
基于数据挖掘技术对精神科病人住院天数的预测
2015-03-05 02:34金华市第二医院李汝庆
电子世界 2015年17期
金华市第二医院 李汝庆
基于数据挖掘技术对精神科病人住院天数的预测
金华市第二医院 李汝庆
【摘要】本文以某精神专科医院5年出院病人数据为基础,预测住院天数为例,介绍数据挖掘的基本应用过程。在数据挖掘过程中,通过对医院信息系统中病人数据进行抽取、清洗和预处理,生成有效的数据挖掘库。并使用IBM SPSS Modeler数据挖掘工具,建立基于决策树算法的住院天数拟合模型。根据此模型可对出院病人住院天数进行预测,制定住院天数标准,根据此标准对各科室进行考核评价。进而达到提高医院床位周转率的目的。
【关键词】住院天数;数据挖掘;SPSS;决策树
住院天数是评价医疗效益和效率、医疗质量和技术水平的一个综合指标。为了使医院的医疗资源得到充分利用,尽量降低患者住院的费用,缩短住院天数势在必行。长期以来,精神病人住院周期长、床位周转率低一直是困扰精神专科医院的难题。因此通过数据挖掘技术建立合理的住院天数拟合模型,通过模型对住院天数进行预测显的具有重要意义。
1 数据挖掘技术
1.1 数据挖掘概念
数据挖掘 (Data Mining,DM )又称数据库中知识发现,是指从大量的数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程。
1.2 IBM SPSS Modeler
IBM SPSS Modeler 是当前比较流行数据挖掘工作台,可以帮助用户在无需编程的情况下快速直观地构建预测模型。它还具有数据提取、转换、分析建模、评估、部署等的功能。可以大大提高用户数据挖掘的效率。
