
一种多核处理器时钟精确并行仿真技术
2015-02-25 09:45苏雅丽呼和浩特民族学院内蒙古呼和浩特010051
赤峰学院学报·自然科学版 2015年6期
关键词:时钟
苏雅丽(呼和浩特民族学院,内蒙古 呼和浩特 010051)
一种多核处理器时钟精确并行仿真技术
苏雅丽
(呼和浩特民族学院,内蒙古呼和浩特010051)
摘要:PCASim作为时钟精确多核处理器有着广泛的应用,本文主要研究该处理器的并行仿真技术.在仿真技术方面,PCASim主要根据成熟的串行仿真技术制造获得,其中,在进行的仿真目标系统中有多项专业技术系统组成,主要包括:基于目录的高速缓存一致性协议;动态竞争的互连网络;多层次的存储子系统.同时,PCASim采用了并行化原型仿真器——POSIX线程库,能够进行划分对象模型为存储子系统、处理器核,并能够实现到宿主线程的映射,依靠S1ack机制实现线程同步.本文就是为了解决该问题,确保仿真器时钟精确性,通过研究当前所广泛应用的S1ack机制,提出了新同步方法.在新的方法中主要采用了提前设置悬挂路障,从而能够实现零延迟事件实时监控并被接受,提高保守同步协议能力.
关键词:多核处理器;PCASim;时钟;精确;并行仿真
1 引言
在单核处理器的发展过程中,功耗问题和处理性能问题一直困扰着计算机技术的发展,然而多核处理器出现就解决了该问题.同时,根据摩尔定律可知,在一年半的时间内必然让单片芯片上集成的晶体管数目成倍增加.晶体管技术的发展促使处理器能够具备更加丰富的功能,从而提升处理功能.2005年之前,Intel和AMD主要从晶体管增加的技术来促进处理器性能的提升.该方法在此之前却未使处理器技术获得革命性的发展,而是在发展中使处理器成为阻碍计算机技术发展难点.在处理器频率达到一定的数值时,晶体管性能边际收益阻碍了其功能的进一步提升,并且这一过程中还存在散热偏大和功耗过大的问题(Agarwal et al,2000).因此,研究多核处理器的仿真细致建模有着重要的意义.
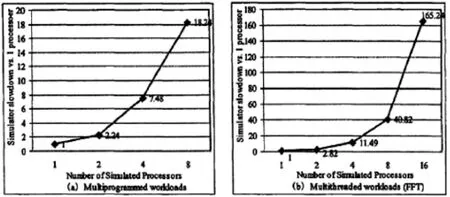
图1 串行仿真器性能的可扩展性
根据上图可知,当目标系统处理器数呈现增加趋势时,传统时钟精确串行仿真存在超线性时间开销的情况.上图中为SimpleScalar的串行多处理器仿真器规模下运行多道程序与多线程程序得到的性能降速比,其中,所用来做比较的是单处理器应用下的数据.通过这一对比可以看出,在多线程程序和多道程序中串行仿真的降速比都超出了线性斜率,额外性能开销在8节点模式下已经超出了1倍.同时,在两种模式下性能下降更为明显.因此,应该选择并行化技术来面对该问题带来的压力,多核处理器仿真技术的研究有着重要价值.
2 实验设置
本文研究中选择目标处理器核兼容X86指令级,处理器核采用了支持单线程的五级超标量乱序执行流水线;处理器核都各自进行连接数据高速缓存体和指令高速缓存体,二级高速缓存体接收到第一层总线共享数块,会进一步借助第二层总线将数据共享到主存控制器和三级高速缓存,从而能够形成胖树型拓扑的结构.其中,在一级、二级、三级高速缓存及主存访问延迟分别为2、10、50、200 Cycle,由目录式MOESI协议维持一致性.同时,测试实例均采用了配置32核心目标处理器,并且处理器其他设置完全一致.
