
气象数据的“大数据应用”浅析
2014-04-29 00:44:03沈文海
中国信息化 2014年11期
沈文海


1. 引言
据统计,2011年全球的数据规模为1.8ZB,这些信息将填满575亿个32GB的ipad,倘以这些ipad做砖石,足可以垒建起两座中国的万里长城。2013 年仅中国当年产生的数据总量就已超过0.8ZB,2倍于2012年,相当于2009年全球的数据总量。预计到2020年,中国产生的数据总量将是2013年的10倍,超过8.5ZB。而届时全球的数据总量预计将达到40ZB,如果将这些数据全部刻录成蓝光光盘,则这些光盘的总重量相当于424艘满载荷的尼米兹级航空母舰。
数据量暴增的速度令人瞠目结舌,我们的确已进入“大数据时代”。
很快地,“地理大数据”、“水利大数据”、“环境大数据”、“金融大数据”、“互联网大数据”乃至“气象大数据”等名词陆续出现在有关媒体上。“大数据”逐渐成为近来人们谈论最多、思考最多的技术话题之一。一些人憧憬于“大数据”可能带来的十分珍稀的高价值信息和珍贵商机,也有许多人困惑于目前所知“大数据”的应用范式,以此研判着可能给本行业带来的变化和新的业务契机——气象部门也是如此。
做为抛砖引玉,笔者拟就如下问题提出自己的看法:
(1)气象数据是否具备“大数据”的核心特征?
(2)所宣称的由大数据引发的思维变革,即:不需要专业知识背景而仅通过单纯的数据分析便可获得新的“知识”,在气象部门核心业务领域(天气预报和气候预测等)中是否适用以及为什么;它与“数据密集型科学发现”之间存在哪些差异。
(3)在大数据背景下,海量气象观探测数据的应用价值范围以及目前价值发挥的可能性。
2. 大数据的现实以及气象数据的特征分析
2.1 大数据的特征和在我国的行业分布
早在2012年前后,业界便已就大数据在体积、类型、速度和价值这四个方面的特征达成了共识,即所谓大数据的4V特征。限于篇幅,不再复述。
一般而言,大数据的起始计量单位至少是PB、EB或ZB级别。
据统计,就数据量而言,中国的大数据近期具有如下行业分布特征:
(1)互联网公司
目前国内互联网公司拥有总计约2EB的数据,其中互联网三巨头BAT(百度、阿里巴巴、腾讯)占有其中的3/4(约1.5EB)。
(2)电信、金融、保险、电力、石化系统
这些行业及企业数据量分布较为平均,就每个单位而言,大致都拥有10PB以上的数据,且年增量都在PB级以上。总和则有数百个EB的存储数据和数十EB的年增量。
(3)公共安全、医疗、交通、电子政务领域
城市:平安城市、智慧城市等工程的建设,监控摄像头遍布大街小巷。一个中等规模城市每年视频监控产生的数据约300PB。最保守估计(含定期循环清除),全国每年保存下来的数据在数百PB以上。
交通:飞机航班往返一次产生的数据达TB级。列车、水陆路运输每年产生并保存下来的各种视频、文本类数据约达数十PB。
卫生:整个医疗卫生行业,一年保存下来的数据可达到数百PB。
电子政务:一个智慧城市的电子政务所产生的数据每季度约达200PB。而调查显示,未来1~2年中国政府部门的数据规模超过100TB的将达到53.3%,有将近三成(33.3%)的用户数据规模是10~50TB。
(4) 其他,商业销售、制造业、农业、物流和流通等领域
随着产业互联网的普及,(线下)商业销售、制造业、农林牧渔业、(线下)餐饮、食品、科研、物流运输等这些传统行业的数据量将呈现迅速增长态势,但目前这些行业数据量尚处于积累期,体量不大,多的达到PB级别,基本约近百TB甚至数十TB级别。
(5)气象数据
气象部门需要永久保存的数据目前约4~5PB,年增量约1PB。
由此可见,以数据量而言,在整个大数据市场中,新兴的互联网行业巨头BAT,以及电信、金融、保险等行业占据比重较大。相对而言,气象数据无论总量还是增量,较这些数据大户至少低3个数量级。
需要注意的是,在大数据的“4V”特征中,“Volume”(体量巨大)仅为必要条件,而非充分条件,如同 30mm的日降水,在我国东南沿海地区十分平常,但在西北地区却是极可能成灾的罕见大雨,所以体量大小是相对的。事实上,大数据概念的提出绝非仅因为数据量的暴增,而且是因为数据已多到用传统方法无法处理,导致人们必须采用新方法、新思路乃至新理念予以应对。如果数据量虽大,但却能够处理和掌控,便不能称其为“大数据”。因此,“4V”对于大数据而言,既是特征,也是考量的四个维度。
