每个不同主题j,根据狄利克雷分布Dir(β)得到该主题上面的一个单词多项式分布向量φ’;
(2)通过泊松分布Poisson(ξ)得到文本的单词数N;根据狄利克雷分布Dir(α)得到文本的相应主题分布概率向量θ;
(3)对该文本N个单词中得每个单词Wn。
假设文档集中有D个文档,隐含K个独立的主题,则所给文本中的第i个词汇Wi出现的概率为:
(10)
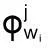
(11)
4基于LDA模型的文本分类
4.1 分类过程简介
基于LDA的文本分类的具体过程如下:
(1)预处理阶段,主要是进行分词和去除停用词。语料库经过中科院分词系统ICTCLAS进行分词,去除停用词;
(2)对不同主题数,采用LDA模型对训练集进行分析建模,确定最优主题数,使模型对于语料库数据中的有效信息拟合最佳,参数推理采用Gibbs抽样,迭代足够多次数,获得训练文本的文本-主题矩阵和主题-特征词矩阵;
(3)在上一步得到的文档集的隐含主题-文本矩阵上训练、构造文本分类器,从而得到分类模型(本文分别使用不同分类法);
(4)运行GibbS抽样算法,迭代较少的次数,计算分类文本d的隐含主题集的概率分布情况;
(5)根据分类模型,预测待分类文本的类别。
4.2 最优主题数的确定
语言模型中标准的评判准则采用困惑度(perplexity)评价各种LDA模型的性能。在训练集上训练得到最优LDA模型,通过计算一个给定训练集合的困惑度可以评价该模型产生文本的能力,困惑度越低模型推广性越好,困惑度的公式为:
(12)
其中,M为文本集中的文本数,Nm为第m篇文本的长度,P(dm)为LDA模型产生第m篇文本的概率,公式为:
(13)
5实验及结果分析
5.1 实验材料说明
本文实验材料首先选择搜狗公开语料库(http://www.sogou.com/labs/dl/t.html)作为实验材料,选取库中的三个主题内容各不相同的语料,并在此基础上分别增至五种、七种主题材料。实验数据共涵盖来自文化、科技、经济、环境、历史、物理、体育共计七种不同内容的材料,每个类随机抽取200篇作为训练集,100篇作为测试集,训练集和测试集之间无重复,训练集和测试集均包含文章的题名和摘要。
