
用Fluent与MongoDB构建高效海量日志采集系统
2014-11-16 07:04韩岩李晓
中国新技术新产品 2014年12期
韩 岩 李 晓
(1.中国科学院新疆理化技术研究所,新疆 乌鲁木齐 830011; 2.中国科学院大学,北京 100049)
1 概述
日志是一个完整系统里面重要的功能组成部分,其利用特定的形式准确并且规范地表达出系统产生的所有行为,依据对日志的分析不仅可以对系统自身的性能进行有效的优化,而且当系统发生故障时,能够准确、及时地定位错误,方便加以修正。
目前,随着互联网web2.0的迅速发展,一个企业级的服务器每天产生日志信息是相当可观的,日志分析研究多集中在如何挖掘数据,而对如何存储海量数据研究较少。这主要是因为很多日志分析系统采用了关系数据库存储或简单的顺序存储,如商用的Oracle数据库,免费的MySQL。采用关系数据库存在效率低下的缺点,简单的顺序存储又存在功能不够强大、查询效率低等不足。因此日志处理缺乏一种能高效查询、适合存储海量数据的管理系统做支撑。现在处理海量日志系统的方案有很多,大部分是基于分布式的原理来实现解决的。本文提出一种Fluent与MongoDB相结合的方法来完成海量日志的存储。
2 提出问题与方案
2.1 提出问题与方案
对于海量日志存储与查询,LZ是一个广告公司的技术人员,需要对500M行(5亿行)的log信息进行存储和数据分析工作,并提出了自己的三种想法:
(1)将海量数据存在MySQL中并对每一个字段做索引。
(2)将以上数据存在MongoDB中并建立索引。
(3)将所有行加载到Hadoop中,通过MapReduce进行数据分析。
2.2 提出方案的原因
第一方案选择MySQL的原因:MySQL是一个开放源码的小型关系型数据库管理系统,软件本身具有体积小、速度快、总体拥有成本低的特点。MySQL是跨操作系统、支持多线程、支持多种存储引擎和查询速度快的数据库管理系统。MySQL具有关系数据库的特征,基本可以反映出关系数据库的特性。
第二种方案选择MongoDB的原因:MongoDB是分布式文档存储数据库,它的特点是高性能、易部署、易使用,存储数据非常方便。它支持的数据结构非常松散,是类似JSON的BSON格式,因此可以存储比较复杂的数据类型。MongoDB的文档模型自由灵活,可以让你在开发过程中畅顺无比。对于大数据量、高并发、弱事务的互联网应用,MongoDB可以应对自如。MongoDB内置的水平扩展机制提供了从百万到十亿级别的数据量处理能力,完全可以满足Web2.0和移动互联网的数据存储需求,其开箱即用的特性也大大降低了中小型网站的运维成本。
第三种方案选择Hadoop的原因:Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
(1)高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。
