
使用LSA降维的改进ART2神经网络文本聚类
2014-08-05 02:40徐晨凯高茂庭
计算机工程与应用 2014年24期
徐晨凯,高茂庭
上海海事大学 信息工程学院,上海 201306
使用LSA降维的改进ART2神经网络文本聚类
徐晨凯,高茂庭
上海海事大学 信息工程学院,上海 201306
1 引言
随着网络信息的快速增长,每天发布的文本数量呈指数级增长,提供一种有效的文本组织方式显得日趋重要,而文本聚类可以对文本数据进行较为科学合理的聚类分析和处理,能够有效地帮助人们去获取想要的各种信息。
一方面,文本通常采用G.Salton等人提出的向量空间模型[1](Vector Space Model,VSM)来表示,并通过如TD-IDF算法[2]来提取特征词的权重,从而形成文本集的矩阵表示。由于文本中出现的单词众多,文本特征矩阵往往表现出巨大的维数,从而导致维数灾难,文本聚类计算复杂,一些经典统计算法无法适用等。解决这些问题的一种有效办法就是先对数据进行降维处理。目前,人们已经提出了许多降维方法,如:主成分分析PCA、独立成分分析ICA、隐含语义分析LSA[3],其中隐含语义分析LSA根据矩阵奇异值分解理论达到快速降维,是一种较为有效的降维方法。
另一方面,为了对文本数据进行有效的聚类处理,人们已经使用了许多有效的聚类方法,如经典的k-means聚类算法[4]、基于SOM神经网络[5]的文本聚类算法等。但这些方法往往需要大量的先验知识来确定聚类簇数目,无法动态学习,对于新向量的学习会影响到已经学习的向量等问题。而根据自适应共振理论提出的ART2神经网络[6-8](简称ART2网络)可以有效地动态学习,并且实现记忆和学习的平衡,还能自适应地确定聚类的数目。但ART2网络依然存在值得改进的地方,如对数据的输入敏感将会极大影响ART2网络的聚类结果[9-14]。
针对以上问题,本文提出一种基于最近邻关系重组数据的改进ART2网络,在不失动态性的同时,有效地降低了ART2网络对数据输入的敏感性,并将LSA理论[3]与这种改进的ART2网络[7-8]相结合实现文本聚类。先运用LSA理论对文本特征矩阵进行降维处理,再运用改进后的ART2网络进行文本聚类。实验表明,该方法不仅能够快速对文本进行聚类,准确度较高,自动地确定文本聚类簇数目,同时还有效地降低了ART2网络对样本输入顺序的敏感性。由于常用的聚类距离有欧氏距离和余弦距离等,而在文本聚类中余弦距离往往比欧氏距离有更好的聚类效果[15],所以本文所使用的距离是余弦距离,并用距离简称。
2 ART2型神经网络基本原理
2.1 ART2神经网络模型
本文使用的ART2网络结构是文献[8]中使用的网络结构,如图1所示。

图1 ART2神经网络结构
ART2神经网络一般都由注意子系统[7](Attentional Subsystem)和定向子系统[7](Orienting Subsystem)两大部分组成,而注意子系统又包括F0、F1和F2三层。对于一个未被归类的输入信号向量I0,通过F0层的放大增益信号,抑制噪声,得到处理后的信号I作为F1层和定向子系统的输入向量。F1层得到F0层的输入向量之后,将F0层的输入向量存储在F1层的STM中,通过非线性变化函数抑制噪声,放大有用信号,经过多次迭代达到稳定后,将所得向量通过F1→F2的LTM,激活F2层的神经元并得到胜利神经元,胜利神经元通过F2→F1的LTM将反馈信息返回给F1层。F1层得到反馈向量后,再次通过非线性变化函数得到稳定的F1层输出向量输出到定向子系统。定向子系统得到F0和F1层的输出向量后,通过距离计算公式和警戒阈值 ρ,决定是抑制胜利神经元,发出reset信号,重新进行搜索还是让胜利神经元进入学习阶段。
