
OMAPL138的双核通信设计
2014-05-10 07:52:24林淦刘建群许东伟李嘉健
机床与液压 2014年22期
林淦,刘建群,许东伟,李嘉健
(广东工业大学机电工程学院,广东广州510006)
TI 公司于2009年推出了一款高性能、低功耗的浮点、定点能力兼备的全新双核处理器——OMAPL138。OMAPL138 是基于DSP 的SoC,采用C6748 DSP 内核+ARM9 内核的双核结构,可实现高达375/456MHz 的内核频率。利用片上嵌入式微处理器内核ARM9,开发人员可以在操作系统平台上充分利用浮定点兼容C6748 DSP 来支持高强度的数据实时处理计算,同时将非实时性任务交给ARM9 内核负责,这种优异的架构能帮助设计者开发出更为出色的产品[1]。
文中主要介绍一种基于OMAPL138 双核握手通信的机制。在ARM 端运行LINUX 系统,主要处理人机交互、向DSP 发送数据等任务;而在DSP 端运行DSPBIOS,循环地接收从ARM 传来数据,进行运算处理。该设计充分地利用ARM 和DSP 自身的强大优势,为工业控制上需要高强度运算的实时控制系统设计提供了一定的借鉴和参考。
1 OMAPL138 整体架构
OMAPL138 是一款集成了ARM926EJ-S 和C6748 DSP 的双核处理器。对比DSP C6000 系列,OMAPL系列更具有低功耗、高处理能力等优势。其内部集成了EDMA3、EMIFA、EMAC、SPI 等丰富的外设接口,ARM 和DSP 都可以独自操作这些外设。由于具有高运算处理能力和先进的电源管理,使得OMAPL 系列非常适合智能和工业行业的应用[2]。OMAPL138 嵌入式双核处理器的内部系统框图如图1所示。
该设计以OMAPL138 为硬件平台,实现双核快速、准确地通信。该设计具有以下几个优势:
(1)OMAPL138 双核之间大数据量通信的一般方式是采用发送方先往共享内存(也就是在图1 外设系统中128 kB RAM)写数据,然后直接给接收方一个中断,接收方在响应中断后再进行读写数据。而该设计对于大数据量的传输是采用ARM 直接对DSP RAM 进行读写操作,大大提高了两核之间的通信速度。
(2)系统启动后,两核单独运行,这样就存在双核运行速度不协调的问题。设计中,通过利用DSPLINK 中的MSG 模块,协调两核之间的运行速度,解决了双核运行速度不协调的问题。
(3)在DSP 端采用两级循环缓存区,避免了DSP 在进行高速实时运算时,双核之间的数据读写冲突,并减少了DSP 读取数据的时间,提高了系统的强实时性。
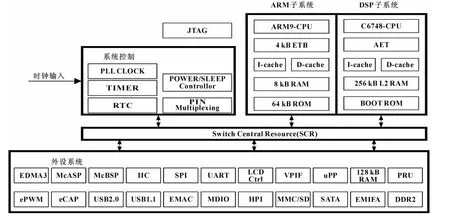
图1 OMAPL138 嵌入式双核处理器的内部系统框图
2 通信机制的整体设计框架
OMAPL138 拥有总共4 GB 的存储器地址空间,地址范围为0x00000000-0xFFFFFFFF。OMAPL138 所有外设资源,包括片内存储器、片外存储器和各个控制寄存器等共同分享了这4 GB 地址空间。其中,共享内存的地址范围为0x80000000-0x8001FFFF,占了128 kB[3-4]。DSPLINK 是TI 提供的通用双核通信的API 函数,它包含了PROC、MSG、CHNL、POOL 等组件。DSPLINK 大部分通信原理都是发送方(ARM或DSP)将数据放在128 kB 的共享内存中,然后给接收方一个中断,告知接收方可接收数据[5]。而这其中的实现过程都是由DSPLINK 封装好的。