根据多线程并行程序测试套件Splash2的应用程序,本文选择其中较为典型程序进行测试,具体有:OCEANCONTIGUOUS、WATER- NSQUARED、WATER- SPATIAL、CHOLESKY、RADIX、LU- CONTIGUOUS、LU- NONCONTIGUOUS以及FFT,同时,设置较大输入规模.实际上,以上程序在工作集和存储访问模式具备明显不同的差异,从而能够涉及不同处理器性能和模型特征.PCASim在进行测试可扩展性和功能性能时,分别使用1、5、9、17条宿主线程仿真32条目标程序线程.通过对比并行仿真的IPC与串行仿真的周期精准,PCASim仍存在部分偏差,导致这一现象的原因是宿主线程并行执行存在不确定性,本文研究中会给出相应的精确度对比结果.此外,进行比较了在增加悬挂故障对仿真器性能的影响.
3 实验结果与分析
根据图2数据可知,说明了PCASim并行仿真时相对串行仿真的加速比以及可扩展性.加速比实际上是由测试程序串行仿真与并行仿真时分别耗费的逻辑时间的比值.在应用5条、9条、17条宿主线程进行程序测试所获得加速比分别为48倍、63倍、8.66倍.同时,在应用5条、9条、17条宿主线程中所获得仿真器的并行效率呈现上升的趋势,其中,导
致该现象原因主要包括集中式管理线程的通信瓶颈以及每条核心线程计算负载的相对下降.通过分析可知,集中式管理线程的通信瓶颈显然存在,而每条核心线程计算负载的相对下降是因为采用32核处理器的目标系统,这就导致总核心线程数翻倍后计算负载降低.同时,在减弱计算负载过程中就会增加通信开销比重,也就出现了恶化集中式管理线程的通信瓶颈.此外,增加的线程数会导致通信资源呈现逐渐上升的趋势,同时也会分割管理线程功能,也就导致通信开销出现额外增加.
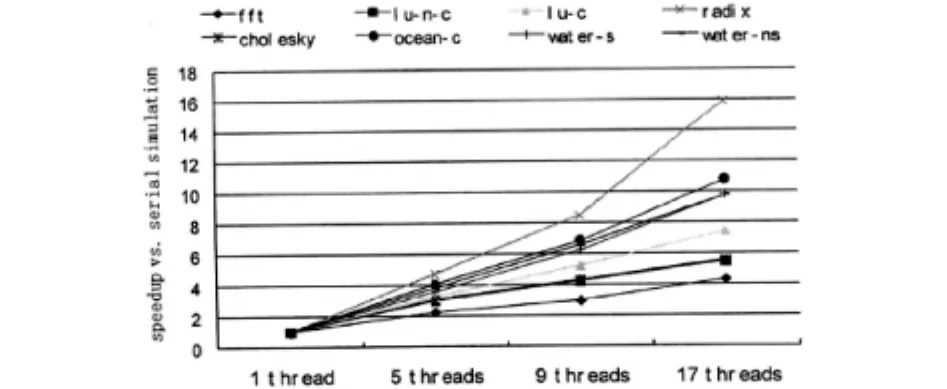
图2 在不同宿主线程下运行各测试程序时仿真器达到的加速比

表1 17条宿主线程下各测试程序的精度损失
根据上表的数据能够直接获得仿真器使用17条宿主线程时各测试程序的在逻辑时间与指令数两种指标上的精度损失.同时,逻辑时间精度损失计算公式如下所示:
Cycle精神损失=

Splash2的测试程序在串行仿真中能够保持确定性,也就是说目标系统在运行过程中都有一致性的状态输出结果,而PCASim却不具备Splash2的确定性,导致这种情况主要原因是功能模拟器成为时序仿真器的一部分而被并行化,从而促使功能仿真器在执行指令的过程中出现数据竞争,也就产生了运行指令数量在每次运行中都存在一定差异.在功能仿真过程中,数据竞争在很大程度上控制难度较大.从时序仿真器的运行机制可知,Slack同步机制和悬挂路障同步机制都不能对仿真器的共享变量访问顺序进行排序;在控制数据竞争产生的过程中,就可以利用串行化来处理功能仿真,然而,该方法却会在一定程度上降低线程数较大仿真器的并行度.
