
基于云计算的微博数据挖掘研究综述
2014-12-28 02:44贾冲冲王名扬张晓霞东北林业大学信息与计算机工程学院黑龙江哈尔滨150040
安徽农业科学 2014年31期
贾冲冲,王名扬*,郑 丹,张晓霞 (东北林业大学信息与计算机工程学院,黑龙江哈尔滨150040)
云计算和Web 2.0技术的发展带领人们走进了“大数据”时代和社交网络交互时代,新技术催生了微博并使之成为新的信息互动和传播的社会化媒体,网络与用户间的关系已由用户被动接受网络呈现的信息转变为主动参与的模式。用户通过发布内容、参与讨论以及分享转载等行为使互联网呈现出更加主动、丰富的形态。数据的增长海量化、类型多样化、传播即时化以及事件的突发性、影响持久化等诸多表现,从一定程度上影响着社会的稳定和舆论走势[1]。技术在提供便利的同时也考验着人们对海量数据的分析和驾驭能力。如何从时刻变化的海量数据中提取出有价值的信息,同时对消极、负面和虚假的信息进行及时监管,已经成为社会化媒体数据研究的重要问题[2]。而云计算可以为海量数据处理和分析提供高效的计算平台,数据挖掘技术在云计算平台的应用将使得微博成为互联网领域的又一变革力量。
为此,笔者以新浪微博为研究对象,从微博数据的获取,到好友推荐、用户影响力评价、网络舆情监测等实际应用,阐述了如何借助云计算平台对微博产生的大量数据进行挖掘的研究成果。
1 微博数据的获取
微博数据挖掘的前提是数据获取。新浪开放平台为第三方提供了获取微博信息的API接口以及方便微博API调用的支持多种计算机语言的SDK软件开发包,其中封装了从授权认证到数据获取与解析的各项功能,开发者通过申请Accesstoken获得开发者权限,就可编写程序调用API接口获取用户信息和微博内容等数据。此外,开发者也可通过Web爬虫方式访问新浪微博平台页面,解析后获取所需数据。
新浪微博拥有数以亿计的微博用户群体,其产生的海量数据给分析研究工作带来一定的困难。作为一个社会化媒体,微博要为用户呈现实时的准确数据和良好的用户体验,因此需要先进的计算分析手段提供技术支撑,而Hadoop就是这样一个能够应用的主流云计算平台。Hadoop是一个能够对大量数据进行分布式处理的软件框架,主要由分布式文件系统HDFS和分布式编程模型MapReduce组成。Hadoop使得用户能轻松开发和运行处理海量数据的应用程序,新浪微博海量数据的获取、处理、存储以及数据挖掘算法均可编写相应的MapReduce程序实现分布式运行,MapReduce架构如图1所示。
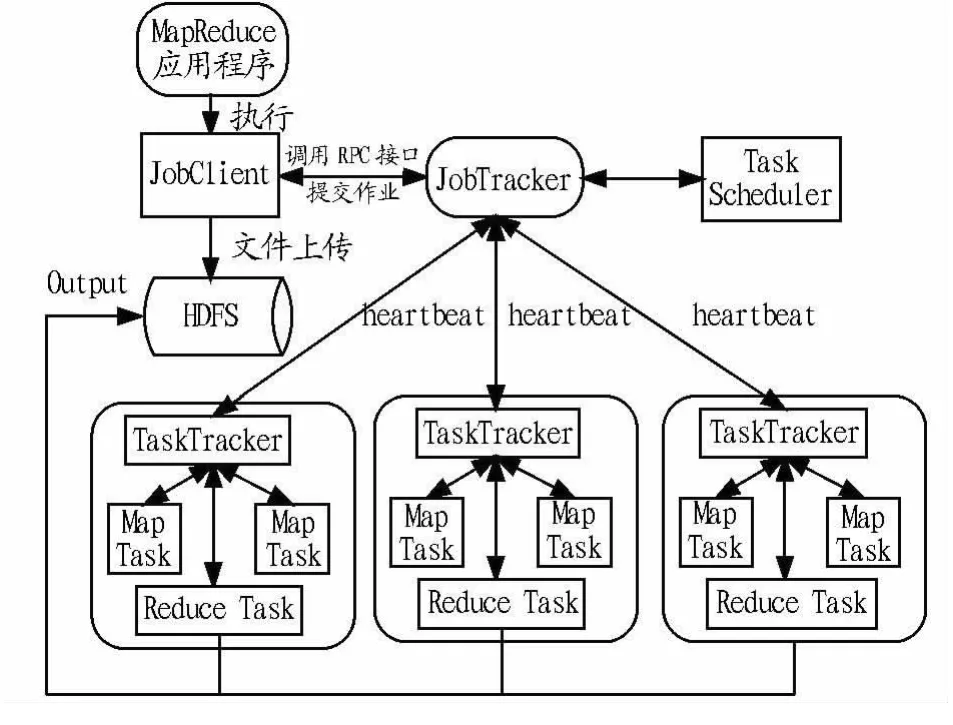
图1 Hadoop MapReduce架构
2 基于云计算的微博平台数据挖掘
2.1 微博用户的好友推荐研究 微博好友推荐系统是微博数据挖掘最基础的应用,它通过关系预测来帮助用户找到感兴趣的人。目前,推荐算法使用较为广泛的是基于内容的推荐和基于协同过滤的推荐。基于内容的推荐主要是依据用户个人信息、标签及以往浏览记录等;协同过滤的原理是查找与目标用户相似的近邻用户,根据近邻用户的评价对目标用户作出推荐。
传统的用户关系预测方法通过共同关注计算用户间的关系强度,假设用N表示关注列表集合,那么用户A和用户B的关系强度R计算公式为:

在式(1)基础上,学者们又进一步提出一些改进的算法,如胡文江等提出一种基于标签的协同过滤算法,用于寻找与目标用户最相似的用户,以进行推荐[3];杨婷设计了基于MapReduce的Dijkstm算法和PageRank算法,计算被推荐用户到其他用户的距离和用户影响力,并结合用户信息基于内容的方式进行推荐[4];Papadimitriou等基于小世界理论探索了更大范围的用户对好友关系的影响,并尝试将算法应用于MapReduce[5]。
