
词类扩充方法在语音识别中的应用
2014-03-21 05:13:14杨林国
电子技术应用 2014年6期
杨林国
(安徽职业技术学院,安徽合肥230061)
近年来,自动语音识别ASR(Automatic Speech Recognition)在移动互联网中受到越来越多的重视。其中,基于N-gram的统计语言模型LM(Language Model)训练是ASR中听写(dictation)应用的重要组成部分。但是N-gram语言模型面临两个重大的问题,即数据的稀疏性[1]和对训练语料的强依赖性。一般情况下,要训练相应的N-gram的语言模型,必须在相应的领域搜集大量的领域语料,并且利用各种有效的平滑算法[2]来解决数据的稀疏性。但是,在实际的应用中,对于领域相关的语料需要大量的人力来搜集或者无法得到,同时特定领域具有特定的分类(如歌手名)和实时性,这限制了在特定领域中语音识别的应用。因此,在这种情况下,基于特定领域的词类扩充方法在语音识别中十分重要[3]。
通常情况下,传统的特定领域的语言模型流程是将一个通用的、训练充分的通用语言模型和一个特定领域的、训练不充分的特定领域模型通过某种方式组合成一个新的模型。因此,这种自适应技术通常也叫话题自适应或者领域自适应技术。可以使用大量的文本训练成一个通用的语言模型M,在给定特定领域的少量语料S后,语言模型自适应的目标就是利用M和S为该特定领域生成一个特定领域模型。用这种方法能够取得比较好的结果[4-5]。但是,这种传统的方法无法满足特定领域词表的不断扩充和实时性。
为了解决特定领域的词类扩充和自适应问题,本文设计了基于分类的语言模型和HCLG[6]结合的新型解码方法,如图1所示。首先需要设计带标签的词类的语言模型,将通用和特定领域语料中的类别用标签替代,训练生成基础词类模型,通过构图生成相应的HCLG。同时,将类别的词表生成有限状态图。最后通过标签将两个HCLG图替换合并,生成自适应特定领域HCLG。此外,由于类别词表相当于语料变动很小,可以不断更新并快速地应用到实际的环境中。
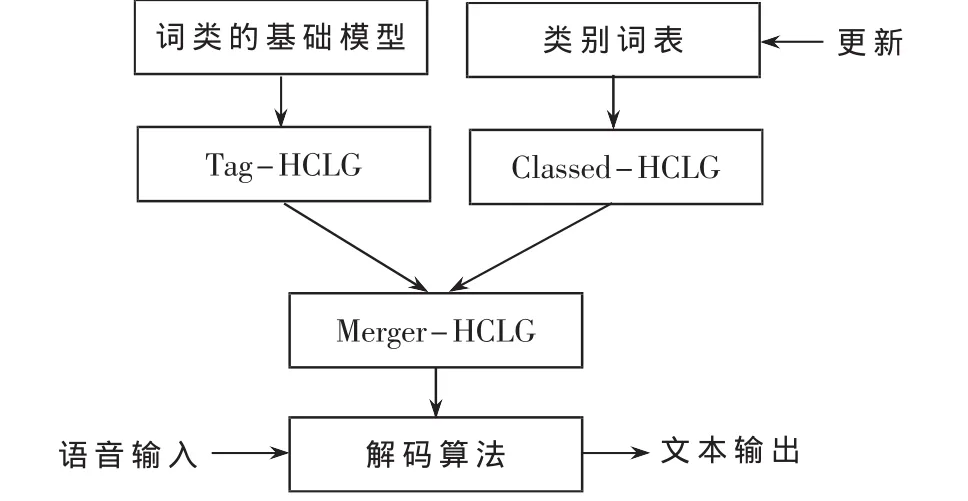
1 带标签的分类语言模型
1.1 N-gram语言模型
N-gram模型[6]于1980年提出,是一种应用广泛的统计语言模型。它采用Markov的假设,即每个词的出现只与前n-1个历史词有关,即:

其中s=w1,w2,w3…wn,w1,w2,w3…wn表示n个词。

其中,c(w1,w2,w3…wn)表示w1,w2,w3…wn在语料中出现的次数。
N-gram语言模型被广泛应用在语音识别、文本处理等各种领域。但是,N-gram语言模型存在一个问题,当一些词汇在学习语料集中没有出现而出现在测试集中时,则会出现数据的稀疏性问题。在特定领域的应用中,这种数据的稀疏性问题[7]尤为突出。虽然目前提出了很多平滑算法来解决此类问题。但是在特定领域中不能解决专业词汇或者新词的问题,如歌曲识别中的歌手名和歌曲名,在互联网中每天都在更新且数量巨大。另一种方法是通过对单词的聚类减小模型空间来解决数据的稀疏问题。本文基于改进的分类的语言模型来快速扩充词汇,解决数特定领域的数据稀疏问题。