2.2 ART2学习方法讨论
对于ART2网络,传统的学习方法主要有快速学习方法,慢速学习方法以及折中学习方法。由于在一般常见学习方法中,F2→F1的LTM权值学习方法和对F1→F2的LTM权值学习方法一样,所以这里只写出F2→F1的LTM权值的学习方法。
快速学习方法公式[7]如下:

其中,J代表胜利神经元的编号,i代表该神经元LTM的第i个分量,k为学习次数,下同。由式(1)可以得出,胜利神经元学习后的权值完全只与新输入的输入信号向量相关,而与之前所学习的输入信号向量无关。虽然这种方法可以快速使胜利神经元的LTM权值达到收敛,但是也导致该胜利神经元的LTM在一定程度上受到噪声的影响[8]。
慢速学习方法公式[7]如下:
由式(10)可以得出,慢速学习方法是一个有权重的学习方法,而由于0<d<1[7],所以神经元的LTM更偏向于最近学习的信号向量。又由式(10)可得:

因为U1向量在 F0层已经进行了归一化操作,所以||U1||的值为1,又因为0<d<1[7],则0<1-d+d2<1,随着k→ +∞,(1-d+d2)k→0,即||ZJ(k)||≤1/(1-d),由于在F1层凡是小于θ的分量都被去除,而θ≥0,所以往往都有输入向量距离在0到1之间,则此时有||ZJ(k)||→1/(1-d)。
折中学习方法公式[8]如下:
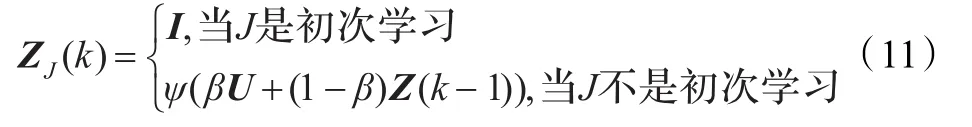
其中ψ为归一化运算,β为0到1之间的一个参数。
由式(1)(10)(11),可以总结出传统ART2网络的学习算法都是非等权重的学习方法。
在许多研究中都使用了一种较为常用的等权重学习方法来减缓向量偏移的问题[10-11]:
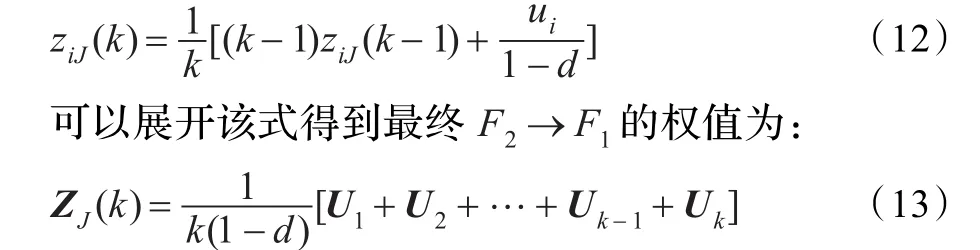
其中k为学习次数。由上述可知||ZJ(k)||<1/(1-d),但是显然||ZJ(k)||的值并非是个定值而是随着U1,U2,…,Uk之间的夹角变化。该学习方法可以算是一种慢速学习方法,而文献[8]中的方法要求每次学习完||ZJ(k)||为一个定值,所以无法利用文献[8]的原理进行步骤上的优化。
本文使用的是一种折中学习方法:

其中,e→0主要防止除0错误所以往往取非常小的数值,在计算中可以忽略,WJ(k)为额外的一个向量,由于存放所有归类在该神经元下的向量和。由式(15)可得,由于e→0,则||WJ(k)||可近似看成是1,为一个恒定值,这就满足了文献[8]提出的快速收敛,随着学习又可以调整的要求。则根据文献[8]的方法,由于原距离计算函数的主要变量为F2→F1的LTM权值以及两个向量之间的余弦距离,而由式(15)可得,F2→F1的LTM权值为一个定值,所以可以将原距离计算函数更改为计算余弦距离,又因为在计算胜利神经元时,此时输入向量U以及F1→F2的LTM权值都是经过归一化处理之后的向量,所以两个向量的内积即为其余弦距离,故当第一个胜利神经元未满足阈值ρ,其余神经元也定无法满足阈值 ρ,故可直接建立新神经元,从而避免了重新搜索阶段,加快了向量的归类过程并去除了参数c和d[8],而ART2网络具体运算步骤与文献[8]的一致。
