
新闻节目导语中关键词自动提取方法研究
2014-07-02 00:29:33何晓华朱津津
电视技术 2014年20期
何晓华,朱津津,凌 坚
(浙江传媒学院 电子信息学院,浙江 杭州 310018)
新闻节目导语中关键词自动提取方法研究
何晓华,朱津津,凌 坚
(浙江传媒学院 电子信息学院,浙江 杭州 310018)
利用词语在文本中的特征信息衡量词语与文本主题相关程度,提出了一种在新闻节目导语中提取关键词的方法,该方法综合了词频、位置分布等特征,组合词方案,并在词频、位置分布特征时考虑了同义词的影响,在实际使用中取得较好效果。
提取;节目导语;同义词;词语特征;组合词
随着新媒体和网络技术的发展,视频新闻节目从无差别的广播方式逐步向个性化、自主化的点播方式转变。为了让受众从海量视频新闻节目中检索到感兴趣的节目,系统必须提供有效的检索方式。直接视频检索存在着诸多的问题,关键词检索是目前广泛采用的有效方法。为了实现利用关键词检索新闻节目,首先要为每个节目提取合适的关键词,人工方法是通过观看整个节目或阅读节目文稿,根据个人理解提取节目的关键词,需要耗费大量的人力。因此,研究采用计算机从新闻节目中自动提取关键词的方法具有重要的实际意义。
国内外对关键词提取方法做了大量的研究,直接通过分析文本语义确定关键词目前还有着诸多困难,基本方法主要分为两大类:基于统计信息和机器学习。基于统计信息的方法选取单词或词组在文中的某些特征作为统计依据,常用的特征包括词频、TF-IDF、N-Gram、词长、出现位置等[1-2],此类方法简单易行,在单主题短文中有比较好的效果。在机器学习方法中,借助大量已标注的语料库作为训练集,通过训练特征参数构造分类模型,将关键词抽取问题转化为分类问题,或者将关键词视为一篇文章中重要且语义聚集的词语的代表,将关键词抽取问题转化为聚类问题。例如基于支持向量机、最大熵模型、相对熵算法、基于聚类的文本摘要等[3]。此类算法不需要训练集,通用性较好,但此类方法对输入样本的类别及聚类的类别数具有较高要求,很难完全覆盖整个样本空间,影响关键词提取质量。
此外,针对中文的语言特点提出了一些关键词提取方法,如条件随机场抽取、中文关键词Text Rank模型和同义词链等方法[4-5],已取得了较好的结果。目前,度量词语和内容关联程度、划分和组合词语等是关键词抽取方法的研究重点。本文针对新闻内容的特点,提出了一种在新闻视频节目导语中提取关键词的方法。该方法利用新闻视频中内容文本的特点,以词频、词性和词语位置为词语特征,计算词语和文本主题的相关程度,给出了组合词处理方法。
1 整体框架
关键词分析的对象是文本,因此,首先要从视频新闻节目中获取内容相关的文本,其主体是播音员播报的语言,称为导语。利用新闻节目制作时的文稿或通过语音识别、人工编目等方式获得新闻节目的导语。获取节目导语文本后,先对文本进行分词、确定词性,并过滤掉文本中与主题无关的词语,这些词语只用于语法结构,如“的”、“但是”等,称为停用词,剩下的词语作为关键词的候选词;然后通过对候选词的词频、词性和位置等信息的统计分析,确定各词汇与文本内容的相关程度。视频新闻节目的关键词提取的主体框架如图1所示。

图1 关键词提取的过程
2 词语特征选取和权重设置
基于统计信息提取关键词是利用词语某些统计特性与文本主题之间的相关性,把相关程度最高的词语作为文本的关键词。通过对新闻节目的分析统计,一个新闻单元一般只包含一个主题,导语文本经过分词和停用词过滤后的候选词不超过100个,相对比较短小。选用词频、词性位置作为统计特性,综合确定词语的权重。
2.1 词频权重
如果某个词语在文本中出现的次数越多,即词频越高,就越有可能成为关键词,但实际上因为中文表达中同义词的存在,比如“电脑”、“计算机”等词表示的是同一个或是十分相近的意思。有些词虽然在文中只出现了一次,但却也表达了比较重要的概念,根据常规的词频统计的方法,这个词很可能不会出现在关键词表中,但同时文中又出现了其同义词,因此,考虑把文中某个词的同义词一起统计计算该词的词频。这样就可以把一部分低频词语通过语义关系整理形成一些新的高频项。
本文中同义词依据《同义词词林扩展版》,《同义词词林》原版是梅家驹等人编写构造的,哈工大信息检索研究室在《同义词词林》的基础上对其进行了扩展。对经过分词并去除停用词等以后的文本进行处理,对处理后文本中的词,查找文中是否存在同义词,把第一个出现的同义词作为候选关键词并统计词频。本文采用一个归一化的词频计算方法,公式如下

式中:ni为候选词i的在文中出现的次数(含i的同义词出现的次数);freqi为候选词i的归一化词频。显然,词频权重和词频成正比是合理的。
2.2 词性
词语的词性对一个词能否成为关键词的影响很大。一般情况下,名词和动词成为关键词的可能性最大,地点和人物姓名也是非常重要的词语。基于这样的判断,设置词性权重计算公式为

