
大型术语部件库建设的实践与思考
2014-09-08 06:49杨福义
中国科技术语 2014年4期
杨福义
(鞍山师范学院,辽宁鞍山 114006)
大型术语部件库建设的实践与思考
杨福义
(鞍山师范学院,辽宁鞍山 114006)
在大规模术语部件库的建设中,获得了10万条术语部件,对建设中使用的技术予以介绍。进行了术语部件库的统计分析,总结了术语部件库的建设经验与问题,提出了进一步解决的方法。
术语部件,统计语言学,术语经济律
术语部件库是一个包含丰富信息的知识库,这些丰富信息有助于新术语的自动发现、术语的自动定义、术语概念体系的建立等相关研究工作[1]。目前,较大型的术语部件库很少,现有的术语部件库也缺少相应的术语部件构成统计分析。为了进一步开展科技文献和论文的自动标引与自动分类工作,以及发现新的科技术语,迫切需要建设一个具有专业领域特异性的术语部件库。
一 术语部件库建设的前期准备
为了更好地进行文本的科学自动分类与自动标引,必须有一个来源可靠、分类科学的分词词典,以及方便合理的分词工具。术语部件对于建立按学科自动分类与自动标引工作具有重要的作用,是当今时代中文信息处理的迫切需要,也是为数以千万读者快速方便进行科学文献智能检索而提供的重要工具。
术语具有鲜明的学科领域性特点,是按学科分类的重要工具,大部分术语由术语部件所组成。术语部件中含有重要的语义信息,可以用于科技文献的自动摘要、关键理论与信息的自动抽取和分析。国家有关部门对术语数据库的建设制定了一系列标准与规范,《术语部件库的信息描述规范》(以下简称“描述规范”)[1]就是其中一项重要的参考资料。
1.术语部件库的数据来源
术语部件库的建设离不开术语数据库。术语部件库需要对术语数据库中的术语进行解析,将多词术语按条目进行切分与标注,在此基础上进行术语部件的提取。所以对术语数据库的要求是权威性、规模性与领域特异性。
术语数据库选用了全国科学技术名词审定委员会(以下简称“全国科技名词委”)网站发布的术语数据电子文本以及中国知网获得授权后发布的规范术语,以保证术语部件的来源权威性。数据库的电子文本通过多年的复制、拷贝、粘贴以及去除因客观因素导致的有问题的术语,获得了基本可靠的原始术语数据。
2.术语的净化与预处理
已经出版的术语词典和发布的术语文件是众多专家多年的心血结晶,但术语库的建设是一项持续恒久的工作,过程中总会有瑕疵,有些问题也存在观点分歧。下面就术语数据库净化与预处理的几个问题予以说明。
(1)术语中的字母词
关于术语中的数字与字母词问题,已有多篇文章对其讨论。在部件库的建设中,对数字字母词做如下处理:对术语中的全角和半角混用词,在不改变原有词义的情况下,采用全角化处理,以保证分词的准确性。
(2)术语中的标点符号词
针对术语中的标点符号,《信息处理用现代汉语分词规范》[2]第一项指出:空格或标点符号是计算机中的分词单位标记,如果将带有标点符号的词按标点符号切分,将违背术语部件与术语相关关系的含义。因此,在术语部件库建设中,对含有标点符号的术语词,要根据具体情况予以处理。
术语中的标点符号问题处理起来更加困难。例如“(0,2)插值[数学](0,2) interpolation”“1K-(2-吡啶基偶氮)-2-萘酚[化学]1-(2-pyridylazo)-2-naphthol, PAN”,绝大多数分词软件都无法把标点符号连接的词汇进行准确分词。术语中的标点符号还有中文标点符号和英文标点符号,也需要根据具体情况做出相应处理。
(3)术语中的特殊字母词
将术语统一转化为全角汉字符号。使用UTF-8编码,可以处理包括中韩日全部象形文字的数据,但对于希腊字母,却只有双字节的内码数据,因此对于含有希腊字母的术语,分词时也要特殊处理,转化为ANSI码处理。
此外,保留术语中的标点符号,不进行分词。对全半角混用情况,一律改为全角字符。删除术语条目中出现的空格。将中文标点符号中的半角连接号改为全角的连接号。全部英文字母与标点均采用全角中文字母表示。
二 术语部件库建设中的分词
