
使用 R对 1995—2011 年我国水资源状况的分析
2015-01-02 05:58王志坚毛声录
水利信息化 2015年1期
叶 枫,王 露,王志坚,张 鹏,毛声录
(1.河海大学 计算机与信息学院,江苏 南京 211100;2.江苏省水利工程规划办公室,江苏 南京 210029;3.南京市六合区水利局,江苏 南京 211500)
简讯
使用 R对 1995—2011 年我国水资源状况的分析
叶 枫1,王 露1,王志坚1,张 鹏2,毛声录3
(1.河海大学 计算机与信息学院,江苏 南京 211100;
2.江苏省水利工程规划办公室,江苏 南京 210029;
3.南京市六合区水利局,江苏 南京 211500)
缓解水资源危机,合理开发利用水资源,关键是从时空维度量化水资源,分析和挖掘出有价值的知识和规律。R 是一种免费的软件,具有丰富的统计计算和图形展现等功能,已成为大数据分析、挖掘和展现的利器。在概述水资源数据特点的基础上,以 1995—2011 年全国各省份水资源统计数据集为例,介绍如何使用 R 对水资源数据进行分析,包括假设检验、趋势分析等。结果既能通过图形化方式清晰直观地看到不同地区、省份的空间维度下,水资源按时间的变化情况, 也可以快速选择出最佳趋势拟合方式等,符合领域业务要求。
大数据;R 语言;水资源;数据分析
0 引言
水资源[1]是人类赖以生存、发展的基础。随着经济发展与人口增长,全球水资源的需求量也与日俱增。与发展相伴随的是严重的水资源浪费与污染。作为最大的发展中国家,我国水资源现状也不容乐观,主要在于:1)水资源时空分布不均,直接影响全局规划与区域发展;2)粗放型的管理和使用机制,使得宝贵的水资源得不到充分利用;3)水污染状况日益严峻。要缓解水资源危机,合理地开发利用水资源,积极推进国家水资源监控能力建设[2],关键是从时空维度量化水资源,分析和挖掘出有价值的知识和规律,并加以科学应用。但是,对于水资源数据的量化、分析和挖掘工作是非常困难的,这是由于:1)随着各类水文、水质传感器得到更加广泛的应用,所获取的水资源数据规模和增长速度都是空前的。2)水资源大数据类型众多(实时水雨情、水文、水质、气象、水利普查等)、数据血统复杂(来源于不同的事权单位)[3],并且数据之间存在着丰富的时空关联信息。
科学研究的“第四范式”[4],也即数据密集型的知识发现,为研究水利领域的数据提供了崭新思路。以物联网、云计算、大数据处理[5]为代表的新技术,可用于数据获取、管理、分析和挖掘等方面,是实现“第四范式”的核心技术。其中,大数据处理是当前研究与应用的热点,其核心是通过对海量数据的整合、分析与挖掘,得出其中有价值的信息与知识。R[6-7]是一种免费的统计软件,具有丰富的统计计算和数据展现等功能,已成为大数据分析、挖掘和展现的利器。基于 R 的大数据深度分析研究[8-9]已有了一些进展。因此,使用 R 对水利信息化领域的特定大数据进行分析、挖掘等是可行的。
本文的主要工作是具体介绍如何结合水资源数据的特点,使用 R 对水资源数据进行分析,例如趋势分析、假设检验等,并通过使用 1995—2011 年全国各省水资源统计数据集做例示,这是最终构建基于 R 的水利领域大数据处理平台的基础。
