
一种基于知识网络血缘关系的网页分类方法
2014-08-30 11:53李华康孙国梓徐向阳夏春蓉
江苏科技大学学报(自然科学版) 2014年4期
李华康, 孙国梓, 胥 备, 徐向阳, 夏春蓉
(1.南京邮电大学 计算机学院、软件学院,江苏 南京 210023)(2.南京大学 计算机科学与技术系,江苏 南京 210093)
一种基于知识网络血缘关系的网页分类方法
李华康1, 孙国梓1, 胥 备1, 徐向阳2, 夏春蓉2
(1.南京邮电大学 计算机学院、软件学院,江苏 南京 210023)(2.南京大学 计算机科学与技术系,江苏 南京 210093)
网页内容分析及分类方法作为用户行为分析、兴趣识别、舆情分析等上层应用的底层核心技术逐渐成为学术界乃至工业界的热点.针对基于标签数据建立机器学习模型的传统网页分类算法已经无法适应移动互联网时代海量数据的迭代更新需求的问题,文中提出一种基于知识网络血缘关系的非监督页面分类方法.该方法以维基中文知识库作为知识网络,标定少量网络上层基础词汇和网络热词的类目体系,利用知识网络的传递性来遍历计算所有节点关键词的类目属性.文章根据中文知识网络特有的文本相似度提出血缘关系算法和相似度提权函数.实验表明这种方法能够有效地提高基于知识网络的中文分类效果.
网页分类; 知识网络; 血缘关系; 提权函数
随着互联网的发展,越来越多的用户通过计算机和移动终端关注各类站点的信息.一些开源的站点如Yahoo和DMOZ ODP,通过提供结构化、层次化的浏览方式方便用户检索信息.而网站结构类目的定义以及所有网页的分类工作主要依靠人工标注来完成.根据网景(NetScape)在2008年的报道,有78940名编辑人员参与ODP网站的分类维护工作.分类的主要工作可以分为以下3类:
1)主题分类[1]: 主要对页面内容的主题进行的分类,如新浪首页的栏目信息,包括体育、文化、教育、科技等;
2)功能分类[2]: 功能分类更侧重于区分页面角色,例如判断当前页面是信息发布页面、讨论板,还是个人博客;
3)情感分类[3]: 作为目前最为热门的分类,用于对用户评论中的正面评论和负面评论进行区分.
在大数据时代,依靠完全人工或者半人工的页面编辑分类方式不仅无法满足快速膨胀的互联网用户需求,更可能面临标记人员本身素质或怠工等因素带来的标签错误等问题.自动化或者半自动化的网页分类技术不仅在学术界越来越受到重视,在工业界也有着巨大的市场需求.
网页分类作为互联网技术的一个基础支撑,对于提高互联网服务质量意义重大.诸多互联网上的关键应用,包括站点目录、搜索引擎、网页爬虫、推荐系统、用户行为分析系统和广告投放系统都需要高效、精准的页面分类结果.基于页面内容的分类方法是最原始也是最主要的网页分类方法[4],主要依赖于正文长短以及关键词的丰度和量.而随着一些大规模词典和类目体系的建立,基于第三方词库[5-6]的分类方法逐渐受到关注.第三方词库作为现成的语义类目不仅可以作为辅助信息增强语义,提高分类精度,而且不需要建立庞大的分类训练样本集,还能适应各种新词汇、词义漂移等现象.
文中主要针对大数据时代网页量多、传统分类方法无法有效进行标签以获得高精度分类结果等问题,提出一种基于知识网络的海量中文分类方法.文中以中文维基类目网络数据库为基础,通过定义少量的基础类目节点,对维基类目网络进行初始化,然后建立关联规则库,遍历整个维基类目网络节点,获得所有节点关键字的类目权值.为了提高分类效果,文中提出了知识网络血缘关系算法和类目分布提权函数.将父节点的子节点和叶子节点分别定义为儿子和女儿,在计算父节点和子节点之间的文本相似度时综合考虑了子节点和叶子节点之间的相似度问题.介于关键字在各类目中的分布不均问题,提出了双曲线类目关键字提权函数.实验数据显示文中提出的方法能够明显地提高知识网络分类算法的精度.最后通过一组横向算法比较,总结基于知识网络算法的优劣点.该方法还能应对传统网页分类算法在页面结构复杂、噪声多等环境下鲁棒性不高的问题.
1 国内外相关研究
1.1 基于文本的网页分类技术
传统的网页分类主要通过对页面非结构化、半结构化[7]和结构化信息进行解析,提取特征值,输入监督、半监督的机器学习系统[8]来实现的.文献[9]中针对网页的文本信息,在Yahoo数据库上提出并实现了一种比Bag of Words更好的N-Gram算法.文献[4]中利用HTML标签的title,headings,metadata以及main text 4个主要特征,提高了传统页面分类精度.而文献[10]利用改进的k-Nearest Neighbor算法分析上述4个权重,获得了更好的效果.文献[11]中提出了一种基于摘要的降低数据噪声的网页分类模型.