如前所述,中文分词已有国家标准,但目前为止,标有词性的专门分词词典还没有公开出版。其中最大的难点是词与字的定义,绝大多数汉字具有词义,可以说几乎一字一词,分成单个汉字显然脱离中文分词作用的初始意愿,分词原则以中文信息处理为目的。规范中明确指出了其他领域参考、补充与细化问题。《信息处理用现代汉语分词规范》[3]中有“一律切分”“不予切分”“应予切分”“按习惯形式切分”等多种规定。没有完整的词表,这些切分原则会有不同解释。在描述规范中,结合紧密、生成能力强、使用稳定的语言片段也可以看作是术语部件。其度量标准问题也不好界定。
因此,分词的准确界定,依然有许多问题需要讨论,山西大学刘开瑛在《中文文本自动分词和标注》一书中指出分词规范的一些问题[3],例如:“每年”一词是否切分,推荐规范与《现代汉语词典》相矛盾问题等。
1.本次术语部件库建设过程的分词标准
(1)遵循国家标准分词规范,以双字词为核心的原则
本文涉及的术语部件库的建设采用词组型分词,把多词术语的分词分到最小词组长度后,不再切分,即使他们是单字术语组成的双字词组,也不再切分。例如:基是单字术语词,体是单字术语词,基体是合成术语新词,在化学、细胞生物学、植物学、航天科技、冶金学、人体组织学等多学科中使用,且具有不同的英文译文和含义。对于这类双字词不再切分,即术语部件库的部件最小字长为2,也就是双字词。双字术语部件词加前缀或后缀可形成新的术语部件,分词后的术语构成一个二叉树,可与其他术语部件构成树图,进一步分析术语的结构与类型。
(2)以多词术语部件构成原则为依据
采用以单字词术语和双字词术语为种子术语,参与新术语部件的发现与扩充建设的原则。
由1个字或2个字组成的规范术语词,加其他汉字则构成新生术语。所加部分一定是术语部件,可以是字,也可以是词。因此,每个多词术语的生成均可以切分为单字术语+单字术语、单字术语+构成术语单字等几种模式。
在分词原则中,2字词或3字词,以及结合紧密、使用稳定的2字或3字词组一律为分词单位。按此原则,2字词与3字词作为分词的基本单位,参与多词术语中部件的度量与计算。在涉及分词歧义的情况下,适当收入4字以上的部件词。中外人名与机构名不受字数限制。
2.本文涉及的几个概念的定义
(1)分词粒度:在冯志伟《现代术语学引论》中,被称为术语长度[4]。一个术语部件词为一粒,称作粒度为1。一个术语部件所含有汉字的个数,称为粒长。例如:“汉字信息处理”的部件数是3,则称为术语部件粒数为3,每粒的粒长均为2。可以说,“汉字信息处理”有三个术语部件词。
(2)术语部件粒长:术语部件按规定原则不再切分时,单个术语部件的汉字的字数称为粒长(不称为字长是因为与计算机科学技术专业中的字长概念相区别)。
(3)缀:以术语中助词为主要成分的单字词。参与术语组词的称为缀,分为前缀、中缀、后缀三种。缀为术语部件中的基本部分,可多次加词构成新部件。这些部件不再切分,以避免失去专业属性,影响特定领域术语部件的分析与应用。这类部件可成为核心部件词的扩充部件,加前缀或者后缀组成新部件。此类部件大部分粒长为3。分词过程产生的中缀,可以合并到前面或后面,构成新的术语部件。
(4)术语部件黏度:术语部件构成新术语词的能力。构词越多黏度越大,对构词数目取对数,取频次的常用对数作为术语黏度的定义。可以定量分析术语部件的生成能力。频次1000条的术语黏度为3,100条的为2,10条的为1。频次只有1条的黏度为0,只在一个术语条目中出现。
这样,就明确定义了术语部件生成术语能力的级别,常用术语部件黏度大于或等于1.0,少用术语部件黏度小于1.0并且大于0,罕用术语部件黏度等于0。将术语部件的生成能力予以定量描述,也对应组成能力十条以上(常用),几条(少用),一条(罕用)的概念。
按此标准,可以分组计量从而发现术语部件分布的客观规律与分布的数学模型。
3.分词词典的建设理据与过程
根据多词术语的定义,多词术语可完全正确切分,如拆出一个部件词,其余仍是多词词组或单个部件词。根据冯志伟介绍的术语生成机制[4],取双字术语词作为新术语部件发现的种子术语,参与分词与新词发现。
4.术语部件库的形成过程
以20 000条双字词术语为种子词开始建设,对约243 000词条的术语数据库按专业进行切分,分词程序包含着新术语部件产生发现模块,每分词一次就生成新词备审文件,审查后补充进入分词词典,再次分词。
