
基于OpenCV的手持式和面板式数字仪表自动采集系统*
2014-03-14 03:26王家澍姜鸣李上海大学上海市质量监督检验技术研究院
上海计量测试 2014年2期
王家澍姜 鸣李 宸/ 1. 上海大学,. 上海市质量监督检验技术研究院
基于OpenCV的手持式和面板式数字仪表自动采集系统*
王家澍1,2姜 鸣2李 宸2/ 1. 上海大学,2. 上海市质量监督检验技术研究院
利用OpenCV计算机视觉库,通过图像/视频感知设备对手持式和面板式数字仪表的显示区域进行图像采集,在对图像几何校正、自适应阈值二值化等预处理后,使用霍夫变换校正倾斜字体,随后对图像先垂直再水平分割,进行图像归一化处理,利用七段码的12个特征值经过训练构成神经网络,最终完成对字符的识别。
OpenCV;数字仪表;自动采集系统
0 引言
随着自动化技术的发展,带有程控接口的数字仪表已经越来越多地使用于自动校准技术,显著提高了工作效率和测试准确度。但市场上仍有数量众多的手持式和面板式仪表,无法由程控接口进行完整的“控、讲、听”操作。通常习惯把计算机称为“控者”,把能够发送数据的设备称为“讲者”,把接收数据的设备称为“听者”。本文介绍的基于OpenCV图像识别技术,可解决其中关键的“听”问题,使手持式和面板式仪表的测量值可以由计算机自动获取。
1 OpenCV简介
OpenCV是Intel资助的开源计算机视觉库,具有大量通用的计算机视觉算法,拥有强大的图像处理功能,实现图像采集和处理。OpenCV拥有如下优点:
1)主要由一系列C函数和少量C++函数构成,同时也提供对C#、Ruby等语言的支持;
2)使用目的是开发实时应用程序,可在Windows、Linux或MAC OS操作系统间进行移植;
3)独立于操作系统、硬件和图形管理器;
4)具有通用的图像/视频载入、保存和模块获取;
5)具有强大的图像及矩阵计算能力,提高开发效率和运行可靠性;
6)所有算法都是基于封装在IPL的动态数据结构,且多数函数对Intel处理器指令代码进行了优化。
OpenCV在图像/视频处理方面突出的优点是在计算机与摄像头之间提供一个方便的软件接口,可以采用简单的函数来实现对摄像头的驱动和图像采集,且由于它集成了DirectShow技术,视频采集时可以达到很高的实时性能。
2 图像识别流程
本系统在VS 2008平台下使用C#调用OpenCV库函数,而能供C#使用的OpenCV库为Emgu CV。测试的对象为数字多用表。
整个图像识别过程可以分成图像捕获、图像几何校正、获取显示区域图像、自适应阀值二值化、图像垂直校准和图像识别六个部分。
2.1 图像的捕获
通过调用网络摄像头的接口程序,在程序中利用OpenCamera()函数打开摄像头。之后通过调用GetcurrentIamge()函数以BMP格式抓取1帧图像。由于需要对每个数据进行不确定度评定,所以每一点都要连续采集10个数据,即10帧图像。经多次实验确认,从捕获1帧图像至完成最终识别用时小于60 ms,所以对一个数值进行10次图像识别可在1 s内完成。
2.2 图像几何校正
数字多用表的显示屏外有一层塑料材质的保护屏,因此会产生反光现象。如果摄像头与被校数字多用表的显示屏成垂直状态时(如图1),数字多用表的显示屏上会有摄像头的阴影(如图2),且此阴影重叠在显示数据上,无法通过滤波或二值化等方法完全去除。通过多次实验发现,摄像头只要能与显示屏有一定的偏差角度,即可解决(见图3和图4)。
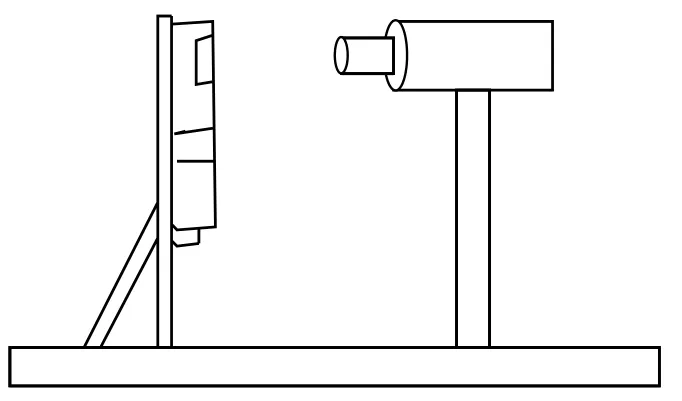
图1 垂直采集

图2 有阴影
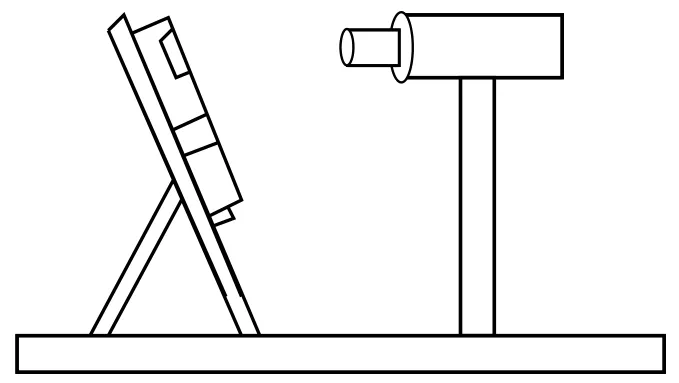
图3 倾斜采集