2.2 气象数据的体量种类分布
气象资料种类繁多,仅气候专用资料,包括冰芯、花粉、树木年轮、历史文献、冰盖、海平面温度、洋流盐度、地表植被等在内的涵盖五大圈层的各种自然界及人类活动的观测资料,已达数十种。而应用于诸如天气、农业气象、人工影响天气、雷电防护、公共气象服务等业务领域的资料,种类亦十分可观(限于篇幅,不予展开讨论)。目前就体积而言,在所有气象资料中,地面观测、气象卫星遥感、天气雷达和数值预报产品四类数据占据总量的90%以上;其中:
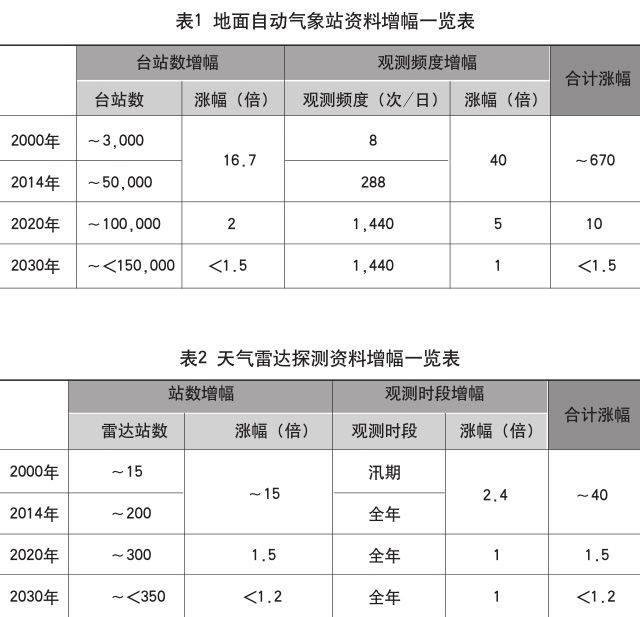
地面观测资料:进入本世纪以来,地面观测方法从人工观测改进为自动观测,摆脱了人类居住条件限制的制约,地面气象观测台站数由本世纪初的不到3,000个,迅速扩展到目前的50,000余个,观测频度由最初的3小时/次调整到目前的5分钟/次,因而导致资料量呈几何倍数增涨,月增量由最初的约240MB猛增到现在的约2.4TB(在库容量),增幅约670倍。根据防、减灾以及气象服务的需要,未来扩建计划有可能将台站数继续扩增至70,000到100,000个,观测频度有可能继续加密到1分钟/次;因此未来六年内该类资料总量有可能在现有基础上再行扩增12.5倍,由现在的每天数百万条记录增至超过一亿条记录/天。而此后,由于观测资料的空间分辨率的提升未来主要依靠遥感手段解决,因此台站密度不会进一步大规模增加。具体数据见表1。
天气雷达资料:按照《天气雷达近期发展规划(2005—2010)》以及《气象发展规划(2011—2015)》中“新一代天气雷达建设增补站点布局方案”,目前在全国已布设约200部不同波长的多普勒天气雷达,并为达到雷达资料全社会共享的目的,已基本实现7×24小时全天候不间断观测;日增总量约300GB。近十五年的增幅约40倍。详见表2。
气象卫星资料:根据《我国气象卫星及其应用发展规划(2011~2020年)》,至2020年,我国计划发射11颗气象业务卫星,包括3颗风云二号03批卫星,3颗风云三号上午星、2颗风云三号下午星、1颗降水测量雷达星以及2颗风云四号光学星。此外还将在2020年前发射2颗气象试验卫星。目前的日增总量约2TB,近十五年的增速约40倍。未来(至2020年)由于风云三号D星和风云四号系列静止卫星的陆续发射,气象卫星资料量有可能增加到约30TB/日,即:未来六年内卫星资料的增速约15倍。随着卫星仪器、通道和分辨率的增加,数据量的增幅可能会更大。
数值预报产品:与地面观测、气象卫星和天气雷达等气象观探测资料不同,气象数值预报模式资料属于气象观探测资料的加工产品。以GRAPS、T639为代表的天气预报模式,以及以BCC_CSM2、DERF2.0为代表的气候预测模式,每天都在实时运行,不断产生着数以万计的各类要素场,以供国家级、省级乃至区域级预报员参考使用,日增量接近TB级。近十五年数值预报模式数据量的增速约20倍,未来六年的增速约小于10倍。限于篇幅,气象卫星和数值预报数据涨幅不再列表。
在上述四类数据之外,气象资料中的其它种类如:气候专用、高空探测、地面农气观测、沙尘暴观测、闪电定位观测、风廓线雷达探测等等资料,种类虽多,但就体积而言,较上述四类资料至少低一个数量级,故难以将其称之为“大数据”;在以下不予专门讨论。
因此,如果就体积而言,气象资料可勉强算得上“大数据”,也是因为地面观测、气象卫星、天气雷达和数值模式这四大金刚将气象资料的体积撑大而成的。
2.3 海量气象数据的特征分析
气象数据的体积虽大,却有其独特的特征:
(1)体积虽大但总量可控
地面观测资料数据量剧增的原因,是站点数的增加和观测频度的大幅加密。由于观测资料的空间分辨率的提升未来主要依靠遥感手段解决,因此在地面观测台站达到一定密度,观测频度达到一定程度后,台站数不会无限制持续增加,观测频度也不会无节制地永远加密下去,因此总量既是可预测的,更是可控的。