使用扩充新部件词后的分词词典再次进行分词,会再次出现新部件,如此循环,直至不再出现术语新部件为止。
接着,对不再具有新词生成的术语库进行单字分析,分别通过前缀、中缀、后缀的处理,组成一些以基本核心部件词为主的扩充部件,例如“非+线性”构成“非线性”。如此反复运算,最终获得10万词汇的术语部件,构成科技术语部件总库。而且对于每个专业,分别单独建立部件词表。以获得具有专业领域属性的术语部件频次数据。用于科技文献的自动标引与自动分类研究。
一般术语数据库,需要按以上分词过程进行5~6次。
笔者编写了术语库分词与新部件发现程序软件,分词软件采用正向最大分词方法,从12字进行切分,递归处理。在种子术语部件库的基础上,对字数大于3的术语进行分词。
术语分词后,如果有连续的单字,则合并为预选新词,经人工甄别后入库。对散落的单字,除语法词外,进行与上下部件归并的粘连操作。
三 分词结果与术语部件库的信息描述
对243 000条的术语数据库进行按专业分词,建立了术语部件库。分词产生103 000条术语部件。按频次黏度定义结果如下:
常用术语部件(黏度>1.0) 6646个 占 6.41%
少用术语部件 (1.0>黏度>0) 33675个 占32.48%
罕用术语部件 (黏度为0) 63349个 占 61.10%
由以上数据可以看到,术语频次曲线的长尾现象,即有大量的部件词只使用一次。各专业罕用词均在60%~80%之间,常用词约占1%~6%。罕用术语部件约占70%,覆盖30%的词次,一般与常用部件约占30%,覆盖70%的词次,即总词次的70%。这个规律也可以称为部件频度分布的三七规则。
罕用部件词量大,而且专业领域特异性明显,对文件详细分类的精确度有重要作用。常用部件使用频度高,对于发现术语新词和文本分类较大类别的划分具有重要意义。
获取各专业、各领域的术语部件词表后,需要各方面进行标注。主要的标注工作如下:
词的语法属性:按国家标准标注语法词性,在无法确定的情况下,使用计算机辅助词性标注加人工校对的方法。
词的专业属性:研究专业分布频次与向量分布。
词的部首属性:研究术语部件字部首与术语部件词的相关性。
词的黏度(术语构成能力)属性:研究术语部件词构成术语的能力与模式。
四 术语部件库的统计分析
1.分析术语部件库经济指数
按术语经济指数定义与冯志伟介绍的术语于形成的经济律计算方法[4],对58个专业术语部件库进行经济指数计算,表1是部分专业的数据计算结果。

表1 部分专业的术语经济指数
2.分析术语部件词频分布规律
根据术语部件词表在术语库的使用频度,可以研究术语部件构成规律。采用五种数学曲线按专业对数据进行计算[5]。计算表明以幂函数拟合效果最好。这里根据齐夫定律(Zipf ’s law),将部件按频度排序。词频与序号的关系是离散的,近似用非线性回归转化为线性回归的方法予以计算。
使用美国语言学家朱斯(M.Joos)对Zipf公式提出修正的双参数词频定律[6]:
Y=AX-B
其中,Y代表频次,X代表单词排序号,B代表指数,A代表系数。
对各个专业分别进行回归计算。对等式两边取对数后化为直线方程进行最小二乘法拟合,对计算结果进行比较分析,部分专业术语部件词频规律方程如表2:
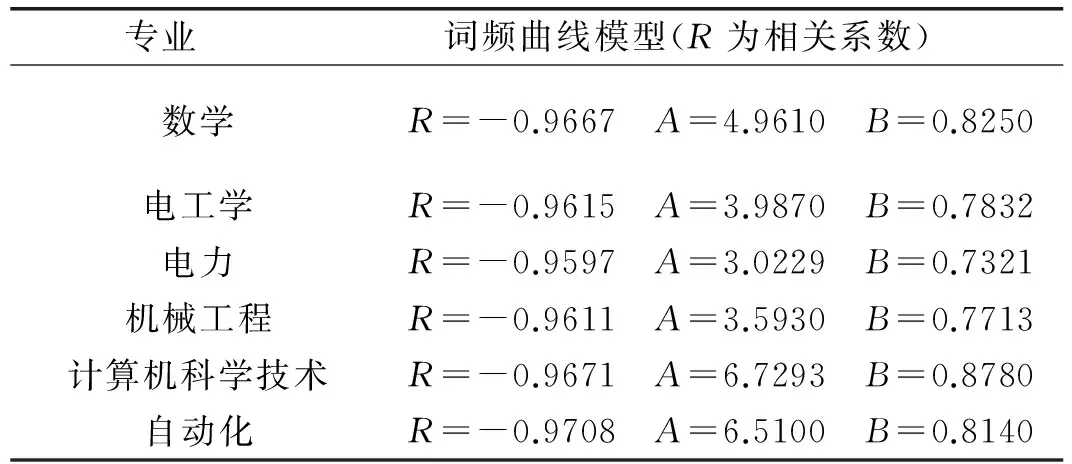
表2 部分专业术语部件库频次曲线数学模型
3.术语部件库之间的相关系数
哪些专业术语部件库之间具有相同的部件较多?可以采用术语部件词构成的方向向量来计量。这是科技文献聚类分析的重要参考数据。使用向量距离的度量方法[7],应用余弦定理对术语部件词表的向量距离进行计算,结果见表4。按词表建立向量,计算不同专业之间的距离(相关系数)。夹角角度为0度,余弦值为1,距离为零,数据越小,距离越大。表3可以看出电力专业与电工学专业,计算机科学技术与自动化专业具有较高的相关系数,共用了较多的术语部件。

表3 专业相互之间术语部件的相关系数(余弦距离)
4.进行科技文献自动标引与自动分类