(2)高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
(3)高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4)高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
(5)低成本:Hadoop是开源的,项目的软件成本因此会大大降低。
2.3 解决问题关键点
针对以上三种解决方案对处理海量的日志信息共同特征,解决海量日志存取主要解决以下几个问题:
(1)高并发读写:现今的网站都是实时的生成动态页面,及时提供动态信息,所以数据库的并发负载很高。尤其是电子商务网站,每秒可以是上百万的请求。
(2)海量数据的高效存储与访问:高效的解决海量数据的读取是最核心的问题之一。对海里数据而言,如果数据存储速度较慢,就会造成网络堵塞甚至网络瘫痪。如果数据库的查询性能较低,就不能及时满足用户查询需求。
(3)高扩展性与可用性:在增加较少硬件成本下,较大提高软件的性能与负载能力,保证其扩展性是可行的。另外,很多服务是实时的、不间断的,所以保证其可用性也是必要的。
3 实验与结果分析
因为日志最主要是写入与查询操作,所以用以上三种想法分别对10万、100万、1000万条数据只进行读写效率的测试。目的是为了验证海量日志数据存储与查询有效性和可行性。
实验日志数据格式如表1:
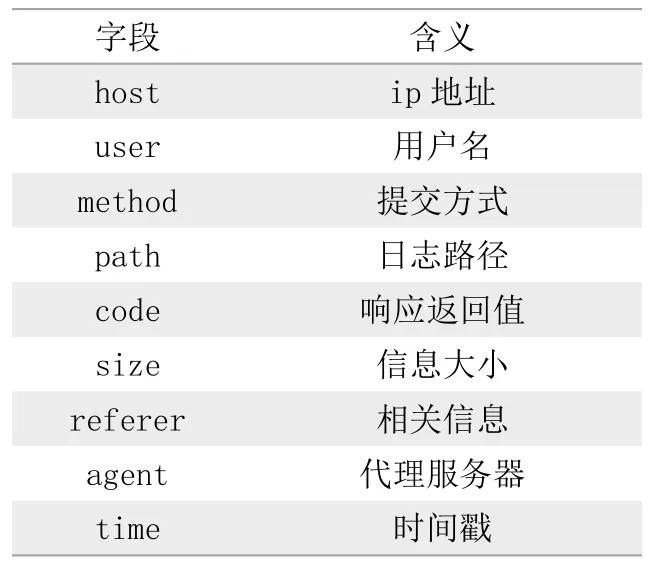
表1 日志格式
3.1 单机实验
实验说明:在单机环境下,分别对10万、100万、1000万条数据只进行读写效率的测试。以下实验是5次运行的平均结果。
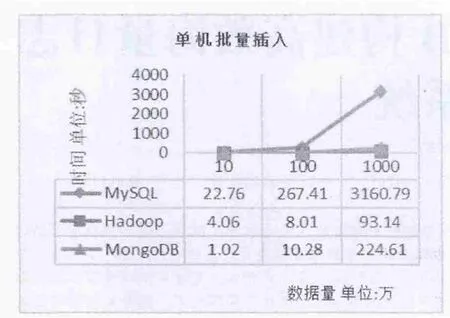
图1 单机批量插入数据
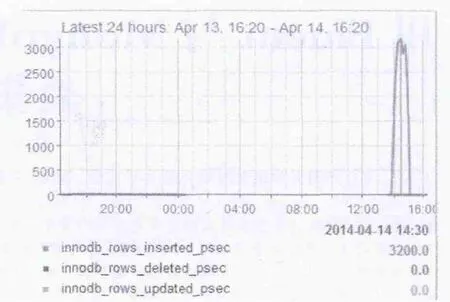
图2 MySQL批量插入性能监控图
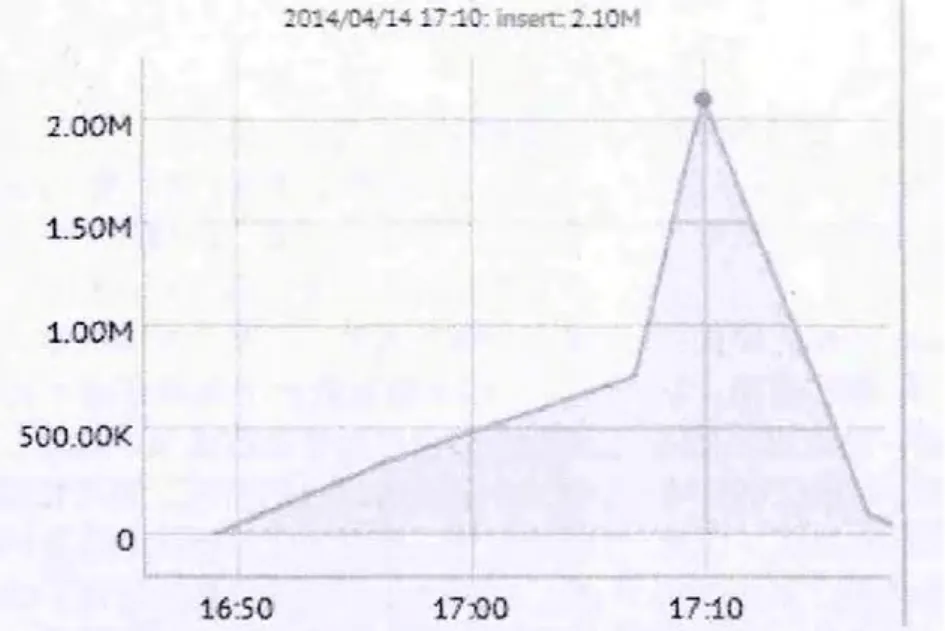
图3 MongoDB批量插入性能监控图
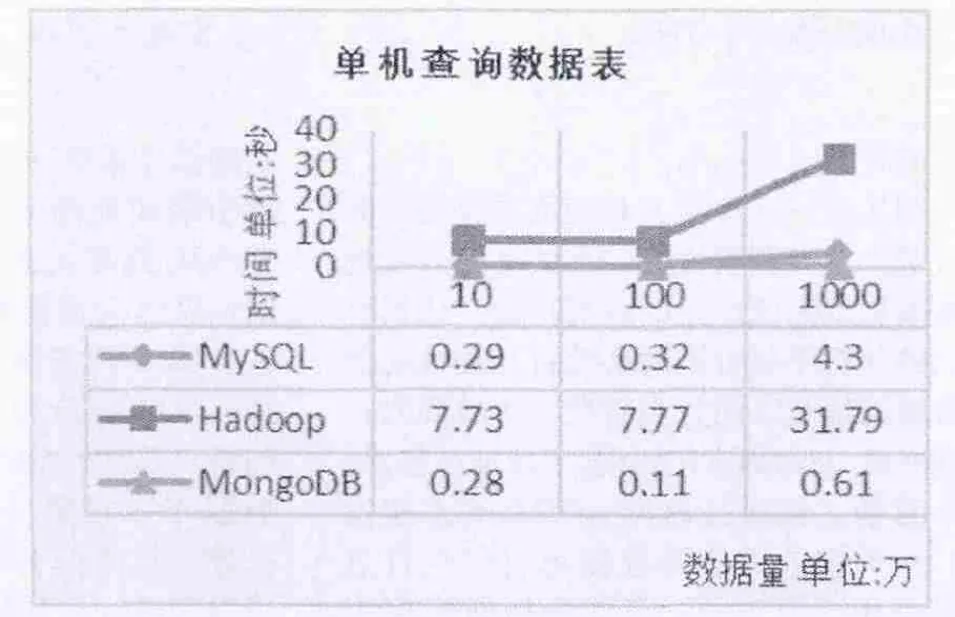
图4 单机批量查询数据
实验环境:单机条件下,在Eclipse下使用Java编写开发的项目。分别对MySQL、Hadoop和MongoDB进行批量插入(原因:数据量大,逐条插入效率低)与查询实验。
(1)批量插入数据
单机环境下,批量插入数据的实验结果如图1。
在批量插入数据时,对MySQL、MongoDB监控信息如图2、图3。
(2)查询数据
在实验数据中随机查询100条数据所用的时间,查询数据实验结果如图4。
在查询数据时,对MySQL、MongoDB监控信息如图5、图6。
(3)实验结果
