
基于迁移学习的行人检测研究进展
2014-08-05 02:40王向东钱跃良
计算机工程与应用 2014年24期
邵 松,刘 宏,王向东,钱跃良
1.中国科学院 计算技术研究所 普适计算研究中心,北京 100190
2.中国科学院 计算技术研究所 移动计算与新型终端北京市重点实验室,北京 100190
基于迁移学习的行人检测研究进展
邵 松1,2,刘 宏1,2,王向东1,2,钱跃良1,2
1.中国科学院 计算技术研究所 普适计算研究中心,北京 100190
2.中国科学院 计算技术研究所 移动计算与新型终端北京市重点实验室,北京 100190
1 引言
行人检测是指在输入的图像或视频中确定是否存在行人,并给出其位置、尺度大小等信息。它在智能视频监控、车辆辅助驾驶、人体行为分析等方面有着广泛的应用,是计算机视觉领域的核心技术之一。同时由于背景的动态变化,以及视角、尺度、遮挡和姿态等的影响造成行人外观的多样性,使得行人检测成为计算机视觉领域的研究热点和难点。
现有的行人检测方法可以分为两类:基于背景建模的方法和基于机器学习的方法。背景建模法通过建立背景模型,利用背景减分割出前景,进一步判断和提取其中的行人目标。这类方法的抗干扰能力不强,适用于摄像头固定的监控场景,难以处理背景的动态变化以及摄像头运动情况下拍摄的动态场景。基于机器学习的方法,从大量训练样本中提取特征来构建行人分类器或检测器,利用滑动窗口机制在图像中进行行人目标的搜索和定位。相对于基于背景建模的方法,这类方法对于动态场景具有更好的鲁棒性,逐渐成为当前的主流研究方法,其核心在于行人目标的特征描述和分类器构造。
在特征描述方面,早期的行人检测多采用如纹理、梯度、边缘等单一特征[1-4]。单一特征的描述能力毕竟有限,近年来出现了多特征融合方法[5-7],将具有互补特性的特征进行融合,进一步改善了检测效果。分类器用于确定最优的决策边界,是影响检测性能的另一个关键因素。目前行人检测领域最具代表性的分类器是支持向量机(SVM)和Adaboost分类器。前者通过将数据映射到高维空间来寻找最大间隔的最优分类面,而后者是一种自适应Boosting算法,将一些弱分类器通过线性加权组合成强分类器[1]。近年来出现了许多改进方法[8-13],进一步提升了行人检测的性能和速度。经过十几年的发展,基于机器学习的行人检测技术获得了长足的进步,正如Dollar综述文献[14]提到的,在INRIA数据集上进行训练和测试时,在每幅图像平均输出1个误报的情况下,漏检率从最初Viola等[1]的47.5%减少到目前Benenson等[15]的6.8%。
虽然基于机器学习的行人检测技术取得了很大的进步,但是由于场景背景的复杂性,以及行人表观的多样性,难以训练一个对于所有场景都适用的通用检测器。Dollar等[14]对现有十几个行人分类器的实验结果也表明,在INRIA数据集上训练好的分类器,直接用于其他不同场景下的行人检测,漏检率将提高20%到50%。针对不同场景下的行人检测任务,现有的行人检测系统,一般采集并手工标注该场景下的大量样本来训练分类器。如果场景发生变化,需要重新采集和标注大量的样本,重新训练分类器,耗时耗力,难以在实际应用中推广。
已有检测器在新场景下的行人检测性能急剧下降,其主要原因是由于新旧场景的拍摄背景、视角、行人姿态和尺寸等方面可能存在差异,使得原有训练集和新场景中的样本遵从不同的数据分布。而目前大多数行人检测方法基于统计学习方法,前提是数据的同分布假设,而当新旧场景存在分布差异时,原有检测器在新场景下难以有效地检测行人,这其实是传统的统计机器学习方法普遍存在的推广性难题。由于在某些场景或领域难以得到大量样本数据,对样本标注会耗费大量人力和物力,而且从头学习也非常耗时,基于此难题,迁移学习(Transfer Learning)或领域自适应方法(Domain Adaptation)[16-19]逐步引入机器学习领域。迁移学习与传统的统计学习方法不同,迁移学习研究不同数据分布下的学习问题,利用从一个场景或环境中学习到的知识来帮助新环境中的学习任务[19]。
