
基于Copula连接函数的数据挖掘关联算法的设计
2014-05-12 10:22张维群
统计与信息论坛 2014年4期
张维群,岳 雪
(1.西安交通大学 经济与金融学院,陕西 西安 710049;2.西安财经学院 统计学院,陕西 西安 710100)
基于Copula连接函数的数据挖掘关联算法的设计
张维群1,2,岳 雪2
(1.西安交通大学 经济与金融学院,陕西 西安 710049;2.西安财经学院 统计学院,陕西 西安 710100)
现实中海量数据往往持续地产生,如何实现信息和知识的动态挖掘已成为人们关注的理论问题。根据数据集分批分步输入处理的思想,以Copula连接函数为理论基础,给出一种有效海量数据的关联分步测度算法,通过模拟实验验证了该算法的可行性,结果显示所设计的关联算法能显著提高关联效应测量的效率,并能有效地解决超海量数据关联效应的测度问题。
关联效应;连接函数;挖掘算法
一、引 论
随着信息技术的进步,人们能以更快速、更简单、更方便的方式获取和存储数据,必然使数据信息量以指数方式增长,海量数据本身并不能直接地体现其价值,有价值的是从中抽取到有用的知识和信息,因此数据挖掘越来越受到重视。数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中有用的信息。现实中存在着海量数据集,但因相对应有限的存储空间及有限生命体时间限制的问题,设计出了高效数据挖掘算法,此算法能够快速挖掘出海量数据的知识和信息,并提供即时决策,已成为当前理论研究的热点问题。
对于数据关联性测度算法的研究较多,不同文献根据问题的特殊性设计了相应的算法。Roecker J A.为解决在多目标数据关联中存在的噪声问题,提出了一种多重扫描联合概率数据关联(JPDA)算法,该算法先利用标准单向扫描JPDA算法对目标进行追踪更新,然后进行后向扫描,并将随着后向扫描目标信息所产生的更好加权数据关联反馈给服务器,从而解决同时在多目标和噪声的环境下测量跟踪数据关联的问题[1];陈玉坤等人运用现代数学中的综合分析法得出模糊相似性测度数据关联算法,其处理速度较快,存储和通信量要求较低,且具有良好的关联效果[2];Wang Hansheng提出了迭代边缘优化拟合算法(IMO),旨在保证MRC目标函数的单调递增,该算法不仅有效稳定,且计算速度也非常令人满意[3];Michael Kaess等人针对边际协方差阵估计数据关联问题很难得到计算完整的密集协方差矩阵,提出使用一个平方根信息矩阵作为维护增量平滑和映射(iSAM)算法,并允许删除不提供信息的测量降低估计的复杂性,该算法用真实数据模拟实验结果较好[4];唐冬丽等人针对联合概率数据关联算法需要知道目标总数并对矩阵差分计算量呈指数增长的问题,提出了一种模糊多门限概率关联算法,该算法利用计算测量与目标的关联概率来替代概率数据关联算法中可行联合事件概率,在改善性能的同时又减少了计算量[5];安振等人认为数据关联算法的研究是多目标跟踪中的核心问题,多目标跟踪的精度和计算过程的复杂度均取决于所采取的数据关联算法的优劣,继而提出了一种改进的次优联合概率数据关联算法[6];Aziz Ashraf M.为了在很大程度上降低联合概率数据关联方法和传统模糊逻辑数据关联方法的计算复杂度,提出加权模糊关联方法解决在嘈杂环境中多目标的跟踪问题,利用模糊聚类来生成一个似然测度代替传统的马哈拉诺比斯距离,实验结果表明该算法具有比最近邻马哈拉诺比斯距离、联合数据关联算法和传统模糊逻辑数据关联方法更好的性能[7]。
综合文献研究可以看出,虽然以往的算法对于变量的关联测度算法有很大的提高,但都是针对有限数据集进行研究,在超大数据集和连续数据流的情况下,算法复杂度太高且运算量较大,算法的效率改进有限。张维群利用迭代思想提出了分步测量关联性的算法[8],但是该算法需要系统存储上步计算的诸多参数,使算法的适用性受到限制。笔者在此基础上,利用云计算思想,将数据分步分批进行处理,利用连接函数的概念,对分批样本的估算结果进行连接,依据收敛后的结论快速地得出关联测度结果。
二、算法设计的理论
(一)算法设计的思想
对于现实中连续生成的海量数据而言,传统的关联测度算法已经不能保证结果的准确性和有效性,这是因为海量数据或无限数据交由一个处理器处理,难免会降低处理效率,也不可能一次性进行即时处理。因此,利用云计算的资源交互概念,对传统海量数据关联挖掘算法进行改进,提出将分“块”数据分步关联性测度计算结果通过连接函数进行连接,依据结果收敛的性质提出了一种快速有效的关联测度算法。在利用海量数据的有限样本情况下,给出了海量数据目标变量间关联性测度结果,使海量数据的关联算法更有效率。
(二)连接函数的构造与性质
1.连接函数的构造
张尧庭最先将Copula函数应用到相关分析中,在Copula连接函数原型的基础上构造连接函数。常用Copula连接函数分为两大类:椭圆Copula函数族和阿基米德Copula函数族。在此,以阿基米德Copula函数为原型,形式如下:
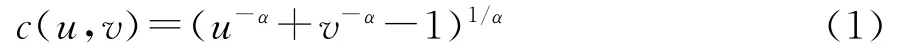
关于“连接函数”,即将边缘分布通过连接函数与联合分布函数形成等式关系这一概念,由于该函数具有形式简单、对称性和可结合性等优良性质,基于样本量与综合信息量相关的客观事实,将权重这一信息加入式(1),再综合考虑相关系数的取值范围,对连接函数设计为:
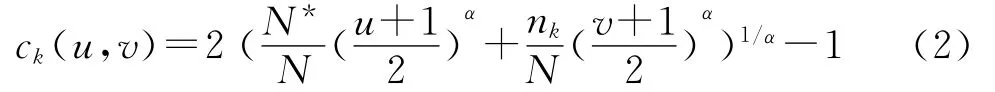