1.2 带标签的分类语言模型
在上文中,特定领域中语言模型的数据稀疏问题尤为突出。而基于词类的语言模型是对基于词的语言模型的改进,可以解决此类问题。
假设类别用tag表示,如“我想听青花瓷(tag)”,即:
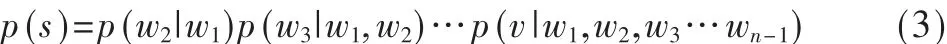
其中s=w1,w2,w3…tag,w1,w2,w3…v表示n个词。
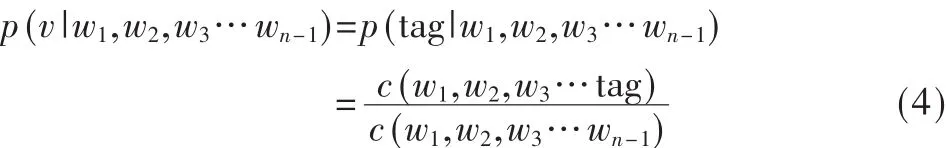
由式(4)可以看出,tag是类别标志,在学习训练时,将语料中的类别词用tag来替换,训练生产的语言模型就是关于tag分类的语言模型,如图2所示。
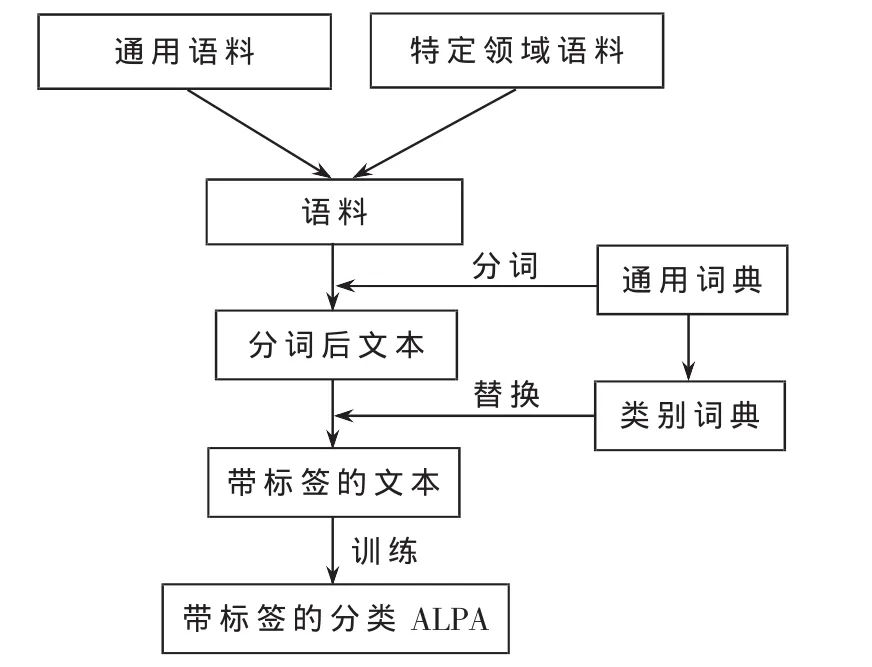
目前的分类的语言模型在计算类别词的概率时是通过平均类别的概率来计算的,在语音识别中,不能快速产生新的解码图结构,并且类别间的空间均分在实际的特定领域中时存在识别率降低的情况。因此,本文将带标签的分类的语言模型在HCLG上进行合并,提高生成新模型的速度和特定领域的语音识别率。
2 HCLG的生产和合并
2.1 HCLG构图
以加权有限状态转换器WFST(Weighted Finite State Transducer)[7-8]为框架的大词汇量连续语音识别系统被广泛的应用,目前很多主流的语音识别系统均采用这一框架。语音识别的解码任务可以看成是在语言模型、发音词典规律、上下文相关和隐马尔可夫模型等知识源限制下,寻找一个最有可能的隐马尔可夫模型状态序列的过程。
语音识别解码就是在给定输入特征序列下寻找最优的次序列w,即在式(5)中寻找最优的次序列。将式(5)进行分解,表示成不同的知识源,并将它们表示成加权有限状态转换器的形式,如表1所示。


表1 语音识别中各种知识源的WFST表示[9]
语音识别中的加权有限状态转换器(HCLG)的整体结构如图3所示[8-10]。
通过分析可以看到,本文中主要是对语言模型(G)进行修改和改进。因此在下面的讨论中,将HCLG简化为G的图结构来讨论,但是G具体包含了HCLG的所有信息,只是表示上方便。
2.2 HCLG合并
在上一小节中,对HCLG的结构进行了解析,在本小节中,对之前产生的带标签的分类的语言模型在HCLG进行合并。以歌曲特定领域为例分析HCLG的合并过程,其中文中的HCLG是简化了的HCLG。
如图4所示是一般的HCLG图结构,在节点间的弧上是N-gram语言模型产生的连续连接词。在1.2小节中介绍了带标签的分类语言模型,如图5所示即为产生的带标签的分类的HCLG,即将图4中的歌曲名和歌手名用tag-song和tag-singer来代替。带标签的分类的HCLG是由图产生的ALPA语言模型通过OpenFst工具产生G.fst,再通过和发音词典(L)、上下文相关音字模型(C)和隐马尔科夫模型(H)一系列操作进行生产。