另外,为了增强本研究在信息资源管理领域的实用性,本文根据图书书目信息和期刊论文标题与摘要等信息资源管理领域真实数据自建语料库进行试验。图书语料获取自武汉大学图书馆馆藏书目数据库(http://opac.lib.whu.edu.cn/),包括计算机技术、军事和体育三个大类2009年部分中文图书文献的书目信息;期刊语料数据摘自中国知网(http://www.cnki.net/),包括了计算机技术、体育和军事三个类别,源自《计算机学报》、《体育科学》和《军事历史研究》三种期刊2007~2009年真实数据。每个类随机抽取200篇作为训练集,100篇作为测试集,训练集和测试集之间无重复,自建语料库中训练集包括材料的题名和摘要,测试集则只包括题名,图书书目信息和期刊论文对于不同分类法均进行5组实验,每次实验材料均不相同,最后取平均值作为实验结果。
5.2 实验结果与分析
本文分两步进行实验:
(1)步骤一:用困惑度确定最优主题数。为了评估LDA模型的优越性和有效性,使用Gibbs抽样获取LDA模型参数时,令α=50/T(T为主题数),β=0.01,Gibbs抽样算法训练集迭代1000次,测试集迭代100次,搜狗语料库将LDA模型主题数设置为30-100(间隔10),自建语料库主题数设置为5-50(间隔5),在不同主题数下分别运行Gibbs算法,三种语料库困惑度随主题数变化如图3~5。
使用困惑度获得的搜狗语料的最优主题数为110,但由于搜狗材料种类篇数较多,数据庞大,困惑度不一定能准确反映最好的分类效果,为了更全面对比系统的分类效果,本实验将搜狗主题数30-100(间隔10)中每种主题数都进行实验,发现最好的分类效果出现在主题数等于30时。自建语料库中图书书目和学术期刊语料库使用困惑度获得的最优主题数则分别为35和30。
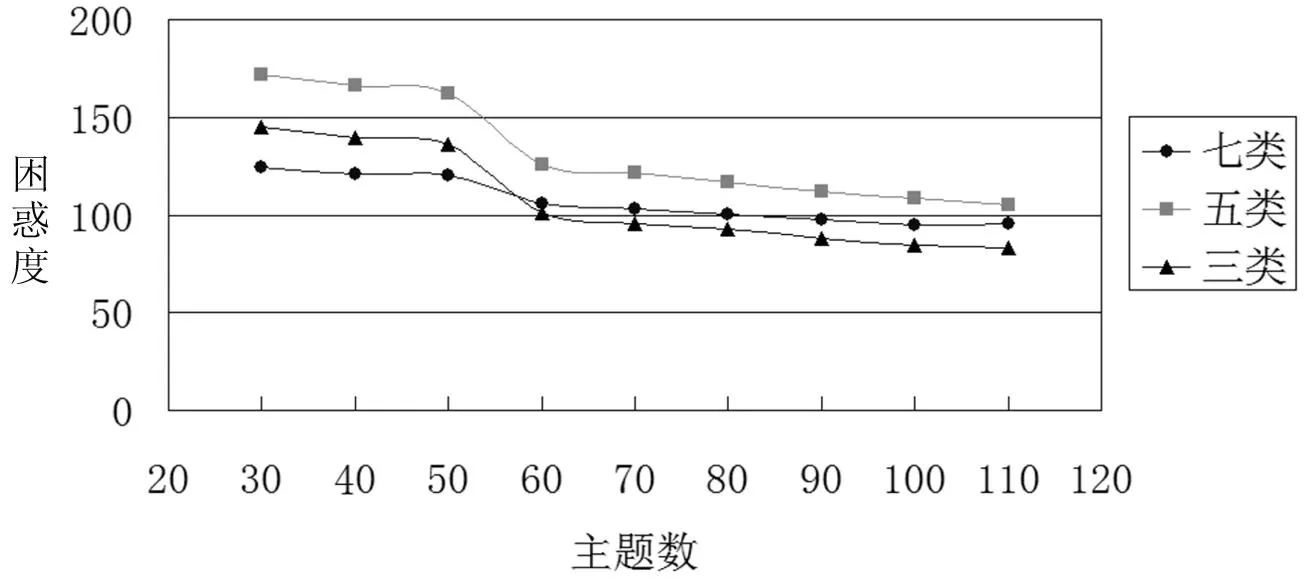
图3 三、五、七种类别材料的搜狗语料困惑度值图
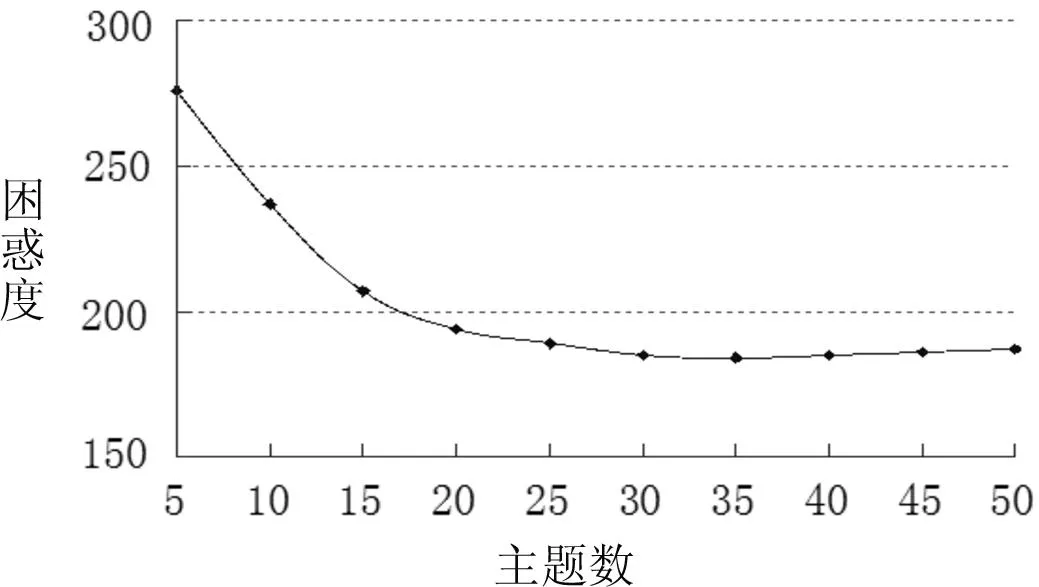
图4图书语料困惑度值
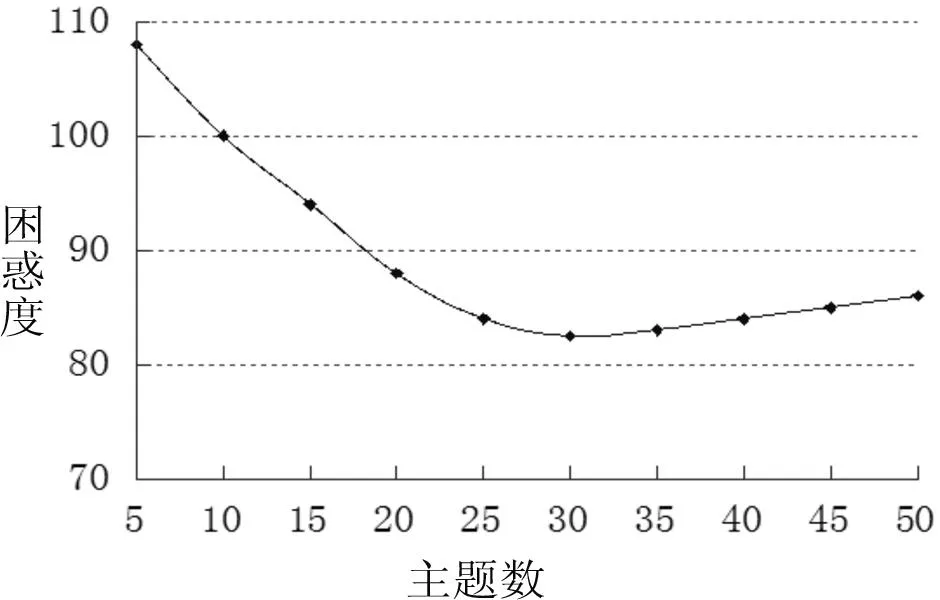
