
基于改进和声搜索算法的支持向量机参数优化
2015-01-13 03:13王秋平赵木来
化工自动化及仪表 2015年11期
王秋平 赵木来
(东北电力大学自动化工程学院,吉林 吉林 132012)
1995年,俄罗斯统计学家Vapnik提出了支持向量机(Support Vector Machine,SVM)理论。该理论建立在统计机器学习中VC维理论和结构风险最小化原理的基础上,解决小样本、非线性和高维度问题有独特的优势[1,2]。支持向量机已在文字识别[3]、语音识别[4]及生物特征识别[5]等多个工程领域取得了成功应用。
众所周知,在给定样本情况下,支持向量分类机的性能主要取决于惩罚参数C和核函数的选取。目前支持向量机参数优化的方法主要有网格搜索法、遗传算法及粒子群优化算法等。网格搜索法是运用数学手段对参数允许的取值范围分段后进行遍历搜索[6],该方法在理论上可以找到最优参数对,但现实运行较为费时;遗传算法通过模仿自然界选择与遗传的机理完成进化,寻找问题的最优解,具有很强的收敛性和鲁棒性[7],但其局部搜索能力差,容易出现早熟现象,算法本身参数较多,同时遗传算法的全局并行性欠佳,基因的继承性决定了算法每一次迭代不能进行整体的更新;粒子群算法也是进化算法的一种,从随机解出发,通过迭代找到最优解[8],其缺点是易陷入局部极值,且进化到后期的精度较差。
与上述参数优化算法对比,和声搜索算法具有以下优点:算法迭代过程采用十进制编码,无需转换操作;新和声的产生需考虑借鉴记忆库中现存所有和声,因此具备更好的全局搜索能力;每次迭代对解向量中所有变量进行操作,多点并行,极大地增加了求解速度。因此,笔者在借鉴和声思想的基础上,将和声搜索算法应用于支持向量分类机的参数优化问题,同时对核电站电动隔离阀门故障分类预测问题进行仿真实验。
假设m维空间上分布N个训练样本数据点,记这N个训练点组成的集合为:
T={(xi,yi),i=1,2,…,N}
(1)
其中,xi∈Rm;yi∈Y={-1,1},Y为训练样本的类别标签。
对于T集合中样本数据的二分类问题,支持向量机采用最大间隔法和对偶理论进行求解。训练样本数据非线性可分时,支持向量机引入核函数和松弛变量、惩罚参数,得到如下最优化对偶问题:
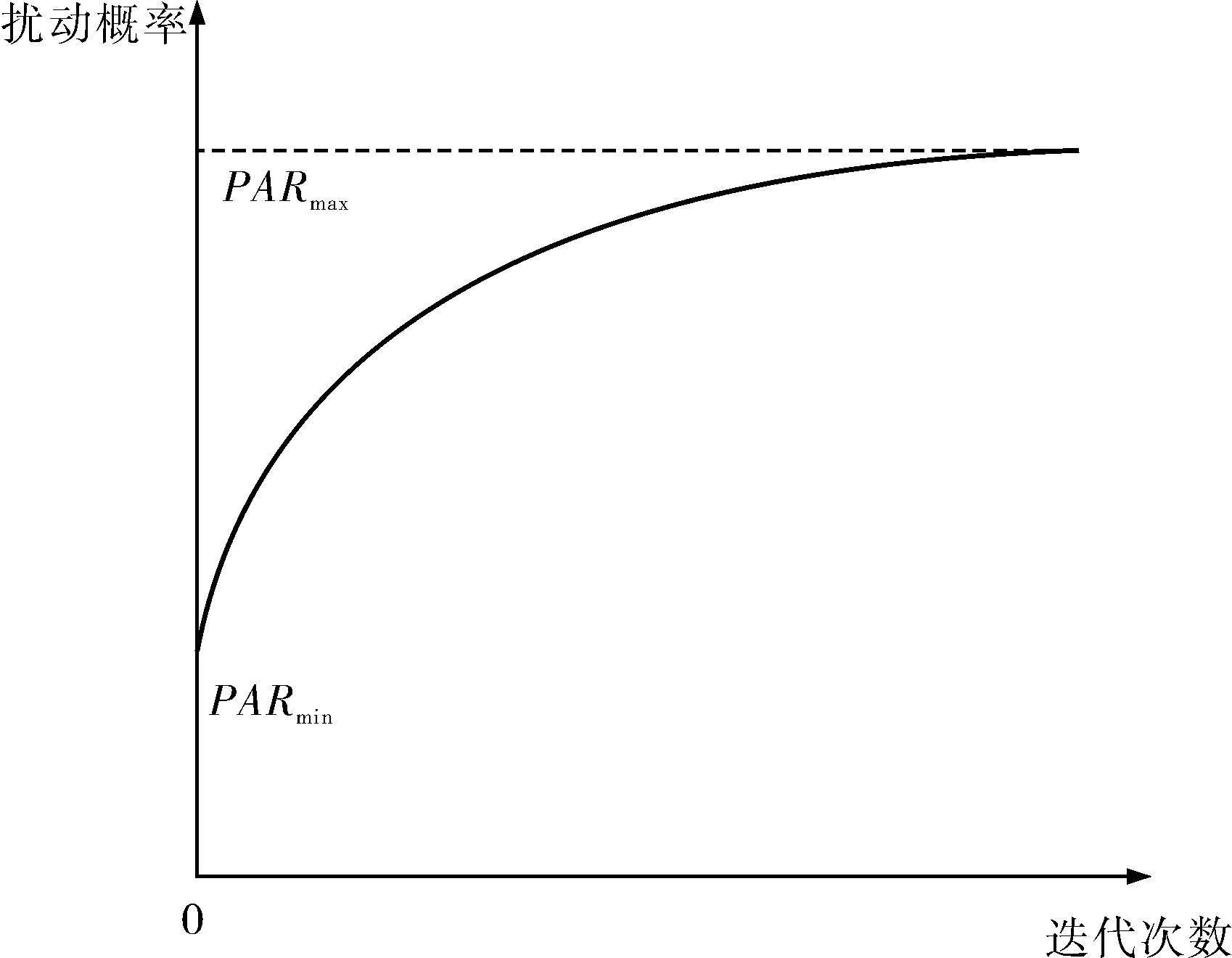
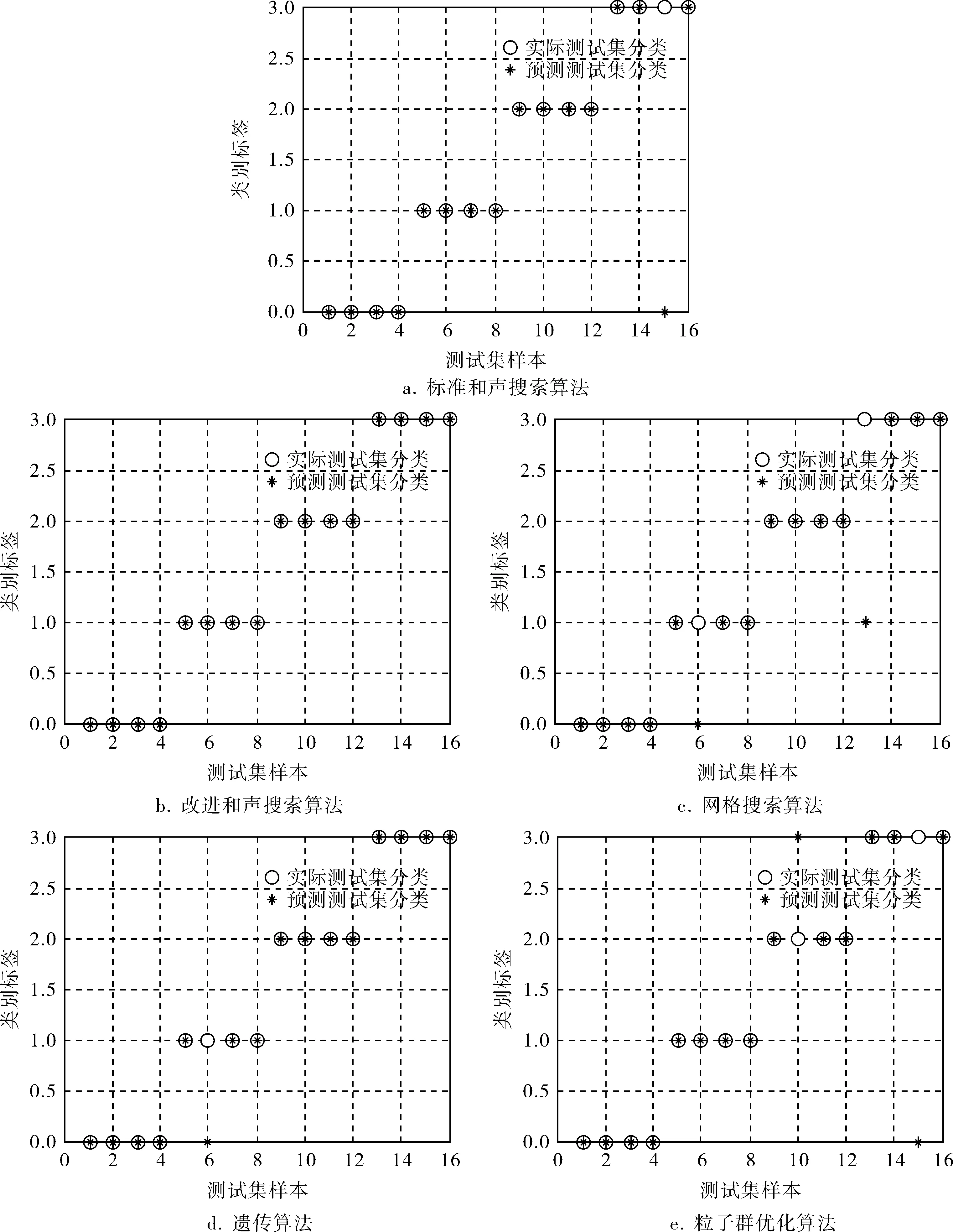
0<αi (2) 其中,αi为拉格朗日乘子;K(xi,xj)为核函数。 b0=1-ω0x(s),y(s)=1 (3) 其中,ω0为最优分类超平面的权值向量;b0为最优分类超平面的偏置;(x(s),y(s))为支持向量样本数据。最终得到测试样本的预测标签为: (4) 从以上支持向量分类机基本原理中可以看出,为得到最优的支持向量分类机的分类结果,算法中引入的惩罚参数的取值和核函数的选取是起决定性作用的。