微博好友推荐系统是微博用户扩展社交圈子的重要途径,且用户间的关注和粉丝关系处于时时的动态变化中。云计算所具有的效用计算和自主计算特点使得推荐更加快速和准确,对于提高用户体验具有重要意义。
2.2 用户影响力的评价研究 微博用户的影响力体现在发博用户通过舆论对其粉丝用户所带来的影响,用户影响力越大,其传播能力越强,由此,影响力最强的那些用户就成了意见领袖,他们拥有更多的话语权,对于信息扩散、舆论导向和商品推介等有着重要作用[6]。目前,国内外学者研究影响力的方法有以下几类。
(1)基于PageRank的评价方法。舒琰等将好友数量作为用户影响力的一个重要指标,基于PageRank进行了MapReuce改造完成了用户影响力排名[7]。PageRank的计算公式为:
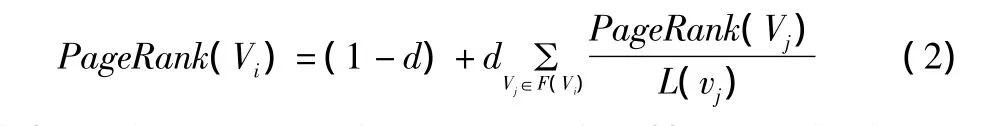
式中,Vi表示用户i;d为阻尼系数,表示某用户随机关注其他用户的概率;F(Vi)表示用户i的粉丝集合;L(Vi)表示用户Vj的关注数。
(2)基于用户行为的评价方法。Cha等在研究中,对微博中最常见的转发、评论、提及3种行为进行研究,并分析了这3种行为所表征的用户影响力类型[8]。
(3)基于PageRank和用户行为的评价方法。陈浩基于PageRank从用户自身质量及其粉丝质量着手,考虑了粉丝数量、评论率、转发率和是否微博认证用户等因素进行影响力评价[6];康书龙结合用户发表微博活跃度和PageRank算法,提出了Behavior-Relationship Rank算法来评价用户影响力[9]。
(4)基于URL追踪的评价方法。Bakshy等指出口碑信息通过许多级联进行传播。通过追踪URL传播情况,并按一定方式分配相应的影响力进行评价[10]。
(5)新浪微博的用户影响力评价模型。新浪微博定义的影响力由活跃度、传播力和覆盖度3大指标构成。活跃度代表发博、转发、评论的有效条数;传播力与微博被转发、被评论的有效条数和有效人数相关;覆盖度则取决于微博的活跃粉丝数的多少。其计算公式为:

由以上可知,微博用户影响力研究考虑的因素主要是用户关系(关注、粉丝等)和用户行为(评论、转发等),其中PageRank是当前用户影响力研究的主流应用算法。由于PageRank算法需要多次迭代,所以当用户量较大时,云计算将是很好的解决手段。
2.3 网络舆情监测研究 网络舆情是指在一定社会空间内,针对社会事件的发生、发展和变化,民众通过网络对公共问题或社会管理者产生和表现出的态度、价值观。互联网的开放性和虚拟性让言论自由得到释放,对那些能引起公众关注的事件,尤其是突发事件(如地震、恐怖袭击等),很快便成了网络舆情[11]。网络舆情是社会舆情在互联网空间的映射,是社会舆情的直接反映,对政治生活秩序和社会稳定的影响越来越大。
社会管理者应当熟悉网络舆情的特点,对于网络中出现的引起相当关注的舆论能够及时作出反馈,防患于未然。因此,使用现代信息技术对网络舆情进行分析,形成一套自动化网络舆情分析系统,从而控制和引导舆论走向是非常必要的。舆情分析系统的技术核心在于舆情分析引擎,主要涉及文本分类、聚类、观点倾向性识别、主题检测与跟踪、自动摘要等计算机文本信息内容识别技术。目前,针对微博舆情,研究者主要从如下几个方面展开分析。
(1)热点话题识别。可以根据微博出处权威度、评论数量、发言时间密集程度等参数,识别出某时间段内的热门话题。
(2)倾向性分析。对微博内容及其评论进行情感分析。
(3)主题跟踪。分析新发微博的话题是否与已有主题相同。
(4)自动摘要。对各类微博主题能够形成自动摘要,帮助理解话题的核心语义。
(5)趋势分析。分析某话题在不同的时间段内人们所关注的程度,来预测它的发展趋势。
(6)突发事件分析。对突发事件综合分析,获知事件发生的全貌并预测事件的发展趋势。
