
基于结构化约束的多视角人体检测方法
2014-06-05 15:30郭晶云刘安安苏育挺
天津大学学报(自然科学与工程技术版) 2014年9期
张 静,郭晶云,刘安安,高 赞,苏育挺,张 哲
(1.天津大学电子信息工程学院,天津 300072;2.天津理工大学计算机与通讯工程学院,天津 300191;3.美国微软公司,华盛顿 98052)
基于结构化约束的多视角人体检测方法
张 静1,郭晶云1,刘安安1,高 赞2,苏育挺1,张 哲3
(1.天津大学电子信息工程学院,天津 300072;2.天津理工大学计算机与通讯工程学院,天津 300191;3.美国微软公司,华盛顿 98052)
针对单视角下信息量不足以及多视角不同视角间信息关联困难的问题,提出了基于结构化约束的多视角人体检测方法.首先通过基于块的人体检测模型获取人体局部块信息;然后采用空间仿射变换将不同视角下重叠区域通过变换矩阵的映射关系关联起来;最后针对仿射变换后的区域因遮挡或者存在多目标导致多视角目标关联困难的问题,利用人体局部显著块间的结构化约束为多视角目标匹配构造最大后验概率模型,通过最优求解获取多视角目标匹配结果.实验结果表明,该方法能够利用多视角信息来有效弥补单视角下人体检测中出现的遮挡问题,显著提高了人体检测效果.
多视角;结构化约束;仿射变换;最大后验概率;目标匹配
多媒体技术已经有多年的发展历史,随着声音、视频、图像压缩等基础技术的日益成熟并进入市场,计算机视觉、机器学习领域也逐渐走入人们视野.人体检测是计算机视觉和机器学习领域的研究热点,也是人机交互、智能监控等领域的基础,人体检测的效果对这些领域的应用具有非常重要的意义.
传统人体检测方法主要是单视角下目标检测方法[1-7],通常是利用单一视角采集视频中人体区域特征进行模型学习,从而实现目标检测.该方法的优点在于通过单一视角信息即可检测人体目标,然而由于人体非刚体运动的复杂性,以及单视角信息的局限性,使该类方法的检测模型在视角变化时往往性能较低.为了克服单视角信息的不足,多传感器融合的方法被一些学者所应用[8-9].Zhang等[8]提出了一种多传感器融合的目标检测方法,其优点在于通过激光扫描的方式获取感兴趣区域,从而辅助提高目标检测的准确率.然而,这种方式依赖于外界附加设备,不适于目前广泛使用的视频监控网络.针对该问题,多视角信息融合的目标检测方法逐渐成为当前研究热点[10-12].Kim 等[11]提出通过将两个视角的人体位置信息映射到水平面来获取位置信息,从而利用多视角信息实现目标检测.该方法无需复杂的3D场景重定标和建模,然而由于这种方法是通过视角间的信息间接获取水平面位置信息,因此往往存在位置偏差,从而导致单一视角下被检测目标区域与其他目标区域重叠,无法将被检测区域与其他目标区域区分开来.
针对上述问题,本文提出了基于结构化约束的多视角人体检测方法.首先,获取运动前景,在前景区域采用基于块的人体检测模型及人体 8个局部显著块信息;其次,采用空间仿射变换将不同视角下重叠区域通过变换矩阵的映射关系关联起来,这样利用仿射变换可以将一个视角下检测到的人体映射到未检测人体的视角上,达到信息互补的效果;最后,针对仿射变换后的区域因遮挡或者存在多目标导致多视角目标关联困难这一问题,利用人体局部显著块间的结构化约束为多视角目标匹配构造最大后验概率模型,通过最优求解获取多视角目标匹配结果.实验结果表明,采用本方法能够有效利用多视角信息来提高检测准确率.
1 基于结构化约束的多视角人体检测方法
为了得到多视角下人体检测以及关联信息,首先要得到单视角下人体检测信息.对于不同视角下人体信息的关联,分两种情况进行描述:①在未出现遮挡以及多目标的情况下,采用空间仿射变换来解决目标关联;②对于遮挡或者多目标距离很近的情况,利用基于块的检测模型,在此基础上利用得到的人体显著块信息获取目标最佳匹配.单视角人体检测以及多视角间信息关联具体描述如下.