2 数据挖掘过程
2.1 数据预处理
高质量数据是进行有效数据挖掘的保证,只有获取了完整、系统、有效、可靠的基础数据,才能确保数据建模的顺利进行,最后得出合理、准确的结论。在本研究中,首先从医院HIS数据库中导出2010-2014年医院精神科病房出院病人数据,并保存为Excel格式。然后在此数据基础上对缺失值和异常值进行科学处理,并根据医院原始病历资料进行适当校正。
2.1.1 缺失值处理
在处理缺失值时,常用有两种方法: 删除该变量或对该变量进行填充。选用哪种方法处理应根据该变量的具体情况而定。一般原则是若变量缺失值超过样本总量的1/3,则删除该变量;若不超过样本总量的1/3,则对该变量进行填充。在本研究中,文化程序和职业两变量由于缺失超过样本总量的1/3以上,所以这两个变量被删除不在此次研究的范围之列。而年龄缺失不超过样本量的1/3,所以进行了填充。
2.1.2 异常值的检出与处理
异常值是影响模型精确度的重要因素。对原始数据的去伪存真,查找数据中的异常值和缺失值等是统计分析过程中的重要环节。例如住院天数少于等于1天和大于1年的住院记录,住院费用为0元或15万元以上的住院记录。为了消除个别诊断病例较少影响分析的正确性,我们只取医院排列前10名的疾病病历,具体诊断ICD10编码为F20,F30,F31,F32,F33,F25,F23,F10,F44,F43,在精神科病房前10名的疾病病历数占所有病历数80%以上。
通过以上多环节的处理最后得到有效病历9942例 ,导入SPSS Modeler中,作为后期分析之用。
