
基于MapReduce的电力设备并行故障诊断方法
2014-09-26 11:26王德文刘晓建
电力自动化设备 2014年10期
王德文,刘晓建
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引言
电力设备是电力系统的基本组成部分,电力设备故障将直接影响智能电网的安全运行。数据挖掘是实现电力设备故障诊断的关键技术之一,是分析电力设备运行状态的主要方法。为了保证电力设备的安全运行,各种故障诊断方法得到应用。文献[1]根据模糊粗糙集算法建立信息决策系统,解决变压器故障诊断问题。文献[2]根据神经网络算法建立了一个针对断路器的快速智能诊断系统,利用断路器状态特征量进行故障类型的识别。这些方法都是在单机环境下进行的,在现有的数据级别范围内能达到较快的故障诊断速度,但没有考虑海量数据对诊断速度的影响。
智能电网中电力设备状态信息数据具有分布广、种类多、数据量巨大的特征。随着智能电网的发展,电力设备故障诊断速度的提高将会成为智能电网建设的瓶颈。
a.数据分布广。我国现有电网分布在不同地域,电力设备分布点多面广,造成电力设备状态信息数据分布广泛。
b.数据种类多。智能电网中电力设备状态信息数据不但包含电力设备在线状态数据,而且包含电力设备运行情况记录数据、电力设备故障诊断数据、电力设备检修试验数据、电力设备缺陷信息数据等[3]。
c.数据量巨大。例如,输电线路中绝缘子泄漏电流数据采样频率高,假设10 ms采集一次数据,一个杆塔在一个月内的数据量就达到了2.5亿条[4];智能电网中断路器数量较多,断路器振动信号数据采集频率高,产生的数据量巨大[5]。
针对智能电网中电力设备状态信息数据的特点,需要引入新的快速计算技术以解决传统故障诊断方法计算能力不足的问题。电力设备并行故障诊断被提出,且在智能电网中具有重要的研究价值。
MapReduce是一个针对大数据并行运算的软件框架,最大的优势在于隐藏繁琐的底层细节,简化并行程序的设计与开发工作[6-8]。文献[9]初步设计了电力系统仿真计算云,采用并行计算技术对电力系统中海量电网数据进行高效仿真计算。文献[10]设计了基于MapReduce的MPApriori算法,在Hadoop平台上实现了对海量WAMS电网数据的并行数据挖掘,且并行数据挖掘效率高于传统数据挖掘平台。总之,在智能电网中借助MapReduce的高性能的计算能力,能够使并行故障诊断算法高效地执行。
本文提出采用MapReduce技术对智能电网中海量电力设备进行并行故障诊断的方法。以对智能电网中海量变压器油中溶解气体分析(DGA)数据用朴素贝叶斯算法进行故障诊断为例,给出了基于Map-Reduce的算法并行化过程。最后,通过Hadoop平台对变压器进行并行故障诊断实验,实现了对智能电网中海量电力设备状态信息数据的快速故障诊断。
1 基于MapReduce的电力设备故障诊断并行化方法