天气雷达的全国布网工作已基本完成,雷达总量不会再有成倍数的增加。且目前的天气雷达已基本实现7×24小时全天候不间断观测。因此天气雷达的资料量(年增量),将稳定相当长一段时间,不会出现成倍数的增量变化。
未来数年内,我国还将发射数颗气象卫星,每颗卫星都会产生数百TB级的数据年增量。为满足气象卫星资料的应用时效,国家卫星气象中心针对每一颗气象卫星,都建有相应专属的地面接收处理系统,已完全实现所有气象卫星遥测遥感资料的实时接收处理。此外,旧星的退役也会导致部分数据来源的关闭。因此气象卫星数据目前虽以每年数百TB的量级增长,且规模有可能继续扩大,但却始终处于可控可管和完全可用状态。
数值预报模式产品资料是各级预报员最重要的预报参考资料,这些产品甫一生成,便即刻送达天气预报、气候预测专家的桌面,供其业务参考使用;同时以满足业务需求的时效,分发至各省级乃至地市级气象部门,供其本地化应用。且只要模式(软件)和基础资料(观探测资料)存在,数值预报产品资料是可再生的,无永久保存的必要。因此数值预报产品资料体积虽大,却始终处于可控可管和可用的状态,未来也将始终如此。
有可能在未来异军突起的是气象服务领域的受众反馈等信息,随着人们生活水平的提高及气候变化影响的日益显现,人们对气象预报的服务质量将日益关注,经互联网将意见、要求、评价等反馈给气象服务部门的现象有可能越发普遍,这对改善气象服务有着十分积极的作用;而如果这部分信息体积迅速膨胀起来,其管理问题对于气象信息技术部门将是一个挑战——但目前尚未出现迅速膨胀的迹象。
因此,气象资料体积虽大,在量级上算得上“大数据”,但却始终处于可控可管可用状态。
根据摩尔定律,从2000年到2014年的十五年之间,相同体积规模的计算机芯片,其处理能力增加1024倍;从2014年至2020年的6年间,处理能力增加16倍。详见表3。
由此可见,即便在涨幅最高的2000年至目前的这十五年间,气象资料的增幅也未超出摩尔定律所标示的计算机处理能力的增幅,今后可预见的未来期间也不会超过。
(2)种类虽多但内部信息单纯,来源单一
气象资料分为14大类,有数百种之多。每种资料所含信息十分单纯:土壤持水量只记载某时某地某规定土壤深度中水份的持有程度,“云能天”只记录某时某地的云量云状、能见度以及天气现象等信息,近百年来不曾变化。即:气象数据体积的增大,是由于时空分辨率的逐步加大所导致的,而不是其它。
气象观探测业务系统只采集那些能够客观反映自然界气象状态的要素,所以气象观探测数据里包含且只包含丰富的气象信息。因此海量气象数据的直接用途只能是气象业务及与之相关联的领域,即:天气预报、气候预测以及气象服务。
麦肯锡公司和Gartner公司始终认为:“大数据是用传统的架构、传统的技术方法无法解决的数据问题”。由上分析可知,气象数据始终处于可管、控、用状态,虽然随着数据体积的不断膨胀,以及原有管理和处理技术架构的陈旧,逐渐出现性能下降、时效减慢等现象,但并非没有解决的技术手段。从这个观点考察,以体积硕大为由称气象数据为“大数据”十分勉强,而且较易产生观念和认知上的混乱;因为衡量体量大小的标准是不断变化的。信息技术的发展突飞猛进,处理及存储能力依照摩尔定律,每18个月增加一倍;今天的大体量规模数据,如果不具备超过摩尔定律的膨胀能力,数年后便很有可能萎缩成中等甚至中等以下规模的数据;这样的事例在IT界俯拾皆是。
3. 大数据理论的适用性分析
3.1 大数据倡导者的基本论点
近年来有关大数据方面的著作如雨后春笋般不断出现,其中被业界公推最具权威性的著作当属由维克托·迈尔-舍恩伯格等撰写的《大数据时代》(以下简称《大》);该书作者就大数据带给人们思维方面的变革,提出了如下三个观点:
(1)当数据处理技术已发生翻天覆地变化时,在大数据时代进行抽样分析已经过时。人们进行分析的对象已不是抽样数据,而是所有的数据,即:“样本 = 总体”。
(2)执迷于精确性是信息缺乏时代和模拟时代的产物,只有接受不精确性,我们才能打开一扇从未涉足的世界的窗户。
(3)知道“是什么”就够了,不必知道“为什么”。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己“发声”。
而对于大数据的价值,该书作者认为,“数据就像一个神奇的钻石矿,当它的首要价值被发掘后仍能不断给予”,它目前展现在人们面前仅仅是其总价值的“冰山一角”。