2.2 数据选取
在日常诊疗过程中住院天数受多种因素的影响,比较复杂性,在收集数据时,会涉及各种维度的信息。这些属于不同维度的信息之间又相互关联的。这样使得数据挖掘工作的难度增大。如果将所有属性都作为数据挖掘模型的自变量进行建模,会增加不必要的计算量,降低效率,甚至会影响数据挖掘结果可解释性。
通过前面的数据预处理,我们从中得到病人的基本信息,包括住院号,姓名,性别,年龄,支付方式,入院日期,出院日期,住院天数,入院情况,入出诊断是否符合,出院方法,是否初次住院。共12个属性。我们应用特征选择的方法,对数据作进一步处理,从12个属性中提取更有代表性的关键属性,以消去冗余,提高计算与分析的效率。因此,我们使用了SPSS Modeler的特征选择方法对数据进行了进一步处理。运行后筛选出影响住院天数的前8个重要因素为: 出院诊断、年龄、出院方法、支付方式、性别、入院时情况、是否初次住院、入出院诊断是否符合。
2.3 住院天数聚类
住院天数为连续数值,为了能通过决策树模型进行分类测试,必须对住院天数进行分类。本研究中通过SPSS Modeler中K-means聚类的方法,对住院天数进行聚类。通过对比具体聚为三类比较合理,如表1所示。
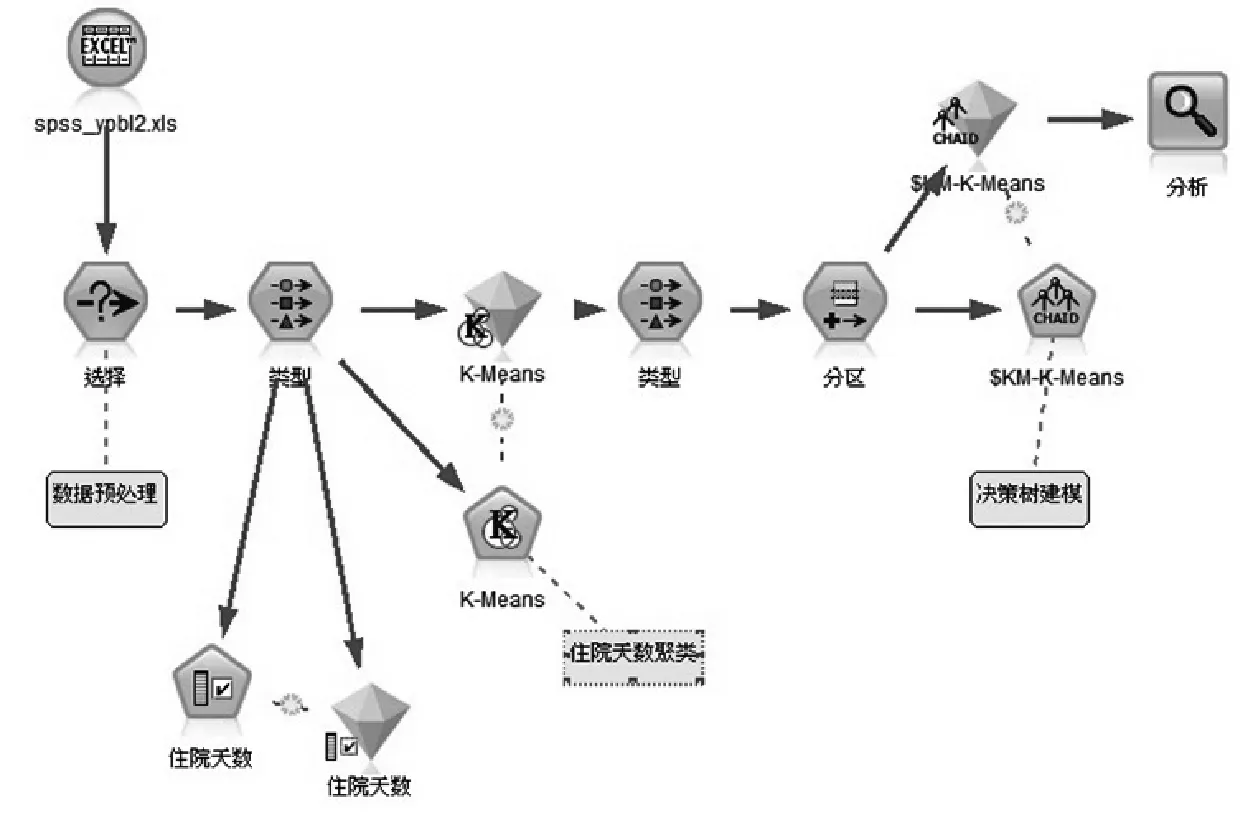
图1 数据流
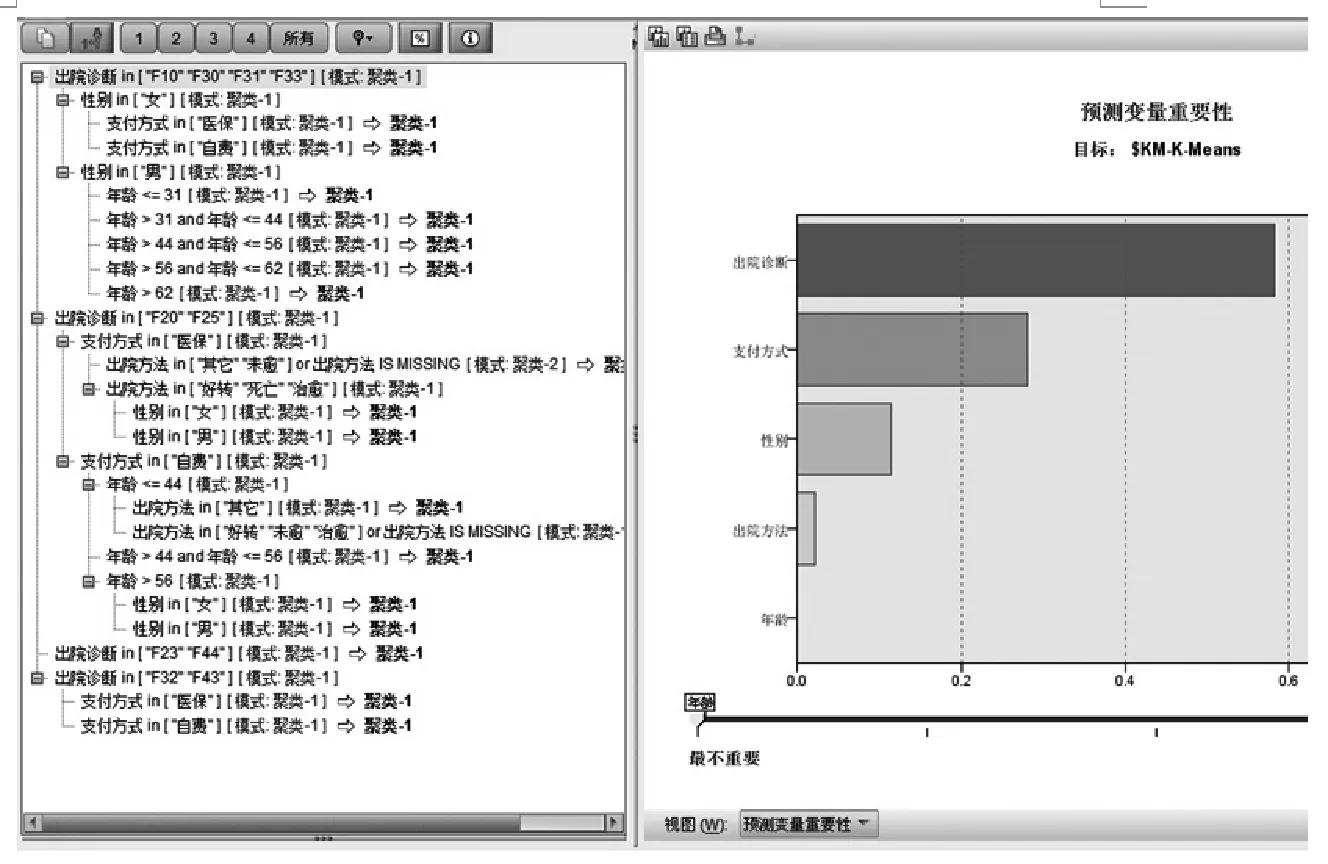
图2 决策树模型
2.4 训练集和测试集的划分
在数据挖掘过程中,评价模型是否精确、有效的一个常方式就是对输入的数据进行划分。本研究中我们把一部分数据划为训练集占80%,用于模型的拟合,另一部分20%的数据为测试集,用来验证所选模型。
