
煤调湿系统蒸汽消耗量的多模型建模研究
2014-05-25 00:34:29王建华罗雷涛耿佳灿
自动化仪表 2014年12期
王建华罗雷涛耿佳灿
(上海应用技术学院电气与电子工程学院1,上海 201418;华东理工大学化工过程先进控制与优化技术教育部重点实验室2,上海 200237)
煤调湿系统蒸汽消耗量的多模型建模研究
王建华1罗雷涛2耿佳灿2
(上海应用技术学院电气与电子工程学院1,上海 201418;华东理工大学化工过程先进控制与优化技术教育部重点实验室2,上海 200237)
煤调湿工艺是炼焦过程的关键技术,建立煤调湿系统的蒸汽消耗量软测量模型对节约生产成本、减少环境污染和提高焦炭质量具有促进作用。针对某炼铁厂煤调湿装置的非线性、强耦合、工况波动大等特点,提出了一种多模型建模方法。对模糊核C均值聚类引入了基于密度的聚类中心初始化方法和聚类数目自适应策略,并将其用于生产工况最优划分;使用最小二乘支持向量机对每个子工况进行数据驱动建模,并利用贝叶斯证据框架优化最小二乘支持向量机的超参数。检验结果表明,所提出的煤调湿系统蒸汽消耗量多模型具有良好的跟踪性能与较高的预测精度。
煤调湿 模糊核C均值聚类 最小二乘支持向量机(LSSVM) 贝叶斯证据框架 多模型
0 引言
煤调湿工艺(coal moisture control,CMC)是焦炭炼制过程的一种预处理技术。CMC通过焦化生产的余热对炼焦煤进行直接或间接的加热,使其中的水分降低到一定的程度,从而保证焦炉能在稳定的条件下生产,以达到提高焦炉生产能力、降低炼焦能耗、改善焦炭质量的目的。煤调湿系统是复杂的非线性系统,其精确的数学模型难以建立。基于能量平衡机理的煤调湿蒸汽消耗量预测模型精度较低,难以适用于复杂的现场生产。数据驱动建模是一种有效的化工过程建模技术,已被成功应用于各种工业过程[1]。传统建模技术的研究集中在各种建模方法的改进,如人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine,SVM)、高斯过程(Gaussian process,GP)等。但是,实际的工业过程往往伴随着多变量、强耦合、工况浮动大等特点,难以用单一的模型精确描述。
近年来,复杂工业过程的多模型建模方法得到了越来越多的研究。多模型建模方法根据工况的不同将系统划分成不同的子区间,建立每个子区间对应的模型,全局过程的输出为子模型的输出加权求和[2]。这种方法在提高模型精度的同时降低了模型的复杂度,弥补了单一模型难以真正描述全局模型的缺点。多模型建模可分为聚类和建模两个步骤,子工况的划分和建模方法的选择对于全局模型效果影响甚大,应根据不同的研究对象确定合适的聚类方法与建模策略。孙建平等[3]依据负荷和主蒸汽温度,使用双层K均值聚类将某电厂的生产过程划分为不同工况,并使用最小二乘支持向量机(least squares support vector machine, LSSVM)建立了不同工况下的模型。Yu等[4]使用多核高斯过程回归和贝叶斯模型平均理论建立了批处理过程的多模型预测方法。陈贵华等[5]提出使用模糊核聚类对石脑油数据库进行最优划分,建立了基于LSSVM的乙烯裂解深度的多模型,并使用差分进化算法对模型参数寻优,模型跟踪性能良好。