(1) 单视角下人体检测和人体分块区域的提取.为了降低背景区域对人体检测的干扰以及提高人体检测速度,首先对每个视角进行背景建模[13],并通过与前景相减求差来获取前景人体运动区域.在获取前景区域后,采用基于块的人体检测模型[14]进行人体检测,获取人体的 8个局部显著区域,为多视角间目标关联提供更多信息.
(2) 基于空间仿射变换的多视角人体区域关联.通过两两相邻视角下标定点的设置和仿射变换矩阵[15]的计算获取多视角间关联信息,从而实现某一视角上的点与其他视角间的空间对应关系.
(3) 基于结构化约束的多视角人体检测.图 1所示为4个视角下的人体检测信息,蓝色区域为检测到的人体,红色区域为映射得到的人体区域,粉色虚线框为关联候选区域.空间仿射变换进行视角间映射时通常会遇到两种情况:①直接关联,对应区域范围内只有一个目标,可以进行直接关联(如图 1红框标记);②关联候选,对应区域内可能存在目标遮挡或者多目标距离很近(如图 1紫色虚标记).针对上述两种情况仅通过仿射变换往往会造成多目标关联错误,因此将前景区域包含多人的情况选作“关联候选区域”,通过第 1.2节所提出的基于结构化约束的多视角人体检测实现最优匹配.
下文详细介绍了该方法的两个核心部分——基于块的人体检测模型和基于结构化约束(人体分块约束)的多视角目标关联方法.
1.1 基于块的人体检测模型
基于分块信息的目标检测模型[14]能够综合利用目标局部显著性特征进行各部分检测,在此基础上形成对目标检测的最终判决,从而提高目标检测的鲁棒性.
针对人体检测问题,所构造的基于分块信息的目标检测模型由 1个全局检测子和 8个肢体分块检测子(分别对应人体的双臂、双腿、双脚、头及其他共 8个区域)联合构成.利用该模型,在图像中检测得到的该区域包含人体的似然为
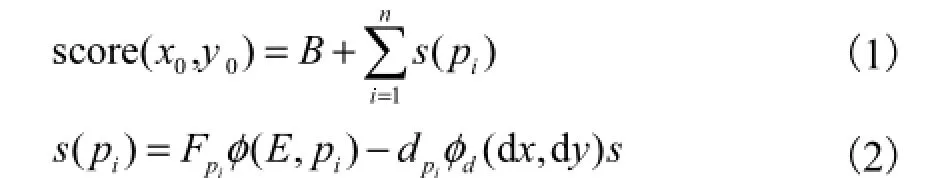
该模型学习和推断具体方法参见文献[14].利用式(1)的检测模型对图像进行遍历检测,获取每个位置包含人体的似然,然后通过阈值限制检测图像中所包含的人体位置.

图1 4个视角下的人体检测信息Fig.1 Human detection information in 4 views
图2所示为基于该模型的检测结果样例,棕色为最终检测标记出的人体信息,其他8种颜色分别表示所检测出的各个块对应信息.此外,该幅图中人体区域均无法通过经典的基于分块梯度直方图特征和支持向量机模型的人体检测经典方法[16]进行准确检测,其原因在于该图像采集摄像头与人体运动平面有较大倾角.因此,通过对比可见,基于分块信息的目标检测模型通过人体分块信息的融合对视角变化具有更强的鲁棒性.

图2 基于分块信息的目标检测结果实例Fig.2 Instance of human detection by part-based information
1.2 基于人体分块约束的多视角目标关联
多视角目标检测的主要问题是由于空间仿射变换映射位置偏移以及视角不同导致的目标区域与其他人体区域的遮挡.因此,在获取多视角人体检测及分块信息后,关键问题在于各视角独立检测所得目标的多视角关联.