随着监控视频,车载视频的不断涌现,大量不同场景下的行人检测任务变得越来越迫切,为了减少繁琐的人工标注,充分利用已有检测器及其大量样本,基于迁移学习机制,研究已有行人检测器在新场景下的适应性问题具有重要的学术价值和实际意义。从当前国内外研究现状来看,这方面的研究受到越来越多的关注,本文针对检测器适应性问题所涉及的样本获取,迁移学习机制等方面进行介绍,并从几个方面对现有方法进行分析和比较,最后对该技术的未来发展方向进行展望。
2 研究现状
2.1 新场景下样本的获取方法
由前所述,由于原有训练样本和新场景样本的数据分布可能存在差异,导致已有检测器在新场景下的检测性能下降,为了实现已有检测器和样本在新场景下的迁移和自适应,首先需要获取新场景的行人样本。高质量的目标场景样本能为后续的样本迁移和分类器训练等过程提供有效的引导。
目前在视频行人检测领域,新场景下样本的获取方法主要有两种:一种是采用手工标注少量样本的方法[20],该方法的样本标注可靠性较高,但是少量样本不足以代表新场景的数据分布特性;另一种是利用已有检测器,自动从目标场景中检测并选取正样本和负样本,重新训练检测器,这是视频行人检测领域目前广泛采用的方法[21-30],这类方法方便快捷,其关键问题是如何提高自动检测和选取样本的可靠性。
样本的自动获取方法在分类器的在线更新中被广泛采用,Nair等[21]针对固定摄像头,使用背景减除方法来获取目标样本。这种方法产生的样本可靠性不高,容易使检测器发生漂移。Rosenberg等[22]使用了一种半监督的self-training方法,选取得分较高的检测结果作为目标样本,但是这些样本不能充分反映新场景的数据分布特性。一些研究[23-26]使用协同训练框架,先基于两种不同类型的特征和少量标注数据学习两个检测器,然后交替地将其中一个检测器用于目标场景,收集可靠性较高的样本重新训练另外一个检测器。要保证协同训练的效果,两个检测器的特征需要互相独立,要设计完全独立的特征较为困难。Sharma等[27]对于初步的行人检测结果进行跟踪,通过选择漏检和误报作为正样本和负样本,选择的样本更有针对性,通过在线增量式学习提高分类器的适应性。这些方法主要针对同一场景下的检测器进行在线学习,由于同一场景下的数据分布具有相似性,所以自动标注的噪声较少。
由于新旧场景数据分布可能存在差异,利用以上方法在新场景下自动获取的样本难免存在标注噪声,即样本的标注可靠性不高。在初始检测结果基础上,结合多种策略对样本标注结果进行调整,提高样本标注的可靠性,是必不可少的重要步骤。Wang等[28]先使用原始检测器在新场景下进行行人检测,然后结合运动、大小、位置、外观和路线模型等上下文信息,为每个样本计算置信度,进行样本筛选,其效果的提高主要依赖于行人或车辆的运动路线,具有一定的局限性。Wang等[29]进一步使用置信度的传播来代替直接设定阈值进行筛选,对样本标注噪声具有一定的鲁棒性。Liang等[30]根据行人尺度、运动等上下文信息和置信度值对自动标注的目标样本进行筛选,得到target templates。然后基于稀疏编码,衡量目标样本和target templates间的相似度,赋予其不同的权重。表1对现有的样本获取方法进行了总结和比较。

表1 样本获取方法比较
综上所述,新场景下标注样本的获取是后续迁移学习的基础。手工标注少量样本虽然保证了样本的可靠性,但是少量样本不足以代表整个新场景的数据分布特点。将已有检测器直接用于新场景进行样本的自动标注是目前常用的方法,而原有检测器的性能和泛化能力对于标注效果有着重要影响。另外,自动标注不可避免地存在标注噪声,如何利用多种策略以及新场景的上下文信息进行样本置信度的调整,从而进行初始检测样本的筛选,提高新场景下标注样本的可靠性,还需要进一步研究。
2.2 迁移学习及在行人检测中的研究进展
虽然已经提出了各种方法从目标场景中自动获取样本,但样本中不可避免地含有标注噪声,会影响检测器的训练效果,而且有时难以从目标场景中获得足够多的样本。与此同时,在源数据集中还有大量标注的样本可用。为充分利用这些资源,迁移学习或领域自适应方法[16-19]近年来逐步在机器学习领域得到应用和发展。迁移学习的整体框架如图1所示,其对已有的知识进行提取和迁移,利用这些知识辅助完成新场景下的检测任务。迁移学习与传统的机器学习不同,不再采用同分布假设,而是利用从一个环境中学习到的知识来帮助新环境中的学习任务。