本文针对煤调湿过程蒸汽消耗量预测问题,提出了一种多模型建模方法。使用模糊核C均值聚类(fuzzy kernel C-means clustering,FKCM)对某炼铁厂煤调湿过程的生产工况进行自适应聚类。将工况划分为不同的子区间,将LSSVM应用于各子区间的数据驱动建模;并通过贝叶斯证据框架(Bayesian evidence framework,BEF)的三层推断对LSSVM的超参数进行优化;最后利用输入向量的模糊隶属度加权输出煤调湿过程的蒸汽消耗量预测值。以该厂数据的实际生产数据进行模型检验,检验结果表明了该多模型建模方法的有效性。
1 煤调湿工艺介绍
在高炉炼铁炼钢及铸造工业生产中,焦炭是不可缺少的主要燃料,焦炭的质量直接影响到炼铁和铸造的质量。炼焦是指将煤在隔绝空气的条件下高温加热至950~1 050℃,经过干燥、热解、熔融、粘结、固化和收缩等加工工艺后,最终制成焦炭。炼焦过程主要在焦炉内进行,由于有水的存在,煤中的水分最先在炼焦炉内蒸发汽化成水蒸气,这就浪费掉了部分宝贵的煤气资源,同时降低了炉墙的表面温度,对炭化室墙面也有腐蚀,影响了焦炉炉体严密性,无形中增加了炼焦煤气的成本。因此,炼焦煤一般都需要经过煤调湿工艺进行干燥预处理,使入炉煤的水分降低到5%~6%。
某炼铁厂的煤调湿采用多管回转式干燥机间接加热方式,其工艺流程如图1所示。图1中的蒸汽管式间接加热转筒干燥器是该套装置的主体设备。从湿煤料槽进入转筒干燥机管间的湿煤,由于转筒干燥器的旋转而向前流动,与其内部走管内的低压蒸汽进行间接换热,煤料与蒸汽逆向流动。由于煤料被加热后会产生大量水汽,因此在煤料入口处通入焦炉烟道气作为载气,以吹走这些水汽,而通入管内的低压蒸汽在换热后转换成饱和水,从蒸汽管式间接加热转筒干燥器中间的一根管子集中后流出,再送入干熄焦锅炉的纯水系统。被载气从蒸汽管式间接加热转筒干燥器中吹出的大量含尘废气将进入除尘系统,经除尘后排放。而集尘产生的煤粉经加湿后会回配到煤处理流程中。该工艺所用热源为炼焦厂干熄焦蒸汽发电后的低压蒸汽(1.6 MPa,260℃),装置可将含水量9.1%~12.2%的湿煤干燥处理成6.5%~6.9%的调湿煤。
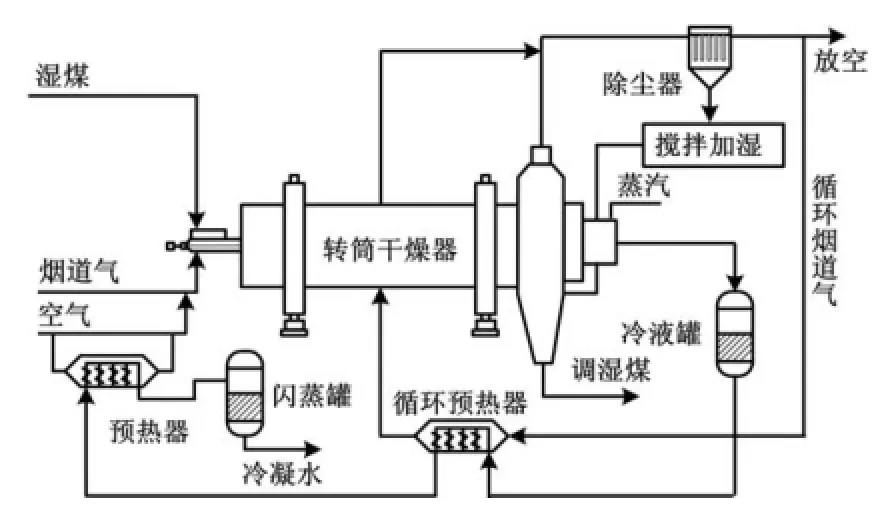
图1 煤调湿过程工艺流程Fig.1 Technological process of the coal moisture control
在实际生产中,煤调湿过程的主要目的是控制好出口煤湿度,在不投入过多成本的情况下使得出口煤湿度满足后续装置的生产要求。由于生产过程中湿煤的传输速度一般是固定的,因此控制出口煤湿度的关键是控制蒸汽消耗量。虽然煤调湿过程是一个不涉及化学反应的换热过程,但由于其涉及到的控制回路较多,它仍然是一个多参数、强耦合、非线性并且大时滞的复杂系统。在该厂生产中,主要由操作人员根据经验对蒸汽流量进行调节。由于不同班组、不同操作工对作业参数的理解不同,并不能准确地把握蒸汽消耗量,造成出口煤湿度波动较大,影响炼焦炉的平稳运行,因此十分有必要建立煤调湿系统的蒸汽消耗量模型,在指定出口煤湿度的情况下计算出相应的蒸汽流量。由于实际生产过程中的工况浮动范围较大,因此本文考虑使用多模型建模技术对煤调湿过程进行模型分析与求解。
2 模糊核聚类算法
2.1 模糊核C均值聚类
模糊C均值聚类(FCM)是Bezdek于1981年提出的一种用隶属度确定每个样本属于某个聚类的程度的一种聚类算法,其主要思想是将数据的聚类转化成非线性优化问题,并通过迭代进行聚类中心和隶属度的求解。其聚类准则函数为:
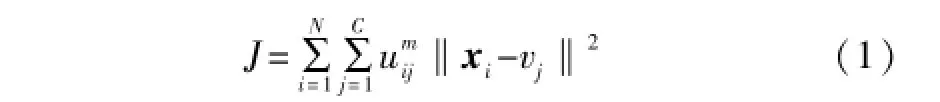
式中:N为分类样本总数;C为聚类个数;xi为待分类的样本向量;vj为聚类中心;m>1为加权参数;uij为样本xi对应于第j个聚类的隶属度。
FCM即寻找一种最佳分类,使目标函数J取得最小值。模糊C均值聚类难以处理分类边界为非线性或者样本集很大的情况[6],这种情况可通过引入核函数的方法得到解决。模糊核C均值聚类(FKCM)即采用非线性映射x→φ(x)将数据映射到高维空间,把低维空间中的线性不可分问题转换成高维空间中的线性可分问题。在高维特征空间中,样本的距离定义为:
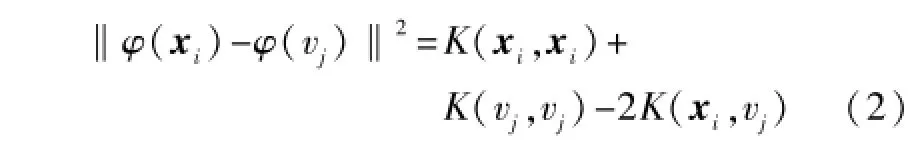
式中:K为核函数。
在本文中,采用高斯核函数,即:
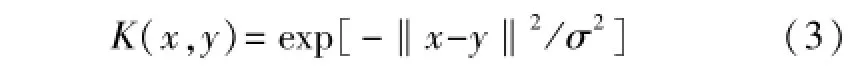
式中:σ为高斯核参数。
由给定样本集,σ确定为:

对于式(1)和式(2),构造拉格朗日函数并分别对u和v求偏导,可得FKCM算法的聚类中心vj和隶属度uij的更新公式,即:
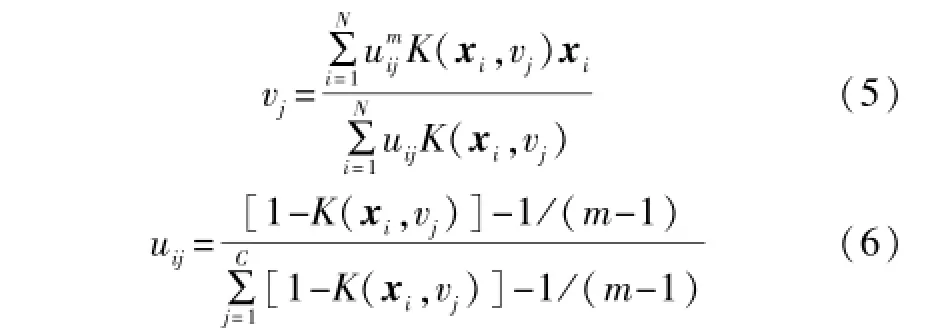
2.2 基于密度的聚类中心初始化
同其他聚类方法一样,FKCM算法的性能同样依赖于初始聚类中心的选取,较好的初始聚类中心不仅能够加快算法收敛速度,而且能提高分类精度。在聚类算法中,一般选取k个距离最远的数据作为初始聚类中心,这些数据在一定程度上能够代表数据的分布特征。文献[7]采取聚类对象分布密度方法来确定初始聚类中心,选择相互距离最远的k个高密度区域的点作为初始聚类中心。该方法定义了一个密度参数:以样本点xi为中心,包含常数Minpts个数据对象的半径称为xi的密度参数,记为ε。ε越大,说明样本点所处的区域数据密度越低。基于密度的聚类中心初始化方法首先计算每个样本点的密度参数,删除密度参数过大的低密度区域的样本,得到高密度样本点集合D。然后取集合D中密度参数最小的点作为第一个聚类中心点c1,集合D中离c1最远的点作为第二个聚类中心点c2,计算集合D中各样本xi到聚类中心c1和c2的距离,c3为满足max{min[d(xi,c1)],min[d(xi,c2)]}的样本点。以此类推,ck为满足max{min[d(xi,c1)],min[d(xi,c2)],…,min[d(xi,ck-1)]}的样本点。依此得到k个初始聚类中心。
2.3 聚类数目的自适应策略
对于某些分类问题来说,聚类数目是固定的。但是对于类似于工况子区间划分的问题,则需要给定聚类个数,这在一定程度上降低了算法的无监督性,一旦设定的聚类数目不合理,将直接影响分类模型的使用效果。由于优秀的聚类划分应当使得各类内样本距离尽可能小,而不同类间距离尽可能大。本文使用著名的Xie-Beni指标[8]来评价聚类的质量。
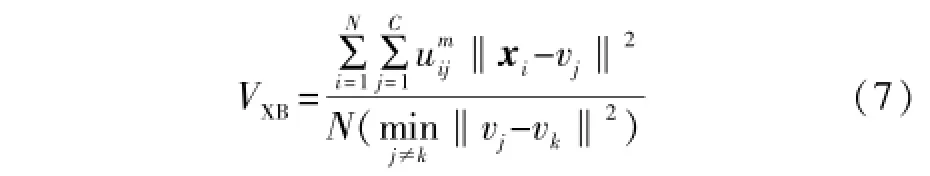
因此,当VXB取极小值时聚类划分最理想。将Xie-Beni指标推广到核空间,即有:
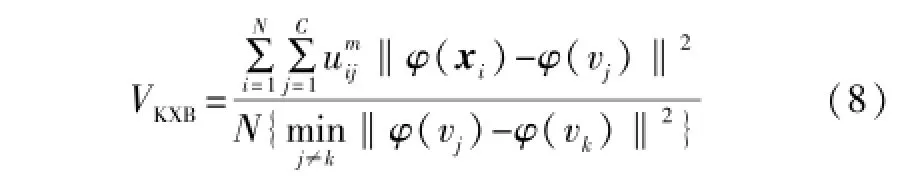
当VKXB取极小值时聚类数目最理想,记聚类数目为C时的Xie-Beni指标为VKXB(C),则本文所使用的模糊核C均值聚类方法描述如下。
①确定算法参数,包括加权参数m、算法最大迭代次数tmax、允许误差ξ和密度常数Minpts,初始聚类数目C=2。