其中,调节惩罚参数C可以得到模型复杂度和学习能力的折中,C值越小代表对错分的惩罚越小,较小的C值可以增加模型的泛化能力,但易产生欠学习问题,而取较大的C值则容易产生过学习现象。RBF核函数是支持向量机中应用性能最好的核函数[9]。RBF核函数参数γ是低维空间训练样本映射到高维空间后形成超球的半径,当γ较小时,学习机对训练样本有很小的错分率,但不能保证对新样本的正确分类,当γ较大时,只能得到一个近似线性函数的学习模型,会严重降低分类精度。 目前的参数优化方法还没有统一的理论依据,且典型的优化方法也都在一定程度上存在各种缺陷,因此,笔者探索了利用和声搜索算法优化支持向量分类机参数的新方法。 和声搜索(Harmony Search,HS)算法是韩国学者Geem Z W等在2001年提出的一种新型现代启发式优化搜索算法。音乐家在谱曲创作中,通过自己的经验和记忆,尝试调整乐队中每一种乐器的音调,最终得到美学评价下的最好和声。和声搜索算法是模拟音乐家创作演奏音乐来设计与目标函数对应的解向量的迭代过程[10,11]。 和声搜索算法的步骤如下: a. 确定目标函数。初始化和声搜索算法各参数值(和声初始记忆库的容量HMS、和声记忆库内取值概率HMCR、扰动概率PAR、扰动带宽BW和运算最大迭代次数NI)。 b. 初始化和声记忆库。在和声记忆库中随机生成HMS个和声,并计算每一个和声在设定的目标函数意义下的适应值。 c. 根据规则生成一个新的和声。 d. 更新和声记忆库。计算新和声的适应度,如果其适应度大于和声记忆库中的最差解,则将新和声替换至和声记忆库中,否则不进行替换。 e. 重复步骤c和d,直到迭代次数gn达到最大值NI,循环结束并输出最优解。 步骤c中生成一个新的和声的规则为:生成0~1间的随机数R1。若随机数R1小于和声记忆库内取值概率HMCR,则随机选择和声记忆库内任意解向量的第一个变量值赋值给新和声向量的第一个元素;若随机数R1不小于和声记忆库内取值概率HMCR,则在和声记忆库外变量取值范围内随机取值。当R1小于HMCR时,即变量新值来自和声记忆库内,生成0~1间的随机数R2。若随机数R2小于扰动概率PAR,则再生成随机数R3、R4,扰动后的变量值为: (5) 其中,Xnew为R1小于HMCR时取自和声记忆库中的新值。若随机数R2不小于扰动概率PAR,则不进行扰动。 利用和声搜索算法进行支持向量机参数优化的核心思想为:将支持向量分类机中的惩罚参数C和核函数参数γ比作演奏和声的两种乐器,模仿调节每种乐器音调达到优美和声的过程,设计C和γ的迭代操作找到使学习模型达到最好分类精度的最佳解向量(bestC,bestγ)。 基本和声搜索算法优化SVM参数的基本步骤如下: a. 选取支持向量机测试集分类预测精确度作为目标函数。初始化参数值为HMS=20,HMCR=0.9,PAR=0.2,BW=0.7,NI=200。 