3 基于LSA降维方法
隐含语义分析是一种用于知识获取和展示的计算理论和方法[3]。它主要通过奇异值分解来实现降维,并因此能够凸显出文本特征矩阵向量间隐含的语义特征。
设W为m×n的词条-文本矩阵,其中,m为词条个数,n为文本个数,则对于矩阵W,可以进行奇异值分解,得到:

其中,U和V矩阵被称为W的左、右奇异矩阵,Σ为一个对角矩阵,对角线上的每个元素为W的奇异值,并且按递减顺序排列。通过取前r个大的奇异值,并将U与V所对应的r个奇异向量,构建W的r-秩近似矩阵Wr:

其中,Ur矩阵中的行向量对应原矩阵W的r个主要的词向量,Vr矩阵中的行向量对应原矩阵W的文本向量。
这样,当使用W 文本矩阵进行聚类时,通过计算WT在Ur矩阵中r个行向量上的投影从而达到降维目的,具体变换方法如下:

其中,W*表示的是降维后的文本-词条矩阵,W表示原词条-文本矩阵。
4 基于LSA的ART2神经网络文本聚类
4.1 ART2神经网络的不足
由于ART2网络的神经元LTM的初始权值实际上是由样本输入顺序决定的,而初始LTM的权值又影响神经元之间的竞争,从而导致ART2网络的稳定性降低,产生对输入样本顺序敏感的现象。
设有一组平面上的数据点,类1的数据结点集为{(cos16°,sin16°),(cos20°,sin20°),(cos24°,sin24°),(cos28°,sin28°),(cos32°,sin32°)},类2的数据结点集为{(cos45°,sin45°),(cos55,sin55°),(cos65°,sin65°),(cos70°,sin70°)},如图2所示,采用k-means算法[4]对该数据进行聚类分析可以得到较为理想的聚类结果。
采用ART2网络进行聚类,由于数据(cos45°,sin45°)和(cos70°,sin70°)的距离为cos25°,若期望ART2网络分出同样聚类效果,则需取到合适的ρ使得数据(cos45°,sin45°)和(cos70°,sin70°)能被放入到同一个类簇,通过计算可以得到 ρ至少为cos16°,而数据(cos45°,sin45°)和(cos32°,sin32°)的余弦距离为cos13°,所以无论如何选取 ρ,只要数据(cos45°,sin45°)和(cos70°,sin70°)能归为同一类簇,那么数据(cos45°,sin45°)和(cos32°,sin32°)也显然可以通过改变顺序归为同一类簇。若此时数据输入顺序为{(cos45°,sin45°),(cos32°,sin32°),(cos65°,sin65°),(cos55°,sin55°),(cos70°,sin70°),(cos16°,sin16°),(cos20°,sin20°),(cos24°,sin24°),(cos28°,sin28°)},则会出现当(cos45°,sin45°)输入时,由于学习的向量为(cos32°,sin32°),则两者之间的距离满足阈值ρ,则此时出现如图3情况。
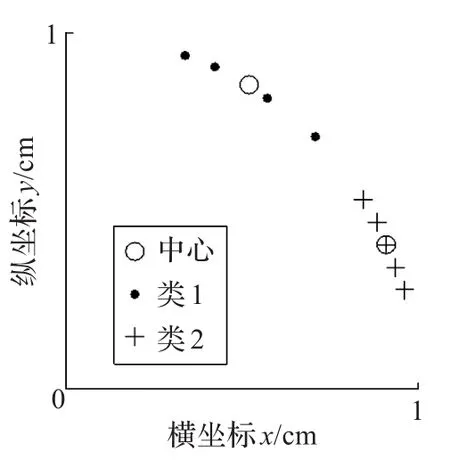
图2 k-means聚类结果

图3 学习向量(cos32°,sin32°)后