②采用基于密度的聚类中心初始化策略初始化聚类中心。
③根据式(5)和式(6)更新聚类中心V(t+1)和隶属度矩阵U(t+1),t代表迭代次数。
④若‖U(t+1)-U(t)‖<ξ或t=tmax,则停止迭代,否则t=t+1,转步骤③。
⑤按式(8)计算VKXB(c)。若VKXB(C-1)<VKXB(C-2)且VKXB(C-1)<VKXB(C),则算法过程结束,转步骤⑥;否则,C=C+1,转步骤②。
⑥输出对应的最优聚类数目C=C-1以及对应的聚类中心和隶属度矩阵。
3 基于贝叶斯证据框架的LSSVM多模型
3.1 最小二乘支持向量机概述
LSSVM是在统计学习理论基础上发展起来的一种回归与建模方法,它的原型是SVM。与SVM相比, LSSVM采用等式约束取代了传统支持向量机中的不等式约束,使用误差的平方和作为松弛变量,把传统SVM的解带约束条件的二次规划问题转化为求解线性方程组问题,从而降低了计算复杂度,提高了算法的求解速度。
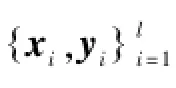
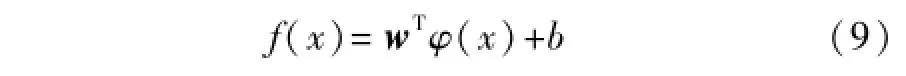
式中:x∈Rn,f(x)∈R;φ(x)为输入向量x在高维空间中的映射。
基于LSSVM采用的结构风险最小化原理,求解式(9)中的w和b即等价于优化问题。

式中:ξ∈Rl×1为误差向量;c(c>0)为LSSVM的正规化参数。
对于该问题,可采用拉格朗日法进行求解。引入拉格朗日因子a,则该问题可转化为:
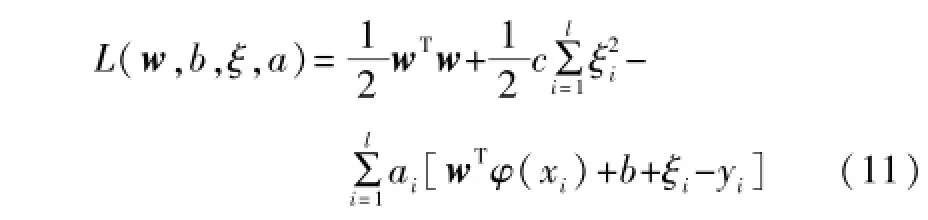
进一步可得:
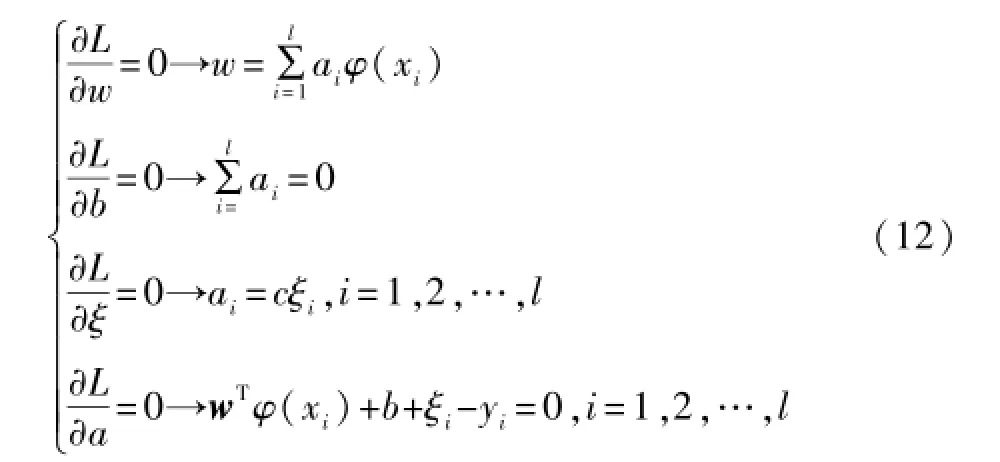
通过引入核函数K(xi,xj)=φ(xi)·φ(xj)的概念,可以不用具体地计算非线性映射φ(·)即可非常方便地求解式(12),最终可得到LSSVM所需求解的线性方程组。
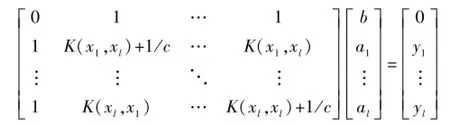
通过求解线性方程组,最终可得到式(13)所示的非线性模型。
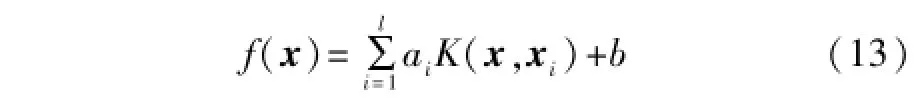
3.2 基于贝叶斯证据框架的LSSVM参数优化
LSSVM超参数的选择对模型的性能影响很大,目前常用的超参数优化估计方法有经验法、确认集、交叉验证、误差界、贝叶斯学习法等[9]。本文采用Mackay[10]提出的贝叶斯证据框架对超参数进行优化。
贝叶斯证据框架的基本思想是根据贝叶斯规则分层次地最大化参数分布的后验概率,从而得到最佳参数值或模型。
推断过程分为三个层次:①准则1推断确定模型参数;②准则2推断确定正规化参数;③准则3推断确定核参数。
①准则1推断
为了便于贝叶斯分析,将优化问题的目标函数式(10)除以c,并用λ代替1/c。假设数据空间为D、模型空间为H,准则1通过贝叶斯规则推断w的后验。
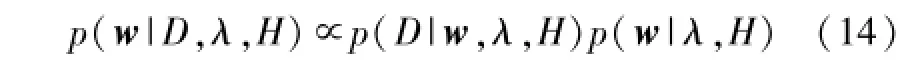
式中:p(D|w,λ,H)和p(w|λ,H)分别为模型H对于数据D的概率分布和先验参数分布。
假设模型训练样本独立同分布,p(w|λ,H)服从高斯分布,即:
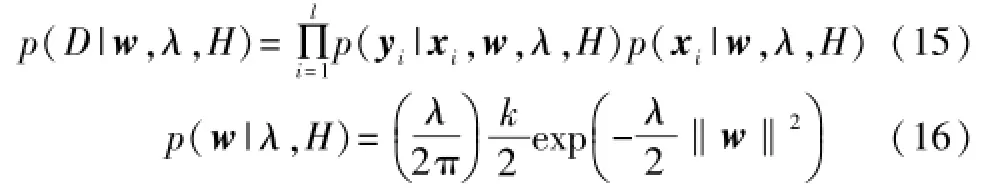