实验结论:在数据量较小的情况下,无论是批量插入还是查询基本都是同一个数据量级上,都能满足用户的需求; 但随着数据量的增大,数据库建立索引后查询效率明显增加了,也增大了存储空间。通过图2与图3可知,MongoDB最大插入速度是MySQL最大插入速度的近700倍。通过图5与图6可以得知,MongoDB最大查询速度是MySQL最大查询速度的近2倍。
3.2 集群实验
实验说明:在集群环境下,分别对10万、100万、1000万条数据只进行读写效率的测试。以下实验是5次运行的平均结果。
实验环境:集群条件下,在Eclipse下使用Java编写开发的项目。分别对MySQL、Hadoop和MongoDB进行实验。
集群环境如下:①MySQL集群:是在虚拟机下以Amoeba为代理服务器3台MySQL数据库构成一个集群;②Hadoop集群:是在虚拟机下3个结点,1个master结点,2个datanode结点;③MongoDB集群:是在虚拟机下由MongoDB构建的3组复制集,每组3个分片,3个Configsvr,1个路由节点。
(1)批量插入数据
实验结果如图7。
(2)查询数据
在实验数据中随机查询100条数据所用的时间,查询数据实验结果如图8。
(3) 实验结果
实验结论:在集群环境下,满足单机条件下的结论,但时间略微有点增加的主要原因是集群的启动与集群之间数据通信。随着数据量的增大,三类不同的集群在插入与查询数据的时间都有所降低,并且MongoDB在查询数据上表现出明显的优势。总之,无论是在单机环境下还是在集群环境下,MongoDB都表现出自己独特的优势,适合作为海量日志的数据仓库。
4 构建日志系统
4.1 用Fluent与MongoDB构建日志采集系统
通过以上实验结果说明MongoDB可以作为海量日志的数据仓库,以下是用Fluent采集日志信息存储到MongoDB或集群中的原理与过程。
(1)整个系统工作原理如图9。
(2) 实现步骤:
a在Linux下,安装MongoDB或MongoDB集群以及fluent-plugin-mongo。
b修改/etc/fluent/Fluentd.conf相关配置,使得Fluent采集信息能存储到MongoDB中。
① 配置输入信息:
type tail
format apache2
path /var/log/apache2/access_log
tag mongo.apache.access
② 配置单机输出信息:
type mongo
database apache
collection access
host localhost
port 27017
flush_interval 10s
③ 配置复制集输出信息:
type mongo_replset
database apache
collection fmongo
nodes ip1:port1, ip2:port2,…
flush_interval 10s
(3) 测试结果
a测试命令:
$ ab -n 100000 -c 100 http://ip地址/
b输出结果如图10.

