
基于潜在语义索引的科技文献主题挖掘
2014-08-05 02:40朱芳芳
计算机工程与应用 2014年24期
刘 勘,朱芳芳
中南财经政法大学 信息与安全工程学院,武汉 430073
基于潜在语义索引的科技文献主题挖掘
刘 勘,朱芳芳
中南财经政法大学 信息与安全工程学院,武汉 430073
1 引言
目前,科技文献的数量正呈爆炸式增长,这给科技文献的有效检索带来了巨大的挑战,人们花费在文献检索上的时间越来越多,却仍然感到很难快速精确地检索到所需要的科技文献。本文引入主题建模的思想,通过对初次检索的科技文献集建立词汇-文献矩阵,引入潜在语义索引(Latent Semantic Indexing,LSI)方法来降低矩阵的维度,以发掘这些文献所蕴含的潜在主题,用户进而可以根据这些主题查找所需文献,大大提高文献检索的效率和准确度。
2 相关研究
1983年Gerard Salton和Michael J.McGill[1]提出的LSI是目前常用的潜在主题建模方法。Scott Deerwester等[2]将LSI方法用于检索分析,假设文本中的词与词之间存在某种潜在的语义结构,采用统计方法寻找这些潜在的语义结构,用来表示词、文本和用户检索信息,从而达到消除词与词之间的相关性、化简文本向量的目的。Thomas Hofmann[3]提出的Probabilistic Latent Semantic Indexing是一种基于混合分解的概率统计模型,可用于信息检索、信息过滤和自然语言处理。Padhraic Smyth[4]提出并行的自动文件索引方法。David Blei等[5]提出的LDA是一种生成离散数据集合的三级分层贝叶斯模型。这些主题挖掘方法的中心思想是将从文本提取的主题词集中的每个词作为一个主题有限混合模型,而每个主题是无限混合的潜在主题的概率模型,这样可以通过主题概率建模,将文本映射到主题空间中,得到文本与主题的关系。
国内最早使用LSI进行索引的是化学资源导航系统ChIN,这是一个基于概念的全文检索系统[6]。之后被不断地改进应用于文本摘要[7-8]、文本分类[9-12]、文本聚类[13]、文本分析[14-16]等各种领域,并且应用范围不断增加。各种知识如SVM[10]和Rough[11]等被用来改进LSI得到更好的表示文本的模型。
但是,利用LSI进行主题挖掘时也存在一定的问题:一是LSI主要采用单值分解过程来降维,而LSI中矩阵表示文本时本身存在巨大的稀疏性,如果采用简单的权重表示特征词会使对分类贡献大的语义可能由于奇异值较小而被过滤;二是LSI挖掘主题时,新加入的文本无法直接计算,挖掘出来的主题不够紧凑,而且可读性不高,用户很难根据挖掘出来的主题来进行文献分类检索。
为了克服以上问题,减小LSI对科技文献主题挖掘的影响,本文采用一种改进的方法对科技文献的主题进行挖掘。科技文献本身的结构是基本固定的,一般由标题、摘要、关键词、正文和结论组成,考虑到各个特征词出现的位置不同而对文献重要性贡献的不同,采用位置加权的方法计算权重,避免了重要特征词可能被过滤的可能性。同时,根据Frobenius理论来对稀疏的文本矩阵进行降维,避免了奇异值分解算法的复杂性,也增强了文本挖掘计算的紧凑性。
3 科技文献的主题挖掘
3.1 主要思路
