
基于支持向量机的信息检索方法研究
2014-07-07 06:05纪凯,韩栋
吉林工程技术师范学院学报 2014年4期
纪 凯,韩 栋
(1.安徽交通职业技术学院 土木工程系,安徽合肥230051;2.法国格勒诺布尔计算机实验室,法国伊泽尔省格勒诺布尔市38000)
1 引言
多媒体索引是从媒体数据中提取出特定的信息线索,然后根据这些线索在大量媒体数据中查找,检索出具有相似特征的数据。它分为两个主要层次:低层次信号特征(如颜色、质地表述信息,例如直方图等)和高层次的语义特征(如概念或者事件表述,例如定义跑步这个动作等)。基于信号特征层面(即低层次)的索引通过机器学习完全自动化,因此用户可以非常方便的使用,比如医生对搜索出图像中较暗或较亮的区域很感兴趣。然而低层次的语义索引常常忽略文件中用户最感兴趣的语义信息,同时某些低级别特性表述也难以方便应用。而高层次的以语义特征为基础的索引方法却有许多优势,是更自然更接近人类感知的查询,但也是最困难的,因为存在“语义鸿沟”问题。如图1所示,在数据库中搜索“美国总统奥巴马喝啤酒”,就需要解决计算机存储原始数据和人类认知数据之间的语义鸿沟。其中一个解决方法是给定查询,即手动标注数据库,通过机器学习模型建立图像视觉内容和高层语义概念的联系。这种方法对少量数据检索非常有效,但随着是数据集规模越来越大,需要更加耗时耗力的工作。因此需要基于机器学习理论的自动搜索方法来完成此类任务,即通过低层次的语义知识,经过训练标注为正和负的样本(即训练集)来生成模型,然后用此模型来预测未标记的数据。
2 基于内容的多媒体索引和检索(CBMIR)
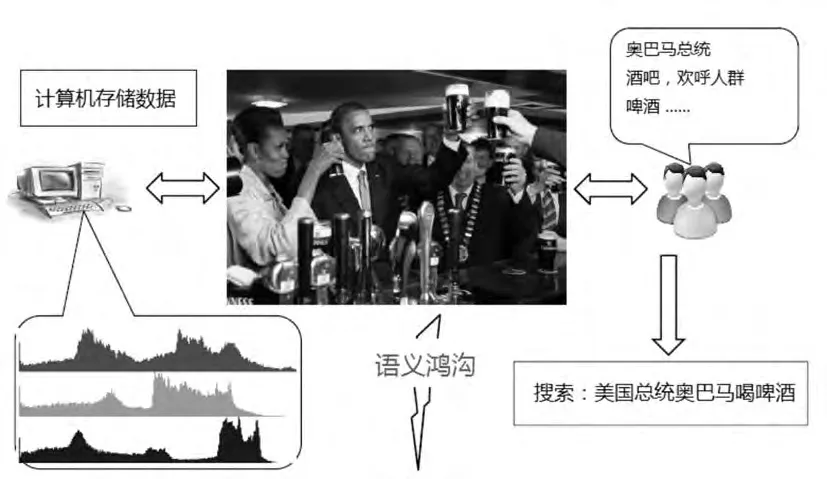
图1 语义鸿沟示例
基于内容(语义概念描述)CBMIR(Content-Based Multimedia Retrieval)的索引和检索被认为是下一代文件索引和检索方法。它可以从低层次特征抽象出高层语义概念,比如关键字语义概念和文件系统进行交互。但对于同一个概念,可以用不同的颜色和形状进行表述,因此如何将抽象语义概念与视觉功能关联是并不容易,这需要在检测时用相关概念知识来避免歧义。图片和视频概念索引是一个显著的基于内容的搜索。首先需要一个训练集样本,对每个目标概念注释为正或负。通过监督学习训练集的低级别特征描述生成检测分类器。监督学习结束后,语义表征的问题表示为:“给定一组低级别的特(X)和一组概念(C),每个属于低级别特征的样品x(x∈X)最有可能属于的那一个概念c(c∈C)?”。对于一组给定的N 个训练样本{(x1,y1),(x2,y2),…,(xN,yN)},其中输入值xi(即低层次的特征向量)形成了一个特征空间X,输出值yi(即目标类)有一个属于无限集合C的类标注c。一个基于训练数据的分类规则就是对于给定一个新的输入值x,找出概率最高的一个属于概念集合C的某一个类c。如图2,一个自动检索系统包括建模和索引。对于给定的一个目标概念,比如飞机,在建模阶段学习训练集的描述及其关联标注之间的关系,产生一个分类模型。索引阶段是将该模型施加于未标注的样本(即测试集)。对于每组样品,它会产生最大似然学习的一组预测分数,检索任务就可以通过测试样品的预测分数实现,即分数靠前的被认为是可能性最大的正确样品类别。图2中两幅待分类图片,第一个图片是飞机的可能性是0.85,而第二个图片是飞机的可能性是0.15,因此认为第一个图片是飞机的可能性最大。