1.1 朴素贝叶斯算法在电力设备故障诊断的应用
基于MapReduce框架的并行故障诊断算法主要为回归、聚类与分类等算法。目标是对智能电网中变压器、断路器、输电线路等电力设备产生的海量状态信息数据进行并行故障诊断,解决传统单机环境下对海量状态数据计算能力不足的问题。
本文中智能电网电力设备并行故障诊断以产生的海量变压器DGA数据为例,也可以对智能电网中断路器状态数据、输电线路波形数据等海量电力设备状态数据进行故障诊断。变压器中应用的故障诊断算法很多,如贝叶斯算法、粗糙集理论算法、支持向量机算法等,其中贝叶斯算法在变压器故障诊断中应用比较普遍[11-15]。
对变压器海量DGA数据的故障诊断以并行朴素贝叶斯分类算法为例。朴素贝叶斯算法具有方法简单、准确率高与速度快的优势,虽然原理比较简单,但是具有很好的实际应用效果。目前,使用朴素贝叶斯分类算法对变压器进行故障诊断的研究很多是单机情况下进行的,将来智能电网中需要用到并行化的朴素贝叶斯算法对海量状态数据进行快速故障诊断。
1.2 电力设备故障诊断并行化流程
Hadoop是一个方便对大数据集进行计算的分布式平台,它在集群中通过并行的工作方式加快计算速度。Hadoop集群由负责资源调度与管理文件目录结构的NameNode和若干负责管理数据存储的DataNode构成。MapReduce是Hadoop的一个子项目,用于大数据集的并行计算,可以为电力设备的故障诊断领域提供高效的并行计算能力与简单、通用的并行算法设计环境。MapReduce的执行流程如图1所示。
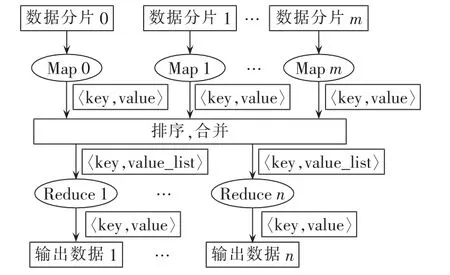
图1 MapReduce执行流程Fig.1 Flowchart of MapReduce execution
MapReduce运行模式可以自动处理数据的分割、负载均衡、容错处理等问题。MapReduce程序设计过程中只需将数据并行计算问题分解成许多可并行执行的子问题,并设计对应的Map函数与Reduce函数,就能将程序运行在分布式系统上。
MapReduce模型中输入数据文件分割成许多相同大小的数据片段,并保存在Hadoop集群中不同的存储节点。数据片段通过执行设计的Map函数,得出运算结果〈key,value〉,通过排序、合并,将 key 值一样的运算结果传送到相同的Reduce函数进行数据归并。最后根据Reduce函数得到结果,并将最终计算结果数据保存在分布式集群上。MapReduce模型使许多种计算在此框架下达到相当高的执行效率,并且还具有可扩展的特点,对大规模数据的计算优势更加明显。
1.3 电力设备故障诊断算法并行化过程
以MapReduce为基本的模型,对朴素贝叶斯算法进行并行化操作。以智能电网中海量变压器DGA数据为例对变压器进行故障诊断。首先对变压器DGA数据进行预处理使其转化成Bayes M/R job读入数据要求的格式,即每一行为1个变压器DGA数据样本,第1个字符是变压器故障类别,剩余的是离散化后的DGA数据,DGA属性数据之间用空格分开。