本文对科技文献进行主题挖掘主要分为三个部分,分别是数据预处理、构造矩阵和矩阵降维。首先对科技文献集进行预处理,删除无效字符后进行分词,去除停用词,构造出词条库。构造矩阵时要先计算词条库中特征词的权重,然后根据计算出来的权重构造词汇-文献矩阵。矩阵降维时采用改进的LSI算法,先是用线性组合的方法来表示词汇-文献矩阵A和词汇-主题矩阵X和主题-文献矩阵Y的关系。主题-文献矩阵Y开始是随机生成的,然后分别固定矩阵Y和矩阵 X,循环计算最后得到稳定的矩阵X和矩阵Y,此时的主题-文献矩阵Y中的每一列就代表了某篇科技文献的所有主题的概率分布,将其降序排列就可得到这篇科技文献面向各主题的重要程度,取出排在前面的n个主题(一般n取3~8)即为该文献的主题词。具体流程图如图1所示。
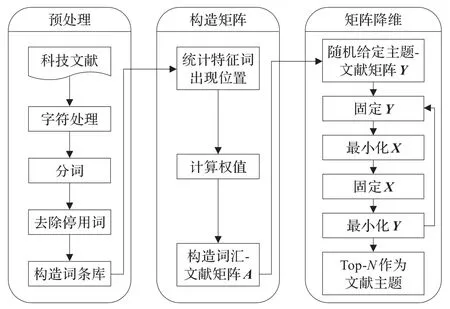
图1 科技文献主题挖掘流程示意图
3.2 预处理
数据预处理要进行的操作包括文本字符处理、分词、去除停用词、构造词条库等步骤。
3.2.1 字符处理
存储在数据库中科技文献的结构和格式都是有规则的,并没有异常值,在进行数据预处理的时候,不需要对文献进行规格化处理操作,直接进行数据清洗操作。去掉不可以作为特征词的字符、数字、连字符和标点。
3.2.2 分词
分词是将文献矩阵化处理特有的预处理步骤,为了提取科技文献中的文本特征词,把文献中的文字切分成有意义的词,提供给后续数据处理使用。
3.2.3 去除停用词
停用词是指在科技文献中出现频率太高,但携带信息较少,对科技文献主题挖掘没有贡献或者贡献太小的词。比如“的,是”等,这时需要对照停用词表消除这些表现力不强的停用词。去除停用词可以节省存储空间,降低计算量,使文本特征词更精炼准确。
3.2.4 构造词条库
经过上述操作后,对所有科技文献集中提取出来的特征词进行统计,排序,然后用这些特征词构造词条库。构造出的词条库中包含了所有的科技文献和进行预处理得到的所有特征词。
3.3 构造词汇-文献矩阵
3.3.1 科技文献表示方法
根据科技文献集构造出了词条库以后,首先采用空间向量模型(Vector Space Model,VSM)来表示,将科技文献看成是一组正交特征词构成的向量a=(a1,a2,…,am),其中,ai为特征词i的权值,表示特征词i在该科技文献中的重要程度。如果有n个科技文献,这n个科技文献总共有m个特征词,就可以构成一个二维的m×n的词汇-文献矩阵A。
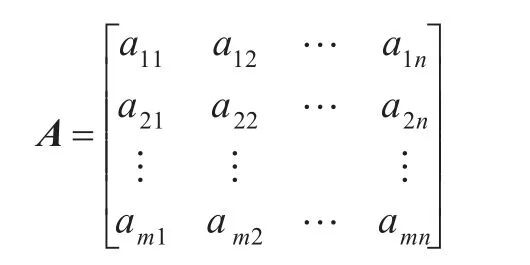
其中,矩阵A的每一行表示一个特征词,每一列表示一篇科技文献,第i行表示第i个特征词,第 j列表示第 j篇科技文献,aij表示第i个特征词在第 j个科技文献中的权值。
3.3.2 特征词权值计算
在词汇-文献矩阵中,矩阵中的每个元素表示这个特征词在文献中的重要程度。但是,同一特征词在科技文献中出现位置不同而对文献的贡献程度不同,在标题中最能反映文献的主题,在摘要、关键字和结论其次,在正文中次之,而在参考文献中重要性是最低的。所以,本文采用基于tf-idf的加权计算方法,考虑特征词在文献中出现的位置对权重的影响,根据公式(1)计算特征词的权重。
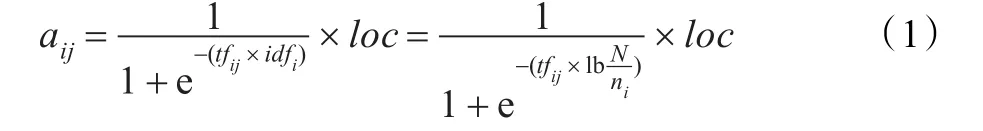
其中,tfij代表特征词i在科技文献 j中出现的频率,由特征词i在科技文献 j中出现的次数除以科技文献 j中的特征词的总数计算。idfi代表特征词i反比于特征词出现的文本频数,N表示科技文献集总数,ni表示含有特征词i的科技文献总数,loc表示特征词在文本中出现的位置。