2.5 模型建立
在数据挖掘中,人工神经网络模型和决策树模型尤其适合作分类预测。本研究中我们选择CHAID决策树模型对住院天数进行分类预测。并把树的深度设为4层。
各变量设置如表2所示。
IBM SPSS Modeler软件进行数据挖掘的过程就是通过一系列的节点运行数据的过程,这个过程称之为流。这一系列节点代表要对数据执行的操作,而节点间的链接表示数据流的方向。本研究中我们建立如图1的数据挖掘的流。
按照节点生成的模型如图2所示。
图2左边显示的是决策树模型右边显示的是各变量重要性。左边的是决策树模型。单击上图中的“查看器”,能显示树状图模型,如图3所示(只部分展开),得到四层18大类别决策树。
2.6 模型评价
在SPSS Modeler 中,常用输出模块的分析节点对生成的模型进行评价。在分区节点里,我们按照80%的训练集和20%的测试集对原数据进行过划分。所以在分析结果中可以看到训练集的样本数为7960例正确率为80.58%。测试集的样本数为1982例正确率为81.48%。综上训练集和测试集的正确率都在80%左右。考虑本研究的资料来源较为单一,同时例数太少,因此该决策树模型是可以接受的。
3 模型应用
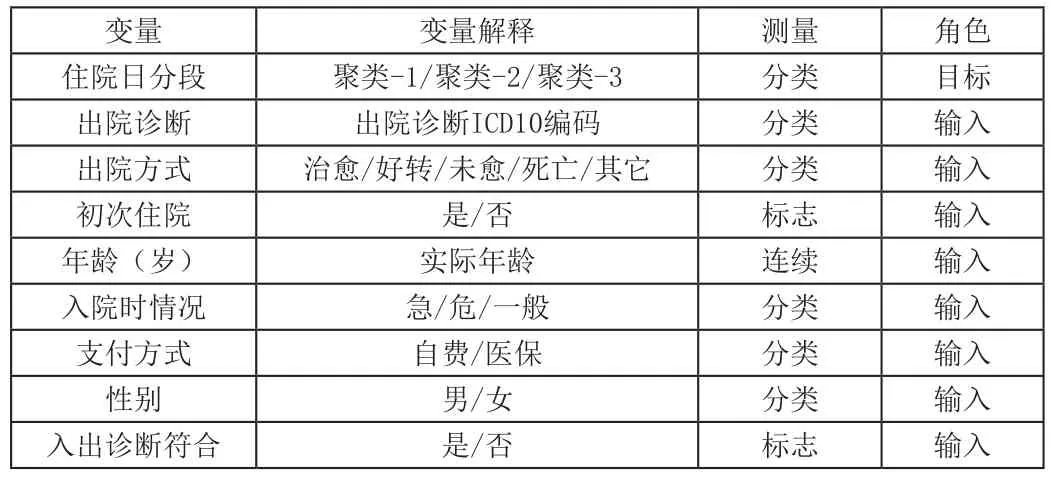
表2
本研究利用数据挖掘技术分析了某精神专科医院精神科病房2010-2014年9942例患者住院天数,对住院天数使用了决策树分类的建模研究。为了得到相对简单的模型本研究中设置决策树的深度为4。最后模型给出4层18个分类(叶子节点),具体的条件和住院天数控制范围如表3所示。其中住院天数均值是根据每个分类中各聚类的中位数X所点的百分数计算得出。