(7)警报系统。对突发事件、涉及公共或人身安全的敏感话题及时发现并报警。
(8)统计报告。根据舆情分析结果生成报告,提供信息检索功能。
2.3.1 热点话题发现。热点话题是指在特定的时间段内出现频率较高或传播范围较广的主题特征词[12]。通过热点话题可以了解当前的微博讨论热点、发现舆情事件等。热点话题的获取一般包括中文分词处理、微博文本特征词获取和话题提取3个主要步骤。
2.3.1.1 微博分词处理。微博文本内容长短不一,为了提取话题,需要对其进行分词处理。常用中文分词效果较好的是由中国科学院开发的ICTCLAS汉语分词系统,ICTCLAS分词精度达到98.45%,分词速度500 kB/s左右,并且支持多级词性标注,提供了包括Java在内的多种计算机语言开发工具包。完成分词后,还要对照停用词表进行去停用词处理,停用词是指对文本意思表达无用的词,如“的”、“呢”等。去除停用词可以降低文本特征向量的维度,减少数据处理复杂度。
2.3.1.2 微博文本特征词获取。文本特征词提取的常用算法是TF-IDF,其思想是:如果某词在一个文本中出现频率(TF)较高,在其他文本中很少出现,则该词具有很好的类别区分能力,选取几个这样权重较高的词可作为该文本的主题特征词。TF-IDF算法表示如下:
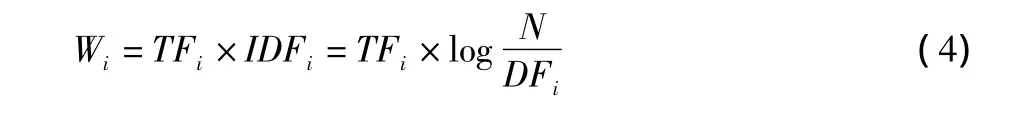
式中,Wi表示单词i的权重;TFi表示单词i在该文本中出现的频率;DFi表示文本集合中出现单词i的文本数量;N表示文本集合的数量。
2.3.1.3 微博话题提取。获取某时段每条微博的特征词后,基于MapReduce的并行FP-growth算法挖掘主题特征词的关联规则频繁项集,根据产生的频繁项集提取该时段的热点话题。基于MapReduce的并行FP-growth算法执行过程如下:①扫描数据,计算一项集的计数。②根据计数与支持度计算出频繁一项集,对于频繁一项集按照计数从大到小排序,存入HDFS,执行Map或Reduce任务前到HDFS上读取相应的项集和序号。③根据划分集合的数目将频繁一项集划分为G份,对每份标号(GID),把一项集映射到对应的GID上,将产生的G-List存入HDFS,以后读取。④再次扫描事务数据,将事务项集转换成项集的序号集合,并对其排序,再生成相应的条件事务序号集合。将其根据GID收集,再对每个GID构造FP树,然后得出条件模式基和条件FP树,再得出最大的K个频繁模式。⑤将所有项集的频繁模式收集起来,对于每个项生成最大的K个频繁模式。
2.3.2 情感分析。情感分析是对带有情感色彩的主观性文本进行分析、归纳和推理的过程。微博中的情感分析是根据微博内容、发博时间等信息,分析发博者所表现出的情绪状态,进而对发博者即将可能产生的行为作出评估。微博及其评论中包含了很多发博者的主观情感内容,对其情感数据的挖掘可用于舆情监控、商品口碑评估、民意倾向预测、网络救助等实际应用中。
微博文本情感分类一般被作为一个二分类问题,即将微博文本集T分为两个类型:T={T1,T2},T1表示(支持、积极的)正面类型,T2表示(反对、消极的)负面类型。情感分类就是利用分类器模型判断微博文本t属于T1还是T2。目前情感分类的方法有基于特征的情感分类方法和基于情感知识的情感分类方法。前者主要使用机器学习手段,让机器学习人工标注好的数据集,从中发现分类规则作为对其他数据集分类的依据;后者建立在情感词典或语义规则的基础上,由于新的网络词语不断出现,且用户更倾向于对新词的使用,使得情感词典的选择和维护工作给此方法带来一定的难度。目前中文微博的情感分类主要是借助情感词典作为特征选择并利用机器学习方法实现分类。该研究总结了基于机器学习的微博文本情感分类算法流程,如图2所示。