本文设定标题的位置权重为2.5,摘要、关键字、结论的位置权重为1.5,正文权重为1。当同一个词汇出现在不同的位置时,则选取该词汇在文本中出现的位置权重最高的位置,如当词汇“人工智能”同时出现在标题、摘要、关键字、正文和结论中时,只取该词汇在标题中的权重,即“人工智能”这个特征词的loc=2.5。
3.3.3 构造词汇-文献矩阵
根据数据预处理得到的词条库和特征词权值,构造出词汇-文献矩阵A,矩阵A是一个稀疏矩阵,它表示科技文献和词条库中的特征词的关系。
3.4 LSI降维
3.4.1 LSI原理
LSI利用矩阵的奇异值分解来降低矩阵的维度,令A=LΣRT,其中,LLT=RTR=I,Σ=diag(δ1,δ2,…,δn)。L,R分别称为矩阵A的左右奇异矩阵,Σ称为矩阵A的奇异值标准形,Σ的对角元素被称为A的奇异值。矩阵 Σ是一个秩为r(r<m,n)的对角矩阵,对角线上的奇异值按大小降序排列,并且矩阵中的后m-r行数据都为0。LSI取矩阵Σ的前K个最大的奇异值,取L和R最前面的k个列和行来构建 A的k-秩近似矩阵 Ak,Ak=LkΣkRT
k,其原理如图2所示。

图2 LSI矩阵分解示意图
图2中,用Ak近似表示原来矩阵A,矩阵Lk中的行向量代表词汇矩阵,矩阵Rk中的列向量代表科技文献矩阵。通过奇异值分解和取k-秩近似矩阵,可以消减原来的词汇-文献矩阵A中包含的值为0的“噪声”因素,减少原矩阵的维度,缩减了向量空间,更加表现出特征词和科技文献之间的关系,提高主题挖掘的效率。
本文处理对象是由科技文献组成的文档集,以特征词在科技文献中出现的频率为依据,把这些训练文档表达为词汇-文献矩阵A(word-article),然后采用奇异值分解方法将矩阵A向主题空间进行投影,得到词汇-主题矩阵 X(word-topic)和主题-文献矩阵Y(topic-article)。其中,词汇-主题矩阵X(对应于左奇异矩阵)是特征词的潜在主题矩阵,矩阵中的值表示每个特征词在潜在主题的权值,根据矩阵 X可以得到训练文档集的主题。主题-文献矩阵Y(对应于右奇异矩阵)是科技文献在主题空间中的投影,根据矩阵Y可以看出每个主题在科技文献中的权重,就可以得到所有表示文献的主题,选取其中权重较高的主题作为科技文献的主题。
3.4.2 LSI方法的改进
LSI可以提高信息索引的性能,但LSI中必须进行的奇异值分解其计算复杂度高。本文另外运用一种改进的潜在语义索引方法进行主题建模[17]。这种方法在进行矩阵分解时,引入Frobenius范数[18],采用线性方法规则化矩阵得到新的矩阵。
这种改进的LSI方法的主要原理是通过线性组合方法对矩阵进行迭代分解来将词汇-文献矩阵A向主题空间进行投影,开始时随机给定一个主题-文献矩阵Y,暂时固定这个主题-文献矩阵Y,根据公式求出最小化的词汇-主题矩阵X,然后固定这个已求出的矩阵X,再求出最小化的主题-文献矩阵Y,反复迭代这两个步骤直到最小值不变,得到最终的词汇-主题矩阵X和主题-文献矩阵Y。更新X和Y时分别引入Frobenius范数的1-范式和2-范式来规则化矩阵,其中,用1-范式规范词汇-主题矩阵X,2-范式规范主题-文档矩阵Y,使得主题挖掘的范围扩大了,而且复杂度也降低了。LSI改进后的主要步骤如下:
步骤1科技文献的线性表示
如果训练文献集中有k个主题,则这k个主题可以表示为一个m×k的词汇-主题矩阵 X=[x1,x2,…,xk],其中,矩阵中的每一列代表一个主题,xi是一个m维的向量,表示第i个主题。用线性组合的方法来表示科技文献集如公式(2)所示。

其中,yn表示文献an在主题空间中的投影,ykn表示第k个主题xk在第n篇科技文献an中的权值。 ykn的值越大说明主题xk越能代表科技文献an。Y=[y1,y2,…,yn]是一个k×n的主题-文献矩阵,第n列 yn表示文献在潜在主题空间中的投影。
由于用公式(2)来表示文献集的线性之和是近似值,会产生误差值,引入范式来约束an与 Xyn的误差使得误差值最小,同时引入变量 f1和 f2来规范公式(2),得到公式(3):
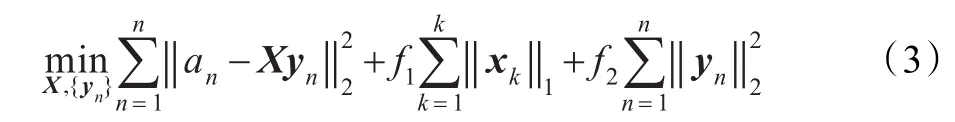
步骤2固定Y,更新X

而由于文献是相互独立的,则公式(4)中的m个词汇是独立的,每个词汇是矩阵X中的每一行,可以分成m次运算,其中每次运算可表示为:
其中,m=1,2,…,m。
将式(5)变换成一个可微分的二次函数,对这个二次函数求导并令它等于0,则可以得到当l≠k时(l=1,2,…,n),xmk的最小值,如公式(6)所示。
其中,vij和uij分别是k×k矩阵V=YYT和m×k矩阵U=AYT的第i行第 j列。
步骤3固定X,更新Y


步骤4主题提取
根据公式(6)和公式(7),迭代更新矩阵X和Y,直到矩阵 X和Y的值稳定,得到词汇-主题矩阵 X和主题-文献矩阵Y,矩阵Y中的每一列就代表一篇科技文献的所有主题,对矩阵中的数据进行降序排列,然后取权重最高的主题代表这篇文献的主题。
4 实验过程及分析
4.1 实验过程
4.1.1 数据来源
进行主题挖掘实验时,词条库的建立是非常重要的,在英文词条库建立方面,国外已经有了REUTER,TREC,OHSUMED等一些标准权威的语料库。而在中文词条库建立方面,目前还没有一个权威的中文文本语料库。因此,本文搜集了万方数据库知识服务平台上的相关论文来建立一个词条库。实验中采集了6个主题共800篇科技类文档,其中人工智能200篇、社交网络100篇、数据挖掘200篇、推荐系统100篇、下一代网络100篇、文本挖掘100篇,词汇共380 021个。
4.1.2 数据预处理
本文采用Visual Studio2010集成开发环境,C#语言进行编程,利用中国科学院计算技术研究所的开源中文分词组件ICTCLAS分词系统共享版进行中文分词,分词后去除停用词,进行词频统计,完成主题挖掘数据预处理过程。预处理后的结果如表1所示,然后设置阈值为2,去除出现频数小于2的特征词,构建出词条库。

表1 预处理结果
4.1.3 生成矩阵
利用权值计算公式(3),根据这些特征词在文中出现的位置计算特征词的权值。利用选取的特征词及其权值来表示文献集中的所有文献,构造出词汇-文献矩阵如表2所示。

表2 构造词汇-文献矩阵
4.1.4 对矩阵进行降维分解
取 f1=0.5,f2=1.0,对词汇-文献矩阵根据改进的LSI算法,利用公式(6)和公式(7)进行降维分解,分别生成词汇-主题矩阵X和主题-文献矩阵Y如表3所示。

表3 词汇-主题矩阵X和主题-文献矩阵Y
4.1.5 主题-文献矩阵Y的主题进行输出