该设计在ARM 端运行LINUX 操作系统,加载dsplink.ko 驱动,在ARM 应用程序中调用DSPLINK的函数库。同时在DSP 端运行DSPBIOS 实现与ARM的握手通信,通信机制的整体设计框架如图2所示[6-8]。
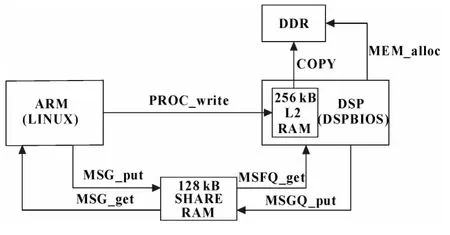
图2 通信机制的整体设计框架
该设计使用了 PROC、MSG、POOL 这3 个DSPLINK 组件。其中:
(1)PROC 组件。PROC_write 可对DSP 内部的L2 RAM 直接进行写操作,可以传输大容量数据,无需通过共享内存。
(2)MSG 组件。MSG_put 和MSG_get 可进行信息发送和接收,所有信息内容都被包含在SampleMessage 结构体中。MSG 传输的字节大小就是sizeof(SampleMessage),它必须与128 字节对齐。而SampleMessage 结构体的成员可自行定义,例如该设计就把PROC_write 在DSP RAM 写的首地址和写的长度封装在结构体中。
#define DSPLINK_BUF_ALIGN 128
DSPLINK _ ALIGN(sizeof(SampleMessage),DSPLINK_BUF_ALIGN)
(3)POOL 组件。为MSG 组件在外设DDR 中分配内存区,其分配大小就是sizeof(SampleMessage)的大小。
3 双核的握手机制
由于ARM 启动后就会唤醒DSP,之后它们之间就各自运行自己的程序。为了解决两核之间的协调问题,该设计利用了DSPLINK 中的MSG 组件。一方面,MSG 为两核之间传递一些状态变量,使它们可以获取对方执行的情况;另一方面,接收方接收消息是采用无限等待模式,这就解决了两核之间执行速度快慢不协调的问题。双核的握手机制示意图如图3所示。

图3 双核的握手机制示意图
4 两级循环缓存区设计
在工业控制应用中,对于外接设备的控制,如伺服电机的控制等,都必须要求是实时的。这就要求DSP 必须不间断地实时地在内存中读取数据,运算后输出控制命令。若采用DSP 处理完ARM 传来的一帧数据后,再请求ARM 发另一帧数据来进行运算处理的方案,不能满足强实时性的要求。因此,该设计建立了两级循环缓存区,以确保缓存区中总有数据供DSP 进行实时运算。
DSP 端建立的两级循环缓存区如图4所示。DSP L2 RAM 为一级缓存区,循环存储从ARM 发过来的数据,而在外设DDR 中开辟第二级缓存区。DSP 在第二级缓存区DDR 中读取数据,进行实时运算处理。建立两级循环缓存区作用在于:(1)避免了DSP 进行实时运算时读取数据与ARM 往DSP L2 RAM 写数据的冲突;(2)减少了DSP 进行实时计算时的读取数据的时间,提高了系统的强实时性。
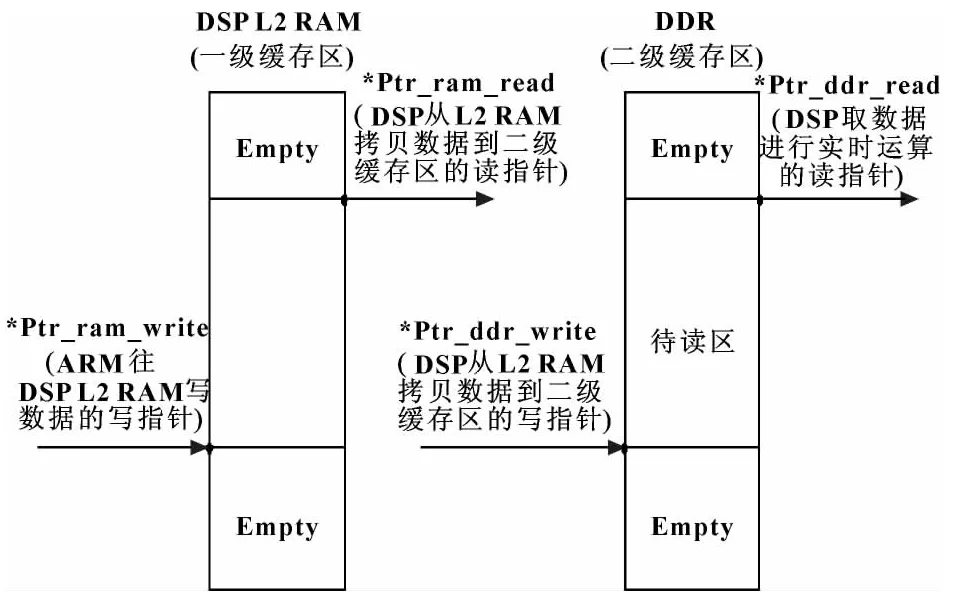
图4 DSP 端建立的两级循环缓存区
首先,在ARM 端定义Message 结构体,其状态变量如下:

Message 就是上面提到MSG 传递的结构体。发送方通过修改该结构体的成员变量,从而告知对方当前的运行情况。
其次,ARM 随时用MSG_get 获取Message 结构体,查询一级缓存区(DSP L2 RAM)的Empty 区的数据大小是否已经大于one_rw_size,如果是就往一级缓存区写one_rw_size 个数据。
最后,当ARM 需要往一级缓存区(DSP L2 RAM)的Empty 区写数据且剩下的数据大小已经小于或等于one_rw_size 的时候,ARM 置位gppwriteover,并将剩下的数据写到一级缓存区(DSP L2 RAM)的Empty 区中。
