
迭代二叉树3代算法的一种改进
2014-07-18 11:53:24朱金坛
西安邮电大学学报 2014年1期
朱金坛
(西安铁路职业技术学院 电子信息系, 陕西 西安 710014)
迭代二叉树3代算法的一种改进
朱金坛
(西安铁路职业技术学院 电子信息系, 陕西 西安 710014)
针对数据挖掘决策树中迭代二叉树3代算法复杂的对数运算以及属性取值多向依赖的缺陷,提出了一种改进算法。该算法将对数运算改进为简易的普通运算,引入重要度、关联度概念以及调整系数,形成一个综合评价指数来确定作为决策树生成的划分结点的属性。仿真结果表明,改进算法简化了计算过程、提高了运算效率,同时使得决策树的形成不依赖属性多值取向。
迭代二叉树3代算法(ID3);决策树;粗糙集论;重要度;关联度
伴随信息技术的快速发展,数据量正在以惊人的速度增长,“丰富的数据与贫乏的知识”之间的矛盾日见突出。数据挖掘作为一种能够从海量数据中寻求有用信息的工具,在各个领域广泛应用[1]。
目前,决策树[2-3]已成为一种重要的数据挖掘方法,而在决策树构造中,迭代二叉树3代(Iterative Dichotomiser 3, ID3)算法[4]作为最具有影响力的一种决策树生成算法,其清晰的理论基础、简单易懂的建树思路,能得到功能较佳的树形结构。通过此算法得到的知识规则很容易被理解和使用,但在分类过程中存在对数运算量较多、计算复杂度倍增,偏向属性取值较多等缺点。之后Quinlan提出的C4.5[5]算法,与统计方法、神经网络[6]等分类算法相比,产生的分类规则易于理解,准确率较高,但在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外C4.5算法只适合于能够驻留于内存的数据集,当训练集大到无法在内存容纳时程序无法运行。本文根据粗糙集论中有关属性重要度和关联度的概念[7-9],针对ID3算法复杂的对数运算以及属性取值多向依赖的问题,对决策树ID3算法进行改进。
1 ID3算法基本思想
在利用决策树构造方法时需充分考虑选取哪个属性作为形成决策树的决策结点。选择的依据是比较谁能最大程度测试样本集的分类特征。
分类决策树算法ID3基本思想是:将熵的概念从信息论[9]当中抽取出来,属性分类的能力由属性的信息增益来决定。选取其中信息增益最大者为决策结点属性,之后进行结点的扩展工作,所依据为该属性的不同取值。再对各分支所对应的样本子集使用递归调用ID3算法的方法来建立决策树的分支结点或叶子结点,同时使用决策树不在生长的三个必要条件进行判断。ID3算法建立决策树是采用了信息增益最大的属性来进行。该算法使得所形成的决策树保证了最小分支和最小冗余。
2 改进算法的思路及步骤
改进算法主要针对ID3算法存在的计算过程复杂与对属性多值取向依赖的问题,采取了简易的运算过程和精确的决策树生成方法。主要思路是将原算法中较难计算的对数运算改进为简易的普通运算;同时根据粗糙集理论知识,引入重要度、关联度的概念以及调整系数,最终形成一个综合评价指数来确定作为决策树生成的划分结点的属性。
设定测试样本集为U,样本集包含的记录数为D,样本属性个数为M,关联度为K,调整系数为δ(0<δ≤1),样本子集分组数最大度量为I,综合评价指数为N。其中调整系数δ=I/D,综合评价指数N=K+δ(当关联度不为零的时候使用),再一次对多值取向问题进行精确改进,防止大数据掩盖小数据现象的发生,提高算法的效率和精确度。具体执行步骤如下。
步骤1 先确定要进行决策树生成的测试样本集,按照不同的属性将样本集中的记录进行分组,得到以编号为集合的分组记录。
步骤2 计算按照属性进行分组后的各分组记录中的最大度量I值。
步骤3 根据粗糙集论中关于对属性重要度知识的描述,计算样本集属性的关联度K值。
步骤4 根据步骤2得到的最大度量I值及本次分组样本集包含的记录数D,计算各属性对应的调整系数δ值。
步骤5 计算各属性对应的综合评价指数N。
步骤6 由步骤5得到的综合评价指数N判断选择哪一个属性作为结点进行进一步的划分。
步骤7 重复以上步骤直至所有的叶子结点都归属同一个类别时,结束结点的划分,得到分类决策树,并提取分类规则。
3 改进算法实例
通过某医院“病情信息系统”的样本数据集实例来阐述改进算法的整个执行过程。表1为患者信息系统的样本数据集。用U表示整个训练样本集,年龄段、病情度、手术、诱发病因是条件属性,为了较为容易地对ID3算法及改进算法进行比较,在样本集中新增加了一个检验属性,它是5个条件属性中取值最多的,分类则为决策属性。