利用4个MapReduce作业类执行算法的训练过程,目标是得出4个值的输出结果:计算每个故障类中DGA数据属性特征词出现的频率值,计算变压器故障类中的词频反文档频率(TFIDF)值,对故障类中的TFIDF值进行求和,计算变压器各故障类中属性特征词出现的概率。其中前一个作业类的运算结果数据作为后一个作业类的输入数据。训练过程结束后得出贝叶斯分类模型并保存在分布式集群中,并行化的朴素贝叶斯算法处理DGA数据训练集的过程如下。
a.第1个MapReduce过程。Map函数接收来自训练文档的DGA样本数据块,读取每个DGA数据中的属性特征词,计算在每个属性特征词在所在故障类中出现的词频(TF)值。Reduce函数统计Map的数据结果,统计出训练数据集中每个变压器故障类的样本数据总数、TF值与故障数据中出现属性特征词的样本数据总数。
b.第2个MapReduce过程。根据第1个MapReduce的输出结果计算每个变压器故障类中每个特征属性的TFIDF值。Map过程计算每个特征属性的反文档频率(IDF)值。Reduce过程根据TF值乘以IDF值计算每个变压器故障类中特征属性的TFIDF结果,同时计算训练文档特征属性总数。
c.第3个MapReduce过程。Map函数调用每个故障类的样本数据总数与训练集DGA数据总数计算各故障类的先验概率。Reduce函数进行汇总,计算每个变压器故障类中所有特征属性的TFIDF总和,计算变压器故障类的先验概率。
d.第4个MapReduce过程。通过计算得到变压器各故障类中特征属性出现的概率,最终得出贝叶斯分类模型。
并行化的朴素贝叶斯算法对DGA数据测试集的故障诊断过程中,先对变压器DGA测试集进行预处理,将其组织成Bayes模型输入文本格式,然后用1个MapReduce过程完成对测试集的故障诊断。Map函数计算待测试的变压器DGA数据中属性特征词出现的次数,并加载训练过程得到的贝叶斯分类模型计算出测试集所属的故障类型。Reduce函数进行归并,最终获得诊断结果。朴素贝叶斯算法并行化流程图如图2所示。
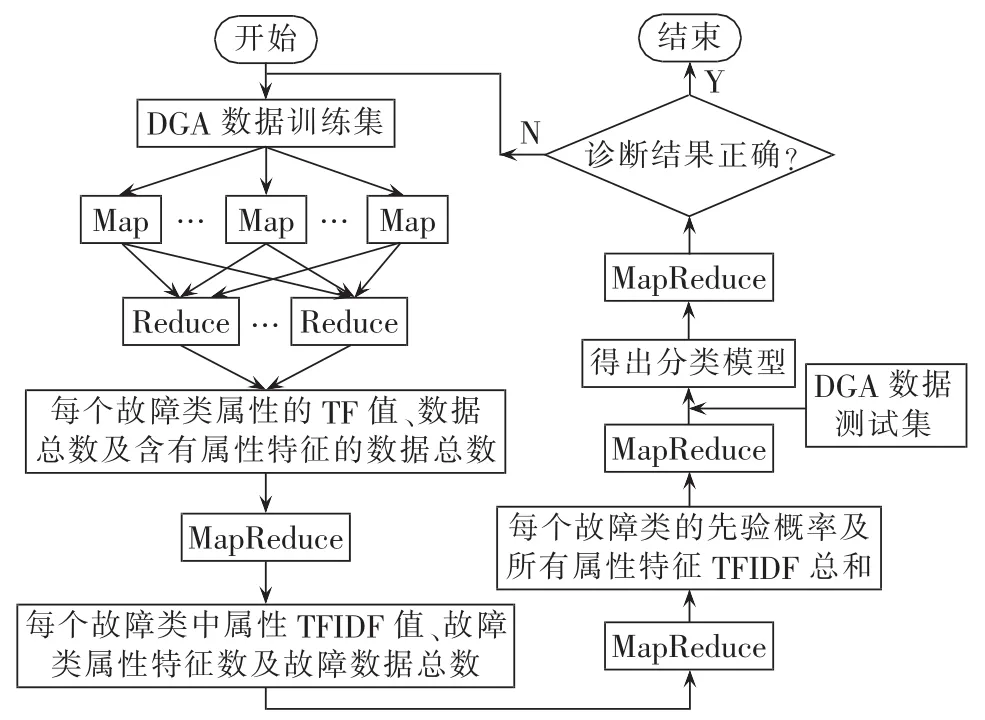
图2 贝叶斯算法并行化流程图Fig.2 Flowchart of Bayesian algorithm parallelization
2 实验过程与测试结果分析
2.1 实验环境
本文在实验室构建了一个电力设备状态信息并行故障诊断实验平台。实验环境由10台配置相同的普通PC机组成,其中一台PC机作为NameNode,其他PC机均作为DataNode。每台PC机CPU均为双核 Interi5-2400,主频 3.10 GHz,4.00 GB 内存,80 GB硬盘。Hadoop所用版本为0.20.2。