1 相关工作
R 是当前发展最为迅速一种开源免费的统计软件。它提供了有弹性的和互动的环境来分析、可视及展现数据;也提供了 3 700 多个统计程序包,以及一些集成的统计工具和各种数学、统计计算的函数,几乎覆盖了整个统计领域的前沿算法。用户只需根据统计模型,指定相应的数据库及相关的参数,便可灵活机动地进行数据分析等工作,甚至创造出符合需要的新的统计计算方法,这样就简化数据分析过程,从数据的存取,到计算结果的展现,能够更好地分析和解决问题。R 可以对多种文件格式进行读取处理,包括:Excel,XML,CSV,ARFF 及 PMML 等。当前,在国外诸多领域中,R已经得到深度应用,与水利相关专业数据处理的 R包也已有一些,例如:hydroTSM 包是高度面向水文建模任务;EnvStats 包可用于环境数据的统计。在文献 [7] 中,介绍了使用 R 对水样中的蓝藻数据进行预处理、探索性数据分析和构建预测模型等。但是,在国内水利信息化领域,依然需要更多的研究和实例来挖潜 R 的分析、展现等能力。
针对大数据的研究是当前信息技术的热点,R也已成为大数据分析、挖掘和展现的利器。对于大数据深度挖掘分析的应用,已有很多研究工作,如文献 [8-10],介绍了诸多开源的、商用的深度分析工具。其中,在文献 [9] 中,概述了当前基于 R 的大数据分析和挖掘的现状,并提出基于云计算集成 R 的大数据分析挖掘服务平台。该平台是前期的工作,已具有了分类与预测、聚类、回归分析和时间序列分析等数据分析挖掘服务。但是,上述工作并没有考虑结合水利领域的特定业务和具体数据进行数据挖掘。
综上所述,大数据的发展如火如荼,但是结合具体领域数据特点进行分析和挖掘,更具有应用价值。对于水利领域而言,由于水资源相关的大数据类型众多、血统复杂并且数据之间存在着丰富的时空关联信息,需要考虑结合水资源数据的特点,利用已有的大数据深度分析和挖掘的基础开展更多的研究工作。
2 水资源数据的分析与展现
水资源数据往往具有下述主要特征[11]:
1)只可能是非负的值。
2)存在异常的数值。
3)数据往往是非正态分布的。
4)当数据值低于或高于某一阈值时,应加以关注。例如:低于某一种或多个检测限的浓度、每年的水位高度中超过众所周知的记录水平的时候,应该进行水质或水位的报警。
5)具有季节性模式。
6)自相关性(Autocorrelation)。连续观测的值往往是彼此密切相关的。
7)依赖于其它变量。例如,数据值往往与排水量、导水率或其它的一些变量有着强烈的共变。
根据上述特点,通常用于衡量水资源数据的测度有均值、中位数及极值等。例如,均值能直接反映数据的整体平均趋势;异常值出现时,通常需要关注或者报警。对水资源数据分析的统计方法有:假设检验、简单关联分析、多元线性回归、趋势分析等。例如,考察年径流量是否服从某种分布,相邻两测站不同时段降雨量系列的均值是否有明显差异等都要对水文数据的分布性质和参数情况做出某种假设;经常把水资源数据与人口、季节性数据进行关联性分析;由于时空分布不均,变化分布不均对地表水进行趋势分析。