移动互联网页面由于文本长度不一,在用户输入关键字检索时也会因为无法匹配而丢失关键页面.文献[12]中用文本相似度算法也并未取得理想的效果.文献[13]中在检索词分类方面提出了用核函数的方法对短文本进行语义扩充,取得了一定进展.另外一些短文本分类技术主要依靠第三方词库,如WordNet[5], OpenCyc[6], ThoughTreasure[14],但也存在各自的缺陷[15].
1.2 知识网络
知识网络又称知识库[16-18],是知识工程中结构化、易操作、易利用、全面有组织的知识集群.知识网络的概念主要来源于两个领域,一个是传统的数据库领域,另一个是人工智能领域,这两项计算技术结合在一起,就促成了知识网络系统的产生和发展[19-20].在互联网上,比较大的知识库系统有Wikipedia,Wordnet,Baike等.Wordnet是普林斯顿大学的心理学家、语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典.文献[21]中利用Wordnet的标题和词汇注释来重新调整检索词的匹配权重的方法,提高了用户检索效果.维基百科(Wikipedia)是一个自由、免费、内容开放的网络百科全书,也是世界上最大的多语种词条知识库.文献[22]中利用英文Wikipedia词库提升了twitter的信息过滤效果;文献[23]和文献[24]中均提出了利用中文维基百科提高中文文本分类的方法.文献[25]和文献[26]中分别利用维基百科的词条及拓扑结构对网页分类进行了优化.
2 知识网络分类算法
维基百科作为目前最为庞大的知识网络,提供了每个页面的分类索引信息,每个类目对应于百科中的一个“概念”,并且隶属于一个或者多个父类目,包含一个或者多个子类目(图1).
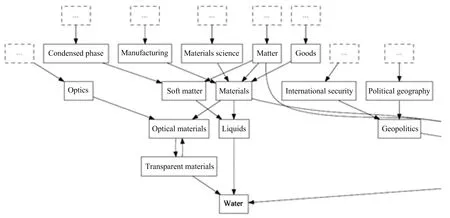
图1 维基百科知识网络拓扑结构示意Fig.1 Plot of Wikipedia knowledge network topology
2.1 维基类目网络结构
维基百科知识体系独立于其他类目体系,无法直接运用于类目主题分类.在此先给出几个定义和规则来重构维基知识库为新的维基类目网络.首先根据维基类目网络以及算法需要给出以下几个名词定义:
1)维基类目词汇:维基知识体系中的每个节点所对应的类目词汇;
2)基础类目:人工定义的基础类目,例如文化、体育、财经等;
3)基础类目词汇:每个基础类目中都包含一个预先定义的词表,基础类目词汇指的是词表中的每个词汇,如文化类目中包含“莫言”,体育类目中包含“篮球”,财经类目中则有“股票”.
定义基础类目向量C={c1,c2,…,cn},其中每个类目ci(1≤i≤n)对应一个基础词典dicti,与此同时假定i基础类目词典中各包含词汇量m,即dicti$定义为:{wordi1,wordi2,…,wordim}.
假设维基知识体系中包含k个互质词汇,维基类目词向量Wiki={w1,w2,…,wk},其中第j个词汇wj(1≤i≤n)的维基类目词汇与基础类目的关联关系如下:
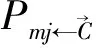
(1)
式中:pji(1≤i≤n)表示该维基类目词汇wj属于基础类目ci的概率,即当前维基类目词汇wj(1≤j≤k)隶属每个类目的可能性.具体关联规则根据不同情况可以分为初始关联、规则关联和完备关联3种.
2.2 初始关联
假设维基类目词汇与基础类目词汇存在一定交叉,即两个词汇完全相同或者存在高相似度sim(w1,w2).sim(w1,w2)表示由w1和w2中重合的非停止字段所占词长度的比重,文中采用余弦相似度和编辑距离两种算法来实现.如类目词汇“涡轮增压”(w10)只出现在基础类目“机械”(c1),那么关系函数为:{w10←c1:others:0}; 类目词汇“芯片频率”(w40)出现在基础类目“计算机”(c2)和“手机”(c3)中时,则类目的初始关联关系为:{W40←c2:0.5,w40←c3:0.5,others:0}.
2.3 规则关联
规则关联主要实现初始关联标记向整个维基知识体系的扩散,维基知识体系中越情迷的节点产生越高的类目关联结果.图2给出了类目节点类Node的数据结构,包括节点对象定义Node,类目词向量下标index,子节点数量children,父节点parents,类目概率category-weight和标记标签mark.

图2 维基知识网络类目节点数据结构定义示意Fig.2 Structure definition of category node inWikipedia knowledge
根据自上而下的遍历过程,维基网络的主要存在3种情况(图3),分别为单一链路规则,单层次多父节点规则和多层次多父节点规则.