图4 无阴影
但是新的问题也由此产生。正因为摄像头与显示屏有了夹角,所以由摄像头捕获的图像从原有的长方形变成了梯形,产生图像失真(见图5)。而该梯形失真将直接导致小数点区域的错误分割。

图5 梯形失真
针对这一情况,需要对图像进行如下处理:先通过比较图像中显示屏上下两条边的长度差,得到需要校正的像素点及方向;再利用图像插值算法把梯形图像还原为原来的长方形。即通过GetPerspective Transform()对应点列表计算变换矩阵。它形成的是四个点的数组,方便把源图像的四个角映射到目标图像上。然后利用WarpPerspective()函数实现最终的矩阵变换。
2.3 获取显示区域图像
摄像头获取的图像要比数字多用表的显示屏大,因此需先在图像中对显示屏区域进行定位,才能进行下一步的图像处理。由于目前数字多用表的显示屏多采用单色液晶屏幕,其底色、显示色及边框产生的阴影在平面图像中区分度不高。而且为方便人工观察,有些型号的数字多用表把显示字体做得非常大,基本撑满了整个显示屏高度,使得摄像头获取的图像中,显示字体已经和边框连接在一起,这对单个字符区域的勾勒和划分带来极大困难。为使系统能更好对显示屏区域进行定位,需要在系统测试之前先获取一幅数字多用表关机状态图像。此时,显示屏上只有单色液晶屏幕的底色,且颜色比较一致,这样就能使系统自动定位其显示屏区域,并能很好地保证定位区域的最大化,防止显示屏区域被错误划分。
2.4 自适应阀值二值化
摄像头获取的图像信息是彩色的,每个像素点由R、G、B(即红色、绿色和蓝色)三个分量组成。直接采用彩色图像处理会大大增加系统的计算量,很难达到实时、快速识别的目的。YUV是编译颜色空间的种类,其中Y表示明亮度,U表示色度,V表示浓度。Y分量物理意义是点的亮度,反映亮度等级。
依据RGB三原色和YUV颜色空间的变化关系,建立如下公式:
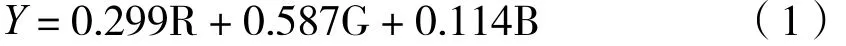
如果把不同深度的颜色作为一色的话,灰度图像就不止黑白两色。通常使用的灰度图由256种不同灰度级组成。当然,对转换后的灰度图像还需进行去噪滤波处理,从而对图像进行局部增强,改善图像的灰度比。
二值化后的图像具有存储空间小、处理速度快等优点。而且用二值化的图像比灰度化的图像具有更好的相关性能和去噪作用。在图像的符号匹配方面,二值化比灰度化更适合用符号来表达。在进行二值化前,还需要对图像有一定的预处理,之后再对直方图选取合适的阈值。
系统采用自适应阈值二值化方法。因为全局二值化是设定一个全局的阈值T,然后根据T将图像的数据分成大于T和小于T的像素群。这种方法简单实用,但在表现图像细节方面存在很大缺陷。而局部二值化是按照一定的规则将整幅图像划分为N个窗口,对这N个窗口中的每一个窗口再按照一个统一的阈值T′将该窗口内的像素划分为两部分,再进行二值化处理。T′是没有经过合理运算得到,一般是取该窗口的平局值。这就导致在每一个窗口内仍然出现的是全局二值化的缺陷。而自适应阈值二值化是把阈值本身作为一个变量。阈值T(X,Y)在每个像素点都不同,通过计算像素点周围的b×b区域的加权平均,然后减去一个常数来得到自适应阈值。在程序中使用以下命令来实现。
Image<Gray, Byte> smoothed = image. ThresholdAdaptive(new Gray(255),
Emgu.CV.CvEnum.ADAPTIVE_THRESHOLD _TYPE.CV_ADAPTIVE_THRESH_MEAN_C,
Emgu.CV.CvEnum.THRESH.CV_THRESH_ BINARY, 41, new Gray(7));