使用图形表现数据中隐含的模式和理论直观方便。对于单一数据集,常用的图形化方式有:柱状图、茎叶图(Stem-and-Leaf Display)、盒图(Boxplots)、四分位图(Quantile Plots)和概率图(Probability Plots)等;用于 2 个或多个数据集的比较时,常用的图形化表示有:柱状图、Q-Q 图(Q-Q Plots)、中位数或标准偏差的点图或线图、盒图(Boxplots)、概率图;对于多元数据,可以使用剖面图(Profile Plot)、星状图(Star Plots)、三线图(Trilinear Diagrams)、主成分分析图(Plots of Principal Components)等。
可将水资源数据的特点总结为如图1 所示的内容。
3 基于 R 的水资源数据分析
3.1 基本的统计和展现

图1 水资源数据的特征
使用 R 对数据进行基本的统计和展现,是非常简单和易用的,对于常用的水资源数据也没有例外。在 R 中,对于均值、中位数、方差等有直接的函数,分别是 mean( ),median( ),var( );对于图形化展现,饼图、直方图、盒图等也可以直接调用相关函数。除了上文提及的 hydroTSM 包和 EnvStats包,还有一些特定的库(library)可专门用于水利领域的数据处理。例如:waterData 包用于检索、分析和日水文序列的异常计算;weatherData 包中的函数可以获取相关站点提供的天气数据(气温、气压等)以便用于天气相关的分析。更多的 R 包和具体用法可以直接参考文献 [12]。
3.2 假设检验
Mann-Kendall 检验是水文数据分析中最为广泛使用的非参数性检验方法,它不需要样本遵从一定的分布,也不受少数异常值的干扰。通过加载 R 中的 Kendall 包,调用其中的 Kendall( ) 方法就可实现,其 R 描述的伪代码实现为
1)输入。水文数据 S,自变量列名 X,因变量列名 Y。
2)输出。参数检验结果 R。
a.library (Kendall);/*加载 Kendall 分析包*/
b.x<—S$X;/*取出列名为 X 的数据*/
c.y<—S$Y;/*取出列名为 Y 的数据*/
d.result<—Kendall (x,y);/*调用方法 Kendall( )处理数据并返回结果*/
e.return result./* 返回结果*/
3.3 趋势拟合
趋势拟合是用平滑的曲线反映出数据变化的总体趋势,从而使数据易于分析与预测。最常见的数据拟合方式有样条差值与 Lowess 局部加权拟合法。样条差值法是常用的、得到平滑曲线的一种差值方法,三次样条又是其中较为广泛的一种;Lowess局部加权拟合法是对二维散点图进行平滑的常用方法,它结合了传统线性回归的简洁性和非线性回归的灵活性。当要估计某个响应变量时,先从其预测变量附近取 1 个数据子集,然后对该子集进行线性或二次回归,回归时采用加权最小二乘法,即越靠近估计点的值其权重越大,最后利用得到的局部回归模型估计响应变量的值,用这种方法进行逐点运算得到整条拟合曲线。以 Lowess 拟合为例,其 R 描述的伪代码描述为