根据笔者的理解,大数据倡导者之所以提出上述论点,是基于如下推断,即:人们目前所获得的数据中蕴含的信息已足够丰富,以至于所有知识的相关信息都包含在其中,人们可以通过分析这些信息而获得欲知的任何知识;而目前IT技术的高速发展使得数据处理能力已达到足可对全体数据进行处理的地步,使得人们能够通过处理和分析信息而获得知识;即,人们既可以而且也能够通过处理数据而获得任何信息和知识。由于所有答案都可从数据分析中获得,于是理论研究便不再重要了——毕竟人们关心的既不是数据也不是方法,而是答案,无论实验、理论、计算模拟以及数据,都只是获得答案的途径。
这里需要强调的是,通过对海量数据的分析处理而“获得知识”,是“大数据”理论最具特色之处。如果单单是“获得信息”,则上述的一切便沦为简单的对海量数据的处理,与目前传统方法几无二致。令人叫绝的是,大数据倡导者们宣称,这些知识的获取可以不依赖于任何专业知识背景,仅凭“数理统计方法”便可获得;这是前所未有的,也是“大数据”如此迷人之所在——如果须要凭借专业知识背景方能通过处理数据、获得并分析信息进而得到这些新的“知识”,则“大数据”与现在各行业现行工作方式便并无本质不同,笼罩在“大数据”全身的炫目光环便黯然失色、荡然无存了。
这是一个令业界乃至社会不少人士惊讶和兴奋的未来——大数据引爆了一场颠覆性的革命。我们正在并将永远拥有取之不尽的信息资源,这些资源是如此的神奇,以至于人们不必再去孜孜不倦地追求理论的探索和试验的真实,只要坐下来分析这些数据就足够了——数据可以告诉你一切,并且数据还将告诉你所有未知的一切。
3.2 适用性分析
大数据的倡导者们描绘了一幅令不少人激动万分的景象,但是否适用于所有领域,却值得斟酌,至少就气象领域而言,其适用性有待商榷:
(1)气象观探测数据的应用始终是“样本= 总体”
自现代气象学科建立以来,气象观探测数据对于各气象业务及学科研究而言,时空密度、时序长度和数据精准性的不足始终困扰着气象业务和科研工作的深入展开,不存在对花费高昂代价千辛万苦采集而来的无比珍贵的观探测数据,会因其数据量过大、无法全部处理而不得不采取“抽样处理”的情况。即,在气象界的观探测数据处理方面,几乎始终是全数据模式,即所谓“样本 = 总体”。问题是,目前在体量上已跨进“大数据”门槛的气象观探测数据,其内在信息是否已足够丰富到可以不考虑自然法则和物理规律,单凭对这些观探测数据进行统计分析既能实现天气预报和气候预测。
气象学科所涉及到的空间尺度,小到水滴碰撞凝结等毫米级微物理过程,大到罗斯贝波等数千公里尺度行星物理过程,其间跨度达到8~9个数量级;预报对象从10米量级的龙卷风,到千米量级的沙尘暴,直至数千千米量级的季风和厄尔尼诺,跨度亦达到6~7个数量级。这些尺度中的气象要素实际状况都需要探知,做为气象部门十分重要工作内容之一的气象探测业务,数十年来工作的主要目的之一,就是探索在代价允许的条件下,实时获得更小尺度的气象要素状况、并保障其准确性的各种手段和方法。为此人们应用了许多新的技术手段,最为典型的就是雷达技术和卫星遥感技术的实际应用;目前为止气象卫星及天气雷达的空间精度较之传统地面观测的数十公里,已缩小到数百米。
然而既便如此,那些云水微物理过程、边界层湍流、风向风速随高度的垂直变化等实况数据,却是难以甚至无法全面采集的,海洋中的洋面以及近、深层的温度、流向及盐度等要素更是如此。要想全部获得这些数据,单就海洋而言,以现有已知的技术手段,除非汪洋大海上布满了各类用于探测的漂流浮标和锚定浮标。
所以,由于天气载体(云团、水汽、冰晶等)的空间尺度之间存在极大的差异性,以及大气运动各尺度天气载体在时间和空间的变率差异极大,用目前已知技术手段不可能全部探知各个尺度内的天气信息。气象观测采样时间和空间分辨率的有限性,导致气象观测和产品数据在未来数十年间只能是“抽样样本”,而不可能是包含所有信息的“总体数据”。
