
基于遗传算法改进的洪水预报模型
2014-09-26 03:48侯翔刘笃晋彭小利
电子设计工程 2014年2期
侯翔,刘笃晋,彭小利
(四川文理学院 计算机科学系,四川 达州 635000)
洪水是无法避免的,洪水造成损失也是必然的。每次洪灾都给达州市政府和人民带来巨大的经济损失和惨重的人员伤亡,事实证明,如果我们还不采取有效的措施来预防洪水,人民的生命财产将面临巨大的威胁,经济损失也将日益扩大。洪水预报就是其中的一种重要的非工程防洪措施,研究和建立洪水预报模型能够提高防洪减灾的能力,避免洪水造成严重的经济损失和惨重的人员伤亡,具有十分重要的学术意义和现实意义。通过洪水预报模型的研究,能够减免洪灾损失而获得巨大的经济效益和社会效益。
1 研究区域
州河(图1)始于宣汉县江口,经宣汉城南门、西北、东林、洋烈至千丘旁入达县境。由东北向西南,经达县罗江乡红梁村曹家湾进入达县境内,穿过达州市和达县的罗江、河市、渡市3个区的7个乡,于木头乡的大河咀出境,流入渠县的农乐、汇东、汇南等乡,在三汇镇与巴河相汇。州河流域面积8 849 km2,河长108 km。多年平均流量190 m3/s,据历史洪水调查最大流量13 700 m3/s(1902年),多年平均径流总量60.1亿 m3。 河宽一般为 200~300 m[1]。

图1 州河水系图Fig.1 Drainage map of Zhou river
州河流域降水量十分充足,年平均降雨量变化在1 000 mm以上,降水时间比较集中,较大降雨多发生在五月到十月之间。根据查阅相关资料,通过统计2001~2007年州河各月平均降雨量(见表1),流域各月平均降雨不均匀,其中7月份是全年降雨最多的月份,其次就是6月和9月这2个月,州河这7年的平均降雨量为1 050 mm,平均每年80%以上的降雨都集中在5月到9月这5个月。
以州河干流土黄——东林段为研究对象,对东林站流量进行预报。所采用的资料为2001~2007年的水文资料,其中2001~2006年资料用于模型率定,2007年资料用于模型检验。通过分析确定网络的输入,建立用遗传算法改进的BP模型(GA-BP模型)进行预报,并对模型的预报结果进行分析。
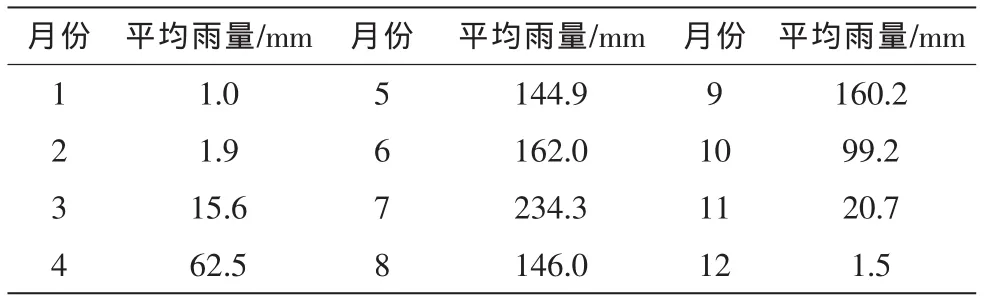
表1 州河各月平均降雨量(2001~2007年)Tab.1 Average rainfall of Zhou river monthly(2001~2007)
2 研究方法
2.1 BP神经网络
BP神经网络是ANN模型中最典型、应用最广泛的一种网络模型,它包含输入层、隐含层和输出层,是一种多层前馈网络。BP网络的学习过程分为2个阶段[2]:信号正向传播是输入信号从输入层输入,经隐含层,最后进入输出层被转化成输出信号;当输出层不能够得到理想的输出时,就会转入误差信号反向传播,将误差信号沿输入信号传播的途径原路返回,并不断调整各层神经元的权值,使网络的输出信号无限逼近于理想输出,网络模型结构如图2所示。