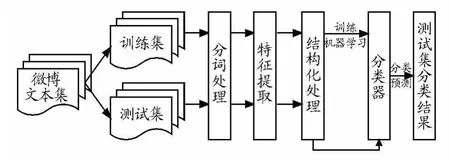
图2 微博文本情感分类算法流程
微博情感分析的文本数据可以选择话题微博,也可以选择话题微博的评论。情感分析完成后,就可进行综合分析和趋势预测,来获知公众对该话题所持的态度,以此为管理者提供决策。
同时应该注意到的是,由于人类情感的复杂性、中文的多义性、受公众情绪的影响而导致的情绪转变和传递等众多因素,使得简单的二分类或者是正、中、负三维描述已无法准确评判用户情感,挑战是一直存在的。
3 结语
针对微博大数据平台,该研究从最初的数据抓取、预处理到最后数据挖掘和实际应用进行了较为全面的介绍,说明了微博平台数据挖掘的价值。微博作为网络时代产物,随着计算机技术的发展和网络用户数量的增多,其产生的影响力也将越来越大。云计算在微博平台上的应用,使得对数据的处理更加方便和快捷,为新应用产品的出现和带来更好的用户体验,提供了更多可能性。
[1]许斌.中文微博的情感分析和影响力技术研究[D].郑州:解放军信息工程大学,2013.
[2]姚海波.微博热点话题检测与趋势预测研究[D].广州:华南理工大学,2013.
[3]胡文江,胡大伟,高永兵,等.基于关联规则与标签的好友推荐算法[J].计算机工程与科学,2013(2):109 -113.
[4]杨婷.基于MapReduce的好友推荐系统的研究与实现[D].北京:北京邮电大学,2013.
[5]PAPADIMITRIOU A,SYMEONIDISP,MANOLOPOULOSY.Fast and accurate link prediction in social networking systems[J].Journal of Systems and Software,2012,85(9):2119 -2132.
[6]陈浩.基于Hadoop的微博用户影响力排名算法研究[D].广州:华东理工大学,2014.
[7]舒琰,向阳,张骐,等.基于PageRank的微博排名MapReduce算法研究[J].计算机技术与发展,2013(2):73 -76,81.
[8]CHA M,HADDADI H,BENEVENUTO F,et al.Measuring user influence in twitter:The million follower fallacy[C]//AAAI.Washington,DC,USA:ICWSM,2010:11 -13.
[9]康书龙.基于用户行为及关系的社交网络节点影响力评价[D].北京:北京邮电大学,2011.
[10]BAKSHY E,HOFMAN JM,MASON WA,et al.Everyone’s an influencer:Quantifying influence on twitter[C]//WSDM.Hong Kong.China,2011:67-69.
[11]陈彦舟,曹金璇.基于Hadoop的微博舆情监控系统[J].计算机系统应用,2013(4):18 -22,9.
[12]林大云.基于Hadoop的微博信息挖掘[J].计算机光盘软件与应用,2012(1):7-8.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
NBA特刊(2018年14期)2018-08-13
电力与能源(2017年6期)2017-05-14
人大建设(2017年11期)2017-04-20
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
信息通信技术(2015年6期)2015-12-26
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