气候学科需要长时段(上千年乃至数千年)的气象观探测数据,方能通过分析数据寻找到内在的气候变化规律。由于现代气象科学的创立不过一百多年的历史,积累的气象观探测数据时段十分有限,为此气候学家们不得不寻找各种气候代用数据,如:冰芯、树木年轮、花粉、岩心乃至皇宫文献档案记载等。然而这些气候代用数据的时间精度十分有限(最高仅达十年左右),对于现代气候预测学科的贡献相对有限。气候学家曾指出,只有建立起时间长度至少达到数百年的较为精准全面的气候数据序列,方才可能满足气候研究和预测业务的实际需求。
因此,虽然气象观探测数据的使用一直处于“样本=全体”状态,但其获得途径却始终是抽样采集,且其本身无论空间尺度还是时间尺度,都远远无法满足天气和气候业务/科研工作的实际需求。也正缘于此,当听到社会上一些非气象领域的、以数据分析见长的公司宣称将尝试通过运用统计分析方法处理气象观探测数据来进行天气预报时,气象学家们在愕然之余,更多的是哑然失笑。
(2)气象服务的特点要求必须追求尽可能高的精确性
“允许不精确”,这是大数据倡导者们提出的另一个惊世骇俗的,令不少科学家闻之瞠目的口号。一些大数据的拥趸者以气象业务中的集合数值预报为例,证明“允许不精确”论断在气象界的适用,即:
因研究表明,多个模式集合平均后的效果优于单模式,故在单一模式相对稳定,短时间内无法大幅提高其预报效果的情况下,科学家们提出了集合平均方法以及超级集合的概念。与单模式相比,多模式超级集合可以明显减小单模式和集合平均的均方根误差。目前,多模式集合预报可提高天气预报水平已得到广泛认同。
然而,提出此观点的人也许忽略了一点:多模式集合技术本质上是通过减小因模式自身不确定性带来的误差来提高预测能力的,多模式集合的效果依赖于各单一模式的预测能力;在各单一模式没有预测能力时,多模式集合也不能提供足够有用的预测信息。
事实上,“允许不精确”口号提出的前提基础,是确信数据中正确信息足够充分,以至于虽然人们从中随机抽取的每一个数据都可能是不精确的,但人们却可以通过统计分析方法,最终得到正确(精确)的结论。
然而这一前提是值得推敲的,如同Ti m Harford所说,“当数据里的假像远远超过真相的时候,还持有‘数据足够大的时候,就可以自己说出结论了这种观点就显得过于天真了。”要想使“大数据自己说话”,首先必须保证数据中的“真相”足够多,对于气象界的多模式集合预报而言,这意味着各模式必须具有尽可能高的预测能力,亦即:单一模式的运算结果应当越准确、越精确越好。
诚如《大》书作者所言,“执迷于精确性是信息缺乏时代和模拟时代的产物”,但如果信息始终处于匮乏状态,那么精确性就是不可抛弃的。气象观探测数据就是这样,由于气象观探测数据的获取始终是“抽样采样”,因此每一个数据都被认为是其所在时空范围内气象要素真实状态的反映;由于该数据是其所在时空范围内唯一的数据,它的与真实状态的偏差只有通过更大时空范围其它数据的综合统计分析方才可能校正,而校正后的数据是否真实反映了本时空范围内气象要素的状态,却无法予以验证,因为自然界的时空状态是不可回退的;所以,应当尽可能确保每一个探测数据的精准性。
“大数据的核心就是预测”,这是《大》书作者舍恩伯格的名言。预报(预测)在时间、空间、形式和强度方面的更加准确,一直是社会对气象界永恒的需求,也是百余年来召唤气象工作者孜孜不倦工作的目标和动力。就天气预报(尤其是灾害性天气预报)而言,目前的主要目标之一,是准确地预报天气现象(灾害性天气过程)的发生形式,并将发生的时间精确到小时、发生的地点精确到千米量级,同时准确预测过程的强度等。这意味着精确性要求对于气象部门而言,只会越来越高,而不是相反。
(3)气象理论科学研究不会终结
《WIRED》杂志主编Chris Anderson于2008年曾断言,“现在已经是一个有海量数据的时代,应用数学已经取代了其它的所有学科工具。而且只要数据足够,就能说明问题。如果你有1PB字节的数据,只要掌握了这些数据之间的相关关系,一切就都迎刃而解了。” Chris Anderson此言的核心思想是,身处大数据时代的我们,所有的普遍规律都不重要了。如今重要的就是数据分析,因为它可以揭示一切问题。
Chris Anderson先生的论断是如此的激进,以至于《大》书作者对此也认为实在荒谬;在他看来,首先,大数据自身就是在理论的基础之上形成的,亦即,在大数据形成之初的数据选择过程中,人们就始终被理论所影响着;其次,我们在分析数据时,也依赖于理论来指导我们选择所使用的工具;最后,人们在解读研究结果时同样会使用理论。因此该作者对同为大数据倡导者的Chris Anderson先生的观点并不赞同:“大数据时代绝不是一个理论消亡的时代;相反,理论贯穿于大数据分析的方方面面”
