
中药方剂药物属性的组网模型
2014-09-13 13:03李茹孙正王崇骏谢俊元
智能系统学报 2014年2期
李茹,孙正,王崇骏,谢俊元
(1.南京大学 计算机科学与技术系,江苏 南京210046; 2.南京大学 计算机软件新技术国家重点实验室,江苏 南京 210046)
中医是中华民族千百年流传下来的精髓,而且越来越得到全球医学界的认可。由于古人对中医记载的重大贡献使得中医体系保存得比较完整。现存的有关文献中,经专家统计,方剂数量大约100 000种。而正是这些相对完整的医药体系以及大量的方剂数据为探索中药方剂的配伍规律提供了很重要的依据,使中医药的发展更加科技化、体系化。
在中医药研究方面,已经有很多专家系统存在,而这些系统大都是针对方剂和药物进行表层的分析。为了发掘出大量数据中包含的隐藏、有价值的信息,可以引用数据挖掘技术。数据挖掘可以对数据进行多方面分析,包括:核心药物的发现,中药方剂的配伍规律,药物之间的关联分析等。可是这种简单的分析不利于对药物配伍规律深层次的认识。最近研究表明,中药药物之间的互相联系可以用网络来描述,在药物上建立复杂网络模型,可以更加直观地展示药物间的联系。而传统中药方剂的复杂网络模型的构建只是关注药物间的联系而不考虑药物自身属性,这样就会忽略一些药物之间潜在的关联。本文的主要思想是在复杂网络模型的基础上,加入药物本身的属性,结合药物的属性和药物间的联系构建一个新的组网模型,让药物属性信息作为社团划分的依据。这样不仅能够得到药物之间的联系,而且还能得出药物属性之间的一些隐藏的信息,更能深入了解药物之间内在的链接关系。
在对中医药方剂数据组网进行数据挖掘方面,国内外已有大量学者进行了相关的研究[1-3],如周学忠等通过完全图的方式对中药方剂数据进行组网,发现网络的节点度分布特性符合幂律分布,从而将其划分到无尺度网络;李稍等[4]从网络药理学、系统生物学角度提出了“网络靶标”的概念,并将方药、病症映射于生物分子网络,以网络为基础建立方药与病证的关联机制;孙道平等[5]基于贡献度和同方率构建传统中药方剂(traditional Chinese medicine formula,TCMF)网络,提出了高重叠的社区发现算法,划分了药物社区结构。而在复杂网络[6]的研究中,更是涉及到诸多领域,如细胞网络、蛋白质作用网络、神经网络、社会网络[7-10]等。复杂网络具有一些重要的统计特征,如Watts和Strogatz[11]在Nature杂志提出的小世界网络模型,体现了“小世界”特征;Barabasi 和Albert[12]提出著名的BA模型,提出“无标度”网络这个概念;Newman[7]提出了复杂网络的社团结构的概念。其中,也有很多学者提出了很多基于复杂网络的经典重叠性聚类算法,如Palla等[13]提出了最大团过滤理论,并提出了能够识别重叠网络簇结构的CPM(clique percolation method)算法;B.Yang等[14]提出基于马尔可夫随机游走模型的FEC(finding and extracting communities)聚类算法.