随后,对向量(cos65°,sin65°)进行聚类,由于其与由(cos45°,sin45°),(cos32°,sin32°)所组成的类的中心向量的余弦距离均不满足阈值 ρ,所以将在F2层生成一个新的神经元如图4情况。
之后,(cos55°,sin55°),(cos70°,sin70°)分布在向量(cos65°,sin65°)两侧,且距离类2的神经元更近且其距离值满足阈值 ρ,则都分别归类到类2中。最终当所有结果学习完成之后,所得结果最终聚类结果如图5。根据图5所示,可以发现,虽然ART2网络最终获得的聚类簇个数比预期的要多,但是聚类准确率却并未提高。而事实上,若原始数据按{(cos45°,sin45°),(cos55°,sin55°),(cos65°,sin65°),(cos70°,sin70°),(cos16°,sin16°),(cos20°,sin20°),(cos24°,sin24°),(cos28°,sin28°),(cos32°,sin32°)}的顺序输入之后,也能得到与k-means聚类结果一致的聚类结果。

图4 学习向量(cos65°,sin65°)后

图5 最终聚类结果
4.2 原因分析
之所以k-means聚类算法具有比ART2网络有更好的聚类结果,一方面,k-means聚类算法初始中心向量往往是通过一些方法获取的,而不是简单的由顺序来决定初始中心向量,从而减弱了对数据输入顺序的依赖;而ART2网络的神经元初始LTM权值从本质上直接依赖于数据的输入顺序,改变数据的输入顺序就可能完全改变了ART2网络的神经元初始LTM权值,若初始的LTM权值介于类与类之间,从而导致一些不同类的边缘元素在竞争中以该错误的神经元为胜利神经元,又由于是不同类的元素,所以该神经元的LTM权值未必能向某个类的特征方向收敛,从而导致聚类结果不佳。另一方面,k-means聚类算法都是初始中心向量个数固定,由于真实的实际数据当具有一定数量之后,不同类的数据确实有不同特征趋势的统计特征,从而使得k-means聚类算法的中心向量向某个类的特征方向收敛,通过不断地迭代,从而使中心向量逐渐收敛从而获得较好的聚类结果;相反,在ART2网络中,若恰好原本具有漂移趋势的中心向量由于新的中心向量产生而被取代,从而使得新的中心向量向某个类的特征中心收敛,而原本的中心向量保持不变,而ART2不会删除神经元,这样就导致ART2网络无论如何迭代,都无法优化聚类结果,同时又增加了聚类类别的个数。
4.3 改进思路
本文根据实体对象往往与其最近邻实体对象更可能是同一类别这一假设,通过最近邻关系来动态地调整输入到ART2网络中信号向量的所属神经元,使最终聚类结果更加稳定准确。
4.4 最近邻重组步骤
本文为ART2网络额外添加一个最近邻关系表,其表内每个结点对应一个输入信号量,其中存放当前所有输入信号向量之间的最近邻关系,并且随着后续信号向量输入动态维护该表。其主要包含当前结点的最近邻结点在表中的位置,与该最近邻的距离值以及一张链表,该链表主要存放以当前结点为最近邻的结点所在表中位置信息。而维护过程中需要使用一个栈和一张表来记录所要处理的结点,该表称为待处理表,栈称为遍历栈。具体步骤如下:
步骤1对新输入的信号向量,依次计算其与之前的信号向量的距离,若某个旧信号向量的最近邻距离大于新信号量与该信号量的距离,则将该信号量的最近邻位置更改为新信号量的位置,其最近邻值改为与新信号量的距离值,并将该信号量位置信息插入到新信号量的链表中。