对于类别的词汇,需要建立字的HCLG,即将单个字做为一个词建立ALPA,然后按照建立HCLG的流程生成类别的HCLG,如图6所示。
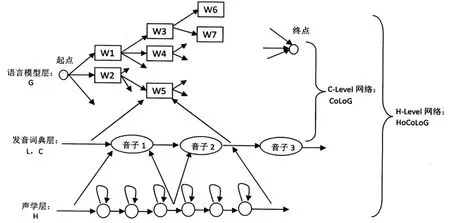
图3 语音识别中的HCLG
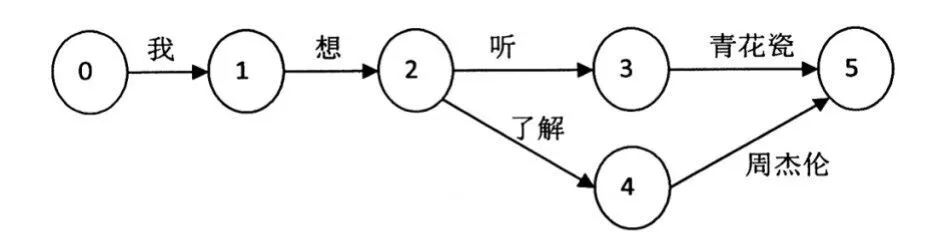
图4 一般HCLG图结构
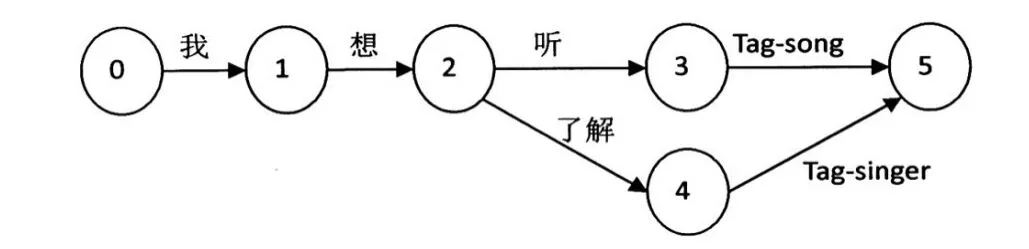
图5 带标签的HCLG

图6 歌手和歌曲的HCLG
有了以上带标签的分类的HCLG和类别的HCLG,即可以通过替换进行图的合并。如图7所示,将图5中的tag-singer和tag-song的弧用类别的HCLG来代替,在替换弧的前后加上eps弧,以使在进行图搜索的过程中与改变之前保持一致。
3 系统实现及讨论
实验所采用的声学模型是由100 h的863语言库采用Kaldi[9-10]的DNN训练工具训练所得。实验采用39维特征参数,包括2维Mel频率参数(MFCC)和normalized Log能量值以及它们的一阶、二阶差分和倒谱均值正规化CMN(Cepstral Mean Normalization)。音素集合使用CMU重音词典中定义的39个音素,加上一个3状态的静音模型和一个单状态可跨越的短暂停模型。
对于语言模型,针对歌曲特定领域,选取了两个类别:歌曲名和歌手名。歌手列表2 000个,歌曲列表5 000个,语料是由百度歌曲知道和搜狗开放语料库的文本混合而成(10 GB)。
使用3个小型的测试集进行测试,每个测试集包括音乐相关的问题200句。在使用音乐的限定模型进行体验测试,语音识别效果相对于普通的方面在3个测试集上都有所提高,并且歌手名和歌曲名的识别率得到提高,这使得在实际应用中可以较好地利用这些准确信息,例如QA系统的实体识别。
本文提出了一种限定领域的词类扩充方法,该方法从语言模型的改进和HCLG的合并两方面来提高限定领域的语音识别结果。这种方法可以使得语言模型变得平滑,以适应限定领域的词汇扩充。同时,通过HCLG的标签替换可以减少HCLG的体积大小,从而提高搜索的效率。只要有分类的限定领域的词表和合适的领域语料,该方法就能在语音识别中获得不错的识别结果。所以,这种方法在限定领域中有很多应用。不过,在本文中没有对词类间的联系进行统计和使用,使得在词类间的查找缺乏一定的选择方案,在接下来的研究中,将会探究词类间的关系,进一步提高限定领域的语音识别效率。
[1]邢永康,马少平.统计语言模型综述[J].计算机科学,2003,30(9):22-26.
[2]FEDERICO M.Efficient language model adaptation through MDI estimation[C].Eurospeech,1999:1583-1586.