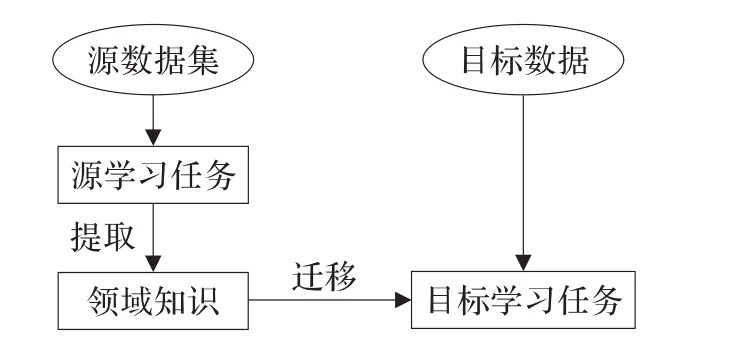
图1 迁移学习图示
迁移学习目前已成功用于自然语言处理、信息检索、物体识别和场景分类等领域。迁移学习在视频行人检测中的研究才刚刚起步,迁移学习中的“源领域”在本文中对应已有训练数据,“目标领域”对应新场景视频数据,“源任务”和“目标任务”对应行人检测,目前文献主要涉及基于实例的迁移和基于特征表示的迁移两个方面,下面将对已有方法进行介绍和分析。
2.2.1 基于实例迁移的行人检测
基于实例的迁移学习方法认为,虽然源领域和目标领域的数据分布不一致,但源数据集中可能存在一些样本和目标样本比较相似,可以将这部分数据迁移到目标场景中,辅助检测器的训练和优化。其关键问题是如何度量源样本和目标样本的相似度,以及如何同目标样本相结合进行新场景下的检测器训练。
(1)源样本迁移方法
现有的研究多采用对源样本重新赋权的方式,权重越大,表明源样本和目标样本越相似,在训练过程中起的作用越大,而如何度量源样本和目标样本的相似度是一个关键问题。
其中,Wang等[29]利用基于图的表示和KNN算法(K-Nearest Neighbor algorithm),将样本看作图上的点,计算样本间的欧氏距离作为边长,构建每个目标样本的K邻域,然后将目标样本与邻域内所有源样本的边长转换为相应权重。则每个源样本的相似度等于其所属的所有邻域中目标样本的置信度和两者间权重的乘积求和。这种方法利用了邻域内目标样本的置信度和距离,但样本间的欧氏距离可能无法准确反映样本间的差异。
Liang等[30]使用稀疏编码的思想来计算样本间的相似度。首先根据上下文信息对目标样本计算置信度并进行筛选,然后将源样本作为基向量,将挑选出的目标样本进行投影,得到稀疏系数。则每个源样本的权重等于投影在上面的所有目标样本对应的稀疏系数与其置信度的乘积之和。稀疏向量比较紧凑,能反映样本间的距离,但直接用源样本做基向量,未必具有良好的代表性和区分性。
Cao等[31]利用流形学习方法筛选出原场景中与新场景中相似度较高的样本。首先对每个目标样本,用KNN算法找到其在源数据集中的近邻,然后利用Isomap(Isometric Mapping)方法将所有样本映射到同一个低维流形空间中。接着计算所有样本的中心点,在流形图上找到每个样本到中心点的路径,并将路径上的源样本加入到目标样本集中,但是流形空间的计算复杂度较高。
Tao等[32]和Duan等[33]则通过多核函数,将样本映射到高维特征空间,用MMD(Maximum Mean Discrepancy)准则度量源数据集和目标数据集间的分布差异。通过最小化数据集间的分布差异和结构风险函数,学习一个合适的多核空间和分类函数,实现对源数据集的整体迁移。此类方法如何选择合适的核函数是关键,而且容易受数据分布差异影响。
(2)检测器训练方法
经过自动标注目标样本和迁移源样本,得到了由赋权的源数据集和目标数据集共同组成的训练集,用于学习一个适用于目标场景的检测器。但自动标注难免存在错误,而源数据集和目标数据集又存在数据分布差异,因此直接利用这些不够可靠的训练样本训练检测器,难以取得很好的效果。
为了提高检测性能,设计一个具有迁移学习能力的训练方法,更加合理有效地利用源样本和目标样本是一个关键问题。
Wang等[29]提出了一个通用性较好的迁移框架:Confidence-Encoded SVM,在原始的SVM目标函数中加入对源样本和目标样本的惩罚项,并使用置信度的传播来处理目标样本中的噪声。获取检测器后,重新标注目标样本和迁移源样本,进行新一轮的训练。经过多轮优化过程后,输出最终的检测器。Liang等[30]采用了和Wang等[29]相似的框架,但使用对目标样本赋权代替置信度的传播,简化了目标函数的构造和训练过程。
Cao等[31]对Adaboost算法进行扩展,提出了ITLAda-Boost方法,通过计算分类器在源和目标数据集上的错分率来动态调整样本权重,被错分的源样本权重逐渐减小,而被错分的目标样本权重逐渐增大。最终的分类器由每轮得到的分类器线性加权组合而成。