其中,p(xi|w,λ,H)可看作是常数。以L[yi,f(xi)]表示损失函数,即L[yi,f(xi)]==[yi-wTφ(xi)-b]2,则有:
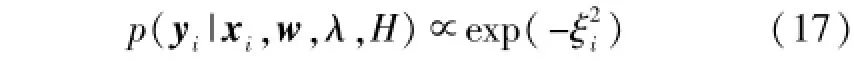
将式(15)~式(17)代入式(14),则有:
通过网络分析仪调试的结果如图8所示,其频段为4.5 GHz~10 GHz。图中通带的边频点插损值分别达到了0.76 dB和0.57 dB,比图4中协同仿真曲线上的A1、A2两点值偏大,这是由低通滤波器、测试接头及电缆线自身的损耗引起的;带外两边的抑制分别达到了74 dB和35 dB,这与图4中的协同仿真B1、B2值相比没太大变化;而全腔仿真远端(6 GHz~10 GHz)的抑制均超过了34 dB,与图4中协同仿真结果相比有极大的改善。

由式(17)可以看出,LSSVM的训练即最大化w的后验p(w|D,λ,H)分布,从而可以得到w的最优值wMP。
②准则2推断
第二层推断正规化参数c,通过最大化λ的后验概率p(λ|D,H),可得λ的最优值。令,则:
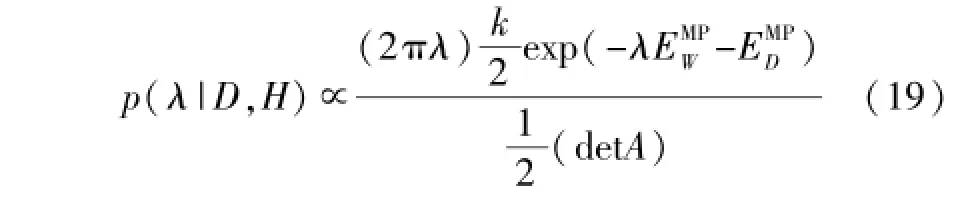
对式(19)两边取对数,可以得到:
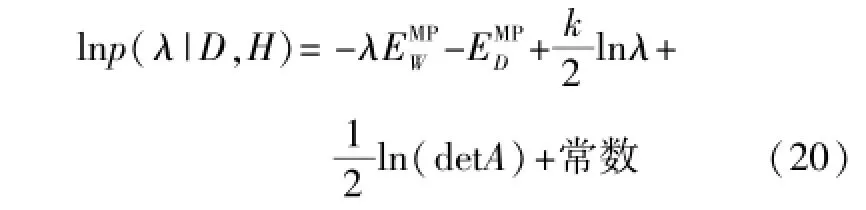
通过最大化lnp(λ|D,H)可得λMP,如式(21)所示。
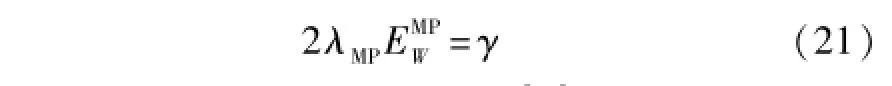
式中:γ=k-λtrA-1为参数的有效数[10]。
③准则3推断
第三层推断核参数σ。通过最大化后验概率p(H|D)∝p(D|H)p(H)得到最优核函数。
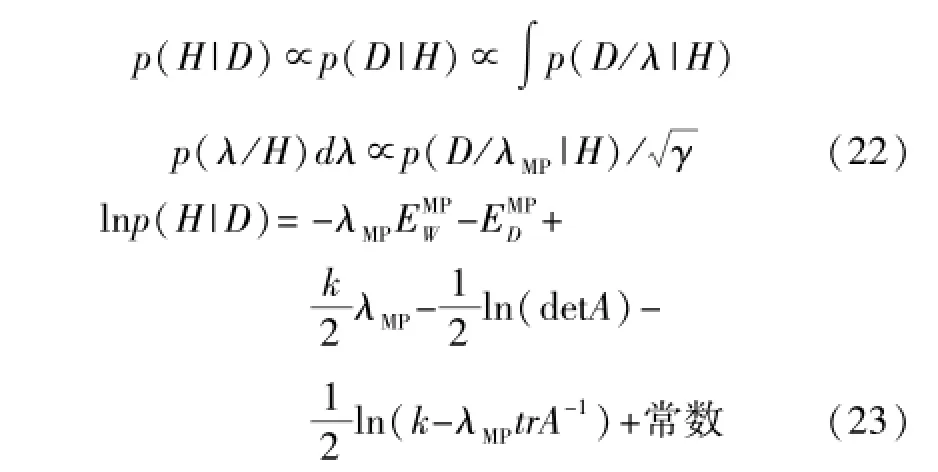
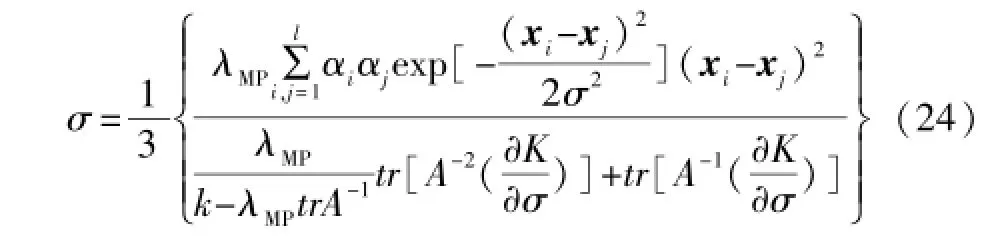
由于核宽度σ不能为负,因此对核参数取绝对值。
3.3 多模型LSSVM建模
多模型建模方法是一种解决复杂非线性系统建模问题的有效工具。多模型的建模可分为子数据集的划分、子模型的建立和多模型的输出3个步骤。本文的多模型LSSVM建模步骤可描述如下。
①对训练样本数据进行数据归一化处理,使用模糊核C均值聚类算法对训练样本数据进行聚类。
②采用LSSVM建立每个聚类的数据驱动模型,并使用贝叶斯证据框架优化LSSVM的超参数。
③对测试样本进行数据归一化处理,评价对应样本的聚类模糊隶属度。
④根据测试样本的模糊隶属度求取对应子模型的输出,并根据模糊隶属度将各个子模型的输出进行加权求和,得到系统的模型输出,即完成了多模型的建立。
4 煤调湿系统蒸汽消耗量的多模型建模
本文以某炼铁厂煤调湿装置为研究对象,采用以上所提出的多模型建模方法构建蒸汽消耗量的软测量模型。该装置利用干熄焦蒸汽发电后的低压蒸汽作为热载体,对装炉煤料进行干燥处理,煤料水分由10.2%左右降至6.5%左右。
整套装置包括热源供给系统、煤料输送系统、换热干燥系统,涉及到的流量、温度、压力等操作参数多达30多个,因此煤料水分控制系统是一个非线性、强耦合、大时滞的复杂系统。在充分了解煤调湿过程工艺机理的基础上,同时对现场采集的数据进行变量相关分析,综合考虑数据采集成本和模型精确度,最后选取了煤切出量、干燥机出口气体温度、入口煤湿度、出口煤湿度和引风机输出功率作为煤调湿过程蒸汽消耗量模型的输入,模型输出即蒸汽的实际流量。