式中:location和people指表示地点或人物,具体权重值可以按实际结果做相应调整。
2.3 词语出现位置
词语首次出现的位置和分布也能在一定程度上反映该词语与文本主题的关联程度,越靠前、分布范围大的词语则越是重要。由于词语在文本中的分布比较复杂,为简化计算,用该词在文中首次出现和末次出现的跨度来表示词语的分布,定义词语位置特征的权重为

式中:f_loci为词i在正文中首次出现的位置;N为文本中的词数总数;l_loci为词i末次出现位置。该公式考虑了词语或其同义词在文中首次位置和跨度。显然,首次出现越靠前、在文字中分布跨度越大,则该词与新闻主题关联越强,权重就越大。
2.4 组合词生成
关键词并不局限于单个词语,也可以是词语组合,事实上,词组往往更能反映文本主题。如果在文本中词相邻出现多次,很有可能是具有完整语义的词组的拆分。提取关键词是应该考虑把这样的词组合起来,得到一个意义表达更为丰富完整的组合词。例如,“索契冬奥会”一词在文本中同时出现多次,而分词系统将其拆分为“索契”和“冬奥会”。很明显,组合词表达了更为丰富的含义。组合词中的各个词语具有相似的权重,如果有多个相邻的词语具有相似的权重,应该将这些词语组合成一个关键词,并且以这些词语中最大权重为该词组的权重,参与关键词的选择。
3 关键词选择算法
综合以上各个特征和权重的分析,得到最终的权重计算公式如下
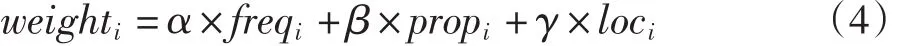
式中:α,β,γ为各个特征权重的比例因子,用以调整不同特征权重在最终权重的贡献度大小,一般可以通过实际效果决定,比如α=1.5,β=0.8,γ=0.6。
至此,本文设计了关键词提取的算法,该算法在为多家电视台存档的新闻视频节目进行编目处理中得到了应用,进行自动关键词提取,取得较好效果。算法过程如下:
1)输入视频,如果视频有对应的文稿,取文稿数据中的导语,转步骤3)。
2)分离伴音数据,调用语音识别模块,将语音识别内容作为导语。
3)利用分词模块,对导语文本进行分词,并对照停用词表,过滤停用词,确定词汇词性,生成候选词集。
4)按式(4)计算各个词汇的权重。
5)分析可能存在的组合词。
6)按权重大小排序,取最大的N个作为该新闻节目的关键词。
算法在计算词汇统计特征时考虑了同义词对关键词提取的影响,避免了遗漏合适的关键词或同义词同时选入的情况,对关键词选取的合理性有提高。
4 结束语
本文在分析视频新闻节目特点的基础上,提出了一种基于词语特征信息统计的关键词提取算法。首先通过综合词频、词性和词语的位置等典型的词语特征,计算词语和文本主题的相关程度,在分析词频和词语位置时考虑了同义词的影响,并提出了组合词的处理方法。算法在为多家电视台存档的新闻视频节目进行编目处理中得到应用,进行自动关键词提取,有效地减轻了人工劳动强度,降低了视频资源再利用的成本。
[1]李静月,李培峰,朱巧明.一种改进的TFIDF网页关键词提取方法[J].计算机应用与软件,2011,28(5):25-27.
[2]马颖华,王永成,苏贵洋,等.一种基于字同现频率的汉语文本主题抽取方法[J].计算机研究与发展,2003,40(6):874-878.
[3] 蒋昌金,彭宏,陈建超,等.基于组合词和同义词集的关键词提取算法[J].计算机应用研究,2010,27(8):2853-2856.
[4] 张颖颖,谢强,丁秋林.基于同义词链的中文关键词提取算法[J].计算机工程,2010,36(19):93-95.
[5]索红光,刘玉树,曾淑英.一种基于词汇链的关键词抽取方法[J].中文信息学报,2006,20(6):25-30.
Research on Automatic Keywords Extraction M ethod in News Programs Leads
HE Xiaohua,ZHU Jinjin,LING Jian
(School of Electronics and Information,Zhejiang University of Media and Communications,Hangzhou 310018,China)
A method of extracting keywords in news leads is proposed in this paper using multi-feature information of the words in the text as a measure of the relationship between the text topic and the words,and these features inclus statistical feature,position feature which considering the influence of synonyms and POS(Part of Speech)feature.In practice use,the method achieves better results.
extraction;news leads;synonym;words characteristic;compound words
TN948
A
何晓华(1975—),女,副教授,主要从事数字通信、视频处理的研究;
��健男
2014-04-06
【本文献信息】何晓华,朱津津,凌坚.新闻节目导语中关键词自动提取方法研究[J].电视技术,2014,38(20).
浙江广播电视技术研究所2013年科研项目
朱津津(1980—),女,实验师,主要从事电视技术的研究和应用;
凌 坚(1968—),副教授,主要从事智能多媒体、视频处理的研究。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
山西农业科学(2021年12期)2021-12-16 05:20:10
作文评点报·低幼版(2020年18期)2020-05-28 02:30:29
首都公共卫生(2019年5期)2019-05-21 01:08:48
新闻传播(2018年8期)2018-12-06 09:03:00
新闻传播(2018年11期)2018-08-29 08:15:30
戏曲研究(2017年2期)2017-11-13 03:10:03
新闻传播(2016年10期)2016-09-26 12:15:03
新闻传播(2015年9期)2015-07-18 11:04:11
读者·校园版(2015年7期)2015-05-14 13:11:40