1 数据处理
在数据挖掘中,数据处理对后续的数据挖掘工作很重要。中医药的原始数据存在一些问题,由于方剂通过不同文献的记载,而且历经历史的变迁,很多药方中药物的名字发生了各种变化,这样就出现了药物同异名、药名重名、药效术语不规范问题,同时药方中存在一些空缺值和错误记录。因此,为了更好地发现中医药的配伍规律,数据处理是不可缺少的重要环节之一。
1.1 药物同异名处理
医药同异名是一个很严重的问题,经过对医药数据的分析,可以将药物名分为以下几种情况:
1)一名独正:一个正名不存在任何异名;2)一名多异:一个正名有一个或者多个异名;3)一正一异:一个异名只属于一个正名;4)多正同异:一个异名属于多个正名。
为了解决上述所有问题,本文针对一名独正不做处理,对于一名多异和一正一异统一用正名来代替,对于多正多异这种情况,采用上下文(功能、主治等)判断识别本体再进行正名替换。
1.2 药物术语处理
中医药方剂中还存在另一个问题是功能术语的规范问题。在中医药的一些文献中,中药的功效存在很多歧义,而且针对同种功效具有多种不同的表述。如“祛风除湿”、“祛风湿”、“祛风散寒”等功效表达意义都是相同的。由于传统文化的影响,为保证工整优美,在方剂存储中,功效大多都是“四字为文”的形式。因功效术语存在一些复杂性,所以几乎没有文献提供一种统一的方法去规范用语。本文的主要思想是首先将原始功能字段分别以2字、3字和4字集合进行排序。之后对4字形式的功能术语进行拆分,将其分为2字形式,如将“清热解毒”拆为“清热”和“解毒”。如若有不符合这个形式的拆为,可以将4字形式转换成3字形式,如“补益元气”改成“补元气”。
将4字形式拆分后,接下来是合并意思相同的功效术语。本文采用的根据混合相似度的方法来进行合并。混合相似度的定义为
SimUnion(A,B)=(SimContext(A,B)+
SimLiterally(A,B))/2
(1)
式中:SimContext(A,B)表示上下文相似度,定义为
SimContext(A,B)=
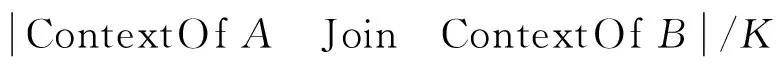
ContextOfA表示A的前K个同现术语组成的集合,ContextOfB表示B的前K个同现术语组成的集合,SimLiterally(A,B)表示字面相似度,定义为
经实验发现,5个同现术语中如果3个相同并且字面一半相似,就可以说明问题。因此,可以设置SimUnion(A,B)阈值为0.55,如果2个术语的混合相似度超过该阈值就认为这2个术语可以合并。
2 药物属性的定义
2.1 药物属性基本内容
药物属性(药性),即所谓的药物属性中药与治疗有关的性能,概括为四气五味、归经 、升降沉浮、毒性[15]等。本文中主要选择药物表中“性味”、“归经”、“功效”3个方面作为药物属性定义的基础。其中“性味”包含了四气五味、毒性等描述,而“功效”上体现了“升降沉浮”等。
2.2 药物属性向量
药物属性向量的具体构建方法是:假定每个字段有N个离散取值,将其定义成N维的属性向量,每维取值0或1(0代表没有出现该取值,1代表出现该取值)。据此方法,可以得到“性味”、“归经”、“功效”3个方面的属性向量如表1~3所示。

表1 性味向量

表2 归经向量

表3 功效向量
3 组建中药方剂属性网络模型
本文的目的是在传统中医药基于结构相似性或属性相似性进行聚类的研究基础上进行改进,将结构相似性和属性相似性结合起来,将属性作为节点添加到组网中,通过药物属性可以使药物建立更多的连接,从而发现隐藏的药物之间的联系。
3.1 组建中药方剂(TCMF)网络
在组建TCMF网络之前,需要一些准备工作。通过计算药物之间的关联度定义一个阈值,关联度比该阈值高,则组网中有边连接,反之则认为无连接。
3.1.1 基于药物依赖度的关联度
常用的组网方式有很多,如完全图[1]、基于频次[5]、基于Jaccard相似度[16]、基于熵[17]、基于互信息[18]等。而在中药方剂数据组网应用场景下,上述相似度量方法存在不均衡情况下的单向依赖关系和对组方长度不敏感等不足,为了解决这些问题,本文提出了药物依赖度的关联度。
定义药物X对Y的依赖度为
Ind(Y|X)=
(∑i1/(Formula(X,Y)i.length-1))/|X|
(2)
式中:Formula(X,Y)表示X和Y的共同组方集合,Formula(X,Y)i.length表示组方集合中第i个方剂的长度,减一是为了消除自身对方剂长度影响。药物关联度的公式为
sim(X,Y)=max{Ind(X|Y),Ind(Y|X)}=
(3)
为了解决X和Y频次不均衡的问题,取X、Y相互依赖度中的最大值,同时还考虑了方剂长度的影响。
但是,通过式(2)和式(3)不难发现:直接取药对依赖度中的最大值是有问题的,如果分母本身过小,也会导致结果很高。所以为了解决这个问题,本文对药物关联度做了改进:
最终的关联度定义为一个分段函数,当X、Y最小频次小于某个阈值时,取依赖度中的较小者;当X、Y最小频次大于阈值时,取依赖度中的较大者,这样就避免了频次过低导致依赖度过高的错误。
3.1.2 组网算法
本文的组网算法的思想是:遍历所有的方剂,计算当前方剂对药物关联度的增益,并将其加到原关联度上。最后,查询所有关联度大的药对进行组网。
组网算法如下:TCMFCreat (DrugSet,FormulaSet,k,x)
Input:药物集合 DrugSet,方剂集合 FormulaSet,频次阈值k,关联度阈值x;