步骤2通过依次计算之前所有信号向量的距离,将所得到新信号量的最近邻位置信息及其距离值写入到新信号向量的结点最近邻关系表中。
步骤3将新信号向量的结点添加到待处理表中,并将该结点压入遍历栈中。
步骤4若栈不空,取出栈顶结点元素,执行步骤6,否则执行步骤5。
步骤5依次遍历所得结点元素内链表中的所有结点,查看链表内结点所对应的最近邻关系表中的结点的最近邻是否为当前所得结点,若是,则将当前访问的链表元素放入到待处理表中并将其放入栈中,将其所在的ART2网络对应神经元的LTM权重减去其所对应的信号向量权重,若不是则将其从该链表中删除,直至访问完链表元素后执行步骤4。
步骤6将所得待处理表内结点所对应信号向量权值相加,归一化后作为新的输入,输入到ART2网络中,将待处理表内结点所对应信号向量归到最终满足阈值ρ的获胜神经元中。
步骤7将新信号向量所对应结点插入到其最近邻所对应结点的链表中,将待处理表清空。
如上例中,当向量(cos65°,sin65°)进入ART2学习之后,虽然此时的情况如之前未修改的ART2网络结果相同,但是当之后的向量(cos55°,sin55°)进入学习之后,由于向量(cos45°,sin45°)距离(cos55°,sin55°)更近,从而改变了(cos45°,sin45°)的最近邻,而(cos32°,sin32°)的最近邻依然是(cos45°,sin45°),所以将(cos32°,sin32°)和(cos45°,sin45°)同时从原神经元中移除,此时该神经元的LTM权值降为0相当于被删除。而(cos32°,sin32°)和(cos45°,sin45°)与向量(cos55°,sin55°)合并计算出中心向量作为ART2神经网络的新输入进行学习,显然此时网络只剩下向量(cos65°,sin65°)所在的神经元,并且其距离满足阈值 ρ。虽然此时,向量(cos32°,sin32°)被误分,但是随着后续向量的进一步学习,当向量(cos28°,sin28°)进入时,由于此时(cos32°,sin32°)的最近邻变成(cos28°,sin28°),从而在原神经元中被移除,而(cos45°,sin45°)的最近邻依然保持不变,故只有(cos32°,sin32°)和(cos28°,sin28°)合并成为新的输入,输入到ART2网络中,并最终归到正确的神经元中,经过改进后的ART2网络所得聚类结果与k-means结果一致,比起未改进的ART2网络所得聚类结果更加正确及稳定。
4.5 基于LSA的改进ART2神经网络文本聚类步骤

步骤1将所要聚类的文本向量通过投影矩阵,投影到降维后的向量空间中。
步骤2将所得投影后的降维向量输入到改进后的ART2神经网络中,进行归类与学习。
步骤3将在同一个输出神经元上获胜的所有输入文本向量归为一类,并将此结果作为最终聚类结果输出。
4.6 算法复杂度分析
在预处理过程中,将会使用LSA来获取用来投影的投影矩阵,其中SVD分解需要花费一定时间,但SVD算法已经较为成熟,一般需要O(n3)的时间复杂度,但由于该操作只在预处理过程中进行,所以只需要一次获取投影矩阵即可,故时间开销可忽略。