b. 随机生成HMS=20个和声,计算每一个和声的平均分类精确度。 c. 按照上文标准和声搜索算法步骤c中的方法产生一个新和声。 d. 更新和声记忆库。 e. 重复进行步骤c和d,迭代至最大次数NI,循环结束并输出全局最优解(bestC,bestγ)。 在标准的和声搜索算法中,和声记忆库内取值概率HMCR、扰动概率PAR和扰动带宽BW是控制算法优化性能的3个重要参数。HMCR是和声记忆库内取值概率,较大的HMCR值可以提升算法的局部搜索能力,较小的HMCR值则有利于保持和声记忆库内解向量的多样性,有效预防早熟现象。类似于遗传算法的变异操作,和声搜索算法也包括对解向量的扰动微调过程,PAR和BW是该过程的控制参数,它们的值可以直接影响最优解向量的收敛速度。PAR取较小值可以增强算法的局部搜索能力,取较大值则有利于和声搜索算法围绕和声记忆库调整搜索区域,使其搜索范围逐渐扩大到整个变量空间。BW为解向量中各变量的微调幅度,BW的取值可以控制局部区域搜索的精细度,设置较大值可以使算法跳出局部极值。 由上可见,和声搜索算法的参数参与整个搜索过程,是算法优化性能优劣的关键因素。标准的和声搜索算法各参数均由实验者凭借经验知识设置固定值,在算法进行过程中不具备调整能力,从而降低了迭代搜索能力,最终影响算法的整体优化性能。针对该缺陷,笔者提出一种具有自适应动态调整功能的PAR和BW参数改进方法。 在和声搜索算法迭代初期,采用较小的PAR值和较大的BW值可以保证区域精细搜索,快速找到局部最优解,同时保持解向量空间的多样性,预防陷入局部极值;而在迭代进化的中后期,较大的PAR值和较小的BW值则能增强算法全局搜索能力,使搜索的重点集中在解空间性能较高的区域,同时较小的扰动带宽不会破坏近优解,从而大幅提高算法的运算效率[12,13]。 扰动概率PAR伴随迭代进化策略: (6) 式中gn——迭代次数; PARmax——最大扰动概率; PARmin——最小扰动概率。 图1为扰动概率PAR随迭代次数的变化曲线,可以看出,随着迭代次数的增加,PAR由最初的最小值沿反正切曲线逐渐增大。当迭代次数gn趋于NI时,PAR为最大值,且PAR变化逐渐趋于平缓,预防进入迭代后期对较优解向量的扰动破坏。 扰动带宽BW伴随迭代进化策略: BW(gn)=BWmin+(BWmax-BWmin)×exp(-gn) (7) 式中BWmax——最大扰动带宽; BWmin——最小扰动带宽。 图2为扰动带宽BW随迭代次数的变化曲线,可以看出,随着迭代次数的增加,BW由最大值按照指数曲线逐渐减小。当gn趋近于NI时,BW近似等于最小值,且逐渐趋于平缓,可保证在迭代后期对解空间中性能较好区域的精细搜索。 图1 扰动概率PAR随迭代次数的变化曲线 图2 扰动带宽BW随迭代次数的变化曲线 与标准和声搜索算法优化SVM参数过程类似,将SVM学习模型的分类准确率作为优化过程的目标函数。