图5 MySQL查询性能监控图
图6 MongoDB查询性能监控图
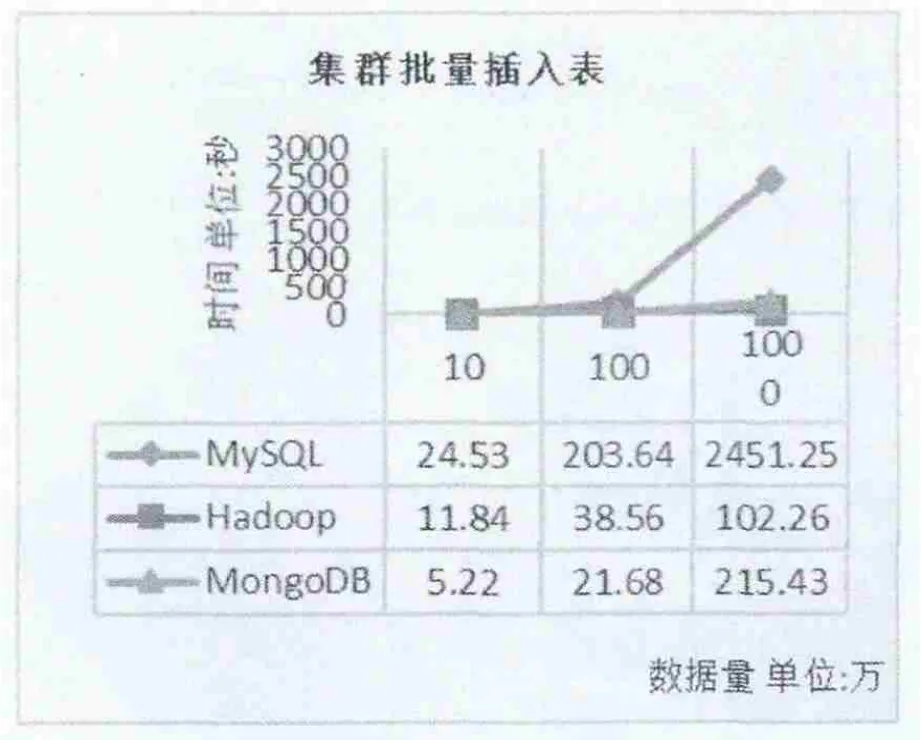
图7 集群批量插入数据
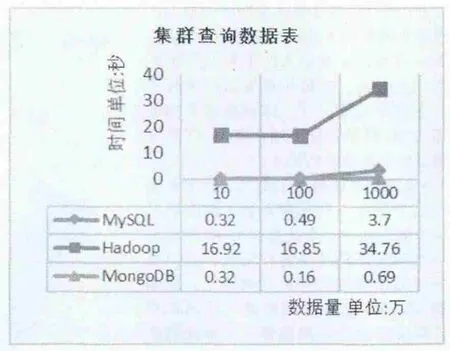
图8 集群批量查询数据
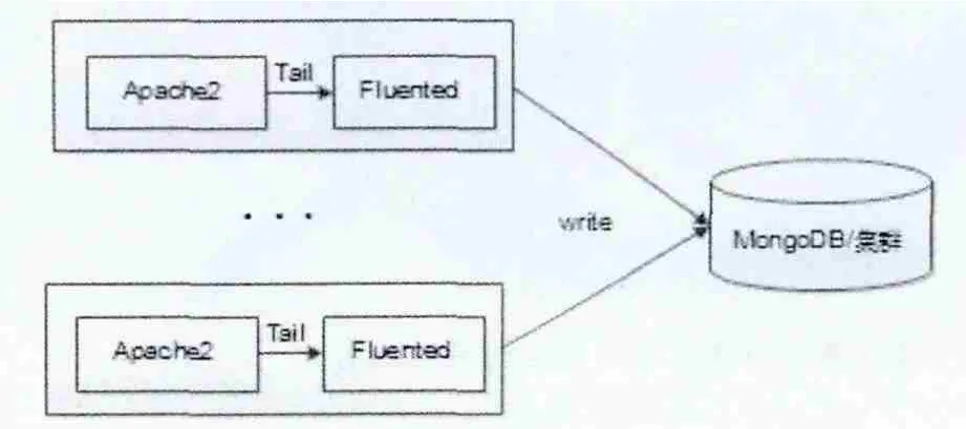
图9 整个系统工作原理
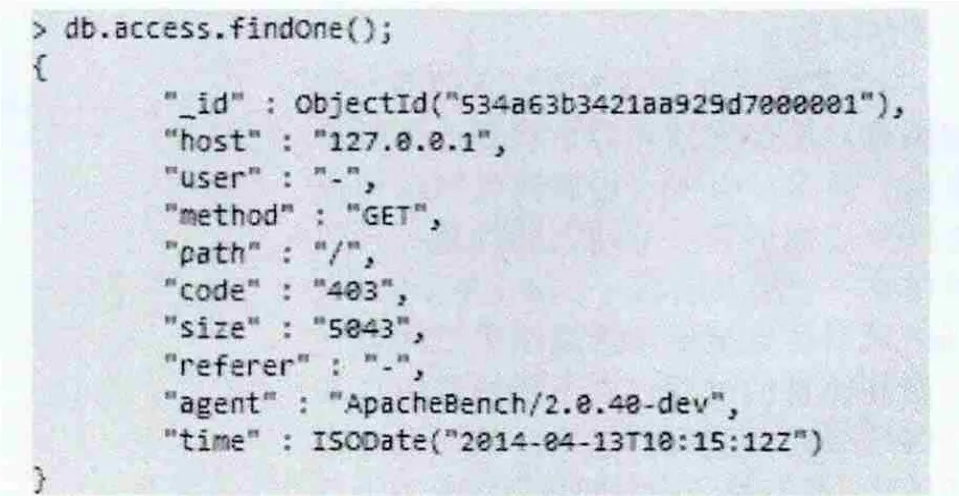
图10 输出结果
结语
本文通过验证MongoDB存储与查询高效性,然后与Fluent相结合构造一个日志采集系统。这种方式可以满足海量日志采集与存储工作,将日志信息直接存储到数据库中,对日志的“增删改查”更方便、更高效,而且日志信息可以进行分布式的存储。但这种方式也有很多不足,例如:单机情况下存储数据不稳定性,集群情况下存储数据的不平衡性和负载均衡的问题等。后续工作还有MongoDB集群的优化和日志分析系统的实现等任务。
[1]白超,杨静,吴建国.基于并行计算的海量日志分析系统实现[J].计算机技术与发展,2013,23(7):80-83.
[2]王兆永. 面向大规模批量日志数据存储方法的研究[D]. 成都: 电子科技大学,2011.
[3]nosqlfan Inc.. MySQL、MongoDB 还是Hadoop ? [EB/OL].[2010-09-02]. http://blog.nosqlfan.com/html/510.html.
[4]邹贵金.深入云计算:MongoDB管理与开发实战详解[M].北京:中国铁道出版社,2013:72-205.
[5]Kristina Cbodorow, Micbael Dirolf.MongoDB权威指南[M]. 北京:人民邮电出版社,2011:45-152.
[6]程苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011,37(11):37-39.
[7]李存琛.海量数据分布式存储技术的研究与应用[D]. 北京: 北京邮电大学,2013.
[8]孙巍,谭成翔.基于Amoeba中间件的分布式数据库管理系统[J].计算机与现代化.2013,02:153-156.
[9]张华强.关系型数据库与NoSQL数据库[J].电脑知识与技术,2011,7(20):4802-4804.
猜你喜欢
新疆钢铁(2021年1期)2021-10-14
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电子制作(2019年13期)2020-01-14
航天工业管理(2019年11期)2019-04-20
阜阳职业技术学院学报(2015年4期)2015-05-17
温州职业技术学院学报(2014年3期)2014-03-11
组合机床与自动化加工技术(2014年12期)2014-03-01