Tao等[32]在多核空间用MMD准则度量源数据集和目标数据集的分布差异,通过最小化数据集间的MMD和结构风险函数,同时学习一个多核组合空间和SVM分类器。Duan等[33]采用和Tao等[32]类似的过程得到多核SVM作为初始判别函数,对未标注的目标数据进行类别划分。然后利用局部学习思想,根据邻居样本的标签信息对每个目标样本的类别进行局部重构。最后再利用这些目标样本学习一个更加鲁棒的分类器。该方法考虑了样本局部分布特征,能在一定程度上提升迁移效果。
Huang等[34]提出了组合多核迁移学习算法(kEMKLT)和递增多核迁移学习算法(kIMKLT)。首先通过学习一个多核函数将样本映射到高维空间,然后选择相似度较大的部分源样本加入目标数据集,重新学习多核SVM分类器,迭代多次。二者不同之处在于前者的最终预测结果由每次迭代的预测结果加权组合得到,而后者只使用最后得到的SVM分类器进行预测,而核函数的选择对结果影响较大。
Tang等[35]不仅在目标函数中加入样本的惩罚项,还引入参数来控制参加训练的源样本和目标样本数目。通过最小化目标函数,舍弃一些惩罚值过大的样本,并且随着训练的进行,减少训练集中源样本数目并增加目标样本数目,提高训练集的样本质量,该方法充分利用了目标样本。
最近的一些研究[36-37]考虑了多个源数据集的情况。张等[36]假设源训练数据来自多个不同的源领域,然后基于每个源数据集和少量目标数据训练一个弱分类器,计算该分类器在目标训练集上的分类误差,作为其权重。弱分类器权重的大小反映了对应的源数据集对于目标任务学习的帮助大小。赋权后的弱分类器连接起来构成当前候选分类器,然后根据候选分类器在训练集上的误差更新源样本权重,进行下一轮迭代。
于等[37]根据多个源数据集中样本的共性,来调节源样本在训练过程中的权重,提出了基于分类一致性的迁移学习算法。该研究基于Boosting框架,在每次迭代过程中,通过学习源数据集得到多个分类器,然后利用熵度量源样本在这些分类器上的分类一致性,对样本权重进行调整。即在不同分类器上分类结果保持一致的样本权重较高,分类结果差别较大的样本权重较低。文献[36]是对多个源领域的知识进行迁移和集成,文献[37]则考虑从多个源领域中挖掘共有的知识用于迁移学习过程。
考虑到样本的标注噪声和数据集间的分布差异,以上研究通过对目标函数的改造和训练方法的设计,较好地将两部分数据融合起来,用于目标场景的学习。一些研究使用了多轮迭代的学习过程[29-31,34-37],相比一次性的迁移,虽然比较耗时,但能有效改善样本质量,从而提高了检测器对当前场景的适应性。
综上所述,基于实例的迁移是目前最为常用的一种迁移学习方法,主要涉及如何筛选源样本以及如何有效利用源样本重新训练检测器。实例迁移的目的是筛选出较好贴合目标场景数据分布的其他场景样本。现有方法大多将衡量场景数据分布的差异转化为度量新旧样本之间的相似度,其关键在于样本的特征描述和样本间的相似度计算方法。另外,根据相似度进行样本筛选也很重要,相似度太高的样本并不能增强数据集的代表性,相似度过低的样本又很可能误导训练过程。特别是在检测器重新训练阶段,如何通过一定的策略不断调整样本比例或者权重,来尽量减少这方面的影响尤其重要。但是,当新旧场景的数据分布差异过大时,一次训练的效果不够理想。检测器应该具有持续优化样本和调整分类界面的能力,因此多轮迭代是一种更好的学习策略。
2.2.2 基于特征迁移的行人检测
基于实例的迁移方法适用于源数据集和目标数据集差别较小的情况,否则难以找到与目标样本相似的源样本进行迁移。而基于特征的迁移方法则是寻找特征层面的公共知识进行迁移,对于数据集差别较大的情况也适用。
目前在行人检测领域基于特征迁移的文献相对较少,要找到一种映射方法或者新的特征表示并不容易。
有些研究[38-39]使用稀疏编码来实现特征的迁移学习。稀疏编码方法首先在未标记样本集中学到一组基向量来近似表征这些样本,然后将有标记的训练样本转换为稀疏编码,用于训练分类器。由于编码比较紧凑,能很好体现图像的边缘结构[38],所以可以适应一定程度的场景变化。Liu等[39]使用SIFT特征点代替随机取点和SIFT特征空间取代灰度空间,提高了稀疏编码的可用性。这类方法的关键是保证基向量的代表性和区分性。