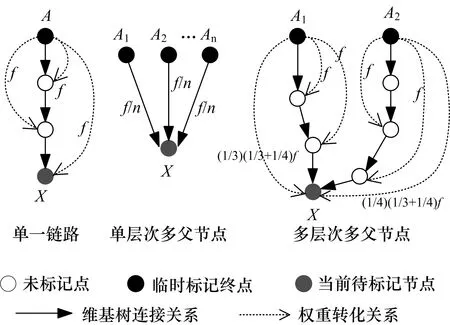
图3 基于维基知识网络拓扑结构的类目节点关联规则模型示意Fig.3 Association rules model of category nodes basedon the topology of Wikipedia network
1)单一链路:需要标记的节点X与最上层已标记节点A之间只有一条链路,则该链路的所经过的词汇必定是直接与上层节点类目相关联,节点X与上层标记节点的类目权重一致,定义其关联规则函数为:
MAPwX←wA:X.category.weight=f(A→X)-
A.category.weight
(2)
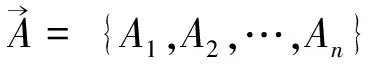
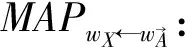
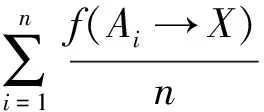
(3)
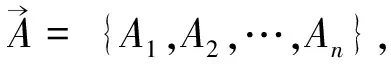
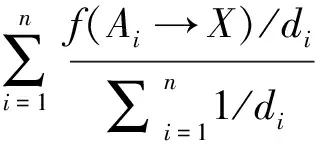
(4)
2.4 完备关联
在整个标记过程中,存在遍历的中间节点仍未被标记的情况,此时采用堆栈算法逐层向上回溯.在确保维基百科数据库的根目录均被标记的情况下,一定能找到一个已经标记的节点,然后再往下迭代,以至整个维基知识体系域,基础类目关联得以完善,最终建立完整的维基类目网络.
2.5 血缘关系函数
考虑到维基类目网络存在上下两层,类目属性存在漂移的现象,如“游戏类型”的父节点有“类型”和“游戏”,但是显然“游戏类型”和“游戏”贴切度更高.即随着维基类目网络深度的增加,子类目是否能够继承父类目的所有类目关系,需要计算子类目与父类目之间的血缘关系.为此引入两个继承函数:
1)基准继承函数:f(N1→N2)=1
2)血缘继承函数:在维基类目网络中,祖先节点和子孙节点的权重关联程度可以利用它们之间重合的叶子节点(页面)或者子节点(子类目)来衡量,具体函数如下:f(N1→N2)=∑∑sim(n1,n2)(n1∈N1.children,n2∈N2.children)
2.6 文本分类
一般的网页分类算法是将页面抽取到的主要文本定义为D,然后通过分词、去停用词来得到关于D的词袋,词袋中包含一些短语以及短语在当前文章中出现的词频.所以网页文本D可以用短语向量T={t1,t2,…,tq}和相对应的词频向量F={tf1,tf2,…,tfq}来表示,且网页文本D隶属于某个类目c1的权值可以计算为:
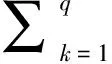
(5)
式中pki是通过关联算法获得的关于短语tk在维基百科中映射为基础类目ci的概率.根据以往经验,长词条含有更多的信息量,并且匹配难度更高,所以用len(tk)对pki进行了加权,同时给出一个提权函数φ(x)以弱化Score(D,ci)计算过程中ftk与pki的权重不均问题.
考虑到一个词汇在血缘继承上,如果多个父节点继承得到的权重差距越大,则表现越好,反之亦然.为了更好表现这个特征,对φ(x)的线性增长进一步调节成正弦双曲线函数,即:
无权重提权:φ(x)=x;
正弦双曲提权:φ(x)=sinh(δ·x),式中δ为常数;
在获得D相对于所有类目的权重后,系统可以采取简单的倒排序法筛选出D的最终类目归属:
D←c2,z=argmax(Scroe(D,ci))
(6)
3 实验及分析
3.1 实验数据集
实验数据来自阿里云计算有限公司提供的站长统计数据,统计显示5000个站点的浏览量在1亿条以上,数据量达到了4 TB.本实验选取2013年新浪、凤凰网、中国雅虎3个具有典型分类栏目的中文门户网站,浏览量前10的共同主题栏目页面(表1).