[3]戴海生.实用的家电语音控制系统的设计与实现[J].电子技术与应用,2005,31(9):43-45.
[4]ROSENFELD R.A maximum entropy approach to adaptive statistical language modelling[J].Computer Speech&Language,1996,10(3):187-228.

图4 两种不同算法对不同人脸库识别率的比较
[5]JELINEK F,MERCER R L.Interpolated estimation of Markov source法的人脸识别的方法。在ORL和Yale人脸数据库上进行了实验,并对实验结果进行分析,结果表明,该方法能对人脸库中由于光照条件引起的图像过亮或者过暗起到很好的补偿作用,使得人脸图像更加清晰,提高了人脸识别的识别率。在下一步研究中可以考虑人脸图像表情变化或者人脸某些部位被遮挡时对人脸识别带来哪些影响。
参考文献
[1]阮秋琦.数字图像处理学(第二版)[M].北京:电子工业出版社,2007.
[2]谢赛琴,沈福明,邱雪娜.基于支持向量机的人脸识别方法[J].计算机工程,2009,35(16):186-188.
[3]张健,肖迪.基于多尺度自适应LDA的人脸识别方法[J].计算机工程与设计,2012,33(1):332-335.
[4]石兰芳,姚静荪,温朝晖,等.扰动激光脉冲放大器增益通量系统的渐近解法[J].南开大学学报,2012,45(5):19-23.
[5]WRIGHT J,GANESH A,YANG A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[6]郑庆,闵帆,陈雷霆.基于复合变换的人脸光照补偿方案[J].计算机应用研究,2008,25(2):507-508.
[7]张铮,王艳平,薛桂香.数字图像处理与机器视觉[M].北京:人民邮电出版社,2010.
[8]边肇祺,张学工.模式识别(第二版)[M].北京:清华大学出版社,2000.
猜你喜欢
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
广东蚕业(2019年3期)2019-05-14 05:37:40
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:10
海外华文教育(2016年1期)2017-01-20 08:21:58
现代语文(2016年21期)2016-05-25 13:13:29
新校长(2016年8期)2016-01-10 06:43:59
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
商事法论集(2014年1期)2014-06-27 01:20:42
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