Wang等[40]首先将原有检测器用于目标场景,收集检测结果,然后从中采样得到若干16×16的图像块。对图像块提取HOG特征,使用分层的K均值算法构造词汇树,然后利用词汇树将置信度高的行人目标检测结果编码为二进制向量。通过计算待分类样本与这些向量间的相似度来进行行人分类。这种方法的思想类似稀疏编码,认为样本可以由小的图像块基元进行表示,不直接寻找不同领域间特征的变换关系,而是将特征转化为一种统一的表示形式。
Pang等[41]认为新场景下的特征位置发生变化,但在原有特征位置周围呈现正态分布。因此,对于boosting结构的级联分类器,先对原有检测器中的每个强分类器,使用特征移位生成特征池,然后通过最小化covariate损耗函数找到最优的特征位置,对分类器进行更新。最后的目标检测器由各个更新后的分类器级联得到。
Tang等[35]将特征分为源数据集和目标数据集共有的特征以及目标场景特有的特征。通过调节特有特征部分的权重向量的L1范数大小来控制其参与训练的程度。开始时只使用共有的特征进行检测器的学习,在训练后期,当目标样本比重足够大,模型对于当前场景更有针对性时,加入目标场景特有的特征,进一步提高检测器的适应能力。
类似的,张等[42]也将特征分为源领域和目标领域共享的特征以及各自特有的特征两部分,并将特征投影到再生核Hilbert空间,通过减少领域间共享特征在Hilbert空间中的嵌入期望距离(EMD)实现特征的有效迁移。以SVM分类器为基础,在目标函数中加入共享特征和特有特征的结构风险函数,进行整体优化,这种融合异构特征的子空间迁移算法,能够保证共享特征和异构特征之间达到较好的平衡。
综上所述,基于特征表示的迁移实质是寻找新旧特征之间的映射关系。为此,需要基于新旧样本的差异或者场景的其他信息进行推测,对旧的特征进行变换和调整。而基于实例的迁移学习也涉及到特征的调整,比如基于候选特征池的检测器在重新训练过程中会重新学习和挑选特征的位置和类型等。基于特征表示的迁移的好处在于不需要新旧场景具有一定的相似度,在样本无法有效迁移的情况下也能使用。但是很多时候特征和场景变化之间的关系并不容易衡量,一些方法使用的假设也不具有普遍适用性,直接对特征进行改造较为困难。因此,在行人检测领域,基于特征表示的迁移更适用于某些特定的场景,比如能够找到较为明显的依据推断出新旧特征之间的映射关系等。
2.2.3 基于实例迁移和特征迁移的比较
针对行人检测任务,基于实例的迁移和基于特征表示的迁移方法各有特点。如果原有标注样本足够多、代表性足够强,通常能找到一些与目标样本相似的源样本用于迁移。因此,现有研究大多使用基于实例的迁移学习算法,将一个已有行人检测器迁移到新场景中。当原始样本和目标样本差别较大时,难以进行样本的迁移,可以考虑采用基于特征的迁移学习方法。可见,基于实例的迁移方法通常具有更强的迁移能力,而基于特征的迁移方法则适用范围更广[43]。表2对二者在基本思路、迁移能力、适用范围和文献数量等方面做了分析和比较。

表2 行人检测中的迁移方法比较
2.3 现状总结和分析
面对新场景下的行人检测任务,由于和原有训练样本往往存在一定的数据分布差异,导致已有检测器在新场景下的检测性能发生显著下降,为避免重新标注大量样本和充分利用原有样本和分类器,基于迁移学习的行人检测研究得到越来越多的关注。以上内容从新场景下样本的获取,以及基于实例的迁移和基于特征表示的迁移等方面对现有方法进行了分析和比较。
新场景样本获取的关键问题是样本自动标注和去噪方法,其目的是提高新场景样本的可靠性和代表性。而迁移学习则基于获取的目标样本,通过引入其他场景样本或者改造已有特征,对检测器进行优化训练,使之能够适应新场景的行人检测任务。根据以上研究现状,将基于迁移学习的行人检测涉及到的关键技术总结如图2所示。
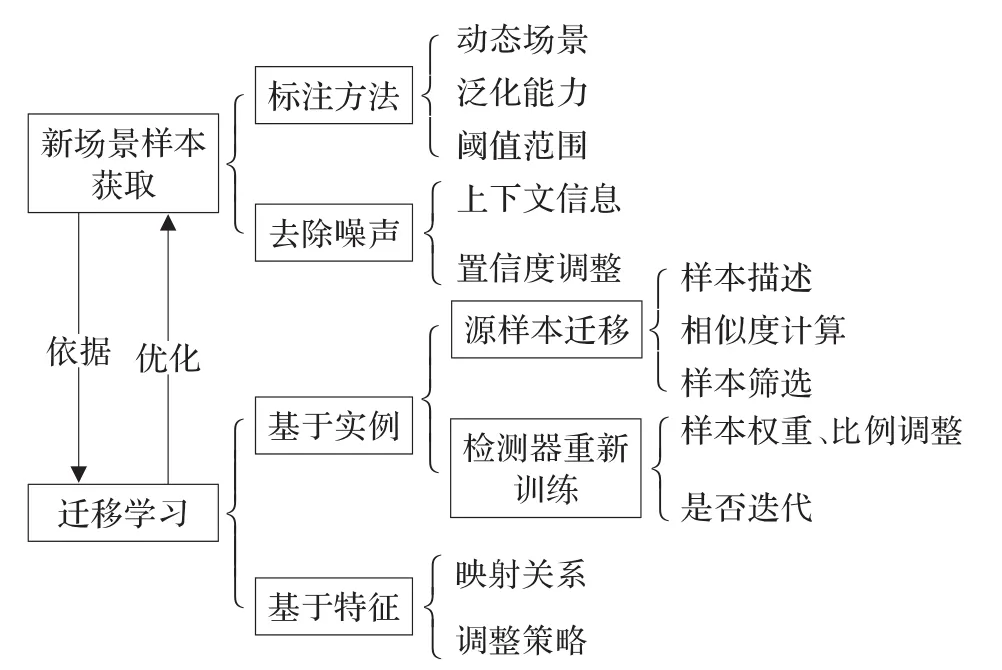
图2 迁移学习关键技术