(三)关联算法的构造
根据数据分“块”的思想,将海量数据中的一个小样本集si交由终端处理,以较为常用的皮尔逊相关系数为例,在已知实际的数据分布关联测度分析中,可根据数据的具体特征来选择具体的相关系数计算方法,估计出样本集si中变量x对y的关联效应水平:


三、算法的模拟实验
(一)算法实现流程

(二)实验结果分析
为了验证设计算法的有效性,用Matlab软件处理来自移动通信行业的26 300组数据,从而计算通话时长与话费开销的关联测度。随机进行分组,可将各组数据分步交由处理器进行处理。为了剔除参数α取值的影响,实验中均令α的取值从0.1取到0.9,输出每次的结果,然后再选取最优结果。实验分别进行了12次,输出结果见表1。
如果利用全部26 300组样本得到计算通话时长与话费开销的关联测度为0.745 9,根据本文算法的实验结果显示,上述数据在实验中最多用了159组数据,样本利用率为60.45%,最少的实验仅通过2组数据就得到了收敛结果,样本利用率只有0.76%。综合实验结果,本文设计的关联算法样本利用率均没有超过61%,最差精度为0.71%,结果说明所设计的关联算法具有明显的优势,大大地降低了处理器运算量,从而节约了处理时间,提高了处理效率,也降低了处理过程对于计算机硬件的要求。
四、结 论
现实中数据平台可能会不断地生成新的数据,传统算法需要将所有数据重新计算。本文设计的算法只需要对新生成数据进行关联性测量,并运用连接函数生成新的测量结果,如果新的测量结果收敛,则可以在一段时期内不用对海量数据进行再挖掘,其关联性测度水平只要通过云平台提供给用户就可以。
本文以数据集分“块”和连接函数为基础,讨论海量数据关联测度算法的设计,并设计了一种有效准确的关联测度算法,验证了该算法具有显著的处理效率和应用的可行性。同样,设计的算法对于测量超海量数据集的关联性水平仍然有效,也为海量数据挖掘的云服务提供了可能。
[1] Roecker J A.Multiple Scan Joint Probabilistic Data Association[J].IEEE Transactions on Aerospace and Electronic Systems,1995,31(3).
[2] 陈玉坤,司锡才,李伟彤.基于模糊相似性测度的数据关联算法研究[J].弹箭与制导学报,2007(2).
[3] Wang H.A Note on Iterative Marginal Optimization:A Simple Algorithm for Maximum Rank Correlation Estimation[J].Computational Statistics & Data Analysis,2007(6).
[4] Kaess M,Dellaert F.Covariance Recovery from a Square Root Information Matrix for Data Association[J].Robotics and Autonomous Systems,2009(12).
[5] 唐冬丽,李小兵,王志清.一种改进的联合概率数据关联算法的研究[J].弹箭与制导学报,2010(6).
[6] 安振,姜秋喜,李业春.次优联合概率数据关联算法的研究[J].现代雷达,2011(4).
[7] Aziz Ashraf M.A New Nearest-Neighbor Association Approach Based on Fuzzy Clustering[J].Aerospace Science and Technology,2013(1).
[8] 张维群.基于海量数据关联效应测度算法的设计[J].统计与信息论坛,2012(7).
A Design of Correlation Algorithm of Data Mining Based on the Copula Function
ZHANG Wei-qun1,2,YUE Xue2
(1.School of Economics and Finance,Xi'an Jiaotong University,Xi'an 710049,China;2.School of Statistics,Xi'an University of Finance and Economics,Xi'an 710100,China)
In reality,the massive data are generated continuously,how to realize the dynamic mining of information and knowledge is a theoretical problem which people concerned.According to the idea of batch wise and stepwise input data processing,an effective stepwise algorithm on mass data correlation is introduced which is based on the theory of copula function.Further,the feasibility of the algorithm is verified by simulation experiments.The results show that the efficiency of measurement on the data association effect can be highly improved through the algorithm referred in this paper,and the measurement of super mass data or even infinite data will be solved effectively.
correlation effect;Copula function;mining algorithm
F224.0∶O213.9
A
1007-3116(2014)04-0010-04
2013-11-18;修复日期:2014-01-12
国家社会科学基金项目《基于多因素的空间抽样调查理论与应用研究》(13BTJ006)
张维群,男,陕西旬邑人,博士生,副教授,研究方向:电子商务数据挖掘,统计测度理论;
岳 雪,女,贵州遵义人,硕士生,研究方向:统计理论,数据挖掘算法。
(责任编辑:郭诗梦)
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
数学物理学报(2022年3期)2022-05-25
数学物理学报(2022年2期)2022-04-26
华中师范大学学报(自然科学版)(2021年2期)2021-04-10
经济与管理(2020年4期)2020-12-28
当代陕西(2019年14期)2019-08-26
中成药(2017年3期)2017-05-17
中学数学杂志(初中版)(2016年5期)2016-11-01
中国环境监察(2016年12期)2016-10-24
中国卫生标准管理(2015年6期)2016-01-14