Output:所要构建网络中的边 EdgeSet;
Description:遍历方剂集合,每一个方剂根据定义的药物关联度计算对相关药对的关联度的增益;
方剂集合遍历完之后,再遍历所有药对,根据输入阈值判断药物间是否有边:
1)For each drug1,drug2 in DrugSet
2)If drug1≠drug2
3)Sim(drug1,drug2) =0
4)For each formula in FormulaSet do
5)If formula.length>1
6)For each drugi,drugj in formula do
7)If drugi≠drugj
8)If min(count(drugi),count(drugj)) 9)Sim(drugi, drugj) = Sim(drugi, drugj)+1/ formula.length*max(count(drugi),count(drugj)) 10)Else 11)Sim(drugi, drugj) = Sim(drugi, drugj)+1/ formula.length*min(count(drugi),count(drugj)) 12)For each drug1,drug2 in DrugSet do 13)If drug1≠drug2 14)If Sim(drug1,drug2)>x 15)EdgeSet.add(drug1,drug2) 16)Return EdgeSet 其中,count(drugi)为计算第i个药物的频次,即它在所有方剂当中出现的次数。在肺痿方剂数据上运行组网算法,通过对网络的性质进行统计,发现网络节点的度分布是符合幂律分布的[2],因此可以将TCMF网络加入到复杂网络的范畴,这样就可以运用复杂网络的分析方法。 通过对网络的性质统计,发现网络节点的度分布是符合幂律分布的[2],因此可以将TCMF网络加入到复杂网络的范畴,这样就可以运用复杂网络的分析方法。 在中医药组成的TCMF网络中,试图权衡结构和属性相似度得到结果。也就是说经常在一起的药物划分在同一社团,并且它们的药性也大致相似。为了达到这个目的,本文提出一种将结构和属性一体化度量的方法,即“属性扩展图”的做法。具体思想是:将节点的每个属性的离散取值作为一个“虚拟”节点,加到原网络中,称为“属性节点”,然后在新网络上利用节点间度量的方式进行聚类。 关于“属性扩展图”的形式化定义: 为了分析基于药物属性的中药方剂组网模型的可行性和有效性,本文在肺痿方剂数据库中的 211 味方剂上进行了试验,并和传统的组网方式进行了对比。试验环境如下:处理器 Intel(R) Pentium(R) G 640 2.8GHz,内存2 GB,硬盘500 GB,操作系统Windows7 32位版,编程语言为Java6.0。 K-clique派系过滤算法(CPM)[13]是由Palla提出的第1个发现重叠社区的算法。它的简要思想是将相邻的K-clique进行合并,有些节点会属于多个K-clique,因此构成了网络中的社区重叠部分。主要实现步骤是,给定一个K值,计算出网络中所有的K-团,建立团-团之间的重叠矩阵,然后通过重叠矩阵来得到重叠的网络簇结构。在本实验中,设置K=4。 本文实验所采用的数据集为肺痿方剂数据库中的 211 味方剂,从中提取了 125 种药物、13 种性味、12 种归经、90 种功效。属性扩展图上有(125+13+12+90)240 个节点, 254 条两两药物组成的“结构边”、 339条“性味边”、493 条“归经边”、679 条“功效边”。 实验结果获得药物社团如表4~5所示。 表4 肺痿药物(未添加属性)社团 表5 肺痿药物(添加属性)社团 在未添加属性的组网中社团划分个数为4个,如表4所示。在添加属性之后,同样根据CPM(K=4)算法,发掘出来的社团数目为19个,在表5中,列出了具有代表性的5个数据。 将表4和表5中的社团进行比较,可以发现: 1)最明显的一点是:添加上属性之后,可以明显的看到一个药物群属于哪些“性味”,“归经”和“功效”,这样更方便获得药物的属性信息。 2)在未添加属性的组网中,通过PCM算法仅仅获得4个社团,而在添加属性之后,获得了19个社团。实验结果表明添加属性这种组网方式是可行的。 3)对表4和表5中社团进行比较发现,表5中的第4、5社团在表4中是不存在的。从此可以说明,通过添加属性可以使药物之间在原基础上增加更多的关联。这也是采用这种组网方式的目的。 结果分析表明将药物的属性添加到网络中进行组网的模型是可行的,并且比传统的组网方式更有效。 由于现实中处理的数据很多是不完备的且存在偏序性,因此研究处理这种复杂数据情况的粗糙集方法是很有实际意义的。本文通过对现有优势关系的分析后提出了α优势关系及其相应的粗糙集模型,以使得对不完备序信息系统的数据分析更加合理。此外,在基于α优势关系的粗糙集模型上,给出了不完备序信息系统的优势区分矩阵以及不完备序决策系统的优势决策区分矩阵,从而实现了属性约简,同时也表明了区分矩阵只能运用属性集的幂集进行构造,而不能运用单个属性集进行构造。 需要指出的是,在α优势关系的基础上,还可以进一步研究不协调不完备序决策系统的属性约简算法,这是本文的下一步工作任务。 参考文献: [1]周雪忠,刘保延,王映辉,等.复方剂药物配伍的复杂网络方法研究[J].