在ART2神经网络聚类过程中,由于先要维护最近邻表,所以需要O(n)的计算时间,之后需要抽取出相应的最近邻关系,这里使用邻接表数据结构进行优化,将最近邻表变成了最近邻树从而只需要沿指针遍历即可,所以问题即为遍历一棵树,其时间复杂度为O(n),而对于一个新输入的信号向量,由于本文无需重新搜索,大大加快了聚类速度,故只需要常数步定可将一个信号向量归类到一个神经元中,而计算胜利神经元的时间复杂度至多为n次,所以最终复杂度为O(n),而上述每个步骤都是顺序执行,所以对于一组n个文本向量的聚类时间复杂度为O(n2)。
在空间复杂度上,由于使用了邻接表来优化时间并且保存最近邻关系,所以其空间复杂度为O(n2),而由于最近邻重组时需要使用之前输入的信号向量,所以需要保存之前的信号向量,其复杂度为O(nm)。
5 实验分析
为了验证本文提出的改进算法对于文本聚类的有效性以及对顺序敏感性的减弱,设计了3组对照实验,实验文本采用海量公司中文智能分词产品[17]进行预处理,共5类486篇。实验1中数据按类顺序输入,实验2改变了样本的输入顺序,按随机顺序。实验3将文本数据分两次输入,第一次输入先抽取出286篇文本,并通过LSA计算得到投影矩阵,降维并进行聚类,之后将剩余200篇通过之前得到的投影矩阵降维后,作为第二次输入进行聚类。实验1主要验证本文算法能够准确有效地进行聚类分析,通过LSA降维之后,能够凸显出语义关系,减少噪声,突出最近邻关系的准确性,从而能够提高聚类结果的准确性;实验2验证本文算法能够有效地减弱聚类结果对样本输入顺序的敏感;实验3验证各聚类算法的动态性。
为了衡量算法最终所得聚类结果的准确性,本文采用准确度衡量方法,该方法较为直观,比较容易理解,计算方法如下:
p=聚类簇正确数据点数/实际该类数据点总数
本文采用基于余弦距离的k-means算法[4]、ART2网络[8]与本文改进算法进行对比,所得实验结果如表1所示。本文所使用的ART2网络的参数设置[12]为a=100,b=100,θ=0.001。
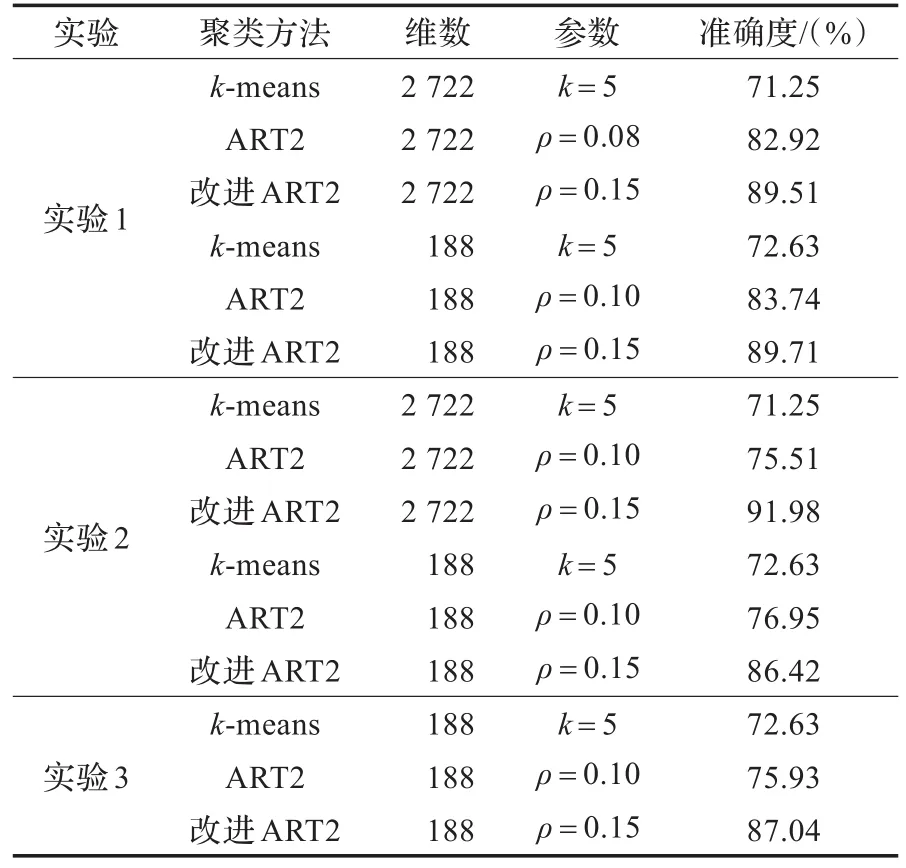
表1 实验结果
(1)通过比较聚类算法在未降维和经过LSA降维之后的聚类结果可得,LSA降维之后可以突出潜在文本隐含语义,加强相同聚类簇实体的相似性及不同聚类簇实体间的差异,使得聚类分析结果更加准确,并且数据降维能有效地降低计算复杂度,从而加快聚类算法的处理速度。
(2)通过实验1和实验2可得,改进后的ART2网络能大大提高传统ART2网络的稳定性及准确性,并且其准确性比k-means算法高而稳定性与k-means算法相近。由于k-means算法通过全局迭代并以最小二乘方作为评价函数,聚类结果对顺序的依赖非常小,而由上分析可得数据输入顺序直接决定了ART2网络的LTM初始值,故其对数据输入顺序的依赖较大,而在引入最近邻重组后,改进的ART2网络有效地减弱了对于输入顺序的依赖。
(3)由实验3可得,只要在同一个向量空间的数据ART2网络以及改进后的ART2网络都可以在原有基础上进行聚类,而k-means算法无法实现。由于ART2网络及改进后的ART2网络的聚类分析实际上是由数据与神经元之间关系确定,从而可在原有聚类基础上进行再次聚类,而k-means算法对新的数据需要采用全局迭代过程才能最终确定聚类结果。
从实验结果可以得出,改进后的ART2网络在聚类结果的准确性和稳定性均优于传统ART2网络的聚类结果。
6 结束语
