
基于线性预测分析的语音信号合成
2014-07-25 09:41白俊贤
通信电源技术 2014年6期
米 川,白俊贤
(河北科技大学研究生学院,河北 石家庄 050000)
0 引 言
语音信号的线性预测作为一种工具,已被应用于语音信号处理的各个方面,是最有效和最流行的语音分析技术之一。它能够较为精确地估计语音参数,用极少的参数就可以有效而又正确地表现语音信号的时域及频域特性。
线性预测应用于语音,是因为线性预测可以提供一个非常好的声道模型,这个声道模型是用准周期脉冲或随机噪声激励一个线性时不变系统所产生的输出而生成的,而这样的声道模型对理论研究和实际应用都是相当有用的。本文就是用这样的线性预测模型合成的语音。
1 语音信号的线性预测
语音信号线性预测分析的基本原理是把被分析的语音信号用一个模型来表示,即将信号看做某一个模型的输出,这样就可以用模型参数来描述信号。
1.1 语音信号的模型
语音信号的模型如图1。

图1 语音信号x(n)的模型化表示
其系统传递函数为:

H(z)是以系数ai和增益G为模型参数的全极点模型。用系数{ai}可以定义一个p阶线性预测器F(z),即:

将这个p阶线性预测器从时域角度理解为:用信号的前p个样本来预测当前的样本得到如下预测值:

预测器的预测误差:
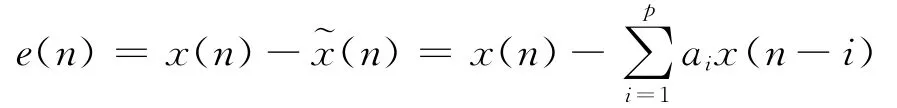
短时预测均方误差为:


即:

解方程得到线性预测系数ai的值。
1.2 线性预测系数的提取
首先录制了一段语音,内容为“语音信号处理”,采样频率为8 kHz,对语音信号进行归一化处理,消除直流分量。然后将语音信号进行分帧处理,每帧240个样点,分别求出每一帧信号的线性预测系数,线性预测计算阶数为12。其中,样点(3601-3841)这一帧信号的线性预测系数提取如图2所示。
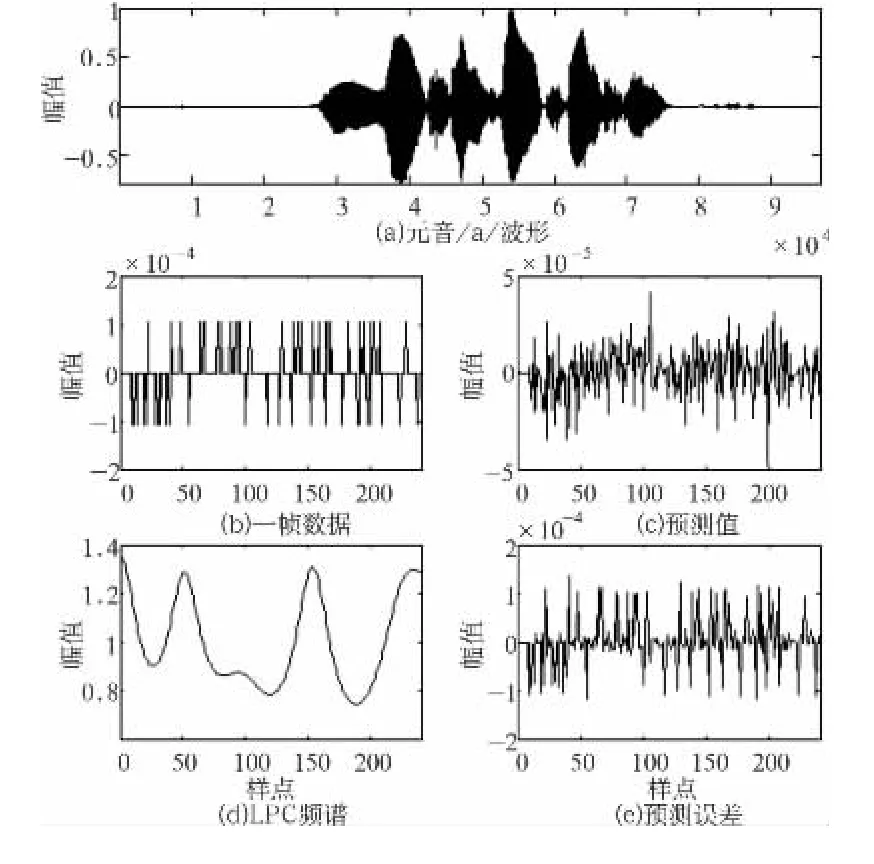
图2 一帧语音信号的线性预测系数
线性预测系数为:

2 线性预测系数合成语音
线性预测参数法是一种简单和实用的语音信号合成方法,特点是复杂度和成本较低,线性预测语音编码可以有效地估计基本语音参数,如基音、共振峰、谱、声道面积函数等,可以对语音的基本模型做出精确的估计。求出预测误差e(n)和预测系数ai后,可求出合成语音
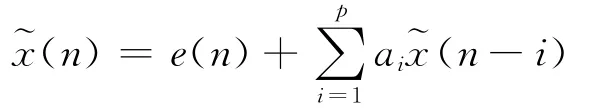
2.1 合成模型
线性预测合成模型是一种滤波器模型,这种语音合成器的框图如图3所示,其中的声道参数和时变滤波器由预测系数ai直接递归滤波器所构成。语音合成的结构如图4所示。

图3 语音合成器的框图

图4 语音合成的结构图
2.2 重叠存储法
语音信号参数合成都是一帧一帧计算的,而且信号在分帧的过程中还有重叠,那么在语音合成的时候如何把一帧帧的数据连接成连续的、平滑的数据流,而不使数据中间产生中断或跳变非常重要。
设有两个时间系列h(n)和x(n),它们的长度相差很大。若h(n)的长度为N、x(n)的长度为N1,而N1≫N。将x(n)分帧为xi(m),相邻两帧之间互不重叠,每帧长与h(n)的长相接近,然后将每帧xi(m)与h(n)做卷积。
假设h(n)是时不变的,在它的后面补零值,有

xi(m)每帧长度为N+M-1,要求分帧后每帧的最后一个数据点都在iM(i=1,2,…)处,对于第一帧(i=1)数据帧的最后一点在M处,其长度只有M,达不到N+M-1,只能向前补了N-1个零值,所以在分帧前数据x(n)要前向补N-1个零值,有

前向补零后的(n)进行分帧,每帧xi(m)为xi(m)=(n) (i-1)M+1≤n≤iM+N-1
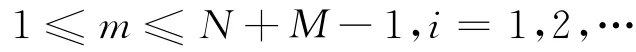
对(m)和xi(m)计算卷积,得到

每帧卷积结果舍去前N-1个点,而只保留最后M个值,即每次卷积只取yi(m)的最后M个值:

而输出序列为

2.3 合成结果
原始语音信号波形和合成语言信号如图5所示。

图5 原始语音信号波形和合成语音信号
3 结 论
本文对语音信号的线性预测分析进行了比较系统的探讨,并用Matlab进行了具体实验,说明了线性预测可提供一种简单而有效的用少量参数来表示语音信号的方法,这种方法是以语音信号数字模型为基础。实际应用中,线性预测模型带来的误差不大、分析计算简单、速度快、计算所得数据量少,因此它在语音分析中的地位是极其重要的。
[1] Linde,Buro,Gray.An Algorithm for Vector Quantizer Design[J].IEEE Transaction Communication,1980,(28):84-95.
[2] 韩纪庆.语音信号处理[M].北京:清华大学出版社,2004.
[3] 王京辉.语音信号处理技术研究[M].济南:山东大学,2008.
[4] 周伟雄.语音信号的神经网络非线性分析模型及应用[D].广州:华南理工大学硕士学位论文,2010.
[5] 高晓红.基于非线性理论的汉语语音的分析[D].长沙:中南大学硕士学位论文,2012.
[6] 宋知用.MATLAB在语音信号分析与合成中的应用[M].北京:北京航空航天大学出版社,2013.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
家庭影院技术(2021年10期)2021-11-20
中学生数理化·高一版(2021年2期)2021-03-19
家庭影院技术(2021年1期)2021-03-19
家庭影院技术(2020年7期)2020-08-24
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