中国中医药信息杂志, 2008, 15(11): 98-100. [2]FALOUTSOS M, FALOUTSOS P, FALOUTSOS C. On power-law relationships of the internet topology[C]//ACM SIGCOMM Computer Communication Review. ACM, 1999, 29(4): 251 -262. [4]李稍.网络靶标中药方剂网络药理学研究的一个切入点[J].中国中药杂志,2011, 15(36): 2017-2020. LI Shao. Network target: a starting point for traditional Chinese medicine network pharmacology[J]. China Journal of Chinese Materia Medica, 2011, 15(36): 2017-2020. [5]孙道平. 复杂网络方剂配伍研究[M]. 南京:南京大学出版社, 2012: 1-5. [6]STROGATZ S H. Exploring complex networks[J]. Nature, 2001, 410(6825): 268-276. [7]GIRVAN M, NEWMAN M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences, 2002, 99(12): 7821-7826 [8]STROGATZ S H. Exploring complex networks[J]. Nature, 2001, 410(6825): 268-276. [9]PALLA G, DERÉNYI I, FARKAS I, et al. Uncovering the overlapping community structure of complex networks in nature and society[J]. Nature, 2005, 435(7043): 814-818. [10]WILKINSON D M, HUBERMAN B A. A method for finding communities of related genes[J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101(Suppl 1): 5241-5248. [11]WATTS D J. Six degrees: the science of a connected age[M]. Cambridge: Cambridge Univ Press, 2004:32-36. [13]PALLA G,DERENI I, FARKAS I,et al. Uncovering the overlapping community structure of complex networks in nature and society[J]. Nature, 2005, 435: 814-818. [14]YANG Bo, CHEUNG W K, LIU Jiming. Community mining from signed social networks[J]. IEEE Trans on Knowledge and Data Engineering, 2007, 19(10): 1333-1348. [15]胡爱萍. 关于中药药性理论现代化研究的思考[J]. 光明中医, 2006, 21(10): 20-22. [16]刘正. 基于MapReduce的中药数据网络化及挖掘[D]. 南京:南京大学, 2012: 16-22. [17]唐仕欢, 陈建新, 杨洪军, 等. 基于复杂系统熵聚类方法的中药新药处方发现研究思路六[J]. 世界科学技术, 中医药现代化, 2009, 11(2): 225-228. Tang Shihuan, Chen Jianxin, Yang Hongjun, et al. Designing new tcm prescriptions based on complex system entropy cluster[J]. World Science and Technology(Modernization of Traditional Chinese Medicine and Materia Medica, 2009, 11(2): 225-228. [18]PENG H, LONG F, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238.3.2 属性扩展图的构建
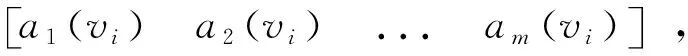

4 实验
4.1 实验设置
4.2 CPM算法
4.3 实验数据
5 结果分析


6 结束语
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
世界科学技术-中医药现代化(2021年8期)2021-12-21
中国民间疗法(2020年22期)2021-01-07
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中成药(2018年9期)2018-10-09
中成药(2018年6期)2018-07-11
中成药(2018年1期)2018-02-02
军事文摘(2017年16期)2018-01-19
学苑创造·A版(2017年1期)2017-01-19