1.2.1 目标函数的构建
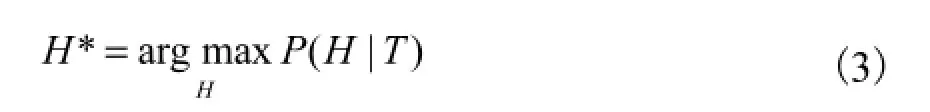
假设 H中每个块信息都相互独立,则上述最优化问题可以转化为
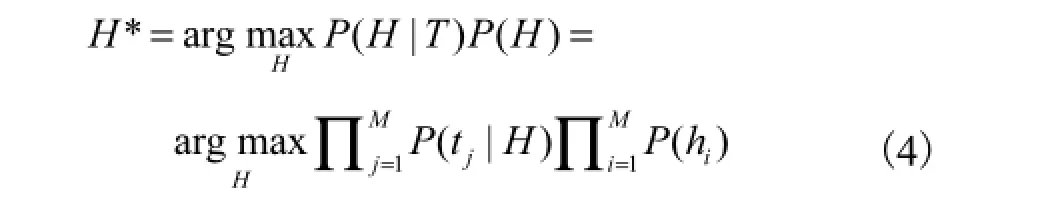
式(4)中2个重要因子分析如下.

(2) 对于两两视角下人体块信息关联,ih包含 2个块区域和,因此基于马尔科夫性,P ( hi)可表示为

通过式(3)~(7),式(3)所示最大后验概率问题可以转化为
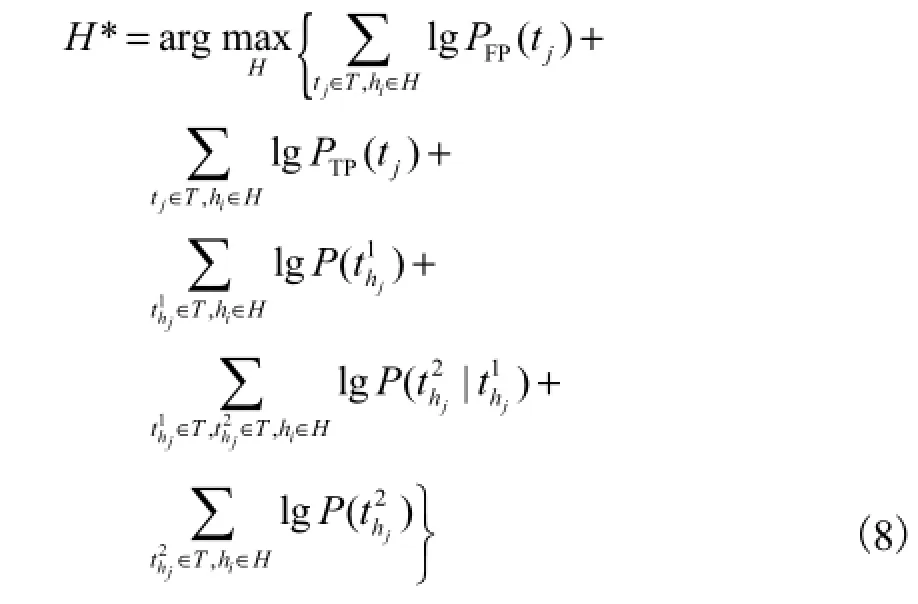
1.2.2 目标函数求解
该最优化问题可以通过线性规划来求解:假设M 为人体块信息的数目,包括块匹配的每种可能情况,是对能够进行匹配的块信息在空间上的限制.β和C可以通过如下方式获得.
人体的块检测信息与对应的人体块区域空间分布有一定空间限制,这样如果A视角块1jt与B视角块2jt之间的空间距离超过一定限制,可以认为这种状态转移不成立.C和β可以定义为

在获取A视角M个块信息与B视角M个块信息可能的对应关系后,最优化问题就转换成在块信息不冲突情况下寻求所有块匹配似然的最大化问题,上述问题也就转化为线性规划问题,即

通过上述人体匹配算法,能够在视角变换以及人体区域信息差异较大的情况下,通过利用人体显著块信息的最优匹配获取遮挡或者多目标人体情况下的最佳目标关联.
2 实验及结果分析
为了评测所提出方法的性能,根据实验需求,笔者采集并构建了多视角信息融合的目标检测数据集.该数据集在室内 4个视角环境下进行采集,视频序列分别包含3个人和5个人两种难度(分别为331帧和394帧),一共标记了2,254个人体,包含非遮挡和局部遮挡情况.由于要检验映射效果,遮挡条件情况下的人体也要标注,这样才能统计映射后的检测效果提高情况.