同时设置自适应参数PAR和BW的最值,将改进的扰动控制参数引入优化过程。类似于标准和声搜索算法优化SVM参数步骤,具体修改为:步骤a中定义PARmin=0.05,PARmax=0.3,BWmin=0.1,BWmax=0.8,步骤c中将式(6)、(7)代入标准和声搜索算法步骤c中,替换固定的扰动概率PAR和扰动带宽BW。 电动隔离阀门是核电站运行的关键设备,应用量很大且检修维护费用昂贵。及时准确地发现阀门故障是核电站安全运行的必要条件。针对阀门关闭不严、填料摩擦力过大和电动传动问题三大主要故障,笔者应用安全级电动隔离阀故障诊断系统[14],提取现场电动隔离阀门运行的峰值、峭度、裕度、脉冲、波形、谐波因子、相关因子、功率谱方差、功率谱重心和功率谱均方十项数据指标。其中,阀门正常运行工况数据20组,三大主要故障工况数据各20组,在每种运行工况中随机选取4组数据组成测试集,其余作为训练集数据。分别运用标准和声搜索算法、改进和声搜索算法、网格搜索算法、遗传算法和粒子群优化算法优化支持向量分类机参数,利用各自优化方法找到的最佳参数对(bestC,bestγ)建立预测模型,对阀门运行数据进行训练和预测,仿真实验的运行结果如图3所示,算法对比见表1。 图3 采用不同优化方法建立的SVM模型对核电站电动隔离阀门数据分类预测结果 优化算法测试集预测准确率%最佳平均分类精确度%程序运行时间s标准和声搜索算法93.7591.2418.4改进和声搜索算法100.0098.5018.8 (续表1) 由表1可以看出,在对16组阀门测试集数据的预测中,基于改进和声搜索算法的支持向量机分类准确率达到100%,交叉验证意义下的最佳平均分类精确度达到98.50%,其程序运行时间与其他算法相比也有所减少。因此,基于改进和声搜索算法的支持向量分类机相比于其他优化方法具有更好的分类性能。 支持向量分类机的参数选择是影响学习模型预测精确度和泛化能力的关键因素。笔者将和声搜索算法应用于支持向量分类机参数优化,同时针对基本和声搜索算法参数相对固化的缺陷,设计了一种伴随迭代次数增加而自适应动态调整参数功能的改进方法。并将基于改进和声搜索算法的支持向量分类机应用于核电站电动隔离阀门故障分类预测。仿真实验结果显示:对比其他优化方法下的支持向量机,基于改进和声搜索算法的支持向量分类机具有更好的学习能力和预测精度。 [1] 丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):2~10. [2] 袁胜发,褚福磊.支持向量机及其在机械故障诊断中的应用[J].振动与冲击,2007,26(11):29~35. [3] 马金娜,田大钢.基于支持向量机的中文文本自动分类研究[J].系统工程与电子技术,2007,29(3):475~478. [4] 栗志意,张卫强,何亮,等.基于核函数的IVEC-SVM说话人识别系统研究[J].