1)输入。水文数据 S,自变量列名 X,因变量列名 Y,平滑程度参数 f_v,预测回归参数 deg。
2)输出。拟合曲线图和回归预测图。
a.x<—S$X;/*取出列名为 X 的数据*/
b.y<—S$Y;/*取出列名为 Y 的数据*/
c.l<—lowess (x,y,f=f_v);/*生成拟合数据*/
d.lowess<—drawLowess (l);/*利用拟合数据画出拟合曲线*/
e.p<—predict (loess(y~x,degree=deg));/*计算水文数据 S 的个数*/
f.pred<—drawPredict (p);/*利用预测数据画出预测曲线*/
g.return [lowess,pred]./*返回拟合和预测曲线*/
4 实例展示
所选用的数据集来自中国计算机学会数字图书馆中的 1995—2011 年的全国各省水资源统计数据,该数据集具体包括:1997—2011 年全国各地区水资源总量数据,2003—2011 年各地区地表水、地下水及重复量的数据。该数据集基于 Excel 文件,数据可靠性高,但是有缺值。结合使用的数据集是 1997—2011 年全国各地区人口数据[13]。
由于数据集规模不大,试验环境可基于单机环境,使用的 R 版本为 R386 3.1.0。若数据规模超过单机能力,可以参考文献 [9] 或者利用 R 具有的并行计算能力。
4.1 数据的整理
对原始数据集进行分类整理,主要包括对于缺失值的处理,如处理某些省份地表水缺失的情况;按时间—地区的处理,如分析某省的水资源变化情况;按区域进行分析、比较,如分析不同地区的水资源状况等。其中,对于缺失值,计算时可以按有值年份计算,比如很多省份缺少 1995 和 1996 年数据,计算时可以从 1997 年开始计算,不能用均值补入的原因是时间序列过短,并且很多区域水资源变化极大,易造成较大误差。
4.2 图形化分析
可分析全国水资源总量的总体状况。1997—2011 年全国水资源总量如图2 所示,15 年来我国水资源总量大体维持在 24 000~30 000 亿m3左右,在 34 000 亿m3区间内存在一个极大值,主要原因是1998 年全国发生了大范围洪水。
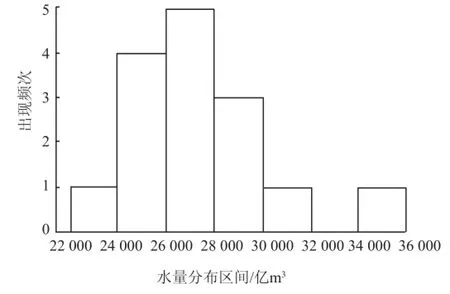
图2 全国水资源总量直方图
2011 年全国水资源总量如图3 所示。其中,西南地区水资源尤其丰富,而华北地区呈现为水资源量短缺。但是,西南地区的水资源供需矛盾依然严峻,不少城市供水不足,中小型河流污染严重,并且地形变化复杂,高原、山原、低谷和盆地相互交错分布,从而导致水资源利用困难[14]。
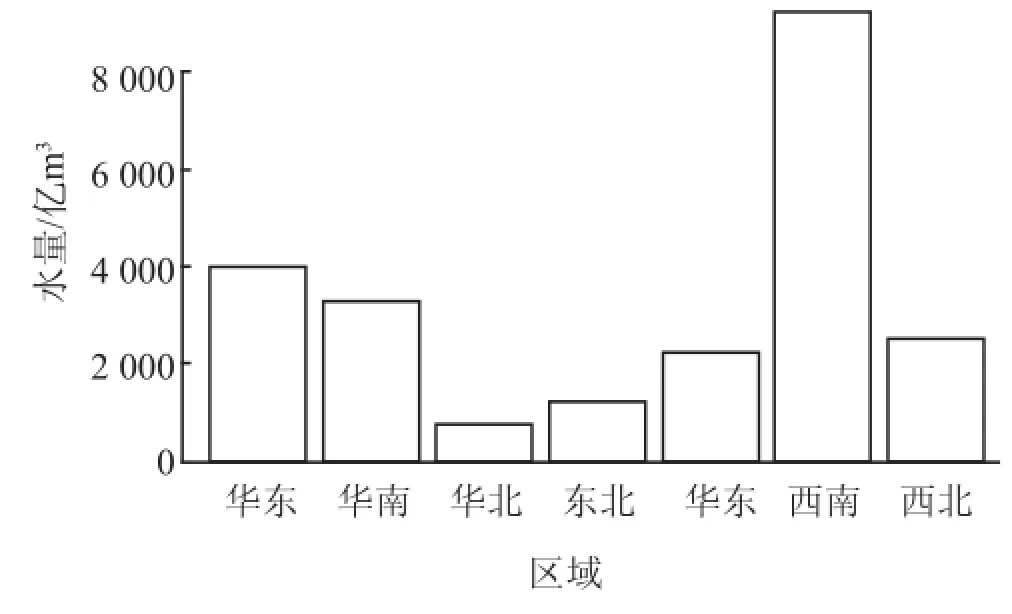
图3 2011 年全国水资源总量直方图
