
基于稀疏编码的鲁棒说话人识别
2014-07-25 09:22:32何勇军孙广路付茂国韩纪庆
数据采集与处理 2014年2期
何勇军 孙广路 付茂国 韩纪庆
(1.哈尔滨理工大学计算机科学与技术学院,哈尔滨,150080;2.哈尔滨工业大学计算机科学与技术学院,哈尔滨,150001)
引 言
说话人识别在过去的几十年里受到了广泛关注,吸引了大量学者进行深入研究。传统方法比如高斯混合-通用背景模型(Gaussian mixture model-Universal background model,GMM-UBM)[1],高斯混合-支持向量机(Gaussian mixture model-sup-port vector machine,GMM-SVM)[2]和联合因素分析(Joint factor analysis,JFA)[3]等,在无噪的理想情况下取得了令人满意的识别率;然而在噪声环境[4]下其性能将急剧降低,这严重限制了说话人识别技术走向现实应用。
为解决这一问题,研究者们提出了大量方法,这些方法大致可分为两类。第一类是提取鲁棒特性,例如线性预测倒谱系数(Linear prediction cepstral coefficient,LPCC),梅尔倒谱系数(Mel-frequency cepstral coefficient,MFCC)[5]和感知线性预测系数(Perceptual linear predictions,PLPs)。特征类方法相对简单,计算复杂度低,可以集成在识别系统的前端,但其性能有限。因为目前还没有一种特征能有选择地只表示语音而不表示噪声。第二类方法则尝试首先去除语音中噪声,然后从增强后的语音中提取特征,典型的有谱减法和维纳滤波。然而,噪声常常是非平稳的,有些噪声甚至像语音,很难建模和估计。因此这类方法不可避免地会造成语音特征的进一步畸变。而现实情况是目前的说话人识别方法对这种畸变是非常敏感。因此,希望采用新技术来解决这个问题。
近年来,研究者们对稀疏编码[6]进行了广泛而深入的研究,为噪声环境下的说话人识别提供了可能的解决方案。稀疏编码用一组原子(基元信号)来表示信号,所有原子的集合称为原子字典。稀疏编码旨在用少量的原子的线性组合来表示信号。最近,一种被称为形态成分分析(Morphological component analysis,MCA)[7]的稀疏编码方法已被成功应用于说话人识别。该方法为每个说话人训练一个字典,并且所有说话人字典连接成一个大字典。在识别过程中,测试语音被稀疏地表示在大字典上。理论上,一个说话人说出的话语只能表示在这个说话人的字典上。因此,稀疏表示可以直接用于分类。
几乎所有基于稀疏编码的说话人识别方法都采用MCA的框架。目前常用的方法是首先将说话人的高斯混合模型(Gaussian mixture model,GMM)转变为均值超向量[8-9]或全部可变性i-向量[10],然后把这些向量组成一个大字典,通过在大字典上的稀疏分解来识别说话人。据报道,这些方法具有比传统的GMM-UBM和GMM-SVM[8]更好的性能。
尽管目前的方法取得了一定的进展,但仍然存在两个问题需要进一步解决。首先,MCA只有在其假设成立之时才能取得良好性能,即一个说话人的语音在它自己的字典上是稀疏的,而在其他字典上是稠密的[7]。然而,并没有理论或实验上的证据表明这种假设在GMM均值超向量域或i-向量域成立。其次,目前的方法还没有考虑说话人识别的噪声鲁棒性,因而这些方法也无法在噪声环境下取得满意的效果。
为了解决这些问题,提出一种基于MCA的说话人识别方法。在这种方法中,信号首先被转换成幅度谱;在这个域中,语音具有稀疏性。此外,字典通过训练的方式获得,与通过样例集合获得字典的方法相比,本文方法能确保语音分解的稀疏性。更重要的是,说话人字典是通过删除与通用背景字典原子相近的原子来进一步优化的,这使得说话人字典具有更强的区分性。此外,噪声字典随输入噪声变化,这使得所提出的方法可以吸收时变噪声。