本文研究表明,使用ART2网络进行文本聚类,能够有效和动态地对文本数据进行聚类分析。但一方面由于文本数据的高维性,所以结合LSA合理地进行降维能够更好地得出聚类结果,另一方面ART2网络为了实现动态性,在一定程度上牺牲了稳定性,所以在低阈值的情况下,表现出对输入顺序的敏感。本文通过最近邻关系重组,在一定程度上改善了这个问题并且保留了ART2网络的高动态性,但仍然有较多的问题遗留等待研究:
(1)由于ART2网络能够自动生成聚类个数,所以实现无需估计聚类个数。而ART2网络的聚类个数主要是由警戒阈值 ρ决定,而如何确定警戒阈值目前还只能通过统计,或者多次测试等手段获取,如何更方便地获取有效的警戒阈值ρ是一个值得研究的方向。
(2)由于最近邻关系是一种全局关系,所以能够在一定程度上确定实体之间的关系,而不依赖输入顺序的改变,但是最近邻关系并不是一种严格的全局关系,当存在“平局”现象时,则此时即使是最近邻关系依然依赖输入顺序,所以如何更好地解决这种“平局”现象使实体之间的关系更加确定也是一个需要研究的问题。
(3)LSA理论是一种有效的降维方法,不仅能够有效减弱原文本-词条矩阵中包含的“噪声”因素,使文本和词条之间的语义关系更加凸现出来;而且降维后使文本-词条向量空间大大缩减,减少了数据计算量,从而提高文本聚类的处理效率。但是由于文本间的相互关联性较为复杂,文本特征的高维性,如何合理地选取文本特征、确定降维规模、有效地处理文本的多个主题仍然是一个值得研究的问题。
[1]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[2]Salton G,Buckley C.Term-weighting approaches in automatic text retrieval[J].Information Processing and Management,1988,24(5):513-523.
[3]Landauer T K,Foltz P W,Laham D.An introduction to latent semantic analysis[J].Discourse Processes,1998,25(2/3):259-284.
[4]Han Jiawei,Kamber M.Data mining:concepts and techniques[M].USA:Morgan Kaufmann,2001.
[5]Kohonen T,Somervuo P.Self-organizing maps of symbol strings[J].Neuro Computing,1998,26(5):19-30.
[6]Carpenter G A,Grossberg S.A massively parallel architecture for a self-organizing neural pattern recognition machine[J].Computer Vision,Graphics and Image Processing,1987,37(1):54-115.
[7]Carpenter G A,Grossberg S.ART-2:self-organization of stable category recognition codes for analog input pattern[J].Applied Optics,1987,26(23):4919-4930.