为了证明该方法的优越性,笔者用两种有代表性的多视角人体检测方法作为比较实验.
(1) 基于多视角空间位置信息融合方法[11].通过人工标定位置信息来达到视角间映射效果.先将地面进行分块,每一块有一个标号,这样不同视角下的信息就会对应起来.然而在实验过程中发现,由于网格的远近会发生尺度变化,这种粗粒度映射方法对定位的精确度会产生很大的影响.因此,实验中笔者改进了该方法,采用能够精确定位位置信息的仿射变换来进行视角映射,因为仿射变换建立的对应关系是像素级的,这样就可以找出不同视角的精确对应关系,达到更好的视角映射效果.
(2) 基于概率化分布图(probabilistic occupancy map,POM)方法[17].笔者基于概率化分布图构建理论分别构建各视角人体区域的后验概率分布来实现多视角信息融合.
为了证明多视角信息有助于提高目标检测性能,笔者设计了两组实验,实验结果如表1所示.
(1) 融合前.仅采用目标检测模型对单一视角视频进行目标检测,然后统计查全率和查准率进行性能评价.如果检测模型定位的人体区域与人工标注的真实人体区域重合度大于50%,则认为该检测模型能够正确定位人体区域.对于基于多视角空间位置信息融合方法[11]和基于概率化分布图方法[17],笔者采用了标准的单视角下目标检测方法[16].对于本文提出方法,采用了第1.1节介绍的基于块的人体检测模型[14].
(2) 融合后.采用不同多视角信息融合方式进行多视角人体检测,并采用查全率和查准率进行性能评价.当且仅当同一个人体在不同视角下定位区域与各视角下真实位置重合度高于50%时,认为该方法能够正确检测目标区域.
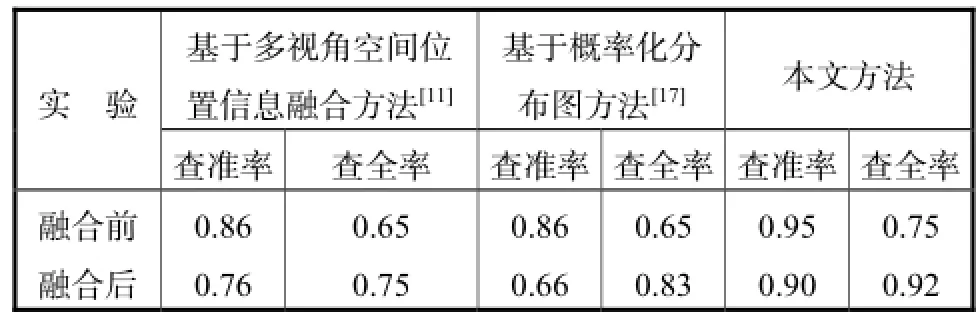
表1 实验结果比较Tab.1 Comparison of experimental results
对表1中的实验结果分析如下.
(1) 对融合前(单视角)人体检测结果进行统计发现,由于所构建实验数据集具有显著的视角变化以及目标间遮挡,因此采用标准的单视角下目标检测方法[16]进行目标检测效果不佳,查全率和查准率仅能分别达到0.65和0.86.相对而言,基于块的目标检测模型能够综合利用人体各显著块区域特征进行人体定位,因此有利于克服遮挡造成的检测困难,因此查全率和查准率均提高约10%.
(2) 引入多视角信息,可以利用目标在不同视角下信息弥补单视角下由于显著视角变化造成的目标漏检,因此 3类方法融合后的查全率均有显著提高,但是查准率均有所下降.比较而言,本文所提出方法能够在显著提高查全率(提高 17%)的情况下保持较高查准率(仅下降5%).
(3) 基于多视角空间位置信息融合方法[11]实验结果分析.从融合后结果可以看到,由于多视角信息的引入,在某个视角未检测到的对象可以通过其他视角对该对象的检测和空间映射关系进行恢复,因此查全率有所提高.但是因为基于仿射变换的方法在空间对应问题上往往受到多个相互遮挡的目标的干扰,从而导致目标检测准确率的显著下降.