1 形态成分和说话人识别
MCA最初是被提出来用于分离具有不同形态成分的混合信号,目前已经成功用于图像分离。给定由K个不同的信号X1,X2,…,XK混合而成的实数域信号Y,即

存在一个字典Ψ=[Φ1,Φ2,…,ΦK],其中Φi∈RN*Mi是信号Xi的一个字典,K是字典的数量,Mi是Φi中的原子数量。MCA假设每个Xi在Φi上稀疏,但是在其他的Φj(j≠i)上稠密,对于信号Y,MCA解决如下的优化问题实现稀疏分解

将MCA用于说话人识别在理论上是可行的。在说话人识别任务中信号不是混合的,而只是一位说话人的语音,即Y=Xi,其中Xi表示第i个说话人的语音。如果每个说话人有一个字典Φi,在这个字典上该说话人的语音是稀疏的,其他说话人的语音是稠密的,能构造Ψ=[Φ1,Φ2,…,ΦK]。在理想条件下,求解方程(2)导致Xi≈Φixi,即仅Φi的原子被使用。因此,可以通过已使用的原子的标签实现对Y的分类。在噪声的环境中,可以把噪声看作是一个说话人。满足MCA的假设的说话人字典和噪声字典可以通过相应的信号训练得到。因此,在说话人识别任务中应用MCA方法是可行的。
从稀疏分解的角度看,噪声会存在两种情况,第一种是噪声本身是稀疏的,即可以找到一个噪声字典稀疏表示噪声信号,那么此时完全可以把噪声看作一个说话人。第二种情况是噪声在噪声字典上不稀疏,虽然此时噪声字典不起作用,但稀疏编码可以有效去噪。
2 基于MCA的说话人识别方法
从上面的分析中,通过设计一个基于MCA的方法得到了良好的性能。在此之前,还有3个问题需要考虑:
(1)如何训练一个大字典,使之满足 MCA的假设。只有当MCA的假设在说话人识别中成立时,该方法才能像预期的那样取得好的分类效果。这种假设的基本要求是提高大字典的区分性。
(2)如何应对不同的噪声。噪声在语音中是很难预测的,因为它可能有两种变化。首先是噪声的类型变化,例如噪声从一种类型变成另一种类型。其次,噪声本身可能是时变的。一个固定不变的噪声字典无法刻画变化的噪声,因而影响识别性能。
(3)如何用稀疏表示分类。在理想的条件下,一个说话人的语音只能通过这个说话人的字典来被稀疏表示;然而,在真实的应用环境中,其他说话人的原子也可能被使用,导致错误的分类。
考虑到以上问题,设计了一种新的说话人识别方法(见图1)。

图1 基于MCA的说话人识别步骤Fig.1 Procedure of speaker recognition based on MCA
2.1 字典准备
2.1.1 特征提取
所提出的方法中以幅度谱为输入特征。在特征提取中,语音信号首先被分割成重叠的帧,然后在每一帧上加汉明窗。接下来,对每帧数据作离散傅里叶变换(Discrete Fourier transform,DFT)并计算幅度谱作为输入特征。
2.1.2 大字典的结构
设计一种新型结构的大字典,下面是有K个说话人的识别系统
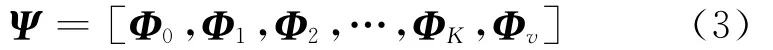
式中:Φ0是一个通用的背景字典,包括所有的说话人的共同的特征。这里借鉴了GMM-UBM用UBM来为背景建模的方法。Φi(i=1,…,K)用于刻画第i个说话人的变化性。Φv用于刻画环境噪声。在Ψ中的所有原子都被标准化成单位范数向量。
这样的一个字典结构具有两个显著优势。首先,它使大词典有更强的鉴别能力。其次,每个说话人字典的原子数量可以大幅度减少,这降低了稀疏分解的计算复杂度。
2.1.3 字典训练
许多方法被用来训练字典,例如,k-SVD[11],k-means[12]。选择k-SVD来训练字典。字典训练的问题被描述成
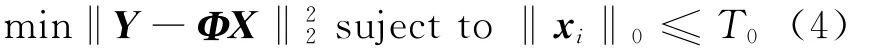
式中:Y=[Y1,Y2,…,YM]是训练的数据集,每一个Yi都是语音帧的特征向量,Φ是字典,X=[x1,x2,…,xM]是一组与Y相对应的稀疏向量,T0是稀疏度的门限。通用的背景字典用大量未标记的不同说话者的语音来训练。每个Φi都用第i个说话者的语音来训练,用Y作初始值。