自动化学报,2014,40(4):780~784. [5] 李晓东,费树岷,张涛.基于奇异值特征和支持向量机的人脸识别[J].东南大学学报(自然科学版),2008,38(6):981~985. [6] 李清毅,周昊,林阿平,等.基于网格搜索和支持向量机的灰熔点预测[J].浙江大学学报(工学版),2011,45(12):2181~2187. [7] 郭彤城,慕春棣.并行遗传算法的新进展[J].系统工程理论与实践,2002,(2):15~23. [8] 陈民铀,张聪誉,罗辞勇.自适应进化多目标粒子群优化算法[J].控制与决策,2009,24(12):1851~1855. [9] 陈然,孙冬野,秦大同,等.发动机支持向量机建模及精度影响因素[J].中南大学学报(自然科学版),2010,41(4): 1391~1397. [10] Geen Z W, Kim J H, Loganathan G V.A New Heuristic Optimization Algorithm: Harmony Search[J]. Simulation,2001, 76(2): 60~68. [11] 依玉峰,高立群,郭丽.和声搜索算法在聚类分析中的应用[J].东北大学学报(自然科学版),2012,33(1):47~51. [12] Mahdavi M,Fesanghary M,Damangir E.An Improved Harmony Search Algorithm for Solving Optimization Problems[J].Applied Mathematics and Computation,2007,188(2):1567~1579. [13] 金永强,苏怀智,李子阳.基于和声搜索的边坡稳定性投影寻踪聚类分析[J].水利学报,2007,(z1):682~686. [14] 杨国峰,胡守印,李智慧.安全级电动隔离阀故障诊断系统的研究与设计[J].核动力工程,2009,30(3):102~106.2 标准和声搜索算法
3 改进的和声搜索算法


4 核电站电动隔离阀门故障分类预测仿真实验


5 结束语
猜你喜欢
数学物理学报(2022年4期)2022-08-22
流程工业(2022年3期)2022-06-23
北京航空航天大学学报(2021年7期)2021-08-13
煤气与热力(2021年3期)2021-06-09
军民两用技术与产品(2021年2期)2021-04-13
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
数学物理学报(2019年4期)2019-10-10
贵州师范学院学报(2016年3期)2016-12-01
河北科技大学学报(2015年5期)2015-03-11
中学科技(2014年11期)2014-12-25