根据矩阵降维后得到的主题-文献矩阵可以得到每篇文献的主题,表4表示的是输出每篇科技文献的前8个主题词(GB7713-8规定每篇文章应选取3~8个关键词,而实验也证明3~8个特征词已经能够表现出该科技文献的主题)。

表4 输出结果
由表4可以看出,这里运用改进的LSI方法得到的主题基本可以表达科技文献的主题,表中的第一列可以得到该文献的主题是有关推荐系统的,并且可以看出推荐系统类科技文献主要研究的是模型、算法和推荐系统的设计;第二列主题是下一代网络,这类文献关于网络协议以及体系结构的设计;第三列主题是人工智能,这类主题则主要集中在应用及算法和模型的研究;第四列是关于数据挖掘的主题,数据挖掘类科技文献集中在算法的研究与模型的应用上。
4.2 测试结果
实验中还将本文的方法与常规的LSI方法以及主题挖掘中常用的LDA方法进行了比较,得到了相应的结果,同时用实验挖掘出来的主题和人工统计出来的主题进行对比来衡量各方法的准确率,其结果如表5所示。
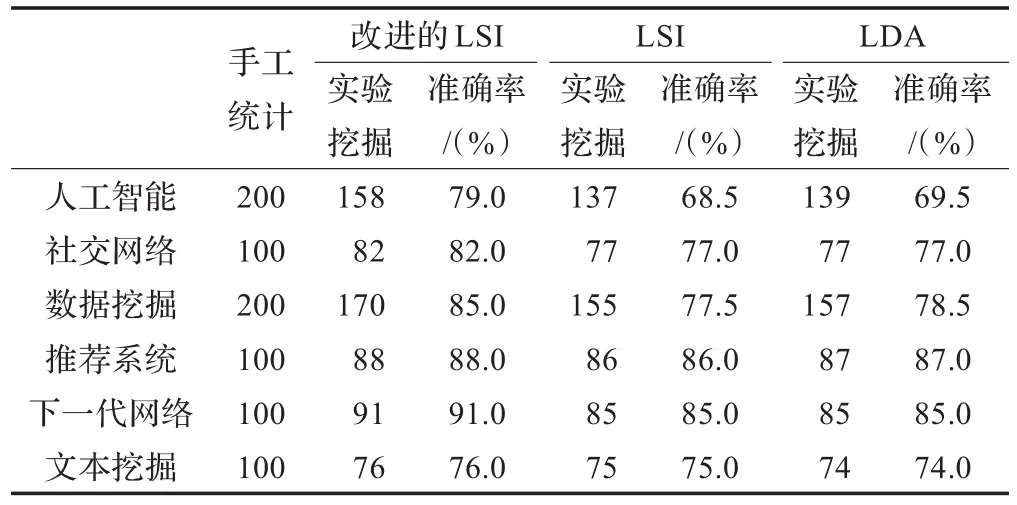
表5 测试结果
由表5可以看出,改进的LSI方法具有较高的准确率。相同数量的文献,含有更多专业词汇,且与主题相关的特征词出现在标题等权重较高位置的科技文献,主题会更明显,更容易被挖掘。而对于文本挖掘这类主题不明确的科技文献中,有一些主题词在文献的标题表述中没有出现,所以权重计算的时候,主题词的权值小于在标题中出现的特征词,而使得最后主题表示的时候没有被采用,导致没有挖掘出这个主题。
5 结论
本文研究了潜在语义索引方法对科技文献进行主题挖掘的方法,尝试了其中的改进方法,降低了LSI奇异值计算的复杂度,应用Frobenius范数理论对文献矩阵降维,简化了计算的难度,减少了部分噪音,简化了计算的过程,能更快地表示原始科技文献空间中的潜在语义结构。但是利用LSI方法进行科技文献的主题挖掘还处在初步的实验阶段,实验中删除的特征词可能会影响后期的主题提取,最后得到的结果其精度还不是特别令人满意,其中的原因值得探讨,也是下一步工作的重点。
[1]Salton G,McGill M J.Introduction to modern information retrieval[M].New York:McGraw-Hill,1983.
[2]Deerwester S,Dumais S T,Furnas G W,et al.Indexing by latent semantic analysis[J].J AM SOC INFORM SCI,1990,41:960-972.
[3]Hofmann T.Probabilistic latent semantic indexing[C]//Proceedings of the 22nd ACM SIGIR International Conference on Research and Development in Information Retrieval,1999:50-57.
[4]Asuncion A U,Smyth P,Welling M.Asynchronous distributed estimation of topic models for document analysis[J]. Statistical Methodology,2011,8(1):3-17.