以上从涉及的关键技术角度进行了总结,在迁移学习的整个系统流程方面可以参考图3所示。首先需要获取新场景的相关信息,这些信息能够反映场景特性,但还不足以对检测器进行有效的重新训练。然后基于获取的信息,对新旧场景进行比较分析,找出场景之间的差异。现有的多数方法还是将场景差异转化为新旧样本间的差异,利用新场景下手工或者自动标注的样本和已有标注样本进行比较,为基于实例的迁移学习提供依据。还有一些方法试图根据场景差异推导特征之间的映射关系,对已有特征进行调整和改造,进行基于特征表示的迁移。最后,将这些迁移的知识和新场景下获取的信息融合起来,在迁移学习框架下对已有的检测器进行重新训练和优化,从而实现已有检测器对于新场景的自适应。

图3 整体结构图示
3 未来研究展望
虽然现有方法在一定程度上改善了新场景下的行人检测效果,但距离实际应用还有很大差距。将来的研究需要从以下几个方面着手:
(1)改善已有行人检测器的初始检测结果
由于新旧场景的数据分布往往存在差异,已有行人检测器在新场景下的检测性能会出现显著下降。其主要原因是统计学习方法的训练目标是最小化经验风险,没有充分考虑分类模型的泛化能力。因此提升已有行人检测器的泛化能力,改善新场景下的样本初始检测结果十分必要。
(2)提高目标样本的可靠性和代表性
新场景下自动获取的样本,不可避免地存在标注噪声。现有方法有的直接利用高置信度样本,有的利用场景上下文信息对样本置信度进行调整,一定程度上改善了样本的可靠性。但是对低置信度样本的利用不够,这些样本往往在一定程度上反映了新旧场景数据分布的差异,如何充分利用这部分样本提高目标样本的代表性有待进一步研究。
(3)新旧样本间的相似性度量
从最初利用欧氏距离到借助多核函数、稀疏编码和流形学习等技术来度量样本间的相似性,现有方法在一定程度上改善了样本迁移效果。但核函数的选择,基向量的学习和流形空间的构造对于相似性度量结果有重要影响,有必要进一步改进现有方法并研究新的样本相似性度量方法。
(4)深度挖掘目标场景信息
场景中的各种上下文信息能够有效地反映场景的某些特性,可用于样本的置信度调整,新旧样本相似性度量以及特征映射关系推导等。现有方法对于场景上下文信息的挖掘和利用还很有限,提出的一些模型不具有推广性。如何更好地挖掘和利用场景上下文信息,改善检测器对于新场景的适应性,还需要进一步研究。
(5)设计持续优化的迁移学习框架
不少现有方法从新场景中一次性地获取目标样本,如果新旧场景存在较大的分布差异,这些目标样本的可靠性和代表性不高,往往不能很好地反映目标场景的数据分布特性。而好的目标样本是影响检测器性能的关键因素,因此需要研究基于多轮迭代优化的迁移学习方法,从而不断改进新场景样本质量,提高检测器性能。
(6)新旧场景间数据分布的整体差异性度量
为了构建一个具有推广性的检测器自适应框架,应该进一步研究和度量原数据集和目标数据集之间的差异程度,根据度量结果再选择合适的方法进行迁移学习。例如,如果差异较小,可以考虑基于实例的迁移,如果差异较大,则采用基于特征的方式或者只使用目标样本来优化检测器,避免出现负迁移现象。
综上所述,如何利用已有行人检测器和训练样本,提高新场景下的行人检测效果,是计算机视觉领域的一个难点,具有重要的理论研究价值和实际应用前景。目前基于迁移学习的行人检测研究虽然取得了一些进展,但是还有许多问题有待进一步研究和探索。
[1]Viola P,Jones M.Rapid object detection using a boosted cascade of simple features[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Kauai,HI,USA,2001:511-518.
[2]Wu Bo,Nevatia R.Detection of multiple,partially occluded humans in a single image by Bayesian combination of edgelet part detectors[C]//Proceedings of IEEE International Conference on Computer Vision,Beijing,China,2005:90-97.