图5期刊语料困惑度值
(2)步骤二:语料库使用中科院分词系统ICTCLAS进行分词并去除停用词。使用潜在语义模型作为文本表示,在实验过程中我们同样发现通过困惑度确定的最优主题数未必会得到最好的分类效果,因此对于不同种类数的搜狗语料分别取主题数30-110(间隔10)后的分类效果进行比较,针对搜狗三种类别材料,选择分类效果最好和困惑度最小时两种情况对比结果(见表1)。图书期刊语料直接对比困惑度最小时的分类结果,抽取五组材料分别进行实验后,得到的结果平均值如表2。
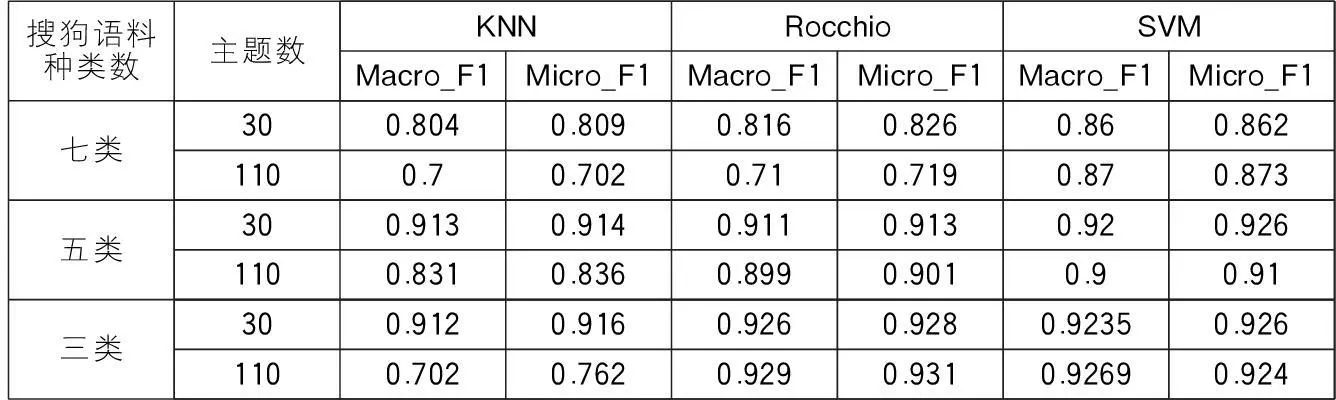
表1 搜狗语料应用不同算法的分类结果对比(两种不同主题数)

表2 图书期刊语料应用不同算法的分类结果对比
根据表1,发现搜狗语料库中处理三、五、七类语料在主题数为30时,分类结果的宏平均F1值的曲线如图6,微平均F1值如图7。观察图6与图7,两种评价指标Macro_F1和Micro_F1的所得结果类似,因此下文仅针对Macro_F1进行数据说明。以上两个表格中可知,当主题数为30、搜狗材料所涉及语料内容包括三种时,三种分类方法表现相当接近,都达到90%以上,使用类中心向量法的宏平均F1值比使用KNN算法高出1.4%,比使用SVM高出0.25%,分类准确率差距较小,三种分类算法在实验材料涵盖的范围较小或实验材料较少时,在特征值为30的情况下都表现出了较好的分类效果。同样的,当搜狗材料包含语料类别达到五种时,三种分类方法的表现都接近于91.5%左右,SVM算法略分别比另外两种算法高0.7%和0.9%。当搜狗材料包含语料类别达到七种时,SVM算法宏平均F1值较类中心向量算法高出4.4%,较KNN算法高出5.6%,由此可知当实验语料涵盖范围较广或语料数量增多后,SVM算法的适应性较高。
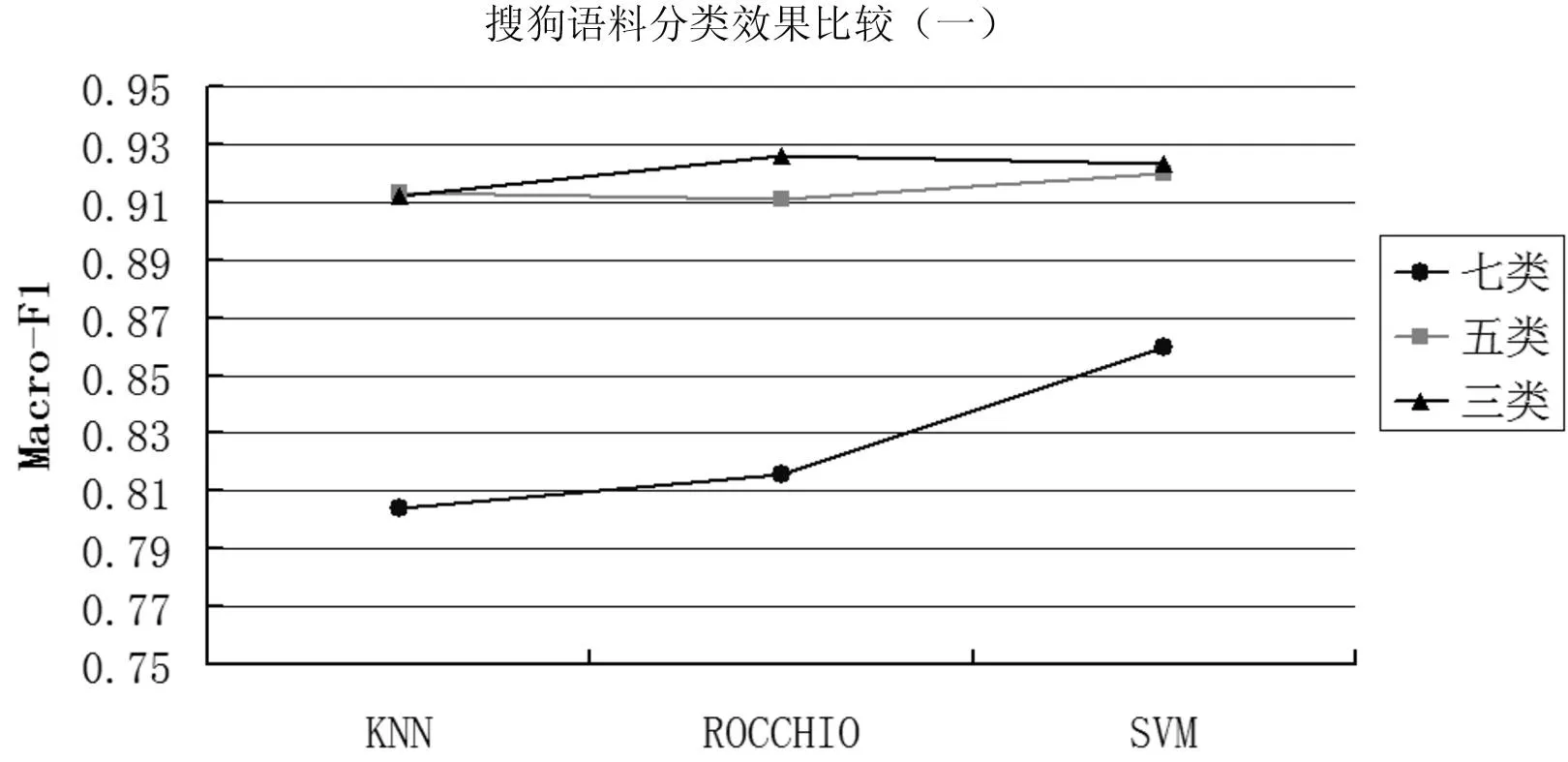
图6 主题数30时搜狗语料分类效果比较
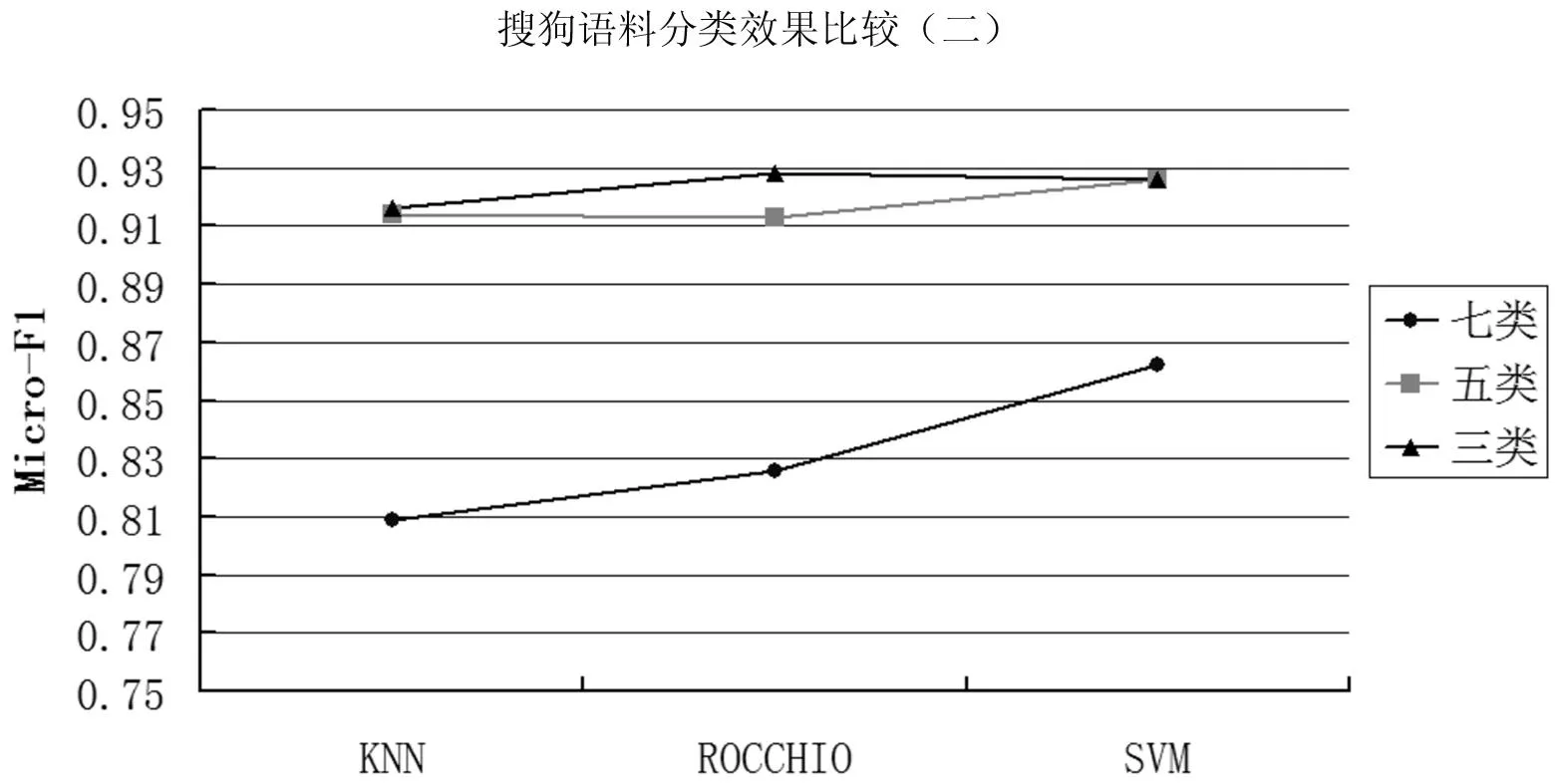
图7 主题数30时搜狗语料分类效果比较