图2 BP神经网络模型结构Fig.2 BP neural network model structure
2.2 遗传算法
遗传算法(Genetic Algorithm)是一种通过模拟适者生存,优胜劣汰的规律,在全局上搜索最优解的算法。它们摆脱了对函数的依赖性,通过对种群个体进行遗传操作,从而实现种群内个体结构重组的迭代过程。在这个过程中,种群个体一代代的得以优化并逐渐接近最佳解。
遗传算法的运行过程按以下步骤完成:1)随机产生初始种群;2)以适应度函数对染色体进行评价;3)选择高适应值的染色体进入下一代;4)通过遗传、变异操作产生新的染色体;5)不断重复 2)-4)步,直到预定的进化代数[4]。
正是因为遗传算法具有全局寻优性、自适应性等特点,搜索不需要依赖于外界信息,自动获取和优化的搜索空间,自适应的调整搜索方向,所以非常适于处理较复杂的问题,随着计算机技术的发展,遗传算法被广泛应用在函数优化、自动控制、机器学习等领域。
2.3 遗传算法优化BP网络
BP网络是一种局部搜索法,如果函数的分布是多峰分布时,通过梯度下降法进行搜索的话,经常会掉入局部极小点。因此,搜索的起始位置十分重要,但是传统的BP网络是随机生成初始权阈值的,因此最终的预报结果也具有随机性,没办法判断是否最优解。而遗传算法恰好是一种用于解决最优化的全局搜索算法,能够同时搜索函数曲线中多个个体,全局搜索能力极强,不容易陷入局部最小点。所以,遗传算法成为了人工神经网络解决搜索问题的一种通用算法。但是,经过大量的实际应用后,人们发现遗传算法也存在着不足之处:容易早熟收敛、陷入局部最优,而且局部搜索的能力较弱等。与BP网络相比,无论从学习精度还是收敛速度上都有所差距。因此,如果完全由遗传算法来训练网络,未必能取得好结果。因此,将遗传算法与BP算法相结合,既能发挥遗传算法的全局搜索能力避免陷入局部最优解,又能通过BP网络的局部搜索能力避免遗传算法的早熟搜收敛,最终提高网络的学习速度和预报精度。
目前,BP网络和遗传算法的结合方式有四种方法,利用遗传算法优化BP网络的拓扑结构、权阈值、同时优化拓扑结构和权阈值、分析训练数据与训练结果。实践证明,不管是否同时进化神经网络的权值与拓扑结构,但就进化网络的结构来说,这就是一件非常困难的事情,这种方法只能解决一些简单的问题,何况对如何选择网络的拓扑结构这个问题,目前不管是理论上还是方法上,都还没找到一种有效的指导原则。因此,本文采用遗传算法优化BP网络的初始权阈值,提出了一种新的算法GA-BP:BP网络的初始权阈值不再随机给出,而是首先由遗传算法通过进化来确定出BP网络的初始权阈值,这样利用遗传算法的全局寻优能力,预先在整个搜索空间内全局性的搜索出一个最佳的范围,然后应用BP网络的局部寻优能力,在这个最佳范围内对网络进行训练直到收敛,这样搜索出的值是全局最小值或近似最小值,避免了陷入局部极小点。GA-BP神经网络算法流程图如图3所示。

图3 GA-BP算法流程图Fig.3 Flow chart of GA-BP algorithm
遗传算法优化BP网络初始权阈值的主要内容有:染色体的表达、适应度函数的定义、进化运算、交叉运算、变异运算等[5]。
1)染色体的表达
遗传算法在搜索前就必须将问题的解编码成字符串才能使用,大多数问题都能够通过采用染色体形式来表达。遗传算法中初始群体的个体是随机产生的,故某一变量分布范围内产生的初始种群为P={X1,X2,…XN},对于任何的一种神经网络来说,Xi∈P(i=1,2,…L)是神经网络所有权阈值组成的实数编码染色体。
2)适应度函数
在GA-BP算法中,遗传算法的目标是让网络中表示实验误差大小的偏差平方和尽可能的小,进化的方向是为了增大适应度函数值。因此能够计算出BP网络的误差平方和,而适应度函数采用误差平方和的倒数。