使用理论,但不必或不屑于产生“新的理论”,这是《大》书作者就理论在大数据时代中的地位和作用的看法,即:“知道是什么即可,不必知道为什么”,“一切让数据告诉你们”。
自上世纪二十年代动力气象学建立起,通过对观探测数据进行统计分析而进行天气预报的方法,便逐步被动力天气所取代。而对于我国气候预测业务而言,以多种数理统计方法为基础建立的统计预测模型,正在逐步被物理统计、动力模式、动力-统计相结合的方法所替代。单纯对观探测数据进行统计分析,已根本无法满足预报和预测在准确性和精确性方面的要求。以“蝴蝶效应”为例,如果不了解气象要素和天气/气候状态之间的物理机理,即便观探测数据再丰富,也无法通过对观探测数据的统计分析预测出南美丛林中的哪只蝴蝶、在哪种天气背景下、在哪个时间、哪个位置扇动几下翅膀以及翅膀扇动的角度和幅度如何,方能在几周后的哪一天的哪个时刻引发北美哪个州的哪个位置的暴风雪。
理论的作用在于解释现象并预测和指导未来,由于目前无法全部获得各个时空尺度中天气要素的实况,观探测数据只能告诉我们一定时空尺度范围内的天气实况,次尺度以下的天气过程只能通过理论分析、建模和模拟等方法予以解释,并通过试验予以验证。又因为气象学科所涉及的时空尺度跨度极大,对天气过程中至为重要的微物理过程无法全面探知,观探测数据在可预见的未来始终是“抽样采集”;因此在可预见的未来,对于气象学科而言,试验、理论和模拟这三种科学发现范式将始终存在,不可或缺——尤其是理论。
综上所述,大数据理论的三个主要观点,即:“样本=总体”、“接受不精确性”和“理论不再重要”,并非是普适性的——至少在气象领域存在适用性问题。
气象数据的“大数据应用”价值辨析
4.1 “大数据应用”定义的困惑
与云计算类似,业界对大数据的定义不胜枚举;维克托·迈尔-舍恩伯格在《大》一书中是如此定义的:“大数据(应用)是人们在大规模数据基础上可以做到的事情,而这些事情在小规模数据的基础上是无法完成的”。
然而我们知道,人们对数据规模的认知是根据当时IT技术所能提供的处理能力而决定的;亦即,数据规模的界定是随IT技术发展而动态变化的;表4是不同年代属于“大规模数据”的数据体量量级。
因此,此定义如不设定适用的时间范围,是颇值得商榷的,因为如按此定义,至少就气象部门而言,意味着气象业务和科研工作始终是“大数据应用”;因为在表4所列年代中,气象观探测数据的体量皆达到当时的“大规模数据”标准,而且全部在被充分使用之中;其它如农业、水利、石油勘探、地震、海洋乃至金融、电信等行业也莫不如此。
依笔者对该书作者观点的理解,就数据量巨大,内含信息空前丰富的当下而言,所谓“大规模数据”和“小规模数据”,具体对应的应当是“全体数据”和“抽样数据”,即:“大数据应用是目前人们在‘全体数据基础上可以做到的事情,而这些事情在‘抽样数据的基础上是无法完成的”。
令人沮丧的是,以这一经过调整的定义来观察气象行业,依然难以辨识“大数据”与日常气象业务科研之间的本质差异,因为全体气象观探测数据都在被充分使用着,几乎不存在因数据量过于庞大无法处理而不得不使用“抽样数据”的情况。而近年来气象观探测数据体量上的巨大膨胀,也并未给气象业务的发展轨迹和发展形态带来颠覆性的变化。如果说由于目前使用了时空密度更为精细的观探测数据,使得天气预报和气候预测结果更加精准,从而派生出其它新的气象服务领域,那么倒退10年20年,同样也是类似的情形。因为每次采用空间密度更密,精确度更高(自然,数据体量也较原来更大)的观探测资料后,都会对预报结果有所改善,这种情况在过去几十年里一再不断地重复出现着。而如果这就是气象界所谓的“大数据应用”,那么气象界数十年来一直在“大数据应用”——只不过名词不同而已,过去称其为“业务发展”。
气象观探测数据的“大数据应用”,不应是一场文字游戏。
笔者认为,气象数据的“大数据应用”,应当是人们通过对海量气象数据的深入分析,挖掘出有别于目前业务内容和科研学科分支的,崭新的、令人意外且惊喜的业务领域、方法和学科分支——即:通过对海量气象观探测数据的分析,人们获得了崭新的知识,而不仅仅是信息。