[8]Carpenter G A,Grossberg S,Rosen D B.ART2-A:an adaptive resonance algorithm for rapid category learning and recognition system[J].Neural Network,1991,4:493-504.
[9]叶晓明,林小竹.慢速权值更新的ART2神经网络研究[J].计算机工程与应用,2010,46(24):146-150.
[10]韩小云,刘瑞岩.ART-2网络学习算法的改进[J].数据采集与处理,1996,11(4):241-245.
[11]刘力,胡博,史立峰.ART2神经网络综述[J].中南大学学报:自然科学版,2007,38(1):21-26.
[12]谌海霞.ART2网络的学习速率调整及其影响[J].微电子学与计算机,2008,25(9):147-150.
[13]吕秀江,王鹏翔,王德元.基于ART2神经网络算法改进的研究[J].计算机技术与发展,2009,19(5):137-139.
[14]顾民,葛良全.一种ART2神经网络的改进算法[J].计算机应用,2007,27(4):945-947.
[15]高茂庭,王正欧.基于LSA降维的RPCL文本聚类算法[J].计算机工程与应用,2006,42(23):138-140.
[16]林鸿飞.基于实例的文本标题分类机制[J].计算机研究与发展,2001,38(9):1132-1136.
[17]海量公司.中文智能分词[EB/OL].[2012-12-20].http://www. hylanda.com/dowmload/segment/.
XU Chenkai,GAO Maoting
College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China
In order to realize dynamic clustering for high-dimensional text data,an improved ART2 neural network text clustering algorithm based on Latent Semantic Analysis(LSA)is proposed,which emerges the semantic relations between texts and terms and reduces the noises,the dimensionality and the computation complexity by LSA.The new algorithm uses an improved intermediate learning method to simplify calculating procedures and accelerate the computation of the ART2 network,and uses the nearest neighbor reformation to improve the stability and weaken the dependence of samples order for the ART2 network clustering.Experiments demonstrate that this improved algorithm can realize dynamic text clustering effectively.
ART2 neural network;nearest neighbor;Latent Semantic Analysis(LSA);dimensionality reduction;text clustering;clustering analysis
针对文本数据高维度的特点和聚类的动态性要求,结合隐含语义分析(LSA)降维,提出一种改进的ART2神经网络文本聚类算法,通过LSA凸显文本和词条之间的语义关系,减少无用噪声,降低数据维度和计算复杂性;采用改进的折中学习方法,减少计算步骤,加快ART2神经网络计算速度,并利用最近邻动态重组方法提高ART2网络聚类的稳定性,减弱算法对样本输入顺序的依赖。实验表明,改进的文本聚类算法能有效地实现动态文本聚类。
ART2神经网络;最近邻;隐含语义分析(LSA);降维;文本聚类;聚类分析
A
TP183
10.3778/j.issn.1002-8331.1302-0109
XU Chenkai,GAO Maoting.Improved ART2 neural network for text clustering based on LSA.Computer Engineering and Applications,2014,50(24):133-138.
上海市科委科技创新项目(No.12595810200);上海海事大学科研项目(No.201100051)。
徐晨凯(1989—),男,硕士研究生,CCF学生会员,主要研究领域:数据挖掘;高茂庭(1963—),男,博士,教授,系统分析员,CCF高级会员,主要研究领域:数据挖掘,数据库与信息系统。E-mail:kk9265w@gmail.com
2013-02-20
2013-04-11
1002-8331(2014)24-0133-06
CNKI网络优先出版:2013-05-13,http∶//www.cnki.net/kcms/detail/11.2127.TP.20130513.1601.002.html
猜你喜欢
车主之友(2022年4期)2022-08-27
自然杂志(2021年6期)2021-12-23
海峡姐妹(2019年12期)2020-01-14
现代装饰(2018年5期)2018-05-26
数学物理学报(2018年1期)2018-03-26
火控雷达技术(2016年1期)2016-02-06
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
燕山大学学报(2014年1期)2014-03-11
电子设计工程(2014年12期)2014-02-27