1997 年全国水资源总量分布如图4 所示,全国各地区 15 年水资源总量均值如图5 所示。西南地区水资源量占全国水资源总量的 35.65%,华北地区仅为 2.5%。华东和华中地区水资源总量均值范围波动较为平稳。然而,华北地区出现均值范围远超总体均值水平的现象。西南地区水资源状况波动较大。结合文献 [14],可分析出主因是西南地区海拔相差悬殊,区域气候差异相差极大,降水量不稳定所导致,有必要开展时空调节。
进一步可以分析水资源数据集的概率分布及区间段的累计频率。为了分析数据的累积频率和区间段数据及极值点出现的概率,可以选取 Cunnane公式计算累积频率作为计算的标准 pi = (i -a)/ (n + 1 - 2 a),其中 a = 0.4,n 为数据集规模。它是相对于 Weibull 公式(a = 0),Blom 公式(a = 0.375),Gringorten 公式(a = 0.44)及 Hazen 公式(a = 0.5)的一种对比较数据分位数较合适的分布概率图,它被北美及一些欧洲的水文学家用于做水量数据和洪水频度曲线,对于处理小数据集的水文数据极其方便。例如,参数 a 值(0~0.5)的不同选择如图6 所示,数据集的分位数图呈现不同的分布。在 28 000~30 000 亿m3区间曲线陡峭,说明出现频率越高数据分布越密集,30 000 亿m3以上区间曲线趋于平缓说明出现频率较低。

图4 1997 年全国水资源总量分布饼图

图5 各地区 15 年水资源总量均值盒图
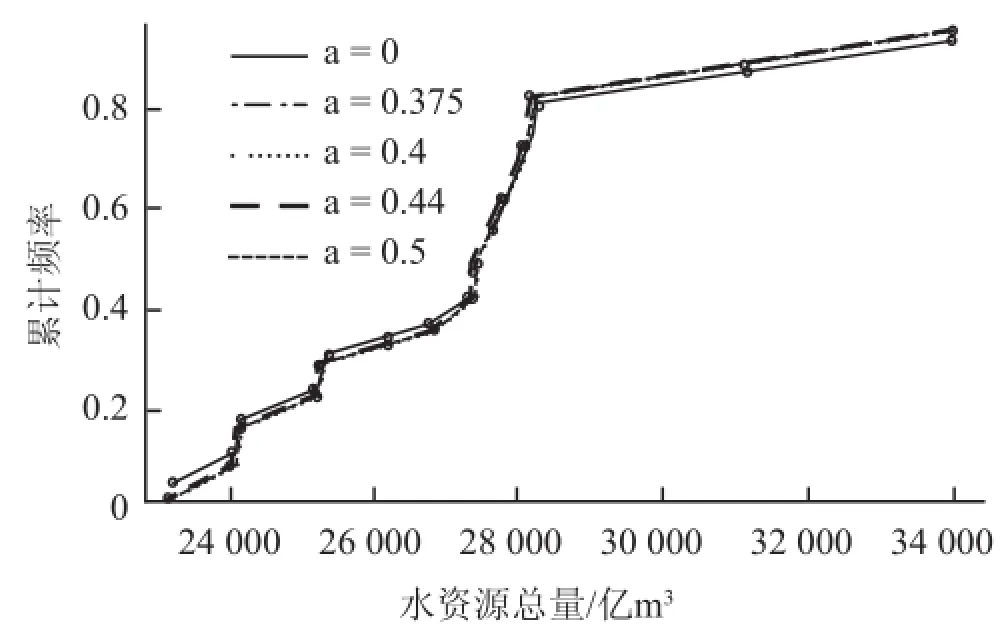
图6 15 年全国水资源总量分位数图
为了分析各地区水资源总量趋势图,以华南地区为例,1997—2011 年华南地区水资源总量如图7所示。该地区水资源量波动较大,有个别极值点,1997 年水资源量为 5 547.90 亿m3,2004 年则出现15 年来的最小极值点,水资源量只有 2 963.30 亿m3,与均值 4 075.60 亿m3比较看,低于均值近 1 000 亿m3的水量,相差非常大。结合文献 [15],原因可能是由于 2004 年月平均气温比常年偏高,时空分布不均及人为的严重浪费与破坏水资源导致 2004 年华南地区出现严重的旱情。
水资源及人口总量数据如图8 所示,可分析出相对应的全国人均水资源量的变化趋势。2004 及2011 年全国人均水资源量达到了极小值点,我国人均水资源量均值在 2 030 m3左右,仅为世界水平的1/4[15-16],而 2004 年人均水资源量,远远低于均值水平。2010 年出现了 15 年来人均水资源量的极大值点为 2 304.883 m3,主要是因为 2011 年降水量比往年偏多。我国水资源总量总体呈现下降趋势,而我国人口数量总体呈现上升趋势,2 者成反比导致我国人均水资源量总体呈现下降趋势,值得密切关注。

图7 1997—2011 年华南地区水资源总量折线图
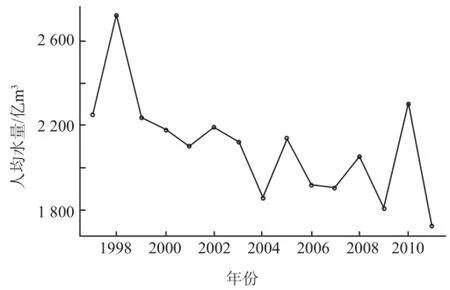
图8 1997—2011 年全国人均水资源量趋势图