为了使模型尽可能涵盖所有工况,采集了该厂煤调湿装置不同班次的458组生产数据。剔除显著误差并进行平滑和归一化处理,最后共得到432组样本数据,其中的324组用于模型训练,剩余108组作为测试数据,以检验模型的泛化能力。
本文所有仿真与试验均在Matlab R2012b环境下完成,LSSVM模型训练与贝叶斯证据框架推断均采用了LS-SVM lab工具箱。聚类最大迭代次数为tmax= 500,允许误差ξ=10-3,加权参数m=2,密度常数Minpts=4。自适应模糊核C均值聚类算法求得最佳聚类个数为5,使用基于贝叶斯证据框架的LSSVM建立了对应的5个子模型。最终的多模型训练效果和检验效果分别如图2和图3所示。
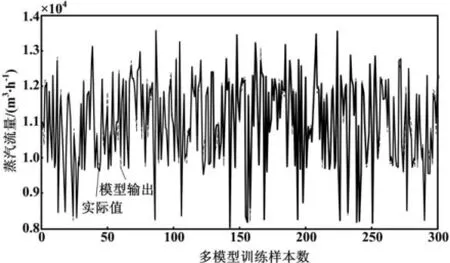
图2 煤调湿蒸汽流量多模型训练结果Fig.2 Training results of the steam flow multi-model for coal moisture control
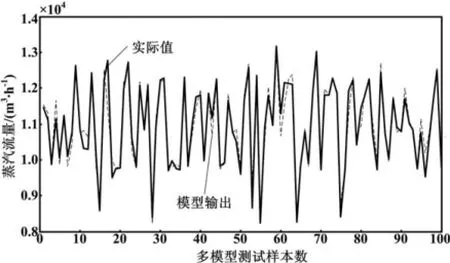
图3 煤调湿蒸汽流量多模型测试结果Fig.3 Test results of steam flow multi-model for coal moisture control
从图3可以看出,采用本文所提出的基于模糊核C均值聚类和LSSVM的多模型建模方法,能够较好地估算出煤调湿系统中蒸汽的消耗量,具有较高的预测精度与泛化能力。
为了进一步验证所提出的多模型建模方法的有效性,在同样的训练数据与测试数据下,分别采用LSSVM和核偏最小二乘(kernel partial least squares, KPLS)进行单模型建模。采用平均绝对误差(mean absolute deviation,MAD)、平均绝对百分比误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)等3项指标进行模型效果对比,如式(25)~式(27)所示。
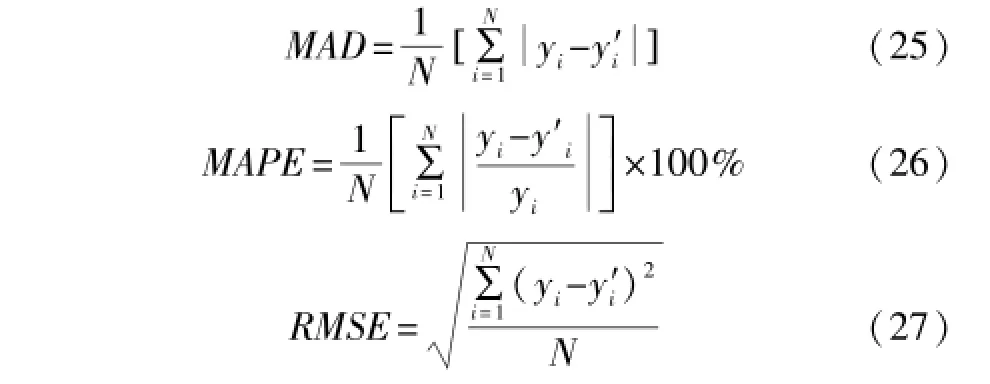
式中:yi为实际蒸汽流量;为模型输出值;N为样本数量。
模型对比结果如表1所示。

表1 煤调湿蒸汽流量多模型与单模型误差比较Tab.1 Comparison of the errors of multi-model and single model of steam flow for coal moisture control
从表1可以看出,基于模糊核C均值聚类和LSSVM的多模型建模方法在各项评价指标上均明显优于传统的LSSVM和KPLS单模型建模方法,从而为煤调湿过程的蒸汽流量预测提供了一种切实可行的建模方法。
5 结束语
本文以某炼铁厂的煤调湿装置为研究背景,提出了一种基于模糊核C均值聚类和最小二乘支持向量机的多模型建模方法。采用模糊核C均值聚类将生产工况划分为不同的子区间,融合基于密度的聚类中心初始化方法和聚类数目自适应策略,在提高聚类收敛速度的同时保证了聚类的准确性。对于不通过的聚类建立了与其对应的子模型,并使用贝叶斯证据框架优化LSSVM的超参数。最后利用模糊隶属度的加权策略输出新样本的多模型预测值。现场数据的测试结果表明,所提出的多模型建模方法优于传统的单模型建模方法,能够在较高的精度内预测煤调湿蒸汽流量值,为煤调湿过程蒸汽流量的实时控制提供了一种有效的手段。