2.1.4 字典的优化
在该方法中,使用Φ0来刻画所有的说话人的共同变化。希望每个说话人的字典只刻画这个说话人和其他说话人之间的不同之处,这样可以提高字典的鉴别能力。为此,提供了一种方法来优化说话人字典(算法1如下所示)。
算法1:字典优化
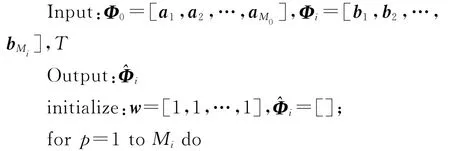
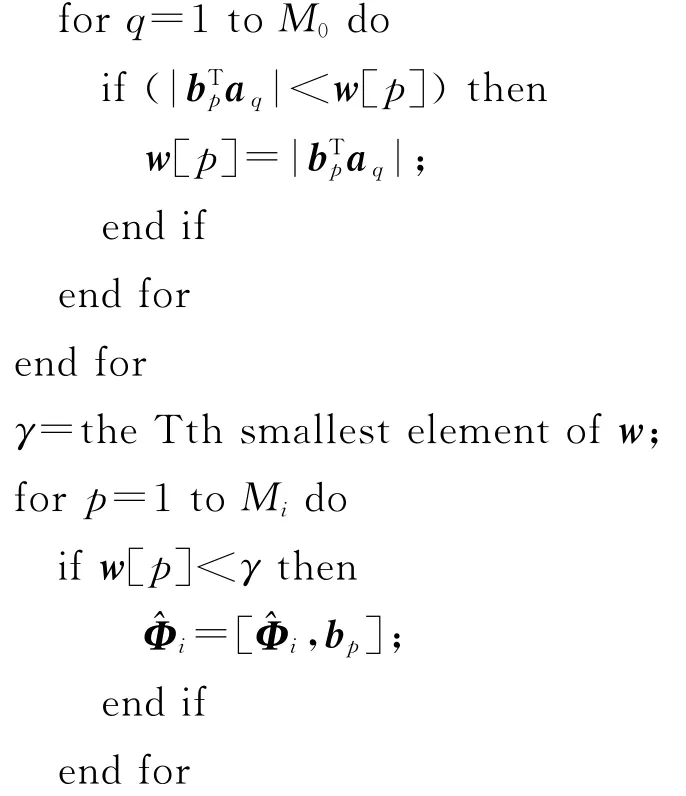
2.2 识 别
2.2.1 稀疏分解
稀疏分解通过解式(2)来实现,但这被证明是NP-难的,不可能通过穷举搜索所有可能的原子集来实现。然而,如果语音是稀疏的或近似稀疏的,那么它可以通过优化式(5)唯一求解[13]
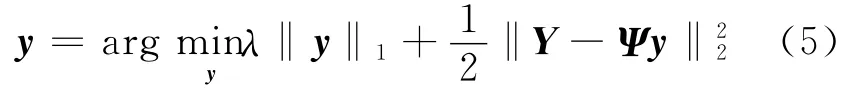
式中:λ>0是调节参数。式(5)也称为基追踪去噪法(Basis pursuit de-noising,BPDN),是本文采用的稀疏分解算法。
2.2.2 噪声字典更新
由于未知的噪声是时变的,因而不可能用一个固定的字典来刻画。一个可行的方法是,用混噪测试语音更新噪声字典。
算法2:噪声字典更新

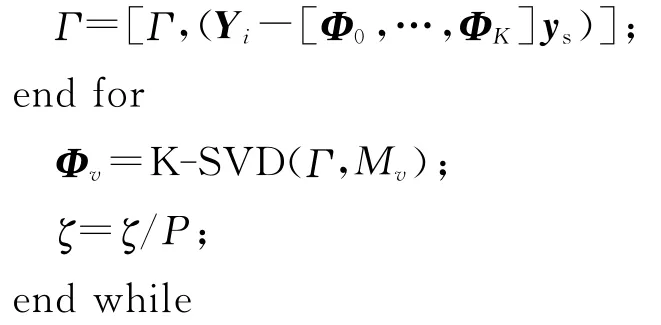
更新的方法如算法2所示,其中γ是一个被噪声污染的测试语音,δ是稀疏分解的误差门限,ys是Yi在Ψ=[Φ0,Φ1,Φ2,…,ΦK]上的稀疏表示,Γ用于保存残留噪声样本,K-SVD(Γ,Mv)表示函数采用K-SVD训练算法训练字典,Mv为字典的原子数,Γ训练数据集。噪声字典以在线的方式训练。噪声语音减去干净语音的残余是训练数据。训练过程重复进行,直到稀疏度收敛为止。
2.2.3 稀疏分类
对于一组测试语音帧[Y1,Y2,…,YP]和其相对的稀疏表示[y1,y2,…,yP],根据式(6)实现对测试语音的分类
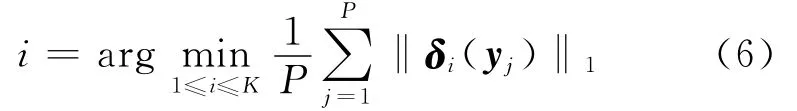
式中:δi(·)表示一个实数向量,其中非零项仅仅来自第i个类别。值得注意的是仅仅在说话人字典上的表示系数被用于范数计算,而噪声字典上的系数则被丢弃。这种方式能有效减小说话人共性和噪声对识别结果的影响。
3 实验与分析
3.1 实验设置
本文采用“863”中文数据库来测试所提出的方法。该语料库是在国家高新技术项目支持下为开发ASR系统而建立,包含96 269句83名男性和83名女性的语音(每个说话人有520句)。数据是在无噪环境下通过近距离麦克风录入,采样率16 kHz,量化位数16位。每个说话人的前10句语音用于字典训练,接下来的10句用于测试。每句测试语音作为一次测试。所有数据以8kHz的采样率进行重采样。用所有训练数据训练一个包含512个原子的通用背景字典。用每个说话人的训练数据训练这个人的字典,训练时以UBD为初始值,然后通过算法1优化。为了获得噪声环境下的测试语音,将4种噪声(来自noisex-92数据库[14]),即 white,f16,babble和pink,分别以0,5,10和20 dB的信噪比人为地加在测试集语音上。这样就有了4个噪声版本的测试集。
在预处理中,窗长为20ms,窗移为10ms。DFT点的数量是512,因此每个向量的维数是257。算法1中的参数T设置为64,这意味着优化后每个说话人字典中有64个原子。噪声字典的原子数量也是64。式(5)中的λ被设为0.01,算法2中δ被设为7。实验中以GMM-UBM方法为基线系统,同时选择GMM-SVM和维纳滤波来进行比较。使用的特征是13维的 MFCC系数(c0~c12)及其一阶和二阶的导数。所有特征都经过倒谱均值和方差的规正处理。采用EM算法在所有训练数据集上训练一个混合度为1 024的UBM。每个说话人的GMM模型用这个说话人的训练数据来训练,训练算法为最大后验概率自适应。
至于GMM-SVM,是将每个培训语音转变成GMM均值超向量,所有超向量都用来训练SVM分类器。另一种用于比较的方法是采用维纳滤波增强语音后提取特征,然后训练模型。实验采用识别准确率来衡量性能。