本文中基于支持向量机的信息检索的研究目的是研究基于内容的图像和视频检索方法,并由此尝试应用于其他领域,比如数据库中遥感图像分类技术。研究工作主要包括提出合适的文件描述和建立分类器的先进机器学习技术两个两部分。其中第二部分将是研究的重点。
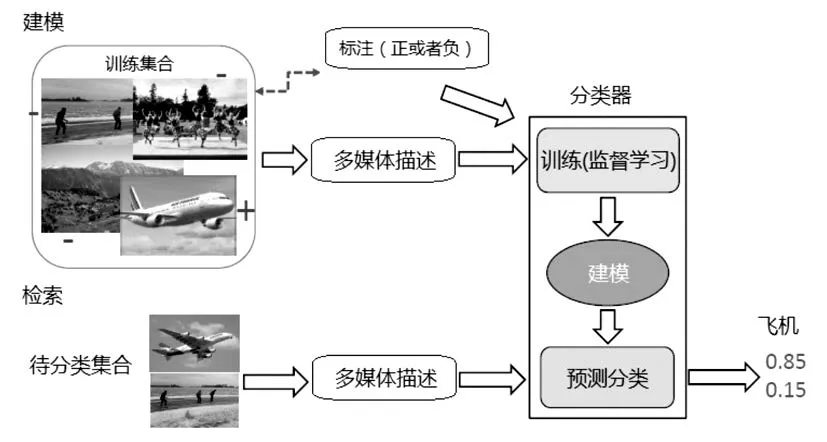
图2 基本内容多媒体检索体系结构
3 分类过程
分类是将一个实体中相似的部分结合成不同类别的过程。例如,书籍可以按他们的书名,作者或出版年份分类。在计算机科学中,分类本质上是基于机器学习技术,目的是学习目标类和每个样品特性之间的关系。因此需要一些例子来学习这些关系,称之为学习集。学习方法主要有两种:监督学习和和非监督学习。在监督学习中,训练集合中的每个例子是一对数据集,包含一个输入样本(例如直方图等低级别的特征描述)和目标输出值(例如标注为正或者负)。通过学习算法分析该训练集来产生分类器。而第二类型的无监督学习,可以发现在未标注数据中的隐藏结构问题。因为此时数据是未标记的,没有最小化误差。这在数据聚类问题中非常有用,其中最常用的算法是K-means(K-均值)。
监督学习算法是此次研究主要采用的方法,它有判别模型和生成模型。生成模型是指定的联合概率P(x,y),包括低级别的特征矢量x和其相关联的标记y。概率估计常见方法是将含有目标概念的数据的最大似然化,然后贝叶斯规则可以用来确定最可能的类。一方面,他们可以从部分标注数据学习,也可以在增量学习中使用。另一方面,识别模型被用于模拟一个不可观测变量y对所观察到的变量x的依赖。它可以被用来模拟条件概率分布P(y|x),从而实现从一个给定的x到y的预测。判别模型通常会对分类和不需要联合分布的回归过程产生非常好的效果。
一般而言,生成模型比判别模型在复杂学习任务表述依赖关系时更加灵活。然而,它需要比判别模型有更多的时间进行训练,于是提出了内核学习方法,一个典型例子就是支持向量机(SVM:Support Machine Learning)。其原理是希望用特殊的内核以克服非线性分离数据的问题,即将初始数据投影到高维空间,然后线性化解决问题。下文将介绍基于监督学习的支持向量机方法。
4 支持向量机
支持向量机(SVM)是一种非常流行和有效的数据分类学习方法。它的基本思想是,对于属于一个或两个类的一组数据样本,SVM是通过一个尽可能宽的分界区间,发现一个可以完美分离d维数据(到其两个类)的超平面,并最大化这两个类到超平面距离。

图3 二维空间线性分离
SVM的最大边缘超平面和超平面是通过两类样本的训练获得的。图3给出了SVM应用于二维空间线性分离,如图所示,在边缘上的样本称为支持向量,H表示超平面,它可以分离黑色和白色的样品。然而,由于数据样本通常不是线性可分离的,SVM的引入“内核诱导特征空间”的概念,通过内核函数将其中的数据映射到一个可以分离的高维空间。通常,内核函数是基于样品(描述体)的相似性,提供了比给定类的描述符本身更多的信息。
为了找到超平面分离器,利用拉格朗日算子选择支持向量的一个定义超平面的子集。这个过程有很大的好处,因为支撑向量简化和加速了索引的第一阶段(即建立模型),其中只有一部分支持向量会影响新样本的索引。即对于一个二元分类问题,给定一个大小为n的训练集T:
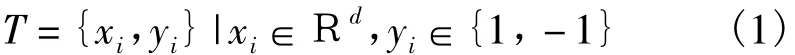
其中xi和yi分别表示训练矢量和目标值T中第i个样本,并且i=1,…,N。分类超平面被定义为:

其中Φ(.)是从数据集 Rd映射到更高维的Hilbert希尔伯特空间H,〈.,.〉表示在H超平面的点积,决定函数f(x)为:

支持向量机的目标是找到一个最佳超平面与两个预定义的类之间的最大间隔。这可通过转化为求解下面的二次优化问题来获得:
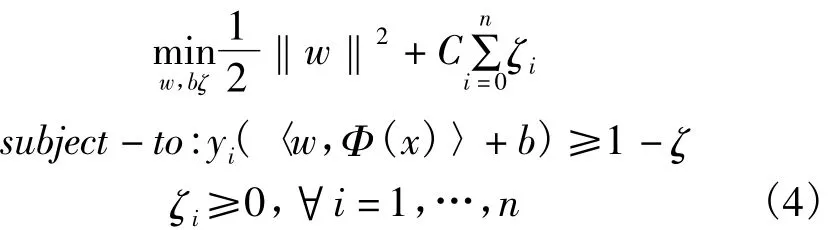
通过定义一个映射z=Φ(x)的变换将d维输入向量x映射到(通常较高)d维向量z。目标是选择一个Φ(),以便新的训练数据{Φ(xi),yi}是一个可分的超平面。值得注意的是,Φ(xi)是与其他Φ(xj)的点积。也就是说,如果知道公式(即内核),即对于用在高维特征空间中的点积:
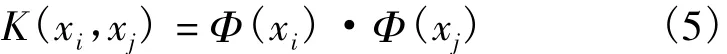
则不必直接处理映射z=Φ(xi)。最流行的内核是径向基函数(Radial Basis Function,RBF),也被称为高斯核函数,被定义为:
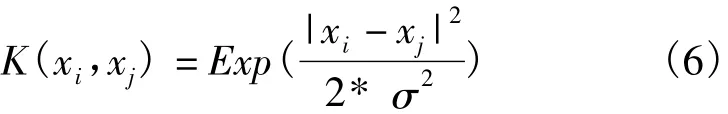
其中,|.|是 L2 欧式范数,xi,xj是两个不同的输入向量,σ是一个可调高斯参数,可通过固定交叉验证。这导致了一个称为内核矩阵或“克矩阵”的对称矩阵,它表示每对输入矢量之间的相似性。原则上,可以使用唯一的相似的功能,导致内核矩阵满足默瑟条件(正定的特征值)。
5 结论
本文通过研究基于内容的信息检索方法,根据机器学习理论,提出利用支持向量机的方法建立图像分类器,将用于访问系统数据。由于目前没有任何一种可适用于所有数据类型的分类器,应根据不同数据不断改进提高现有方法。
[1]SMEULDERS,A.W.M.,WORRING,M.,SANTINI,S.,GUPTA,A.and JAIN,R.Content-based image retrieval at the end of the early years.IEEE Trans.Pattern Anal.Mach.Intell,2000.
[2]B.SAFADIand G.QUENOT.Evaluations ofmulti-learners approaches for concepts indexing in video documents.RIAO,Apr 2010:88 -91,Paris,France.
[3]徐险峰.基于内容的多媒体信息检索技术[J].现代情报,2005,(3).
[4]CORTES,C.and VAPNIK,V.Support-vector networks.Machine Learning,1995,20.
[5]SCHOLKOPF,B.and SMOLA,A.J.Learning with Kernels:Support Vector Machines,Regularization,Optimization,and Beyond.MIT Press,2001,Cambridge,MA,USA.
猜你喜欢
数学年刊A辑(中文版)(2021年3期)2021-11-05
今日农业(2021年9期)2021-07-28
数学年刊A辑(中文版)(2021年2期)2021-07-17
开放教育研究(2020年2期)2020-03-31
数学物理学报(2019年1期)2019-03-21
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
新农业(2016年23期)2016-08-16
现代语文(2016年21期)2016-05-25
数学年刊A辑(中文版)(2015年1期)2015-10-30
