
汉盲翻译中的分词连写处理算法研究
2014-07-23 01:37陈优阳
网络安全技术与应用 2014年2期
陈优阳
(北京理工大学计算机学院 北京 100081)
0 引言
2000年《东京宣言》中提出了信息无障碍的理念。信息无障碍[1]是指利用不断发展的信息科学技术,使得所有人都能无障碍地获取信息资源。其核心内容是利用科学技术手段消除某些生理功能退化或丧失的人群在信息获取、接受过程中的障碍。因为盲人存在最严重的信息获取问题,所以推进盲人信息无障碍尤其最为迫切和重要。
解决盲人信息无障碍问题的一个重要方法就是利用先进的计算机应用技术,制造出适合盲人使用的计算机硬件设备和软件系统。软件系统中非常重要的一个系统是汉盲翻译系统,汉盲翻译系统将数字化的中文信息翻译成数字化的盲文,然后通过特殊的显示或印刷设备把信息以盲文形式呈现出来。
本文旨在研究如何设计一个高效,易于扩展和维护的盲文分词连写实现方案。首先设计了一个基于SC文法[4]的规则表示形式,并且根据盲文分词连写需要设计了一个连写规则库。然后根据语料和基于字典树的匹配算法设计了一个连写语料统计库,它用来连写那些无法表示为规则的连写知识。最后,本文提出的方案实现了快速、准确的分词连写需求,并且连写规则库和连写语料统计库是易于扩展和维护的。
1 问题描述
我们形式化地定义了分词连写处理问题。提出了基于 SC文法的规则表示和连写语料统计库的解决方案。其中,连写语料统计库用来处理需要连写却无法用规则形式化表示的知识。分词连写处理模块的输入是分词模块的输出结果,设为
2 解决方案描述
2.1 形式化规则库的设计
针对可以用形式化规则表示的连写知识需求,本文设计了一个基于 SC文法的,可扩展性好的,表示效率高的,人性化的规则表示语言。
第一部分是规则句块部分。我们使用“Si{}”(i=1,2,3……)表示规则中的句块,Si表示句块的索引,即该句块处于规则中的位置。{}表示句块的属性字典,它使得规则表示系统易于理解和扩展。其中,属性字典由多个属性与属性值组成,属性可取值为词性,内容和字数。一个属性可以对应多个属性值,这样我们可以在一条规则里面表示多个连写要求,多个属性值用“/”分割,分词后的句块只要满足该属性中的一个属性值,就匹配成功,这样使得我们的规则表示效率高,也容易扩展。
第二部分是条件部分。其中条件部分是由条件名字和条件句块组成。有些分词利用规则进行连写需要设定一定的条件,最常见的条件是规则中某两句块的内容必须相同。如果一个规则的条件部分不为空,分词的结果除了必须匹配上规则的句块之外,还需要满足条件部分中定义的条件才可以进行连写,条件部分使得我们的规则表示灵活多变,能适应各种需求。
第三部分是连写模式部分。因为有的规则涉及到多个句块,但是最后连写的时候并不是把所有的句块都连写,所以需要连写模式部分来指定需要连写的句块,使用规则句块部分中的句块索引”Si”即可表示需要连写的句块。例如规则“名词后接两个方位词,则两个方位词连写”。我们用S1表示名词,S2和S3表示两个方位词,则连写模式就是”S2,S3”,表示只需将S2,S3连写。这种设计方式可满足规则连写的普适性。
规则的三个部分用”|”分隔,下面给出一个具体的规则表示的例子。在本文的第二部分提到的连写规则“单音节动词重叠式连写”,其对应的规则表示内容如下“S1{label:verb,length:1} S2{label:verb,length:1}|prefix_content_equal(S1,S2)|S1,S2”。