[1] Kadlec P,Gabrys B,Strandt S.Data-driven soft sensors in the process industry[J].Computers&Chemical Engineering,2009,33(4): 795-814.
[2] Li Y,Su H,Chu J.Overview on subspace model identification methods[J].Journal of Chemical Industry and Engineering China, 2006,57(3):473.
[3] 孙建平,苑一方.复杂过程的多模型建模方法研究[J].仪器仪表学报,2011,32(1):132-137.
[4] Yu J,Chen K,Rashid M M.A Bayesian model averaging based multi-kernel Gaussian process regression framework for nonlinear state estimationandqualitypredictionofmultiphasebatch processes with transient dynamics and uncertainty[J].Chemical Engineering Science,2013,93(10):96-109.
[5] 陈贵华,王昕,王振雷,等.基于模糊核聚类的乙烯裂解深度DELSSVM多模型建模[J].化工学报,2012,63(6):1790-1796.
[6] 李侃,刘玉树.模糊核聚类的自适应算法[J].控制与决策, 2004,19(5):595-597.
[7] 赖玉霞,刘建平.K-means算法的初始聚类中心的优化[J].计算机工程与应用,2008,44(10):147-149.
[8] Xie X L,Beni G.A validity measure for fuzzy clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1991, 13(8):841-847.
[9] Yan W,Shao H,Wang X.Soft sensing modeling based on support vector machine and Bayesian model selection[J].Computers& Chemical Engineering,2004,28(8):1489-1498.
[10] Mackay D J.Probable networks and plausible predictions-a review of practical Bayesian methods for supervised neural networks[J]. Network:Computation in Neural Systems,1995,6(3):469-505.
Research on the Multi-model Modeling for Vapor Consumption of Coal Moisture Control System