[3]Sabzmeydani P,Mori G.Detecting pedestrians by learning shapelet features[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Minneapolis,Minnesota,USA,2007:1-8.
[4]Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,San Diego,CA,USA,2005:886-893.
[5]Wang Xiaoyu,Han T X,Yan Shuicheng.An HOG-LBP human detector with partial occlusion handling[C]//Proceedings of IEEE International Conference on Computer Vision,Kyoto,Japan,2009.
[6]Wojek C,Schiele B.A performance evaluation of single and multi-feature people detection[C]//Proceedings of DAGM Symposium on Pattern Recognition,Munich,Germany,2008:82-91.
[7]Dollar P,Tu Zhuowen,Perona P,et al.Integral channel features[C]//Proceedings of British Machine Vision Conference,London,UK,2009:1-11.
[8]Maji S,Berg A,Malik J.Classification using intersection kernel svms is efficient[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Anchorage,Alaska,USA,2008:1-8.
[9]Kim T K,Cipolla R.MCBoost:Multiple Classifiers Boosting for perceptual co-clustering of images and visual features[C]//Proceedings of IEEE Conference on Neural Information Processing Systems,Vancouver,British Columbia,Canada,2008:841-856.
[10]Xu Yanwu,Cao Xianbin,Qiao Hong.An efficient tree classifier ensemble-based approach for pedestrian detection[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2011,41(1):107-117.
[11]Liu Hong,Xu Tao,Wang Xiangdong,et al.Robust human detection based on related hog features and cascaded adaboost and svm classifiers[C]//Proceedings of International Conference on Multimedia Modeling,Huangshan,China,2013:345-355.
[12]Dollar P,Belongie S,Perona P.The fastest pedestrian detector in the West[C]//Proceedings of British Machine Vision Conference,Aberystwyth,UK,2010:1-11.
[13]Dollar P,Appel R,Kienzle W.Crosstalk cascades for framerate pedestrian detection[C]//Proceedings of European Conference on Computer Vision,Firenze,Italy,2012:645-659.
[14]Dollar P,Wojek C,Schiele B,et al.Pedestrian detection:an evaluation of the state of the art[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(4).
[15]Benenson R,Mathias M,Timofte R.Pedestrian detection at 100 frames per second[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Providence,Rhode Island,2012:2903-2910.
[16]Thrun S,Pratt L.Learning to learn[M].Holland:Kluwer Academic Publishers,1998.
[17]Raina R,Battle A,Lee H,et al.Self-taught learning:transfer learning from unlabeled data[C]//Proceedings of International Conference on Machine Learning,Corvallis,Oregon,USA,2007:759-766.
[18]Daume H,Marcu D.Domain adaptation for statistical classifiers[J].Journal of Artificial Intelligence Research,2006,26(1):101-126.
[19]Pan S J,Yang Qiang.A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering,2010,22(10):1345-1359.
[20]Melville P,Mooney R J.Diverse ensembles for active learning[C]//Proceedings of International Conference on Machine Learning,Banff,Alberta,Canada,2004:584-591.
[21]Nair V,Clark J.An unsupervised online learning framework for moving object detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Washington DC,USA,2004:317-324.
[22]Rosenberg C,Hebert M,Schneiderman H.Semi-supervised self-training of object detection models[C]//Proceedings of IEEE Workshop on Application of Computer Vision,Breckenridge,CO,USA,2005:29-36.
[23]Javed O,Ali S,Shah M.Online detection and classification of moving objects using progressively improving detectors[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,San Diego,CA,USA,2005:696-701.
[24]Levin A,Viola P,Freund Y.Unsupervised improvement of visual detectors using co-training[C]//Proceedings of IEEE International Conference on Computer Vision,Nice,France,2003:626-633.
[25]Roth P,Grabner H,Skocaj D,et al.On-line conservative learning for person detection[C]//Proceedings of IEEE International Workshop on Performance Evaluation of Tracking and Surveillance,Breckenridge,Colorado,USA,2005:223-230.
[26]Wu Bo,Nevatia R.Improving part based object detection by unsupervised online boosting[C]//Proceedings of IEEE Conference on CVPR,USA,2007:1-8.
[27]Sharma P,Huang Chang,Nevatia R.Unsupervised incremental learning for improved object detection in a video[C]//Proceedings of IEEE Conference on CVPR,Providence,Rhode Island,USA,2012:3298-3305.
[28]Wang Meng,Wang Xiaogang.Automatic adaptation of a generic pedestrian detector to a specific traffic scene[C]// Proceedings of IEEE Conference on CVPR,Colorado Springs,CO,USA,2011:3401-3408.
[29]Wang Meng,Li Wei,Wang Xiaogang.Transferring a generic pedestrian detector towards specific scenes[C]//Proceedings of IEEE Conference on CVPR,Providence,Rhode Island,USA,2012:3274-3281.