表1 测试样本集
具体的过程如下。
(1)首先利用属性对测试样本集中记录进行统计分组,并计算出样本子集分组数最大度量I。
U/类别={{1,2,3,4,5,6,7,8,9},
{10,11,12,13,14}},
U/年龄段={{1,2,3,10},
{4,5,6,7,11,12},{8,9,13,14}},
I/年龄段=6,
U/病情度={{1,2,3,4,6,9,10},
{5,7,8,11,12,13,14}},
I/病情度=7,
U/手术={{1,3,6,7,8,9,11,13},
{2,4,5,1,12,14}},
I/手术=8,
U/诱发病因={{1,4,11,13,14},
{2,5,8,9},{3,6,7,10,12}},
I/诱发病因=5,
U/检验标志={{1},{2},{3},{4},{5},{6},
{7},{8},{9},{10},{11},{12},{13},{14}},
I/检验标志=1。
(2)计算样本集属性的关联度
关联度K描述了利用属性C能够将论域U中的元素正确分类到划分U/D的块中的比率。其中U为测试样本集,C*(X)是由D的划分U/D中的所有块的C下近似的并构成,称其为划分U/D对于C的正域。

(3)计算各属性对应的调整系数
根据公式δ=I/D计算年龄段、病情度、手术、诱发病因和检验标志属性的调整系数。
δ/年龄段=6/14=0.429,
δ/病情度=7/14=0.5 ,
δ/手术=8/14=0.571,
δ/诱发病因=5/14=0.357,
δ/检验标志= 1/14=0.071。
(4)计算各属性对应的综合评价指数
根据公式N=K+δ计算年龄段、病情度、手术、诱发病因和检验标志、属性的综合评价指数。
N/年龄段=0+6/14=0.429,
N/病情度=0+7/14=0.5,
N/手术=0+8/14=0.571,
N/诱发病因=2/7+5/14=0.715,
N/检验标志=0+1/14=1/14=0.071。
由此得到,将属性中的诱发病因作为测试属性的原因是因为其最终的综合评价指数最大。接着可以从中分裂出3个子样本集
U1={1,4,11,13,14},
U2={2,5,8,9},
U3={3,6,7,10,12},
它们都来自于样本集合U。分析得到的3个子样本集,发现U2不必再进行划分,原因归结于其中的元素都属于A类。据此得到一个叶子结点。剩下的U1与U3仍然采用此方法进行综合评价指数的计算以便确定之后的划分原则。
具体执行过程如下。
U1/分类={{1,4},{11,13,14}},
U1/年龄段={{1},{4,11},{13,14}},
关联度K=3/5=0.6,
I1/年龄段=2 ,
δ1/年龄段=2/5=0.4,
U1/病情度={{1,4},{11,13,14}},
关联度K=5/5=1,
I/病情度=3,
δ/病情度=3/5=0.6,
U1/手术={{1,11,13},{4,14}},
关联度K=0/5=0,
I/手术=3,
δ/手术=3/5=0.6
U1/检验标志={{1},{4},{11},{13},{14}},
关联度K=0/5=0,
I/检验标志=1,
δ/检验标志= 1/5=0.2。
由此得到U1子样本集中各个属性综合评价指数为
N1/年龄段=0.6+0.4=1,
N1/病情度=1+0.6=1.6 ,
N1/手术=0+0.6=0.6,
N1/检验标志=0+0.2=0.2。
由上面的计算结果得到,U1的子集本集或者属于A类,或者属于B类,这些是取决于病情度属性的综合评价指数最大。符合了决策树停止生长的条件,所以中止本分支树的划分。
同样的方法针对U3子样本集进行运算,得到测试属性为手术属性取决于其计算得到的综合评价指数最大。最后划分子样本集或者属于A类,或者属于B类,到此整个划分也就终止了。
经过以上算法过程执行,对样本集属性的运算之后产生了一个决策树,如图1所示。
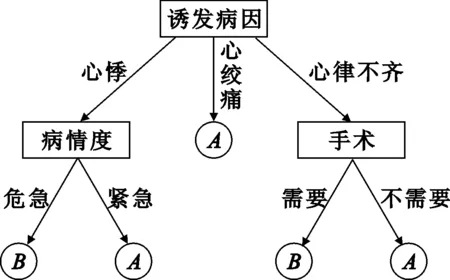
图1 决策树生成图
由此得到决策树的提取规则可表示为
算法:Generate_decision_tree(samples, attribute)。由给定样本集产生一棵决策树。
输入:测试样本集samples,由离散值属性表示;候选属性的集合attribute_list。
输出:一棵决策树。
方法:
Generate_decision_tree(samples, attribute_list)
(1) 创建结点N=诱发病因;
(2) if samples 都在同一个类别then
(3) returnN作为叶结点,以类A或者B 标记
(4) if attribut_list=心悸 then
(5) returnN=“病情度”标记为叶结点
(6) else
(7) if attribut_list=心律不齐 then
(8) returnN=“手术”标记为叶结点
(9) 递归使用Generate_decision_tree(samples, attribute)方法。
(10) ifN=“病情度”
(11) if attribut_list=危急 then
(12) returnN作为叶结点,标记为B
(13) else returnN作为叶结点,标记为A
(14) ifN=“手术”
(15) if attribut_list=需要 then
(16) returnN作为叶结点,标记为B
(17) else returnN作为叶结点,标记为A
4 改进算法仿真
仿真实验中涉及的时间以本地计算机上的执行时间为准,选取两个不同的数据集作为决策树生成仿真的实验数据,仿真实验的测试环境为Intel Core i5-3210M 2.5GHz,内存为 2G。仿真实验的整个流程如图2所示。