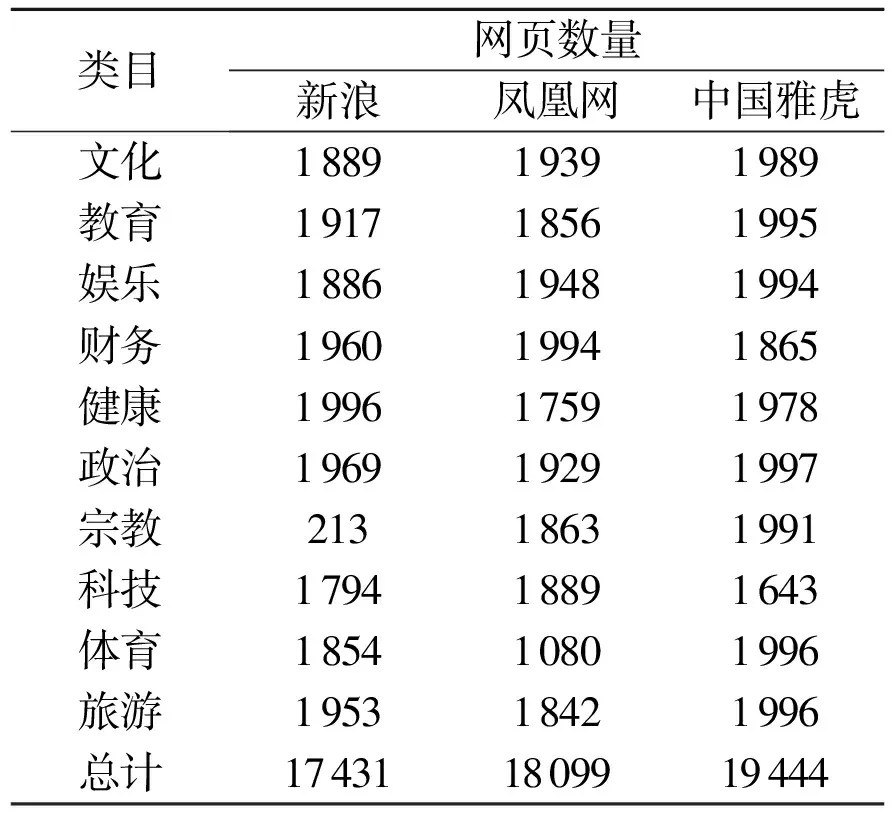
表1 实验网站及各栏目网页数量表Table 1 Web pages number of experimental sitesin different channels
3.2 血缘关系函数实验
表2给出了新浪、凤凰网和中国雅虎3个测试站点的知识网络关联规则分类实验结果.基础继承列出了一般关联规则下各个类目的预测准确率.显而易见,使用血缘关系算法之后,总体预测准确率有了3%左右的提升.在后面的实验中,如果不加说明,统一使用血缘关系函数.
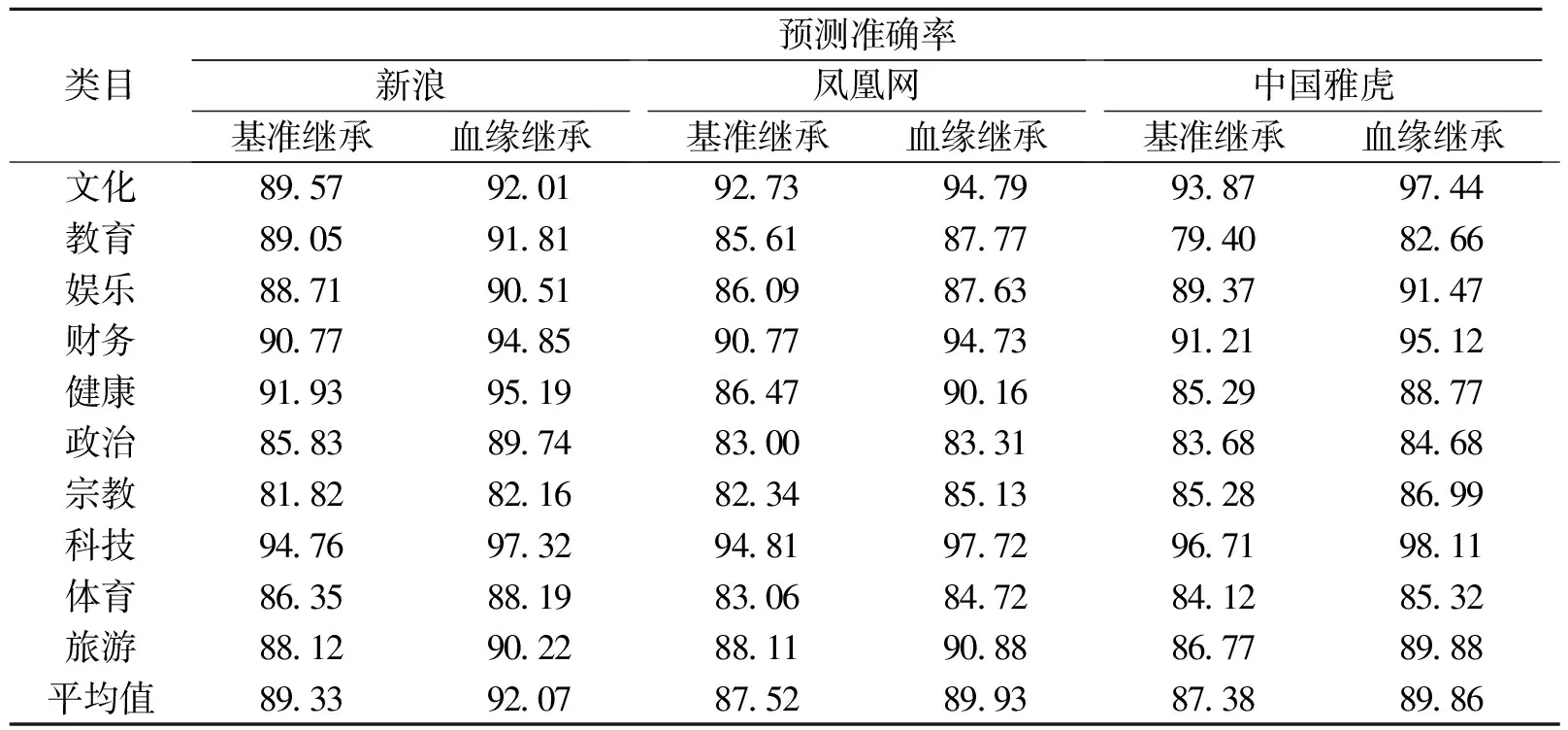
表2 基准和血缘继承函数对比实验结果Table 2 Experimental results comparing for benchmarks with basic inheritance and kinship-relationship %
3.3 提权函数评测
图4a)给出了使用提权函数后新浪站点各类目的准确率,可以看出提权函数对其中某些类目有改善.而图4b)是3个站点所有类目准确率平均值随着提权函数百分比的增长变化曲线.显然,随着提权函数的增高,各站点的分类准确率也有相应提高,并且在25%的时候达到了最佳效果.