(4) 基于概率化分布图方法[17]实验结果分析,相对于基于多视角空间位置信息融合方法,该方法直接利用空间仿射变换进行多视角目标关联,计算各视角下目标在不同位置出现的概率,从而实现更为灵活的多视角关联,有利于进一步避免单视角下漏检,因此能够进一步提高查全率(0.83).与基于多视角空间位置信息融合方法一样,该方法不能很好地解决遮挡目标的相互干扰,因此目标检测查准率较低(0.66).
(5) 本文所提出方法实验结果分析.首先,本文提出方法避免了前两种方法对于空间位置信息的依赖,直接采用目标区域的视觉特征进行多视角关联,从而实现多视角信息的融合,因此该方法能够进一步提高查全率(0.92).其次,该方法将多视角下目标匹配转化为基于人体块区域结构化约束的最大后验概率问题,通过最优求解获取多视角目标匹配结果,因此能够有效解决多目标遮挡带来的检测困难.但是,实验中发现,当多目标遮挡区域较大时,基于块的检测模型无法获取有效的人体局部块视觉特征,导致多视角块特征相似度计算得不准确,因此准确率有所下降.通过表 1可知,该方法可以在显著提高查全率的同时保持较高的查准率(0.90),如图 3所示(椭圆标记的为采用文献[16]方法的检测结果,矩形框标记的为采用本文方法的检测结果).
通过上述分析和比较可见,基于结构化约束的多视角人体检测方法能够有效利用多视角信息实现更准确和鲁棒的目标检测.
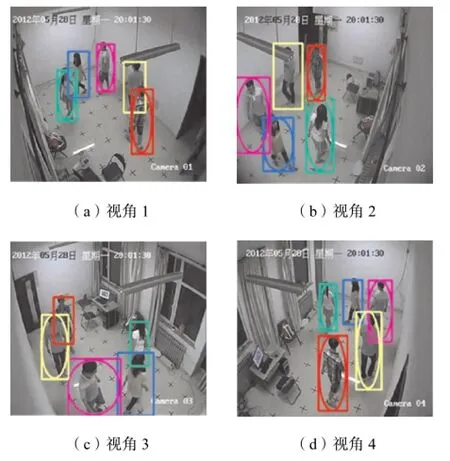
图3 基于分块信息的目标检测模型和本文提出方法的检测结果Fig.3 Results of model based on part-based human detection and proposed method
3 结 语
本文提出了基于结构化约束的多视角人体检测方法.该方法通过基于块的人体检测模型获取人体局部块信息,然后采用空间仿射变换将不同视角下重叠区域通过变换矩阵的映射关系关联起来,最后针对仿射变换后的区域因遮挡或者存在多目标导致多视角目标关联困难这一问题,利用人体局部显著块间的结构化约束为多视角目标匹配构造最大后验概率模型,通过最优求解获取多视角目标匹配结果.比较实验结果表明,本方法能够有效利用多视角信息来弥补单视角下人体检测中出现的漏检和遮挡问题,显著提高人体检测效果.
参考文献:
[1] Rossi M,Bozzoli A. Tracking and counting moving people[C]// IEEE International Conference on Image Processing. Austin,USA,1994:212-216.
[2] Cucchiara R,Grana C,Piccardi M,et al. Detecting moving objects,ghosts,and shadows in video streams[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(PAMI),2003,25(10):1337-1342.
[3] Yoon Sang Min,Kim Hyunwoo. Real-time multiple people detection using skin color,motion and appearance information[C]// 13th IEEE International Workshop on Robot and Human Interactive Communication. Kurashiki,Okayama,Japan,2004:331-334.
[4] Dalal N,Triggs B,Schmid C. Human detection using oriented histograms of flow and appearance[C]// European Conference on Computer Vision(ECCV). Graz,Austria,2006:7-13.
[5] Cucchiara R,Grana C,Piccardi M,et al. Using boosted features for the detection of people in 2D range data[C]// 2007 IEEE International Conference on Robotics and Automation. Beijing,China,2007:3402-3407.
[6] Chakraborty Bhaskar,Rudovic Ognjen,Gonz`alez Jordi. View-invariant human-body detection with extension to human action recognition using component-wise HMM of body parts[C]// 8th IEEE International Conference on Automatic Face and Gesture Recognition. Amsterdam,the Netherlands,2008:1-6.