3.2 结果和分析
结果如表1所示,其中GU表示GMM-UBM,GS表示GMM-SVM,WF表示维纳滤波。可以看到,在干净的条件下所有的方法都可以达到满意的效果。GMM-UBM的性能随着噪声水平的增加而迅速降低。在10dB的白噪声下,其准确率下降到6.0%。GMM-SVM的性能比GMM-UBM要好,但它对噪声也很敏感。维纳滤波获得的提升是很有限的,在某些情况下,其准确率甚至会下降,如在Babble噪声下。尽管语音增强方法可以减少噪声,但它们引起了进一步的畸变,而当前的说话人识别系统对此是非常敏感的。相比之下,本文方法取得了比其他方法更好的性能。当信噪比为20 dB,精度可以达到高达90%以上;信噪比下降到0 dB时,精度可以保持60%以上。

表1 在各种不同噪声环境下的性能比较Table 1 Performance comparison under various noisy environments %
4 结束语
在现实的应用中,说话人识别系统的性能随信噪比的降低而迅速下降,因此,提高系统的鲁棒性具有重要的作用。目前的研究主要集中在信道失配和场景变化上。虽然目前的文献提出了许多有效的方法;然而,缺乏有效的方法来克服噪声的影响。为了解决这一问题,提出一种基于MCA的说话人识别方法。在分析MCA的假设基础上,设计了一种字典构造方法使这一假设成立。首先,在频谱域训练字典,这里的语音倾向于稀疏。字典是通过训练的方法而不是收集样例的方法来获取,这进一步确保了语音在字典上稀疏。第二,设计了一种新型的字典结构并通过增强字典的区分性来优化字典。一方面,这种方法使得说话人字典能刻画不同说话人的变化;另一方面,可以大幅度减少原子数,提高系统效率。第三,在大词典中放入噪声字典,并给出了一个根据噪声在线更新噪声字典的算法,这确保了噪声字典可以稀疏表示随时变化的噪声。最后,在实验中通过在干净语音中人为添加噪声来模拟噪声环境。实验结果表明,该方法对于各种噪声具有鲁棒性。
本方法对环境噪声具有更强的鲁棒性,因此具有更加广泛的实用价值,可用于现实的说话人识别任务。虽然所提出的方法对字典进行了优化,但计算量仍然很大。因此该方法目前不适合用于有实时需求的应用场合。我们将在未来的工作中降低本方法的时间复杂度,提高其运行的效率。
[1] Reynolds D,Quatieri T F,Dunn R B.Speaker verification using adapted Gaussian mixture models[J].Digital Signal Process,2000,10:19-41.
[2] Campbell W M,Sturim D E,Reynolds D A.Support vector machines using GMM supervectors for speaker verification[J].IEEE Signal Processing Letters,2006,13:308-311.
[3] Kenny P,Boulianne G,Ouellet P,et al.Joint factor analysis versus eigenchannels in speaker recognition[J].IEEE Trans Audio Speech Lang Process,2007,15(4):1435-1447.
[4] Ming J,Hazen T J,Glass J R,et al.Robust speaker recognition in noisy conditions[J].IEEE Trans Audio Speech Lang Process,2007,15(5):1711-1723.
[5] 王华朋,杨军.应用似然比框架的法庭说话人识别[J].数据采集与处理,2013,28(2):239-243.