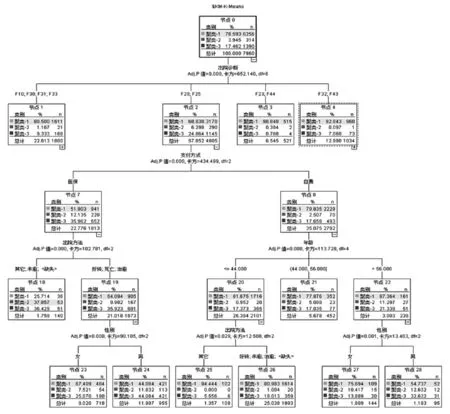
图3 树状图模型
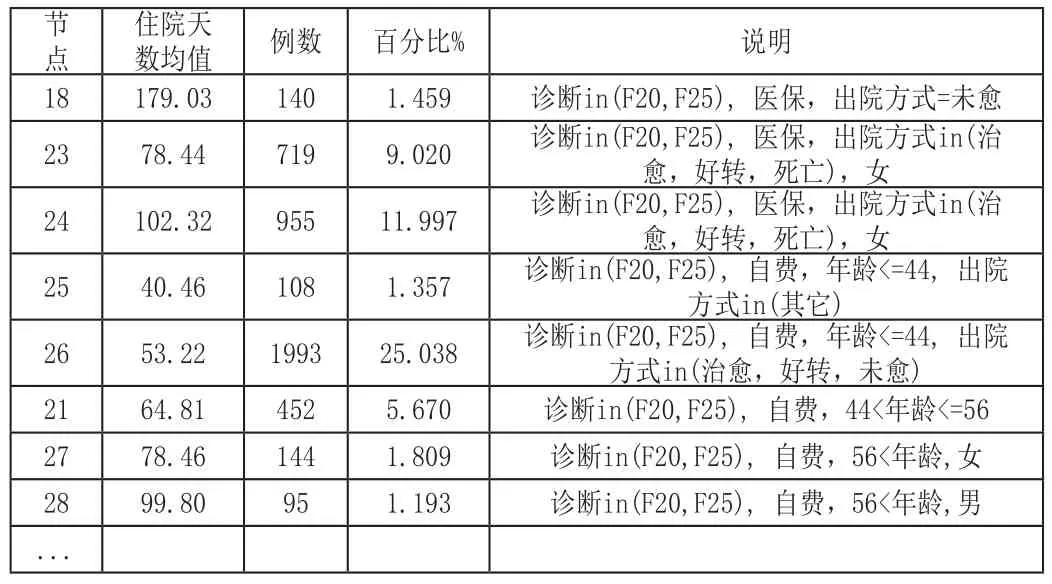
表3
根据表3,可以对出院病人住院天数进行预测,制定住院天数标准,根据此标准对各科室进行考核评价。
4 未来努力方向
本研究中得到的模型只有80%的正确率,如要应用到医院日常管理中还是相对较低。因此未来应从以下几方面着手完善模型。首先模型应该是动态的,在后续的研究中要不断补充样本,对模型进行优化。其次本研究使用的CHAID算法未必是最好,在今后的研究中,应采用多种模型进行分析比对,寻求最优组合。最后住院天数的影响因素较多,由于医院数据完整性的限制,有些变量无法提取到完整的数据只能放弃,在今后的研究中应该结合HIS系统改造,补充模型变量。
参考文献
[1]朱凌云,吴宝明,曹长修,等.医学数据挖掘的技术、方法及应用[J].生物医学工程学杂志,2003,20(3):559-562.DOI:10.3321/ j.issn:1001-5515.2003.03.047.
[2]杨海青.数据挖掘技术在医院管理中的应用[J].中华医院管理杂志,2005,21(7):497-499.DOI:10.3760/j.issn:1000 -6672.2005.07.026.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
电子设计工程(2014年18期)2014-02-27