[7] García-MartínÁlvaro,Hauptmann Alex,José M Martinez. People detection based on appearance and motion models[C]// 8th IEEE International Conference on Advanced Video and Signal-Based Surveillance(AVSS). Klagenfurt,Austria,2011:256-260.
[8] Zhang Zhengzhi,Kodagoda K R S. Multi-sensor approach for people detection[C]// Proceedings of the 2005 International Conference on Intelligent Sensors,Sensor Networks and Information Processing Conference. Melbourne,Australia,2005:355-360.
[9] Ros J,Mekhnacha K. Multi-sensor human tracking with the Bayesian occupancy filter[C]//16th International Conference on Digital Signal Processing.Santorini,Greece,2009:1-8.
[10] Dockstader S,Tekalp A M. Multiple camera tracking of interacting and occluded human motion[J]. Proceedings of the IEEE,2001,89(10):1441-1455.
[11] Kim Kyungnam,Davis L S. Multi-camera tracking and segmentation of occluded people on ground plane using search-guided particle filtering[C]// ECCV'06 Proceedings of the 9th European Conference on Computer Vision. San Diego,USA,2006:98-109.
[12] Zeng Chengbin,Ma Huadong. Human detection using multi-camera and 3D scene knowledge[C]//18th IEEE International Conference on Image Processing. Brussels,Belgium,2011:1793-1796.
[13] Kim Kyungnam,Chalidabhongse T H,Harwood D,et al. Real-time foreground background segmentation using codebook model[J]. Real-Time Imaging,2005,11(3):172-185.
[14] Felzenszwalb P F,Girshick R B,McAllester D,et al. Object detection with discriminatively trained part based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(PAMI),2010,32(8):1627-1645.
[15] Ghali S. Introduction to Geometric Computing[M]. London:Springer Verlag,2008.
[16] Dalal Navneet,Triggs B. Histograms of oriented gradients for human detection[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR). San Diego,USA,2005,32(9):886-893.
[17] Fleuret F,Berclaz J,Lengagne J,et al. Multicamera people tracking with a probabilistic occupancy map[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(PAMI),2008,30(2):267-282.
(责任编辑:金顺爱)
Multi-View Body Structure-Constrainted Human Detection Method
Zhang Jing1,Guo Jingyun1,Liu An′an1,Gao Zan2,Su Yuting1,Zhang Zhe3
(1. School of Electronic Information Engineering,Tianjin University,Tianjin 300072,China;2. School of Computer and Communication Engineering,Tianjin University of Technology,Tianjin 300191,China;3. Microsoft,WA 98052,USA)
To solve the problems of lack of information in single-view and the difficulty in information correspondence in different views,a multi-view body structure-constrainted human detection method was proposed. First,part-based human detection model is implemented to obtain the information on human body part. Then leverage spatial affine transform to correlate the overlapping regions in different views. Finally,to overcome the challenge of object corresponding in multi-view environment caused by partial occlusion and multiple target existence in neighborhood,the model of maximum a posterior(MAP)is developed for multi-view object matching by taking advantage of the body structure constraints. The multi-view object matching result can be achieved by optimizing the objective function of the modal.The experimental results show that the proposed method can improve human detection by efficiently using multi-view cues to avoid partial occlusion in single-view.
multi-view;structural-constraint;affine transform;maximum a posterior(MAP);object matching
TP391.4
:A
:0493-2137(2014)09-0753-06
10.11784/tdxbz201305040
2013-05-18;
2013-08-18.
国家自然科学基金资助项目(61100124,21106095,61202168,61170239);天津市应用基础与前沿技术研究计划资助项目(10JCYBJC25500).
张 静(1972— ),女,博士,副教授,zhangjing@tju.edu.cn.
刘安安,anan0422@gmail.com.
时间:2014-01-03.
http://www.cnki.net/kcms/doi/10.11784/tdxbz201305040.html.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(趣味科学)(2022年1期)2022-04-26
房地产导刊(2022年4期)2022-04-19
大科技·百科新说(2021年10期)2021-12-31
新世纪智能(数学备考)(2021年9期)2021-11-24
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
当代陕西(2019年15期)2019-09-02
小猕猴学习画刊·下半月(2019年6期)2019-08-13
中山大学学报(自然科学版)(中英文)(2018年4期)2018-08-08
特别健康(2018年3期)2018-07-04