Coal moisture control technology is the key technique of the coking process.Establishing the soft sensing model for vapor consumption in coal moisture control system may save production costs,reduce environmental pollution and improve the quality of coke.In accordance with the features of the coal moisture control equipment in certain ironworks,e.g.,nonlinearity,strong coupling and large fluctuations of working condition,the multi-model modeling method is proposed.The density-based clustering center initialization method and number of clusters adaptive strategy are integrated into the fuzzy C-means clustering to get optimal division of the production working conditions. The least squares support vector machines(LSSVM)is applied to conduct data-driven modeling for each sub-working conditions,and the parameters of the LSSVM is optimized by adopting Bayesian evidence framework.The checked results indicate that the proposed multi-model possesses good tracking performance and higher prediction accuracy.
Coal moisture control Fuzzy kernel C-means clustering Least squares support vector machines(LSSVM) Bayesian evidence framework Multi-model
TP391+.9
A
修改稿收到日期:2014-11-25。
王建华(1955-),男,1988年毕业于华东化工学院工业自动化专业,获硕士学位,副教授;主要从事工业过程建模、控制与优化。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28 07:34:58
电子测试(2017年15期)2017-12-18 07:19:27
中国核电(2017年1期)2017-05-17 06:10:04
小猕猴智力画刊(2017年4期)2017-05-04 04:12:36
数理化解题研究(2017年4期)2017-05-04 04:07:54
军事文摘·科学少年(2017年1期)2017-04-26 21:33:18
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