图2 改进算法仿真流程图
实验开始,先从加州大学欧文分校提出的用于机器学习的数据库UCI[10]中选取数据集,作为仿真实验的输入项进行测试比较,其中数据集1选为Segment-Challenge,数据集2选为Zoo。测试数据与测试结果分别如表2和表3所示。

表2 测试数据集

表3 测试结果
由表3可知,改进算法比原始算法的精确度提高,数据集Segment-Challenge与Zoo的节点数在使用改进前后的算法中有了进一步减少,算法的耗时也得到缩减。整个决策树的准确率得到了提高,规模整体缩小。
5 结 论
改进算法采取简易的运算过程和精确的决策树生成方法的分析,使得在决策树生成速度和精度上都有很大的提高。实例分析表明,改进算法能有效地对属性进行约简,并且多数情况下能提高算法效率,减少约简的计算复杂度。
[1] 王春梅. 基于数据仓库的数据挖掘技术[J]. 西安邮电学院学报,2006,11(5):99-102.
[2] 陶荣,张永胜,杜宏保.基于粗集论中属性依赖度的ID3改进算法[J].河南科技大学学报:自然科学版,2010(1):42-45.
[3] 牛文颖.改进的ID3决策树分类算法在成绩分析中的应用研究[D].大连:大连交通大学,2008:10-12.
[4] 邓全.决策树算法与客户流失分析[J].西安邮电大学学报,2013,18(3):49-51.
[5] 索永强,马力,谭薇.一种改进的粗糙集属性约简启发式算法[J].西安邮电学院学报,2009,14(5):116-120.
[6] Giaci G,章子木. 采用神经网络和统计算法相结合的方式检测远程传感图象分类[J].图象识别与自动化,2000(2):45-54.
[7] 王熙照,杨晨晓.分支合并对决策树归纳学习的影响[J].计算机学报,2008,8 (8):40-43.
[8] 杜巍.基于数据挖掘技术的人力资源信息系统的需求分析[D].济南:山东大学, 2009:19-24.
[9] 张先荣.粗糙集理论在智能数据分析中的应用[J].河南科技大学学报:自然科学版,2008(5):60-65.
[10] 袁凯.多视角协同训练算法研究[D].西安:西安电子科技大学,2013:51-66.
[责任编辑:祝剑]
An improved algorithm of iterative dichotomiser 3
ZHU Jintan
(Department of Electronic Information, Xi’an Railway Vocational and Technical Institute, Xi’an 710014, China)
Iterative dichotomiser 3(ID3) algorithm for data mining of complex logarithmic and property values more dependence on defect,This paper presents an improved algorithm. The difficult part of the logarithmic in the original algorithm is improved into an easy one. At the same time, the importance, the concept of correlation degree and the adjustment of the coefficient are introduced in this article. Finally, a comprehensive evaluation index is formed to determine the choice of a property as the division of the decision tree generated notes. Simulation result show that the improved algorithm can simplify the calculation, improve the efficiency of the operation, and make the formation of the decision tress independent of the formation of attribute value orientation.
Iterative Dichotomiser 3 (ID3), decision tree, rough sets, importance degree, correlation degree
10.13682/j.issn.2095-6533.2014.01.007
2013-11-11
陕西省自然科学基金资助项目 (2012JQ8050)
朱金坛(1981-),男,硕士,讲师,从事算法处理研究及软件开发研究。E-mail:zjt_88@126.com
TP301
A
2095-6533(2014)01-0037-05
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23 13:05:50
国际商业技术(2022年4期)2022-04-21 21:16:19
家庭影院技术(2020年7期)2020-08-24 08:18:08
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
数学物理学报(2018年1期)2018-03-26 08:16:42
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
中国音乐教育(2014年11期)2014-05-18 09:58:22
电子设计工程(2014年12期)2014-02-27 11:58:23