[30]Liang Feidie,Tang Sheng,Wang Yu,et al.A sparse coding based transfer learning framework for pedestrian detection[C]//Proceedings of International Conference on Multimedia Modeling,Huangshan,China,2013:272-282.
[31]Cao Xianbin,Wang Zhong,Yan Pingkun,et al.Transfer learning for pedestrian detection[J].Neurocomputing,2013,100:51-57.
[32]陶剑文,王士同.多核局部领域适应学习[J].软件学报,2012,23(9):2297-2310.
[33]Duan Lixin,Tsang I W,Xu Dong.Domain transfer multiple kernel learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(3):465-479.
[34]黄育钊.基于样本迁移的多核学习算法研究[D].广州:中山大学,2010.
[35]Tang K,Ramanathan V,Li Feifei,et al.Shifting weights:adapting object detectors from image to video[C]//Proceedings of IEEE Conference on Neural Information Processing Systems,Lake Tahoe,Nevada,USA,2012:647-655.
[36]张倩,李海港,李明,等.基于多源动态TrAdaBoost的实例迁移学习方法[J].中国矿业大学学报,2014(4).
[37]于立萍,唐焕玲.基于分类一致性的迁移学习及其在行人检测中的应用[J].山东大学学报:工学版,2013,43(4).
[38]谢尧芳,苏松志,李绍滋.基于稀疏编码的迁移学习及其在行人检测中的应用[J].厦门大学学报:自然科学版,2010,49(2):186-192.
[39]刘扬,程健,卢汉清.基于目标局部特征的迁移式学习[C]//中国图象图形学会.第十四届全国图象图形学学术会议论文集.北京:清华大学出版社,2008.
[40]Wang Xiaoyu,Hua Gang,Han T X.Detection by detections:non-parametric detector adaptation for a video[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,Providence,Rhode Island,USA,2012:350-357.
[41]Pang Junbiao,Huang Qingming,Yan Shuicheng,et al. Transferring boosted detectors towards viewpoint and scene adaptiveness[J].IEEE Transactions on Image Processing,2011,20(5):1388-1400.
[42]张景祥,王士同,邓赵红,等.融合异构特征的子空间迁移学习算法[J].自动化学报,2014,40(2):236-246.
[43]戴文渊.基于实例和特征的迁移学习算法研究[D].上海:上海交通大学,2008.
SHAO Song1,2,LIU Hong1,2,WANG Xiangdong1,2,QIAN Yueliang1,2
1.Research Center for Pervasive Computing,Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
2.Beijing Key Laboratory of Mobile Computing and Pervasive Device,Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
Pedestrian detection is an active area of research with challenge in computer vision.In recent years,pedestrian detection based on machine learning has achieved great development.However,since data of various application scenes are under different data distributions,the performance of a well-trained detector drops significantly in a new scene.In order to avoid the effort of manual labeling and make full use of the original detector and labeled samples,pedestrian detection based on transfer learning has attracted more and more attention.This paper reviews pedestrian detection based on transfer learning,involving sample collection,transfer learning and detector optimization.Recent research on this topic is summarized and compared in different ways.Future directions are discussed.
pedestrian detection;detector;transfer learning;domain adaptation
行人检测是计算机视觉的研究热点和难点,近年来基于机器学习的行人检测技术取得了长足的进步,但由于不同场景的数据分布存在差异,已有检测器在新场景下的行人检测性能出现显著下降。为了避免繁琐的人工标注,充分利用原有检测器和标注样本,基于迁移学习的行人检测研究受到越来越多的关注。对其中涉及到的样本获取、迁移学习机制等关键技术进行综述,并从多个角度对现有方法进行分析和比较,最后对该技术的未来进行展望。
行人检测;检测器;迁移学习;场景自适应
A
TP391
10.3778/j.issn.1002-8331.1311-0358
SHAO Song,LIU Hong,WANG Xiangdong,et al.Review of pedestrian detection based on transfer learning.Computer Engineering and Applications,2014,50(24):156-163.
国家自然科学基金(No.61202209);北京市自然科学基金(No.4142051)。
邵松,硕士研究生,主要研究方向为视频图像中的目标检测、模式识别;刘宏,通讯作者,博士,副研究员,硕士生导师,CCF高级会员,主要研究方向为视频图像处理、模式识别和智能人机交互;王向东,博士,高级工程师,主要研究方向为智能人机交互、模式识别;钱跃良,正高级工程师,主要研究方向为智能人机交互、多媒体技术。E-mail:hliu@ict.ac.cn
2013-11-25
2014-06-06
1002-8331(2014)24-0156-08
CNKI网络优先出版:2014-07-11,http∶//www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1311-0358.html
猜你喜欢
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中国交通信息化(2017年9期)2017-06-06
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
工业设计(2016年11期)2016-04-16
电测与仪表(2014年15期)2014-04-04
河南科技(2014年22期)2014-02-27
食品科学(2013年8期)2013-03-11