通过分析地表水、地下水及重复量的数据,各地区水资源污染现状并集合各地区地势、环境、气候等因素能分析出污染的可能原因。以最近几年广受关注的华北地区为例,对华北地区各城市与各省份的水资源总量、地表水量、地下水量及重复量进行分析,生成华北地区各省(市)趋势对比图,如图9 所示。
内蒙古自治区地表水呈现较平稳的态势,地下水与重复量虽没有较大波动,但均有下降的趋势,这很大程度上是受人为因素的影响[17]。北京的状况主要受地下水变化的影响,年份差异非常大。作为人口密集的国际化都市,其人均水资源占有量约为285 m3/人,只是全国人均水资源占有量的 1/7[18]。天津为典型的北方地区,存在典型的时空的差异问题,导致其成为全国人均水资源占有量最少的省市之一,仅为全国人均占有量的 1/13,在天津地区由于地表水资源极度崩溃,超量开采地下水,导致地下水位下降,引发大面积的地下沉降和海水入侵等环境问题[19]。山西省地处山地、高原地区,总的地势北高南低,因为山地和季风气候的原因,主要会由于暴雨形成山洪暴发,洪水出现的平均间隔也具有一定的规律性,局部地区的洪灾平均 3~4 年出现1 次[20],这可能是导致山西省水资源总量大幅度变化的原因。河北省水资源量波动较大,地下水资源量影响着全省水资源总量的变化,地表水资源量远远小于地下水资源量是由于河北省的地表水已专供北京和天津地区使用[21]。总而言之,华北地区水资源极为短缺并且人们过分依赖于地下水的开采,导致地下水位持续下降,使华北地区成为世界上最大的地下水漏斗区。


图9 华北地区各省(市)水资源趋势图
4.3 假设检验
利用假设检验,对各区域进行趋势检验。在给定的置信水平 = 0.05 上,如果支持原假设(水资源数据有明显趋势变化)的概率为 p,当 p < 0.05 则原假设将被拒绝,说明随着时间变化的序列不存在明显的变化趋势;当 p>0.05 则接受原假设,说明随着时间变化的序列存在明显的变化趋势;得到的 p 值如表 1 所示,除华东地区以外,其值小于 0.05,所以华东地区有足够的理由拒绝原假设,因此没有明显的变化趋势。其它 6 个区域的 p 值均大于 0.05,因此趋势性检验显著。
另外,通过趋势性检验的测量值可以说明各区域降水量随年份变化的具体趋势。从表 1 中可以看出华北与东北地区的检验值均为正值,说明华北与东北地区 15 年来水资源总量总体呈上升趋势,而其它区域均为负值,故呈现下降趋势。

表 1 各地区 Mann-Kendall 趋势性检验值
4.4 趋势拟合
利用三次差值拟合法得到的平滑曲线如图10 所示,Lowess 局部加权拟合与预测图如图11 所示,从图11 中则可以看出根据平滑程度为目的,选择一个合适的 f 是由主观决定的。平滑的 Lowess 变化通过改变窗口的宽度,就像被平滑因子 f 所控制。f 取值越小说明曲线平滑程度越低越接近于数据的具体趋势,f 取值越大越接近于 1 说明曲线平滑程度越高只能说明数据的大体趋势不能更精确地表达数据,有较大的误差。在 Lowess 中根据回归次数不同,预测的模型曲线则不同。图11 中可以看出二次回归的预测值与趋势线拟合程度比一次回归的要高,更接近于数据的准确性。
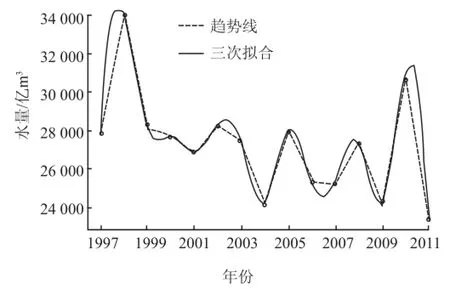