以术语部件库的术语条目作为主题词与关键词,是把文献中涉及专业属性最敏感部分进行提炼。实践表明,应用术语部件库可以进行自动标引,并有利于计算机辅助信息检索,为用户提供相关词族群的检索词汇,也可以为科技术语审定提供参考。
由于部件是从术语数据库中提炼出的精化部分,可以对文件中的术语在各专业的向量分布进行概率统计分析。从而为解决相关学科的检索和新的术语分类提供参考依据。
例如,通过文献的生物学词频概率和电子学的词频概率,发现涉及生物电子学的新词。
5.构建由术语部件表达知识与概念的语义网
概念是人类知识的基本单元。通常一个概念对应一个自然语言的单词或词组,对术语部件库的进一步深入研究,可以考虑构建以部件词为核心的科技术语词网,以及术语工程专家系统。建立适合在网络环境下应用的术语知识组织系统,运用知识本体的理论和方法研究术语,并进一步理解知识的内涵与相互关系,为科技术语知识的学习提供便利工具,为术语概念体系的建立提供依据和参考。
五 结 语
术语部件库的建设是术语工作的重要组成。无论采用何种方法与何种工具,最终形成的部件库将殊途同归。笔者初步建成含有10万条词汇的术语部件库,这项工程还远未结束,还有大量的属性标定与词汇审校工作。部件库也需要专家学者的进一步审定,建成的部件库词表审定后可以资源共享,供更多的科技人员研究术语时作为参考,或可避免低水平的重复劳动。
术语部件是对浩瀚术语数据的凝缩与集中,做好术语部件库的建设具有重要意义。仅以笔者的数年实践抛砖引玉,期望术语部件库的研究、数据挖掘能得到更多同仁的重视,为中国术语的规范推广与应用做出贡献。
[1] GB/T 19102—2003 术语部件库的信息描述规范[S].北京:中国标准出版社,2003.
[2] GB/T 13715—1992 信息处理用现代汉语分词规范[S].北京:中国标准出版社,1992.
[3] 刘开瑛.中文文本自动分词和标注[M].北京:商务印书馆,2000:30-33.
[4] 冯志伟.现代术语学引论(增订本)[M].北京:商务印书馆,2011.
[5] 陈魁.应用概率统计[M].北京:清华大学出版社,2000:255-260.
[6] 冯志伟,胡凤国. 数理语言学[M].北京:商务印书馆,2012:269.
[7] 吴军.数学之美[M].北京:人民邮电出版社,2012:127-135.
Practice and Thoughts on Building a Large Term Component Database
YANG Fuyi
Based on 100 000 term components obtained during the construction of large-scale term component database, we introduced the construction techniques. We also made statistics on the term components of database, sum up construction experience and problems for the database construction, and put forward suggestions for further work.
term component, statistical linguistics, word term economic law
2014-03-27
杨福义(1945—), 辽宁盖州人,鞍山师范学院高级工程师, 研究方向为语料库、术语数据库与知识组织系统。通信方式:yangfuyi@sina.com。
H083;N04
A
1673-8578(2014)04-0009-05
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
小读者(2020年4期)2020-06-16
快乐语文(2017年12期)2017-05-09
小学生必读(低年级版)(2017年12期)2017-03-08
语文知识(2015年9期)2015-02-28
外语学刊(2011年3期)2011-01-22