当搜狗语料类处理三、五、七类语料时,主题数110时,分类结果的宏平均F1值的曲线如图8。当搜狗材料所涉及语料类别只有三种时,使用类中心向量法的分类宏平均F1值比使用KNN算法高出22.7%,比使用SVM高出0.21%。当搜狗材料包含语料类别达到五种时,类中心向量和SVM分类方法的表现都接近于90%,KNN算法仅有83.1%,SVM算法比KNN算法高6.9%。当搜狗材料包含语料类别达到七种时,KNN算法和类中心向量法宏平均F1值接近70%,SVM算法最高,达到87%,平均高出其他两种约17%左右,由此可知在语料及语料涉及范围增加的情况下,SVM算法仍旧表现出了较好的适应性。
图书书目和学术期刊语料分类效果宏平均F1值如图9所示。学术期刊宏平均F1值均在85%左右,其中类中心向量法的分类宏平均F1值达87.24%,较SVM算法高3%,较KNN算法高7%,此时类中心向量法更能适应学术期刊材料分类的工作,根据我们对类中心向量算法的了解,这可能是由于材料类间距离比较大而类内距离比较小的类别分布情况导致的。而对图书书目语料,SVM算法分类正确率达84%,比KNN和类中心分别高出10%和4%,分类表现明显较好,说明SVM算法相较其他二种算法能更好地适应图书书目的分类。
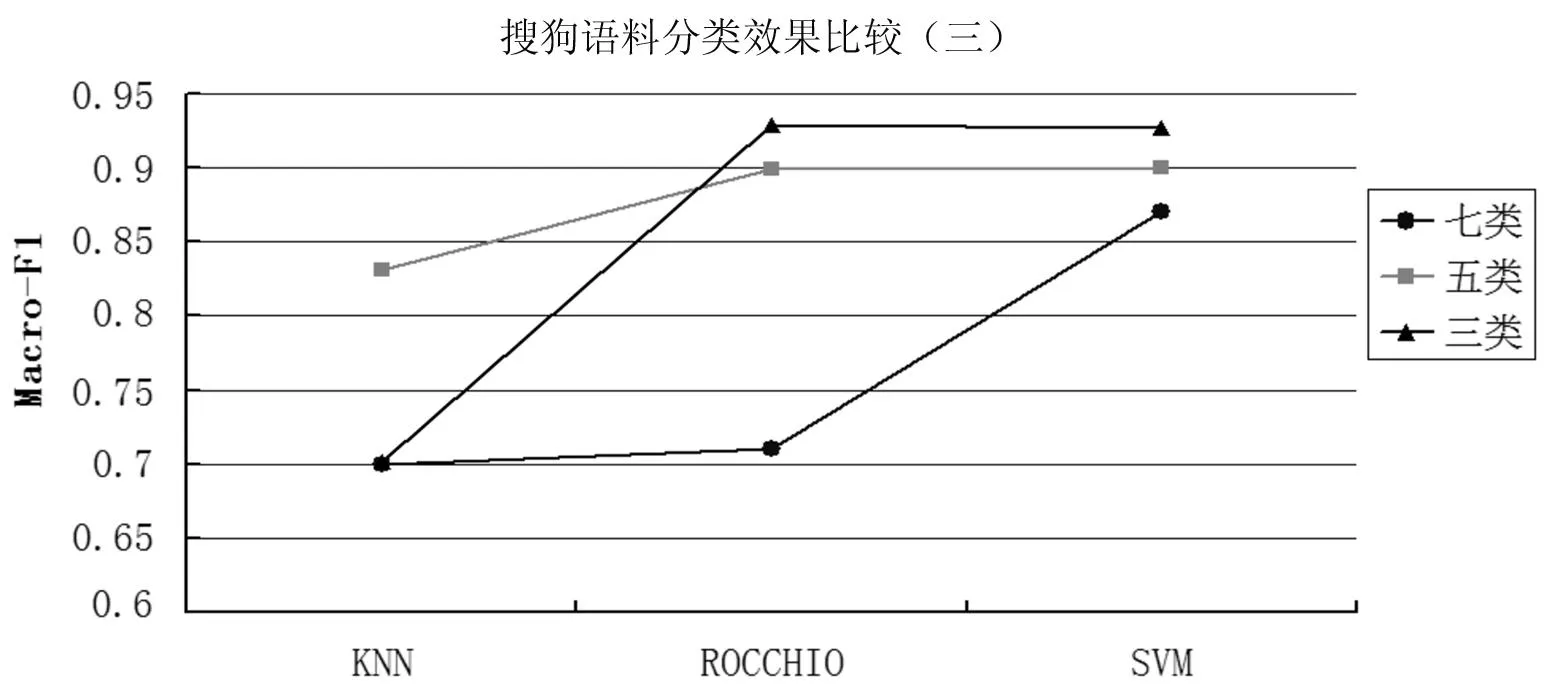
图8 主题数110时搜狗语料分类效果比较
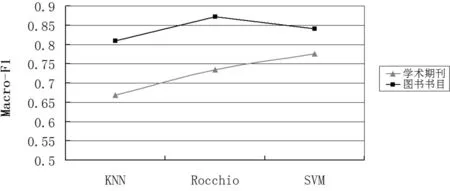
图9 图书期刊语料分类效果比较
6总结及展望
本文主要以信息资源领域的网页、图书期刊的书目或题录信息等主要数字文本资源为对象,使用LDA模型作为统一的文本表示方法,比较了常用的三种分类算法分类效果和特性,希望能分辨出不同算法在实际应用中的优劣,借此寻找更适用于信息资源管理的自动分类算法。从实验结果中得知,LDA模型环境下,三种算法中的KNN 算法模型简单,但当语料种类增多后,其分类精确度不高,尤其在对规模较大信息资源语料库进行分类时显得十分不利。类中心向量法相比KNN具有较高的分类效果,在极少数情况下与KNN相近。大部分情况下SVM算法分类准确率相较另两种算法高0.7~22%左右,极少部分情况下类中心向量法高出SVM算法0.2~0.7%,以上三种分类算法的分类正确率基本能达到80%左右。