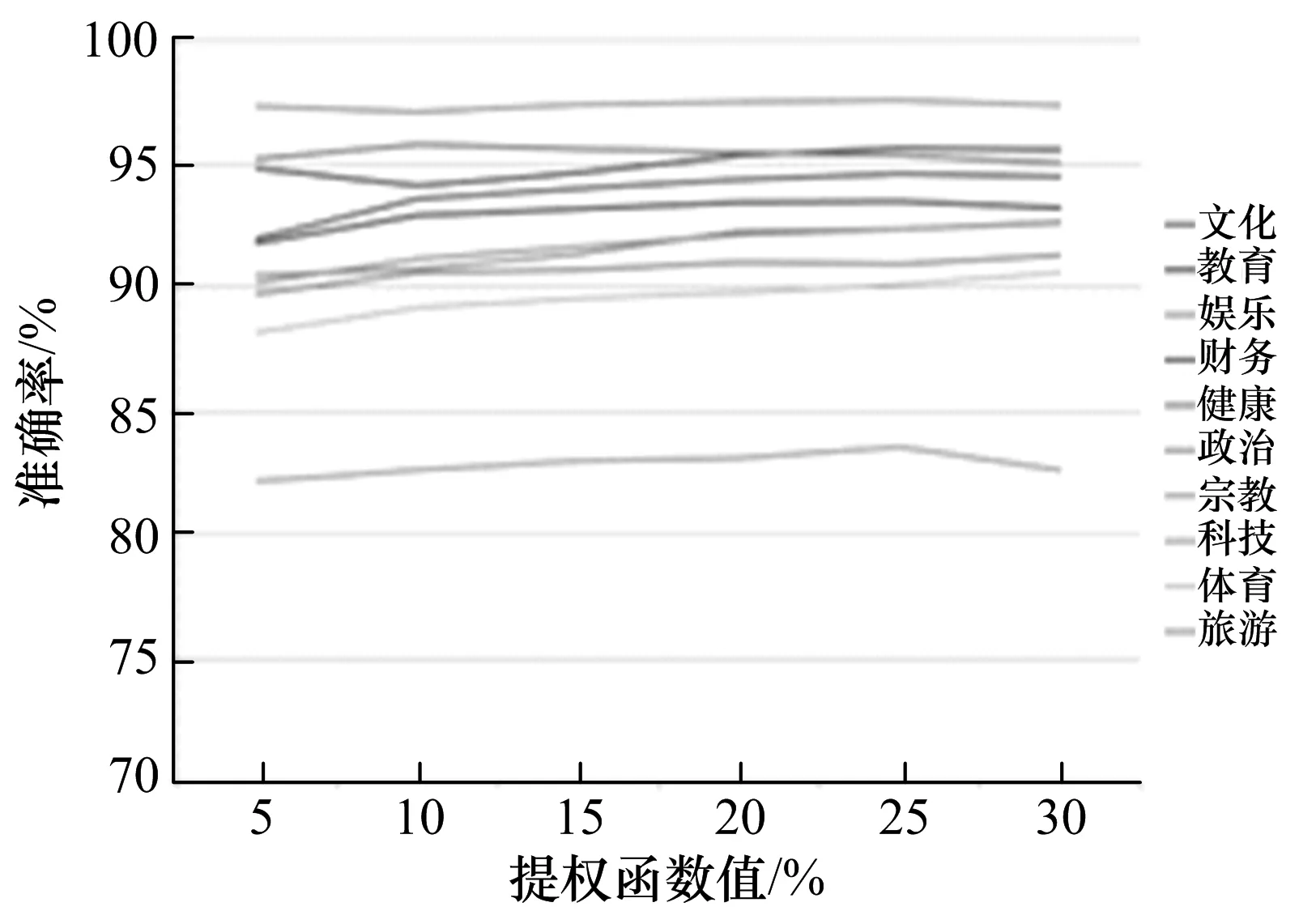
a) 新浪
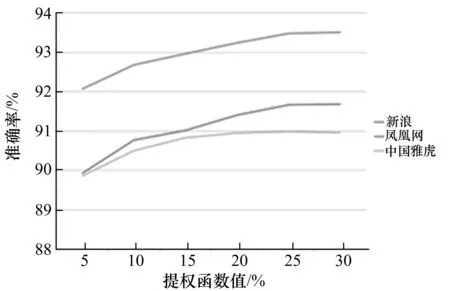
b) 所有类目准确度平均值
3.4 算法对比实验
为了体现基于知识网络血缘关系算法相比传统网页内容分类算法的优势,文中采用血缘继承函数和提权函数的最佳效果与传统的Bag of Words,TF-IDF算法进行比较.传统的BoW和TF-IDF方法根据各类样本数据和测试数据集合的大小,各类精度呈现出70%~90%的不稳定的分类结果.而采用维基知识网络分类算法不仅确保各分类准确度都在85%以上,而且各对比项的平均分类结果都有2%~4%的提升.