图10 三次样条差值拟合
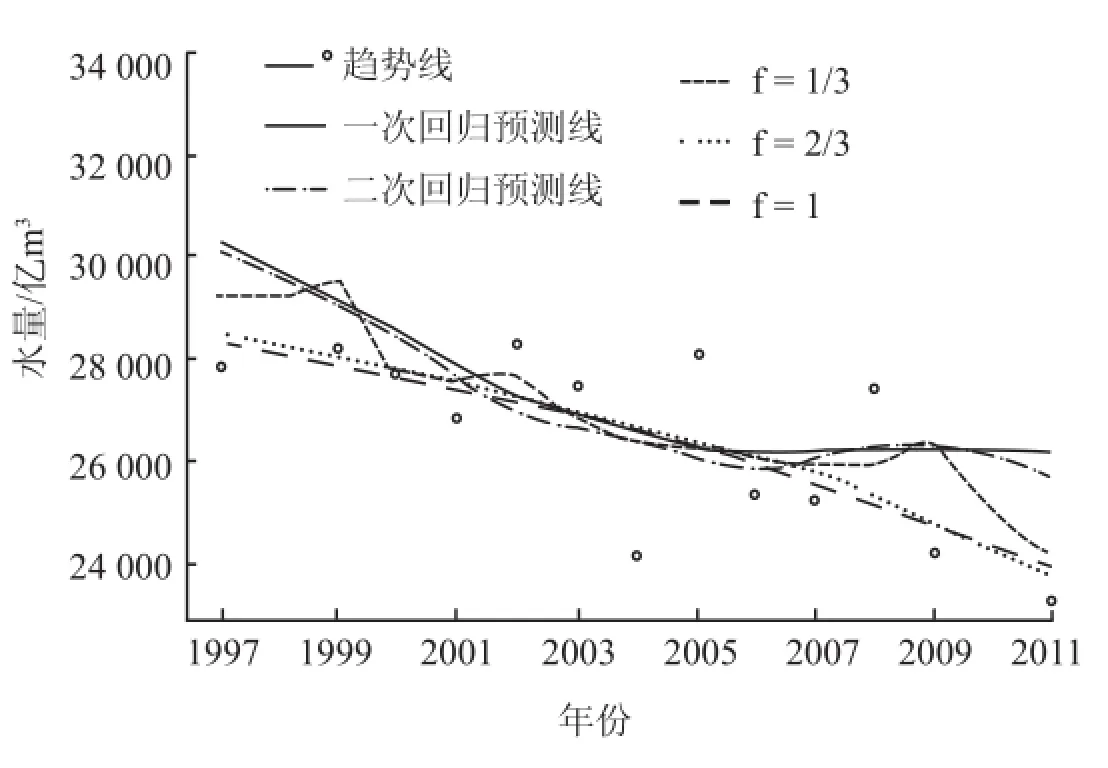
图11 Lowess 局部加权拟合与预测图
5 结语
主要以 1995—2011 年全国各省水资源统计数据集为例,通过图形化方式清晰展示了不同地区、省份的空间维度下水资源按时间的变化情况,也可以快速地比较出最合适的趋势拟合方式。这些工作都符合日常水利业务领域的需求,是非常有价值和意义的。
未来的研究将主要在 2 个方面:1)由于所选用的数据集数据量小,周期序列不够长,展现出的趋势拟合效果有限。后续工作将集中于面向水利领域传感器流数据的分析与挖掘,深入应用 R 语言在大数据方面的处理能力;2)在前期工作的基础上,构建面向水利领域特定数据的分析展现平台。
参考文献:
[1] 刘昌明,王红瑞.浅析水资源与人口、经济和社会环境的关系[J].自然资源学报,2003,18 (5): 635-644.
[2] 蔡阳.国家水资源监控能力建设项目及其进展[J].水利信息化,2013 (6): 5-10.
[3] 冯钧,许潇,唐志贤,等.水利大数据及其资源化关键技术研究[J].水利信息化,2013 (4): 6-9.
[4] T.Hey,S.Tansley,K.Tolle.第四范式:数据密集型科学发现[M].北京:科学出版社,2012: i-xxiv.
[5] A.Rajaraman,J.D.Ullman.大数据:互联网大规模数据挖掘[M].北京:人民邮电出版社,2012: 1-40.
[6] J.Maindonald,W.J.Braun.Data Analysis and Graphics Using R—an Example-Based Approach[M].Third Edition.New York: Cambridge University Press,2010: 1-10.
[7] L.Torgo.Data Mining with R: Learning with Case Studies[M].Boca Raton: Chapman&Hall/CRC,2011: 1-94.
[8] S.Das,Y.Sismanis,K.S.Beyer,et al.Ricardo: Integrating R and Hadoop[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data.Indiana: ACM Press,2010: 987-998.
[9] F.Ye,Z.J.Wang,F.C.Zhou,et al.Cloud-based Big Data Mining &Analyzing Services Platform integrating R[C]//Processing of 2013 International Conference on Advanced Cloud and Big Data.Nanjing: IEEE Computer Society,2013: 147-151.