针对悬挂路障对并行仿真器性能的影响本文进行了研究,获得研究结果如图3所示.根据图中数据可知,相对Slack机制进行了归一数据处理,也就是降速比等于使用悬挂路障的仿真速度除以不使用悬挂路障、单纯Slack同步的仿真速度.其中,仿真器中的悬挂路障未使用,这就不能及时接收到零延迟事件,同时,若出现零延迟事件迟到,接收线程就认为此时为其发生时刻,也就是进行延长仿真总时间,仿真速度也成为指标进行对比和分析.当一级高速缓存访问缺失时就会进行创建悬挂路障,同时,相对管理线程运行速度,核心线程有着更快的速度,并且在超过时间窗口就会转变成单时钟周期同步.在应用程序访问过程中,一级高速缓存有着很大的命中率,一般情况下也不会主动创建悬挂路障;在发生访问缺失和核心线程超过时间窗口上限,相比于路障阻塞线程情况下,单时钟周期同步的性能损失较低,所以,在创建悬挂路障时不会过大的影响仿真器性能.在实施悬挂路障能够控制在性能范围,保持其性能在5%上下浮动,负值性能产生也是因为并行仿真不确定导致的,可以看出,悬挂路障不会产生过大的影响.
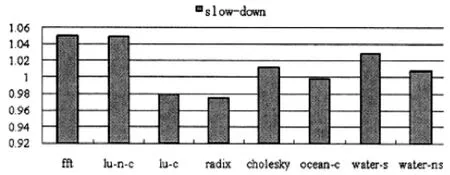
图3 悬挂路障机制对仿真器性能的影响
4 总结
通过实验研究,PCASim在17条宿主线程规模时相对串行仿真达到了平均8.66倍的加速比,该数值保持在较高水平,同时,采用集中映射后端子系统就能够展示可扩展性.
参考文献:
〔1〕陈芳园,张冬松,王志英.异构多核处理器体系结构设计研究[J].计算机工程与科学,2011(12).
〔2〕唐轶轩,吴俊敏,陈国良,朱小东,胡蝶.并行片上网络仿真器ParaNSim的设计及性能分析[J].西安交通大学学报,2012(02).
〔3〕王进祥,付方发,孙俊.NoC_MPSim:基于片上网络通信架构多核仿真平台[J].中国集成电路,2011(06).
〔4〕吴嘉慧.JPEG图像解码方案[J].现代计算机,2007(03).
〔5〕高明伦,杜高明.NoC:下一代集成电路主流设计技术[J].微电子学,2006(04).
〔6〕Luca Benini,Davide Bertozzi,A1essandro Bog1io1o,Francesco Meniche11i,Mauro O1ivieri. MPARM: Exp1oring the Mu1ti-Processor SoC Design Space with SystemC [J]. The Journa1 of VLSI Signa1 Processing -Systems for Signa1,Image,and Video Techno1ogy.2005 (2).
〔7〕Axe1 Jantsch,Johnny ?berg,Hannu Tenhunen. Specia1 issue on networks on chip [J]. Journa1 of Systems Architecture.2003(2).
中图分类号:TP332
文献标识码:A
文章编号:1673- 260X(2015)03- 0012- 02
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
数学大王·低年级(2018年9期)2018-10-24
数学小灵通·3-4年级(2017年6期)2017-06-22
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·B版(2016年7期)2016-07-02
三联生活周刊(2016年20期)2016-05-16
学苑创造·A版(2016年4期)2016-04-16
数学大王·低年级(2015年3期)2015-04-17