[5]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[6]李晓霞,郭力.ChIN化学化工资源导航系统的新进展[J].计算机与应用化学,2002,19(1):139-143.
[7]林鸿飞,高仁璟.基于潜在语义索引的文本摘要方法[J].大连理工大学学报,2001,41(6):744-748.
[8]陈戈,段建勇,陆汝占.基于潜在语义索引和句子聚类的中文自动文摘[J].计算机仿真,2008,25(7):82-85.
[9]曾雪强,王明文,陈素芬.一种基于潜在语义结构的文本分类模型[J].华南理工大学学报:自然科学版,2004,32(z1):99-102.
[10]郭武斌,周宽久,张世荣.基于潜在语义索引的SVM文本分类模型[J].情报学报,2009,28(6):827-833.
[11]何明,冯博琴,傅向华.基于Rough集潜在语义索引的Web文档分类[J].计算机工程,2004,30(13).
[12]张秋余,刘洋.使用基于SVM的局部潜在语义索引进行文本分类[J].计算机应用,2007,27(6):1382-1384.
[13]陈毅恒,秦兵,刘挺,等.基于潜在语义索引和自组织映射网的检索结果聚类方法[J].计算机研究与发展,2009,46(7):1176-1183.
[14]林鸿飞,战学刚,姚天顺.基于潜在语义索引的文本分析方法[J].模式识别与人工智能,2000,13(1):47-51.
[15]王瑛.基于VSM的潜在语义索引[J].陕西科技大学学报:自然科学版,2010,28(5):151-158.
[16]杨雪敏,张毅坤,崔颖安.基于LSI的代码-文档可追溯关联挖掘研究[J].计算机工程,2011,37(8):34-36.
[17]Wang Q,Xu J,Li H,et al.Regularized latent semantic indexing[C]//Proceedings of SIGIR’11,Beijing,2011:978-988.
[18]方保镕,周继东,李医民.矩阵论[M].北京:清华大学出版社,2004:158-167.
LIU Kan,ZHU Fangfang
School of Information and Safety Engineering,Zhongnan University of Economics and Law,Wuhan 430073,China
Based on a method improved by Latent Semantic Indexing,a topic mining for scientific papers is proposed. This paper describes a process which is used to mine the topics of the scientific papers.It performs conversion,removes non-alphabetic and stop word before further processing.It constructs the term-document matrix based on all words’weight. It uses modified LSI algorithm to cut the dimension of the matrix and gets a new topic-document matrix.It takes the highest weight of the top five themes as the papers’topic.This method utilizes the Frobenius norm to regulate matrix,reducing the dimension of the matrix.So the theme of the scientific papers can be mined quickly and accurately.
latent semantic indexing;topic modeling;scientific documents
提出了一种基于潜在语义的科技文献主题挖掘方法,描述了科技文献的主题挖掘模型。对科技文献集进行预处理,计算特征词权重,构造出词汇-文献矩阵。用改进的LSI算法对稀疏矩阵进行降维得到固定的主题-文献矩阵。取权重最高的主题作为该文献的主题。该方法利用Frobenius范数来规范矩阵,对稀疏矩阵进行降维,可以快速精确地挖掘出科技文献的主题。
潜在语义索引;主题挖掘;科技文献
A
TP311
10.3778/j.issn.1002-8331.1305-0146
LIU Kan,ZHU Fangfang.Research of topic mining for scientific papers based on LSI.Computer Engineering and Applications,2014,50(24):113-117.
国家自然科学基金(No.71203164)。
刘勘,男,博士,副教授,研究领域为数据挖掘、语义检索、信息可视化等;朱芳芳,女,硕士研究生,研究领域为文本挖掘。E-mail:lkan@sina.com
2013-05-14
2013-06-30
1002-8331(2014)24-0113-05
CNKI网络优先出版:2013-09-04,http∶//www.cnki.net/kcms/detail/11.2127.TP.20130904.1344.014.html
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
开放教育研究(2020年2期)2020-03-31
中华胰腺病杂志(2019年4期)2019-08-29
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
现代语文(2016年21期)2016-05-25
中文信息学报(2015年4期)2015-04-21
大连民族大学学报(2015年2期)2015-02-27
中华胰腺病杂志(2012年3期)2012-11-07