Wang Huapeng,Yang Jun.Application of likelihood ratio for speaker recognition framework[J].Journal of Data Acquisition and Processing,2013,28(2):239-243.
[6] Donoho D L.Compressed sensing[J].IEEE Trans on Inf Theory,2006,52(4):1289-1306.
[7] Bobin J,Starck J-L,Fadili J M,et al.Morphological component analysis:An adaptive thresholding strategy[J].IEEE Trans on Image Processing,2007,16(11):2675-2681.
[8] Naseem I,Togneri R,Bennamoun M.Sparse representation for speaker identification[C]//Proc ICPR.Turkey:Istanbul,2010:4460-4463.
[9] KuaJ M K,Ambikairajah E,Epps J,et al.Speaker verification using sparse representation classification[C]//Proc ICASSP.Czech,Prague:[s.n.],2011:4548-4551.
[10]Dehak N,Kenny P,Dehak R,et al.Front-end factor analysis for speaker verification[J].IEEE Trans Audio Speech Lang,2010,19(4):788-798.
[11]Aharon M,Elad M,Bruckstein A M.The K-SVD:an algorithm for designing of overcomplete dictionaries for sparse representation[J].IEEE Trans on Signal Process,2006,54(11):4311-4322.
[12]MacQueen J B.Some methods for classification and analysis of multivariate observations [C]//Proc BSMSP.Berkeley:University of California Press,1967:281-297.
[13]Chen S,Donoho D,Saunders M.Atomic decomposition by basis pursuit[J].SIAM Rev,2001,43(1):129-159.
[14]Horman S.Introduction of noisex-92.Available:http://www.speech.cs.cmu.edu/comp.speech/Section1/Data/noisex.html.1996-08-13
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
Contemporary Social Sciences(2022年3期)2022-11-26 15:50:39
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 06:42:32
汉字汉语研究(2021年1期)2021-06-11 01:15:02
贺州学院学报(2017年1期)2017-06-05 09:15:36
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