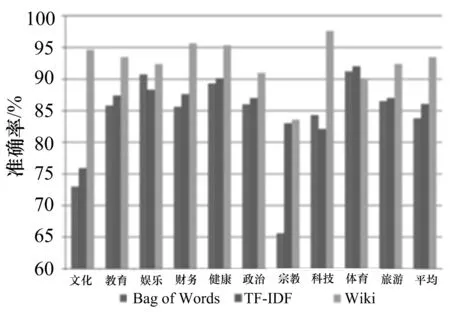
a) 新浪
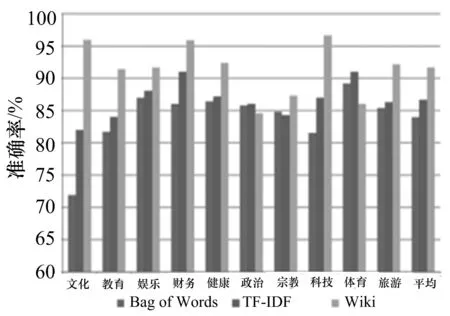
b) 凤凰网
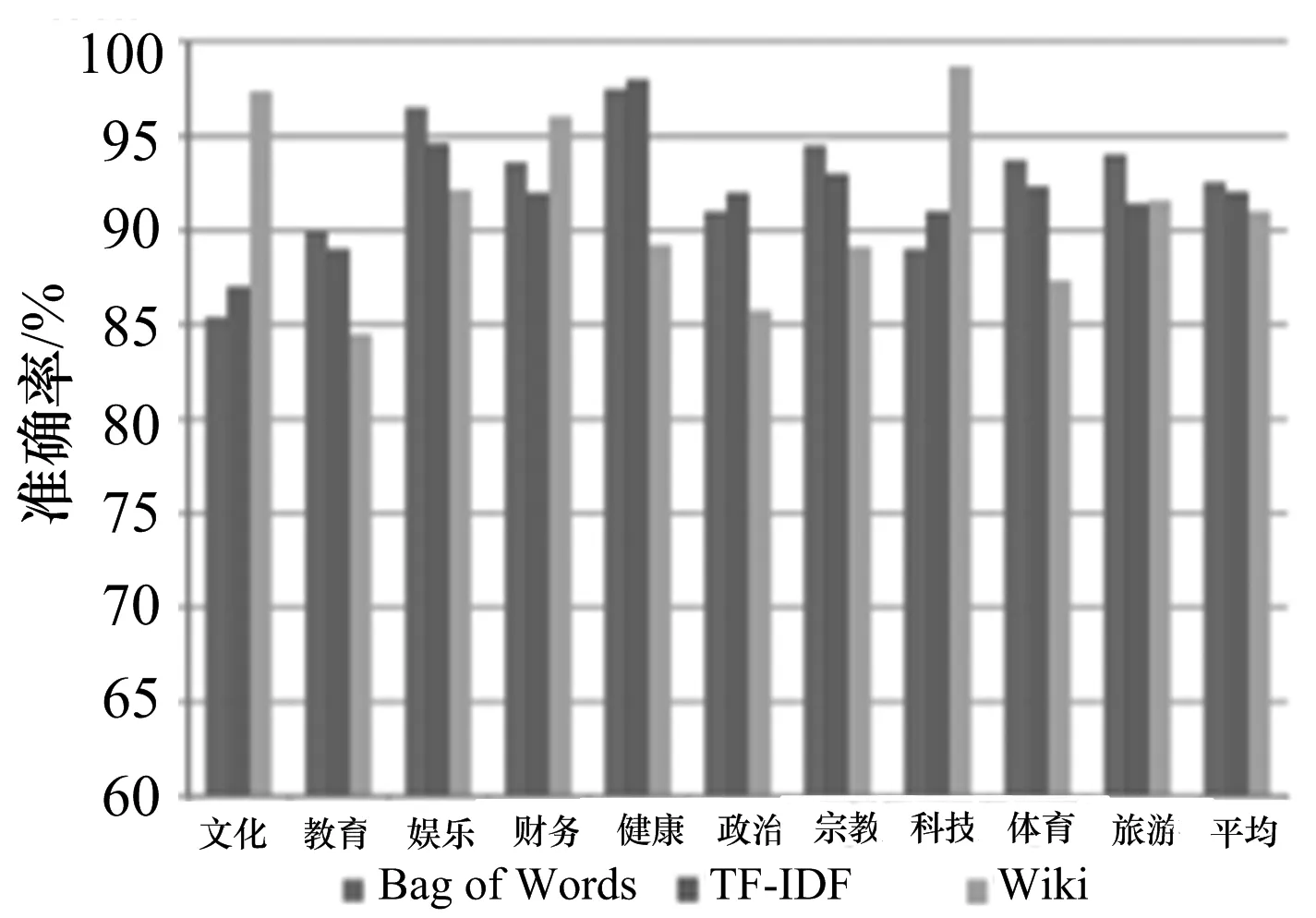
c) 中国雅虎
总体的分类准确率对比中,维基知识网络分类算法在新浪和凤凰网数据集中对比传统方法优势明显,而中国雅虎却截然相反.经过线下分析这3个站点页面结构,发现中国雅虎的网页长度远高于新浪和凤凰网,这也是传统大规模网页分类算法的局限所在.综上所述,维基主题分类在分类准确度和普适性上要优于传统分类方法,更适用于文本质量参差不齐的互联网环境.
4 总结
文中主要针对全网环境数据结构复杂、噪声多、干扰强的特点,提出了一种基于维基网络的主题分类模型.首先,将维基网络中的靠近根节点的类目词以及网络最新热词初始化为基础类目词汇,然后通过维基网络的初始关联、规则关联和完备关联3种传递特性进行全网遍历,获得所有维基词汇的类目属性.在遍历过程中考虑到子节点的多父节点继承问题以及随着步长深度增加产生的类目漂移问题,文中提出了血缘关联函数和提权继承函数.实验表明这种基于知识网络的血缘关系中文网页分类算法能够很好地对网页进行分类,并且能够适应不同环境下网页质量问题.
在实验过程中,发现维基百科对于中文的支持并不理想.其主要原因有:
1)维基百科英文词汇量要比中文大得多,许多英文类目都没有对应的中文编辑;
2)维基百科上的中文词库有一部分是繁体编码,这给数据处理过程带来很多不便;
3)可以整合一些更复杂的模型诸如LDA等主题模型.为了更好体现方法的适用性,系统将导入基于互动百科(百度百科)等类目体系融合的新知识网络体系.
References)
[1] He X F, Ding C H Q, Zha H Y, et al. Automatic topic identification using webpage clustering[C]∥IEEEInternationalConferenceonDataMining.San Jose CA USA:IEEE, 2001: 195-202.
[2] Zhang Xiaodan. A new algorithm for uncertain problem of web page classification[J].JournalofSoftware,2012, 7(3):526-531.
[3] Na J C, Thet T T.Effectiveness of web search results for genre and sentiment classification[J].JournalofInformationScience,2009, 35(6):709-726.