所以,大数据应用的标志不止在于对体量庞大的数据的使用,而且在于通过且仅仅是因为通过对这些体量庞大数据的分析处理,人们从中获得了崭新的知识——获得知识,而不仅仅是获得信息,是“大数据应用”区别于“大数据处理”的核心标志。
4.2 海量气象数据的价值范围辨析
沃尔玛能够通过分析得出婴儿纸尿布与啤酒之间销量上的正相关关系,是因为其数据库中包含所有本系统连锁店中所有商品的销售记录,包括啤酒和婴儿纸尿布。阿里巴巴企业能够提前半年预测出2008年北美将爆发经济危机,是因为其数据库中详细记录了数年来世界各地与阿里集团的每一笔订单和询单,可从中统计并发现出其异常变化以及变化的区域分布,并进而做出推断。美国中央情报局能够通过对电子邮件的筛选探知出几十起针对本土的恐怖袭击计划,并提前采取相应措施,是因为恐怖分子使用电子邮件进行通信联络,留下了相关的痕迹。而气象数据与之不同:如前所述,气象观探测数据体量虽大,但与互联网大数据相比较,气象数据的信息种类单纯。无论多么优秀的金融分析师,都不可能单从分析海量气象观探测数据来预测纽约道琼斯股票的涨跌以及沪深股市的未来走向,因为气象数据里根本不含有任何这方面的信息。做个比喻:气象观探测数据是一个含量极纯的“富铁矿”,人们穷尽各种方法,也只能从中冶炼出铁和钢材来。那种企图通过改进冶炼方法来从中提炼出铝、铜、银乃至金的想法是注定会落空的——因为此矿中根本不含有这些物质。
做为“自然界感知信息”的气象观探测数据,产生于自然界,它反映的是自然界与气象有关的各种要素的状态以及变化轨迹;而互联网大数据产生于人类社会,它反映的是人类社会活动的痕迹。自然界与人类社会虽有千丝万缕的联系,但却无法完全等同,否则管理学、心理学、经济学、国际政治学以及社会学等专注于人类社会的学科便没有存在的必要了。正如“丛林法则”不会永久适用于人类社会的高级形态一样,社会学中的一些结论和方法也未必可以简单地套用到自然学科中来——对于海量气象观探测数据也是如此。
大数据时代数据体量迅速膨胀的背后,是信息量的迅速丰富。而导致信息量丰富的原因至少有两种,其一是信息种类的不断丰富,即信息涉及(采集)面的扩大;其二是信息密度的丰富,即信息种类(即采集面)没有明显增加,但同种信息的采集密度却大幅增加。互联网大数据属于前者,而海量气象观探测数据则属于后者。所以,与互联网大数据不同,海量气象数据的核心和基本价值,始终是气象业务的应用,而不是其它。
气象观探测数据时空密度的增加,使得较原来更小尺度的气象要素及变化痕迹得以被探知,从而为气象学家们提供了研究这一尺度内气象规律的实况依据;这是海量气象观探测数据在本领域内的“大数据应用”。此外,如胡小明先生所言:虽然一些数据所蕴含的其所属领域的内部规律(即所谓“首要价值”)已被本领域专家充分发掘,但如果将这些数据与其它领域数据相链接,却有可能发现出许多意想不到的相关关系,即所谓“丰富的未知价值在领域的外部”。气象观探测数据的“新的价值”的发现,或许寄希望于此。但令人担忧的是,数据的社会共享至今仍是一个世界性难题。美国政府多年以来一再发布政令,要求政府部门在规定期限内将与国家安全无关的数据实现社会共享,从一个侧面反映出数据社会共享的难度。在我国,早在二十一世纪初便由科技部主导的科学数据共享试点工作,十余年来进展并不顺利,行业间的数据并未真正实现共享,气象部门获得某些相关部门的观测数据异常困难。因此,气象数据通过跨行业深度结合而挖掘其“新的令人兴奋的应用价值”的必要环境并非已全部具备。
4.3 “第四范式”的方向性启示
虽然目前看不到通过对气象观探测数据的数理统计分析,即可进行准确天气预报(或气候预测)的可能及可行性,但气象观探测信息在近年来的迅速丰富,却是不争的事实。由于观探测数据采集密度的不断增大,许多小尺度天气过程开始被探测和捕捉到,动力天气学中一些过去由于信息和计算资源的短缺而不得不采用参数化方法以平均态方式予以解决的物理过程,现在有可能通过较为精确的大规模计算而得到更为精确的积分结果。历史上,每一次观探测密度的增加,都对天气预报的准确性起到一定的积极作用,并在一定程度上丰富了气象学的理论和知识。所以,观探测信息采集尺度的缩小,使得气象学家们通过分析这些小尺度信息,获得较大尺度天气状况以及变化规律的期盼成为可能——需要注意的是,这种分析过程所采用的工具不仅仅是应用数学一门学科,而是数学、物理学、化学、生物学乃至人类学等诸多学科知识的综合运用,此外还需要气象学家们丰富的知识和智慧。