实验中以额定电压在220 kV及以下的变压器作为研究对象。根据相关文献和电力公司中有关变压器的历史资料收集到具有明确故障的237条变压器故障数据与369条健康状态下运行的变压器数据[16-18]。实验过程经过反复多次的测试,取平均值作为最终实验结果。
2.2 变压器故障类型及离散化标准
根据IEC标准和我国电力行业标准DL/T722—2000[19],变压器故障类型如表1所示,部分变压器故障数据如表2所示(φ表示气体含量)。
朴素贝叶斯分类算法是一种符号化分析算法,算法中的属性值都看作定性数据,因此需要对变压器DGA数据属性值进行离散化处理。考虑到在实际变压器故障诊断中,不同气体含量值和气体间比值,其定量标准差异很大。所以,可行的离散化方法是依据一定的规则,对不同属性值设定阈值进行分段,每一段作为定性数据,从而保证变压器故障诊断顺利进行。 根据 DL /T722—2000[19]和相关文献[20-21]以及专家经验,变压器DGA数据离散化如表3所示。
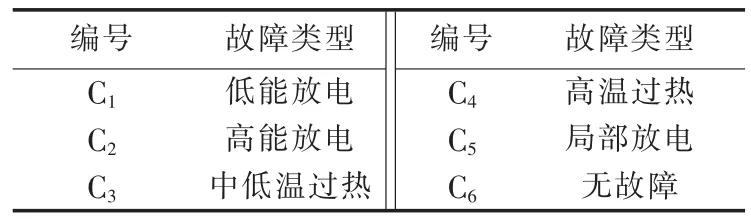
表1 变压器故障种类Table 1 Categories of transformer fault
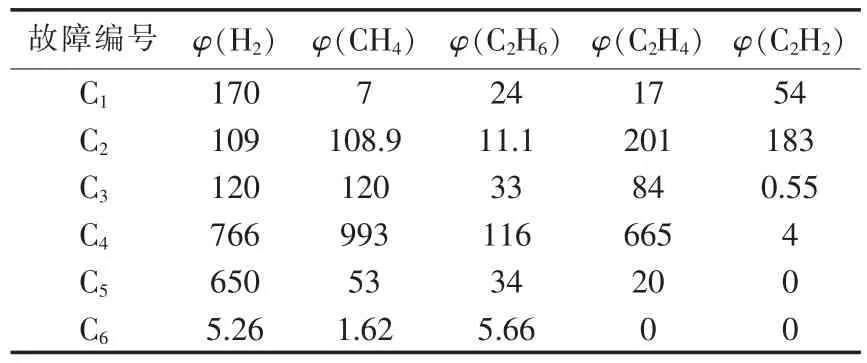
表2 部分变压器故障样本Table 2 Partial of transformer fault samples μL /L

表3 DGA数据离散化Table 3 Discretization of DGA data μL /L
2.3 朴素贝叶斯算法并行化的验证
本实验变压器DGA样本数据的训练集与测试集按2∶1随机划分,在小规模DGA数据集的情况下,在集群上应用并行化的朴素贝叶斯分类算法对变压器进行故障诊断,实验结果如表4所示。
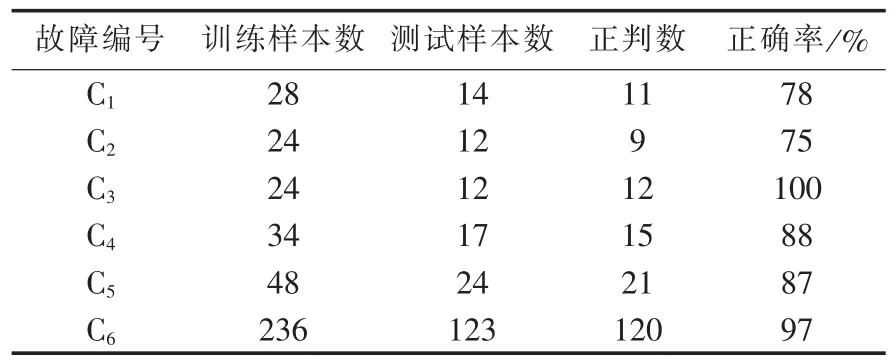
表4 变压器故障诊断结果Table 4 Result of transformer fault diagnosis
如表4所示,依据文献[21],本实验对存在故障的变压器的诊断准确率是正常的故障诊断率,在变压器数据样本充足的情况下诊断正确率会进一步提升。并行化的朴素贝叶斯算法对变压器DGA数据显示出了预期的诊断效果,并对算法的诊断结果取得了初步验证。
2.4 Hadoop集群与单机运行时间对比实验
本实验要在Hadoop实验平台上模拟对智能电网中海量变压器在线监测DGA数据集的故障诊断,必须增大测试集的数据规模。由于条件限制无法得到大规模测试数据,实验中采取随机复制已有数据集的方法,来得到大规模的测试数据。在实验中,测试在相同大小DGA数据集下朴素贝叶斯算法在Hadoop平台与单机平台上的运行时间,实验结果如表5所示。
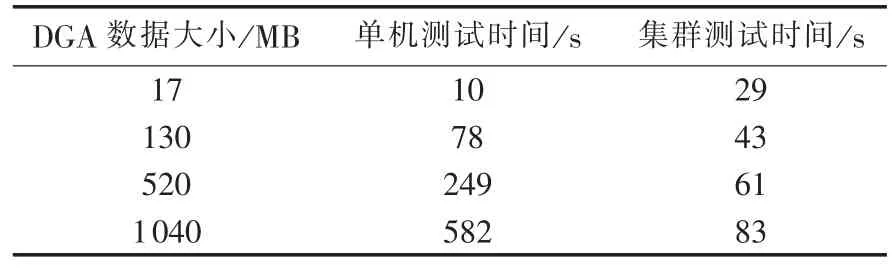
表5 测试时间对比Table 5 Comparison of test time