实验结果表明,在三种分类算法都能正常运行的情况下,SVM算法取得了更好的分类效果。本次实验的结果也说明不同分类方法和分类语料都对信息资源数字文本分类的结果造成不同程度的影响。本文的后续工作是进一步研究基于LDA的文本分类技术中,特征项选择法等其他因素对网页、图书和期刊等数字文本自动分类结果的影响。
参考文献
[1]Sebastiani F.Machine learning in automated taxt categorization[J].ACM computing surveys,2002,34(1):1-47
[2]Deerwester S, Dumais S T, Furnas G W, etc. Indexing by latent semantic indexing[J]. Journal of the American Society for Information Science, 1990, 41(6):391-407
[3]Hofmann T. Probabilistic latent semantic indexing[C]// Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval (SIGIR-99). Berkeley, CA, 1999: 50-57
[4]李文波,孙乐,张大鲲. 基于Labeled-LDA模型的文本分类新算法[J]. 计算机学报,2008(4):620-627
[5]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(4-5): 993-1022
[6]Yang Y,Liu X.A re-examination of text categorization methods[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval(SIGIR’99).New York,NY:ACM,1999:42-49
[7]Zu G,Ohyama W,Wakabayashi T,et al.Accuracy improvement of automatic text classification based on feature transformation[C]//Proceedings of the 2003 ACM symposium on Document engineering.New York,NY:ACM,2003:118-120
[8]Chen Y,Bogen P L,Hsieh H,et al.Categorization of computing education resources with utilization of crowdsourcing[C]//Proceedings of the 12th ACM/IEEE-CS joint conference on Digital Libraries.New York,NY:ACM,2012:121-124
[9]陈立孚,周宁,李丹. 基于机器学习的自动文本分类模型研究[J]. 现代图书情报技术,2005(10):23-27
[10] 周文霞.现代文本分类技术研究[J]. 武警学院学报,2007,23(12): 93-96
[11] 陈琳,王健. 三种中文文本自动分类算法的比较和研究 [J]. 计算机与现代化, 2012(2): 1-4, 7
[12] 张野,杨建林. 基于KNN和SVM的中文文本自动分类研究[J]. 情报科学,2011,29(9):1313-1317,1377
[13] 刘美茹. 基于LSI和SVM的文本分类研究[J]. 计算机工程, 2007,33(15):217-219
[14] 周顽,周才学. 基于扩展概念格模型的文本分类规则提取的研究[J].计算机工程与科学,2010,(08):98-100,103
[15] 李淑英,杜丽娟. 浅谈文本分类技术[J],中国科技博览,2009(12): 244
[16] 张学工. 关于统计学习理论与支持向量机[J]. 自动化学报, 2000, 26(1): 32-42
[17] 翟林, 刘亚军. 支持向量机的中文文本分类研究[J]. 计算机与数字工程, 2005, 33(3): 21-23, 45
[18] 宋枫溪,高林. 文本分类器性能评估指标[J]. 计算机工程, 2004, 30(13):107-109, 127