[4] Golub K, Ardo A. Importance of html structural elementsand metadata in automated subject classification[C]∥ResearchandAdvancedTechnologyforDigitalLibraries.[S.l.]:Springer, 2005:368-378.
[5] Miller G A. Wordnet: a lexical database for English[J].CommunicationsoftheACM,1995,38(11):39-41.
[6] Matuszek C, Cabral J, Witbrock M, et al.An introduction to the syntax and content of cyc[C]∥AAAISpringSymposiumonFormalizingandCompilingBackgroundKnowledgeanditsApplicationstoKnowledgeRepresentationandQuestionAnswering.[S.l.]: Citeseer, 2006.
[7] Haussler D. Convolution kernels on discrete structures[R].Santa Cruz:Department of Computer Science, University of California, 1999.
[8] Mitchell T. The role of unlabeled data in supervised learning[C]∥ProceedingsoftheSixthInternationalColloquiumonCognitiveScience. San Sebastian:[s.n.], 1999:2-11.
[9] Mladenic D. Turning yahoo into an automatic web-page classifier[C]∥EuropeanConferenceonArtificialIntelligence.[S.l.]:Citeseer,1998:473-474.
[10] Kwon O W, Lee J H. Text categorization based on k-nearest neighbor approach for web site classification[J].InformationProcessingandManagement,2003,39(1):25-44.
[11] Shen D, Chen Z, Yang Q, et al. Web-page classification through summarization[C]∥Proceedingsofthe27thAnnualInternationalConferenceonResearchandDevelopmentinInformationRetrieval.[S.l.]:ACM, 2004:242-249.