2.2 连写语料统计库的设计
分词连写规则可以解决大部分分词连写的需求,然而有一部分词需要连写却无法用形式化的规则进行表示。为了解决这个问题,本文设计了一个基于高效的字符查找数据结构Trie的连写语料统计库。连写语料统计库中的每一条记录为需要连写的字词,出现在连写统计库中的词如果被分词器分开,我们要能识别出各种切开的情况并且还原那个词。以“爱鸟周”为例,分词器的分词结果有可能为”爱 鸟周”、“爱鸟 周”“爱 鸟 周”,“爱鸟周”,当分词结果为前面3种情况时,都需要将分词结果重新连写为“爱鸟周”。由此可见,随着词的长度增加,需要考虑的的情况呈指数型增长,因此我们需要一个高效的句块查找数据结构,Trie是一个非常合适的选择。
Trie[4],又称前缀树或字典树,我们结合统计库中句块匹配给出一个小型Trie树实例,如图一。图中的空心节点是字典树的根节点。边上的字表示句块的内容,白色节点表示树中的内部节点,蓝色实心节点表示统计库中的词。由于其复杂度与词表的个数无关,所以能极大的加快查找速度,即使增加了许多统计库后也是如此。引入字典树提高了整个系统的可扩展性,是本论文的一大亮点。
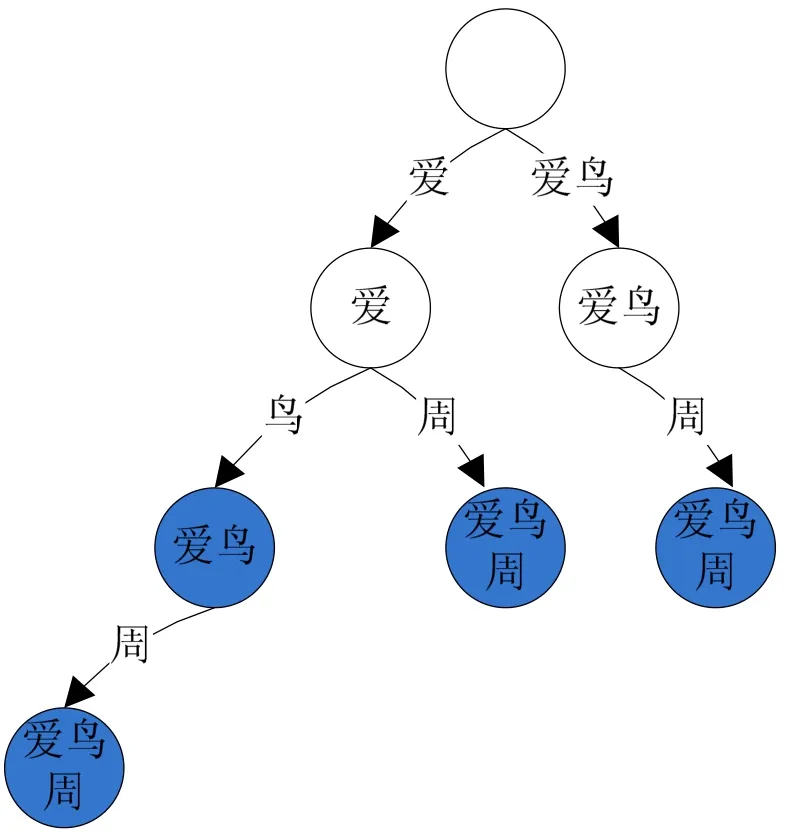
图1 字典树在统计库上的应用实例
3 实验和结果分析
根据《中国盲文》[5]对盲文分词连写的要求,我们设计了130条连写规则。根据中国盲文出版社的专家知识和实际语料,设计了一个连写统计库。我们对2000条句子进行了连写处理,连写处理的结果由中国盲文出版社的专家进行鉴定。根据实验结果,我们的解决方案连写处理的准确率达到91%。连写错误是由于分词及词性标注的错误引起的。影响准确率的根本因素是中文分词和词性标注这个模块。首先中文分词的准确率没有达到百分百的精度,所以它肯定会对连写算法造成负面影响。其次,对一个词进行词性标注时会有歧义,因为汉语词的兼类现象比较频繁。
4 结论和未来工作
根据我们设计的分词连写规则库和连写语料统计库,很好的解决了汉盲翻译转换中存在的分词连写问题,实现了汉盲翻译高效和准确地转换。由于所设计的连写规则库和语料统计库是可扩充的,那么接下来,我们可以更深入的了解盲人对于分词连写的需求,然后设计更多的连写规则添加到连写规则库中,更好的让盲人理解和得到信息。
[1]何川,国内信息无障碍的现状及展望.现代电信科技,2007.37(3):p.4-8.
[2]黄河燕,陈肇雄,黄静,基于多知识分析的汉盲转换算法,in 语言计算与基于内容的文本处理.2003:哈尔滨.p.607-613.
[3]陈肇雄,高庆狮,SC 文法功能体系.计算机学报,1992.11:p.801-808.
[4]Knuth,D.E.,The art of computer programming,volume 3:sorting and searching.1973,Addison-Wesley Reading,Mass.
[5]滕伟民等.中国盲文.1996:华厦出版社.
猜你喜欢
残疾人研究(2022年1期)2022-08-30
疯狂英语·新悦读(2021年9期)2021-11-23
疯狂英语·新阅版(2021年9期)2021-10-30
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
北京联合大学学报(2016年4期)2016-11-18
读者(2016年14期)2016-06-29