3)进化运算
进化运算是种群逐代更新的过程,通过选择算子具体执行。使用排序选择法来选择,适应值越高的染色体被选中的概率越大,反之,适应值越低的染色体被选中的概率越小。
4)交叉运算
实数编码很难使用单点交叉或者多点交叉这些方法来进行交叉,所以需要解空间里直接进行运算,因此,设计了一种经过改进的算术交叉算子。该算术交叉算子对于有这样的一个性质:解空间D里任何2个点x1、x2的经过线性运算后产生的值,同样还是解空间D中的一个点。算术交叉的过程是:将种群中任意2个染色体、Xt选为双亲,用Xti、Xt来产生子代个体,从而代替父代个体。
5)变异操作
变异的作用是按照一定概率随机的选择改变染色体的基因值。由于采用实数编码染色体,故变异运算使用了非一致变异算子 d(Xi)。 d(Xi)函数的优点为:进化初期 Xi的变化范围较大,说明搜索范围较大;随着进化不断的进行,Xi的变化范围缩小了,于是将搜索范围限定到一个很小的空间,能够提高BP网络的搜索速度,增加预报精度。
2.4 模型评估指标
采用《水文情报预报规范》(SL250-2000)中的规定的合格率和确定性系数作为模型评估指标。一次洪水预报的误差小于许可误差即为合格预报。合格率QR表示经过多次预报后总的精度水平,确定性系数DC表示洪水预报过程与实测过程之间的拟合程度。公式为:

式中:m是预报总次数;n是合格预报次数。y0(i)为实测值;yc(i)预报值;为实测值的平均值。
3 计算结果
3.1 输入因子分析及模型训练
本研究对象是洪水,具有非线性关系的特征,因此参考以往模型应用经验,采用单隐层BP网络,传递函数采用Sigmoid函数,学习方法采用Levenberg-Marquardt法。确定将土黄、毛坝、黄金三站的流量3个因子作为模型输入,东林站流量为模型输出,通过反复测试对比,确定最合适的隐含层节点数为5,即网络拓扑结构为3-5-1。遗传算法在运行过程中的重要参数:种群规模为200,迭代次数为2 000,选择概率为 0.1,交叉概率为 0.3,变异概率为 0.1;BP网络学习步长为0.01,目标误差为10-4,训练次数为104次。
将传统BP网络随机产生的初始权阈值和经过遗传算法优化后的权阈值的最大值和最小值汇总于表3中。
如表2所示,经过遗传算法优化后的网络权阈值与随机产生的权阈值相比,它的取值范围要大很多,这样有利于更大范围内寻找模型的最优权阈值,避免陷入局部极小值。用遗传算法优化模型的权阈值后,再进一步训练模型,使模型最终收敛于最优解。

表2 权阈值取值范围一览表Tab.2 Range table of weight and threshold values
3.2 洪水预报结果
用GA-BP算法训练好的模型对测试样本进行预报,预报流量和实测流量对比见图4。预报结果显示合格率QR=93.75%,确定性系数DC=0.974,达到了《水文情报预报规范》(SL250-2000)规定的精度评定标准甲级。

图4 预报流量和实测流量对比图Fig.4 Comparison chart of predictable flow and measured flow
4 结 论
将遗传算法和BP网络结合在一起,建立了GA-BP洪水预报模型,并以州河干流土黄——东林段为研究区域,对东林站的洪水流量进行了预报,取得了令人满意的预报精度。从预报结果来看,以基本水文资料为输入,使用遗传算法优化BP网络的初始权阈值,改进洪水预报模型是可行的,有利于神经网络模型在州河洪水预报中的应用。
在应用改进BP网络进行洪水预报时,训练样本数据选取既要保证多样性,同时也要注意数据的代表性和不均匀性。另外,由于近年来人类活动对环境影响巨大,用历史资料训练的模型对当前洪水进行预报是否可行,还要用近年资料对模型验证或重新训练后才可被用于实际预报。
[1]百度百科.渠江[EB/OL].(2012-09).http://baike.baidu.com/view/746730.htm.
[2]中华人民共和国水利部.SL250-2000水文情报预报规范[S].北京:中国水利水电出版社,2000.
[3]范睿.基于遗传算法的神经网络洪水预报研究与应用[D].哈尔滨:哈尔滨工程大学,2005.
[4]闵祥宇.基于人工神经网络的渭河上游洪水预报研究[D].兰州:兰州大学,2011.
[5]甄祯.基于改进人工神经网络的水文要素评价与预报[D].昆明:昆明理工大学,2011.
[6]苗孝芳.水文学原理[M].北京:中国水利水电出版社,2004.
猜你喜欢
娃娃乐园·综合智能(2019年6期)2019-07-10
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
天津诗人(2017年2期)2017-11-29
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
少儿科学周刊·儿童版(2015年7期)2015-11-24