[12] Metzler D, Dumais S, Meek C. Similarity measures for short segments of text[J].AdvancesinInformationRetrieval,2007,4425:16-27.
[13] Sahami M, Heilman T D. A web-based kernel function for measuring the similarity of short text snippets[C]∥Proceedingsofthe15thInternationalConferenceonWorldWideWeb.[S.l.]:ACM, 2006:377-386.
[14] McCarthy J, Minsky M, Sloman A, et al. An architecture of diversity for commonsense reasoning[J].IBMSystemsJournal,2002, 41(3):530-539.
[15] Schonhofen P. Identifying document topics using the Wikipedia category network[C]∥InternationalConferenceonWebIntelligence, [S.l.]:IEEE,2006:456-462.
[16] 艾丹祥,张玉峰.利用主题图建立概念知识库[J]. 图书情报知识, 2003(2): 48-50.
[17] Zhang L. Knowledge graph theory and structural parsing[M]. Twente University Press, 2002.
[18] Bollacker K, Evans C, Paritosh P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]∥InternationalConferenceonManagementofData. [S.l.]: ACM, 2008: 1247-1250.
[19] 陈悦,刘则渊,陈劲,等.科学知识图谱的发展历程[J].科学学研究, 2008, 26(3): 449-460. Chen Yue,Liu Zeyuan,Chen Jin,et al.History and theory of mapping knowledge domain[J].StudiesinScienceofScience,2008, 26(3): 449-460.(in Chinese)
[20] 刘则渊,陈悦,侯海燕.科学知识图谱:方法与应用[M].北京:人民出版社,2008:294-295.
[21] Pal D, Mitra M, Datta K. Improving Query Expansion Using WordNet [EB/OL].2013.http:∥arxiv.org/abs/1309.4938
[22] Sriram B, Fuhry D, Demir E, et al. Short text classification in twitter to improve information filtering[C]∥Proceedingsofthe33rdInternationalConferenceonResearchandDevelopmentinInformationRetrieval. [S.l.]:ACM, 2010: 841-842.
[23] 范云杰,刘怀亮.基于维基百科的中文短文本分类研究[J]. 现代图书情报技术, 2012(3):47-52. Fan Yunjie, Liu Huailiang.Research on Chinese short text classification based on Wikipedia[J].NewTechnologyofLibraryandInformationService,2012(3):47-52.(in Chinese)
[24] 陈俊波, 李华康, 曾鹏程,等. 一种基于树形关联关系的文本分类方法:中国,申请号:201310009087.4[P].2013.
[25] 李华康.面向Web知识挖掘技术的研究与应用[R].上海:上海交通大学博士后报告,2013.
[26] 赖龙彬. 基于维基类目网络和URL模式树的网页分类方法探究[D].上海:上海交通大学, 2013.
(责任编辑:童天添)
Anapproachforwebpageclassificationbasedonkinship-relationshipknowledgenetwork
Li Huakang1, Sun Guozi1, Xu Bei1, Xu Xiangyang2, Xia Chunrong2
(1.School of Computer Science and Technology & School of Software, Nanjing University of Posts and Telecommunications,Nanjing Jiangsu 210023, China)(2.Department of Computer Science and Technology, Nanjing University,Nanjing Jiangsu 210093, China)
Analysis and classification approach of webpage content, which is a kernel technology for user behavior analysis, interest identification and opinion analysis, has become a hot topic not only in academia research but also in industry community. Webpage classification algorithm based on traditional labeled data to establish machine learning models has been unable to adapt to the requirement of iterative update of massive data in the era of mobile internet. An approach for webpage classification based on kinship-relationship knowledge network is proposed in this paper. The Wikipedia knowledge base is introduced as the base of knowledge network. After labeling the category of few basic vocabulary nodes and hot keywords in Wikipedia, we use the transmissibility of network to estimate the category attributes of all nodes. According to the specific characteristic of Chinese text, we proposed kinship-relationship and weights smoothing function during the traverse process. Experimental results show that this method is able to effectively improve Chinese webpage classification based on knowledge network.
webpage classification; knowledge network; kinship relationship; weights smoothing function
10.3969/j.issn.1673-4807.2014.04.015
2014-08-05
李华康(1982—),男,讲师,博士,研究方向为网络挖掘、用户行为分析、大数据分析.E-mail:huakanglee@njupt.edu.cn
TP18; TP391
A
1673-4807(2014)04-0380-07
猜你喜欢
英语文摘(2021年8期)2021-11-02
中学生数理化·七年级数学人教版(2020年9期)2020-11-16
意林·少年版(2018年22期)2018-12-05
成都信息工程大学学报(2018年1期)2018-05-31
新闻传播(2015年4期)2015-07-18
文理导航·阅读与作文(2015年1期)2015-07-13
读者·原创版(2015年11期)2015-03-01
图书馆学刊(2015年11期)2015-02-12
图书馆论坛(2015年2期)2015-01-03
意林(2014年2期)2014-02-11