[10] F.Zulkernine,M.Bauer,A.Aboulnaga.Towards Cloudbased Analytics-as-a-Service (CLAaaS) for Big Data Analytics in the Cloud[C]//Processding of 2013 IEEE International Congress on Big Data.Santa Clara,IEEE ComputerSociety,2013: 62-69.
[11] D.R.Helsel,R.M.Hirsch.Statistical Methods in Water Resources[A]// Techniques of Water-Resources Investigations of the US Geological Survey Book 4,Hydrologic Analysis and Interpretation[M].http://water.usgs.gov/pubs/twri/ twri4a3/,2012: 1-97.
[12] R Development Core Team.R: A Language and Environment for Statistical Computing[Z].R Foundation for Statistical Computing.[2014-08-14].http://www.R-project.org/
[13] 中华人民共和国国家统计局.中国人口统计年鉴 1949—2012[EB/OL].[2014-08-14].http://www.datatang.com/ data/46244.
[14] 陈传友.西南地区水资源及其评价[J].自然资源学报,1992,7 (4): 312-328.
[15] 中华人民共和国水利部.2004 年全国水资源公报[R].北京:中国水利水电出版社,2005: 1-5.
[16] 中华人民共和国水利部.2011 年全国水资源公报[R].北京:中国水利水电出版社,2012: 1-24.
[17] 刘艳慧.内蒙古水资源供求现状分析与评价[J].内蒙古统计,2008,3 (2): 21-22.
[18] 北京市水务局.2011 年北京市水资源公报[R].北京:中国水利水电出版社,2012: 1-17.
[19] 天津市水务局.2011 年天津市水资源公报[R].北京:中国水利水电出版社,2012: 1-10.
[20] 薛凤海.山西省水资源问题研究[J].水资源保护,2004,20 (1): 53-56.
[21] 吕长安.河北省水资源现状分析与解决措施[J].中国水利,2003,3 (6): 76-77.
Analysis of Water Resources Data in Different Provinces between 1995-2011 Using R
YE Feng1,WANG Lu1,WANG Zhijian1,ZHANG Peng2,MAO Shenglu3
(1.College of Computer and Information,Hohai University,Nanjing 211100,China;
2.Hydraulic Engineering Planning Office of Jiangsu,Nanjing 210029,China;
3.Water Conservancy Bureau of Liuhe District,Nanjing 211500,China)
Aimed at easing the water crisis,developing and utilizing the water resource appropriately,it is critical to quantify water resource from the space-time dimension,as well as analyze and mine the valuable knowledge and patterns in the datasets.As a free software with a wealth of statistical computing and data presentation capabilities,R has become a major data analysis,mining and graphical presentation tool for big data.Based on summarizing the characters of water resource data,and according to the analysis of statistics of water resources in different provinces from 1995 to 2011,it introduces how to utilize different methods to analyze water resources using R including hypothesis tests and trend analysis.Through graphical presentation,the results can show how the water resource varies with time in different areas or provinces,and quickly choose the best trend fitting mode for the business demand in the water conservancy domain.
big data;R language;water resource;data analysis
TP312;TV21
A
1674-9405(2015)01-0001-08
2014-08-03
江苏水利科技项目“‘智慧河流’研究及其在六合滁河管理中的应用”(2013025);国家科技支撑计划项目数字流域关键技术(2013BAB05B00);基于物联网的流域信息获取技术研究(2013BAB05B01);河海大学中央高校基本科研业务费项目(2009B21614)
叶 枫(1980-),男,山东济南人,讲师,主要从事云计算和水信息学的研究。
猜你喜欢
水资源与水工程学报(2022年2期)2022-05-19
今日农业(2021年3期)2021-12-05
今日农业(2021年10期)2021-11-27
第一财经(2021年6期)2021-06-10
中国化肥信息(2019年1期)2019-01-17
浙江水利科技(2018年5期)2018-10-08
消费导刊(2018年10期)2018-08-20
Coco薇(2017年9期)2017-09-07
纺织服装流行趋势展望(2016年2期)2016-05-04
山西水利(2015年12期)2015-12-16