由表5可见,当测试的变压器DGA数据集规模较小时,集群的运行时间大于单机运行时间,这是因为算法的执行过程中集群计算节点之间需要信息交互,消耗了一定的时间,而这部分时间占总运行时间的比例较大,导致集群的运行时间大于单机环境下;当测试数据规模逐渐增加时,集群的计算时间效率越来越高于单机环境下,体现了Hadoop集群对大数据集进行运算的优越性。
2.5 集群加速比性能分析
加速比为处理相同数据规模时处理器数量从p增加为q时集群的加速效果,是评判一个算法并行化效果的重要指标[22]。本实验主要测试并行化的朴素贝叶斯算法处理不同大小DGA数据集时的加速比,结果如图3所示。
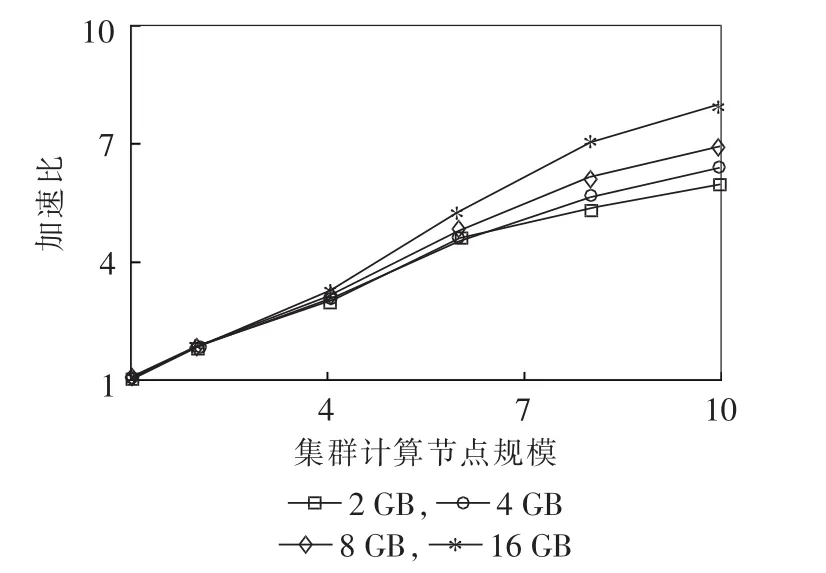
图3 加速比测试结果Fig.3 Result of speedup ratio test
从图3中可知,并行化的朴素贝叶斯算法的加速比是接近线性的,这是由于相同数据规模下集群规模越大,算法的计算时间越短。随着DGA数据集规模的增大,朴素贝叶斯算法加速比性能会越来越好,也说明并行计算方法能够很好地解决大规模数据情况下计算时间过长的问题。在相同的DGA数据规模下,随着集群计算节点规模的增加,加速比的增长速率逐渐减缓,这是由于集群规模的扩大导致计算节点之间通信量增加,减缓了加速比的增长速率。考虑到16 GB大小的DGA数据集相对于集群而言并不是很大,集群性能没有得到全面的体现,图中曲线并没有靠近对角线,这再次说明集群更适合大规模数据集。
3 结论
本文针对传统电力设备故障诊断算法在对海量状态数据进行计算时出现的计算能力不足的问题,研究了MapReduce并行计算框架。利用Hadoop/MapReduce平台给出了朴素贝叶斯算法的并行故障诊断过程,实现了以变压器为例的电力设备快速并行故障诊断。实验表明,当变压器DGA数据集达到一定规模后,Hadoop集群可以对变压器进行快速并行故障诊断,并显示出了较好的加速比性能。
目前,本文只是对电力设备的并行故障诊断做了实验,后期工作将逐步应用到电力设备的故障诊断中,并对现有的诊断方法进行改进,进一步提高故障诊断的速度与精度。
猜你喜欢
小资CHIC!ELEGANCE(2021年36期)2021-10-15
法律方法(2021年4期)2021-03-16
江苏安全生产(2020年7期)2020-09-04
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
当代陕西(2019年9期)2019-05-20
现代工业经济和信息化(2016年22期)2016-08-23
铁道通信信号(2016年6期)2016-06-01
电测与仪表(2016年18期)2016-04-11
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