[19] Wainwright M J, Jordan M I.A variational principle for graphical models[A]//Haykin S, Principe J, Sejnowski T, etc. eds. New Directions in Statistical Signal Processing: From Systems to Brain. Cambridge, MA: MIT Press, 2005: 155-202
Text Classification Algorithms Using the LDA Model: On the Comparison of the Applicaitons on Webpages and eTexts Including Books and Journals
Li XiangdongPan Lian
(1.School of Information Management, Wuhan University, Wuhan 430072;2.Center for the Studies of Information Resources of Wuhan University, Wuhan 430072)
[Abstract]The object of this research is the bibliographic information and other major digital text of Webpage, books and journals in the information resource management. Based on the LDA model, this paper studies the characteristics of automatic text classification in digital resources management,and analyzes the different effect and influence of three kinds of common classification algorithm which including KNN, SVM and Rocchio algorithm. The experiment shows that the accuracy of three classification algorithms basic is about 80%, while in most cases SVM algorithm having 0.7~22% higher classification accuracy than the other two algorithms. Its conclusion may provide a certain basis for choosing the appropriate classification algorithm when LDA model is using in digital information classification system.
[Key words]LDADigital resourcesBibliographic informationClassificationClassification algorithm
(收稿日期:2014-09-11)
DOI:10.13365/j.jirm.2015.04.024
[中图分类号]TP391;G202
[文献标识码]A
[文章编号]2095-2171(2015)04-0024-08
[作者简介]李湘东,博士,副教授,研究方向为自动分类、数据挖掘,Email:xli_xiao@hotmail.com;潘练,硕士生,研究方向为自动分类。
猜你喜欢
通信技术(2021年12期)2022-01-25
电脑报(2020年30期)2020-08-11
天津外国语大学学报(2020年1期)2020-03-25
通信产业报(2019年31期)2019-10-21
综艺报(2018年15期)2018-08-15
CHIP新电脑(2016年11期)2016-12-03
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