而在DSP 端,每次查询二级缓存区(DDR)的Empty 区大小是否大于one_rw_size 并且dspreadover未置位,那么就从Ptr_ram_read 开始地址往下读one_rw_size 个字节写到二级缓存区(DDR)中。
当ARM 已经置位gppwriteover 且二级缓存区(DDR)需要从一级缓存区(DSP L2 RAM)读的数据大小已经小于one_rw_size 的时候,DSP 将一级缓存区剩下的数据全部读到二级缓存区,并置位dspreadover。而当DSP 在二级缓存区中读取数据去进行运算的大小等于file_transfer_size 时,表示数据已经执行完,DSP 置位Processover,并通知ARM 程序执行完毕。
ARM 工作流程图如图5所示,DSP 工作流程图如图6所示。

图5 ARM 工作流程图
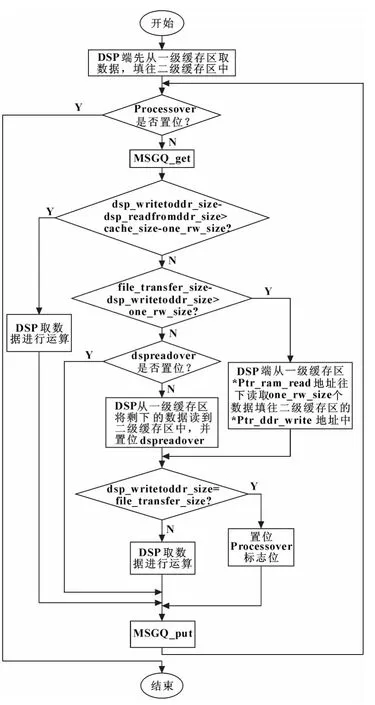
图6 DSP 工作流程图
5 结束语
设计了一种基于OMAPL138 的双核通信机制:一方面,对于小数据量的消息传输,通过共享内存进行交互通信;另一方面,对于大数据量的通信,直接采用ARM 往DSP RAM 里面进行读写,提高了通信速度。并且,在DSP 端建立了两级循环缓冲区,而ARM 端监视缓冲区,一旦缓冲区有空闲区域就往里面写数据,确保了缓冲区一直有数据供DSP 读取进行运算。经测试,该机制运行稳定、快速,ARM 和DSP 都可以准确地进行通信。
[1]彭启琮,杨錬,潘晔.开放式多媒体应用平台——OMAP处理器的原理及应用[M].北京:电子工业出版社,2005.
[2]TEXAS INSTRUMENTS.OMAP-L138 Applications Processor System Reference Guide[M],2010.
[3]付浩,刘建群.基于OMAP-L138 的嵌入式运动控制器的设计与研究[J].科学技术与工程,2013,13(1):196-200.
[4]TEXAS INSTRUMENTS.OMAP-L138 Applications Processor System Reference Guide[M],2010.
[5]TEXAS INSTRUMENTS.Building DSPLink Applications version 1.65.00.02[M],2010.
[6]赵加祥.DSP 系统设计和BIOS 编程及应用实例[M].北京:机械工业出版社,2008.
[7]CorbetRubini,Kroah Hartman.Linux 设备驱动程序[M].3 版.北京:中国电力出版社,2010:21-44.
[8]宋宝华.设备驱动开发详解[M].2 版.北京:人民邮电出版社,2010.
猜你喜欢
房地产导刊(2022年1期)2022-02-28 08:09:16
山西电子技术(2019年4期)2019-09-07 08:00:34
科技风(2017年20期)2017-07-10 18:56:06
合成化学(2015年2期)2016-01-17 09:03:58
电子世界(2014年21期)2014-04-29 06:41:36
无机化学学报(2014年1期)2014-02-28 17:30:13
无机化学学报(2014年1期)2014-02-28 17:30:07
电子设计工程(2014年18期)2014-02-27 12:00:34
组合机床与自动化加工技术(2013年1期)2013-12-23 04:47:02
计算机应用文摘(2010年25期)2010-04-29 00:44:03