通过综合运用所有已有知识,对信息量迅速丰富的数据进行分析,可以补充完善现有知识,甚至获得新的知识,这是《第四范式:数据密集型科学发现》作者的主要观点,也是《大》书作者极力宣扬的。问题在于该模式(即:数据密集型模式)是否将取代人类历史进程中依次产生的“试验”、“理论”和“计算模拟”这三种模式,而成为未来唯一的科学发现模式?《大》书作者对此是肯定的,所以产生出“理论不再重要”和“接受不精确性”的派生观点;而笔者在上面耗费大量篇幅无非是要证明,这一豪情万丈的结论目前并不适用于气象领域。虽然面对的都是大数据,都是讨论通过对大数据的分析获得新的知识和方法,但《第四范式》的作者无疑是冷静和缜密的,结论令人信服。相比较而言,《大》书作者则显得轻率和极端,得出的结论在不少部门和行业难以现实落地——至少在气象部门是这样。所以,即便是真理,也不能随意向前多迈一步。
如何应对“数据密集型科学发现”在气象行业的具体实现,这是《第四范式》给气象IT部门提出的新的课题。事实上,“海量气象观探测数据的规范化存储管理和高时效应用”这一现实命题,已经挟气象数据的滔滔洪水骤然降临了;随之而来的还有海量气象观探测数据的高速传输、科学分析、处理和高效应用等课题,限于篇幅,笔者将另文详述。
综上所述,可得出如下结论:
(1)目前气象数据体量虽大,但增速缓于摩尔定律。在未来的数年或十余年后,其体量将渐趋适中。同时,由于气象观探测数据中所含信息在空间密度和时序长度方面都与实际需求存在差异,且短期内无法解决,因此无法达到单凭通过对数据的分析处理便可不断获得新的气象知识的程度。以“接受不精确性”和“理论不再重要”为特征的《大数据时代》思维变革观点目前并不适用于气象部门。
(2)现阶段海量气象数据的“大数据应用”,除本行业内深度挖掘之外,最大的可能在于与其它相关行业或领域数据的深度融合,以获得跨领域跨学科的“新知识”。然而这需要科学数据社会共享这一大环境的有效改善。
(3)“数据密集型科学发现”将成为未来气象科学发展和进步的新的途径和模式,气象IT部门应予以充分重视。
5. 结语
信息的迅速丰富,导致大数据时代的来临。面对几乎取之不尽用之不竭的信息,一些人束手无策、一些人欣喜若狂、一些人充满激情地畅想着未来,还有一些人则将其描绘成一面绚丽的大旗,并将其覆盖在自己原本滞销的货物之上,以期连旗带货一同高价兜售出去。
对于气象部门IT从业人员而言,“大数据”不是旗帜,也不是时髦名词,而是一个需要认真思考的现实问题:如何将这些珍贵的气象信息的价值发挥到极致。有一点可以肯定,这绝不是气象IT部门一家的事情,这需要气象学家、IT工程师以及有关职能部门的通力合作,方才可能实现。同时它有可能意味着气象学科传统研究方法乃至机制的变化。
本文在修改过程中,得到了周秀骥院士以及熊安元、施进民、赵立成、李维京、惠建中、许泳、黄王旬 专家的指点,在此致谢。
作者单位:国家气象信息中心
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18 13:11:03
内蒙古气象(2021年2期)2021-07-01 06:19:58
青少年科技博览(中学版)(2020年1期)2020-04-21 08:57:46
心声歌刊(2019年5期)2020-01-19 01:52:52
领导决策信息(2018年46期)2018-04-20 04:00:42
百科探秘·航空航天(2017年11期)2017-12-20 07:31:28
商情(2017年1期)2017-03-22 21:46:58
大陆桥视野·下(2016年11期)2017-02-28 10:33:49
中国教育信息化·高教职教(2016年11期)2017-01-03 21:55:08
商业会计(2016年6期)2016-04-07 02:08:16