其中CV_ADAPTIVE_THRESH_MEAN_C是对区域的所有像素平均加权,CV_THRESH_BINARY则是阈值类型。
2.5 图像垂直校准
由于目前使用的数字多用表型号各异,其显示数字的形式也不尽相同。有些显示数字是完全垂直的,而有些显示数字向右稍微倾斜一点,这就影响了对小数点位置判断的准确率,从而又影响到对后继数字的识别。为此,需要对这个图像进行垂直化校准。实现方法是找出数字中的竖线,计算出该竖线和水平线的角度,对图像进行相应的角度旋转,从而保证处理后图像中每个数字都是完全垂直。图6所示的四位数字都以同一角度向左倾斜。

图6 字体倾斜
利用霍夫变换进行检测,其主要优点在于受噪声和曲线间断影响较小。在已知曲线形状条件下,霍夫变换实际上是利用分散的边缘点进行曲线逼近。其基本理论是二值图像中的任何点都可能是一些候选直线集合的一部分。本系统先用HoughLines()函数得到与线段垂直的极坐标形式的线段图,随后使用GetExteriorAngleDegree()函数求得各线段的倾斜角度,并判断该夹角是否大于60°。如果大于60°,则求出这些线段的平均倾角,并作为判断是否进行修正依据。若要修正,则先调用GetPerspectiveTransform()函数计算出变换矩阵,再调用WarpPerspective()函数对图像进行变换,从而达到图像垂直校准的目的。使用霍夫变换的函数如下:
LineSegment2D[][] lines = smoothed. HoughLines(new Gray(50), new Gray(200), 1.0, 3.14 / 180, 50, 50.0, 10.0)
这条语句首先利用Canny算子定义了两个上下限阈值,它可以对图像进行提边,以降低后续霍夫变换的计算量。然后设定像素分辨力和弧度分辨力,其次是设定构成线段的直线像素点的累计个数和最短线段的像素点数,最后给出线段分离间距,如果小于给定值,仍然可判定为一条线段。
2.6 图像的识别
要识别整个图像,需先对图像中的每个数字进行单个识别。如果被检数字多用表的显示数字清晰正确,利用七段码的四个特征数据就能很好地识别。但遇到笔划有残缺时,就有可能造成误判。本系统引入神经网络,除了要考虑七段码的四个特征外,同时还考虑了八个图像区域中的黑点成份,从而减少断笔造成对识别正确性的影响。系统对每个型号的数字多用表都增加了训练这一步骤,对经过训练的字符图像进行匹配识别,按匹配度最大原则,决定其唯一字符。没有经过训练的数字多用表,由于其八个图像区的特征点未经学习,所以通过神经网络的预测值会比较低,可信度变差,只能用七段码的四个特征数据来判断。
无论对数字多用表进行训练与否,都先要对图像进行垂直和水平分割,再对图像进行归一化处理,采用提取特征向量方法,利用七段码的特征数据来进行识别,从而保证识别过程中的准确性与快速性。2.6.1 垂直和水平分割
基本方法是对二值化后的图像统计横竖亮点个数,然后先垂直投影分割,再进行水平投影分割。利用函数公式:
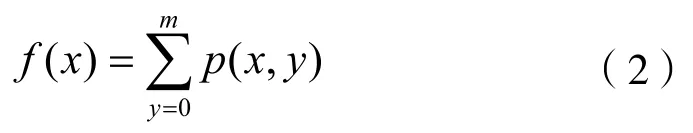
其中:p(x,y)为x,y点处的灰度值,m为整个矩形框垂直方向的像素点数量。
用字符之间间隔的特点,对字符图像先进行垂直投影,相邻字符之间间隔的投影值正好处于f(x)的波谷处,此处就为字符分割位置。同时,为了区分同一纵向但不同高度的字符,比如“1”和小数点,需要再进行水平投影。利用水平投影,可以得到f(y),找到相应的波谷进行水平方向分割。两者结合,就可以得到单个字符的区域图像。
2.6.2 图像归一化
为使图像可抵抗几何变换影响,还需找出图像中的不变量,从而得知这些图像原本就是一样的或者是一个系列的,在完成字符分割后还要把图像归一化成32×16二值图像。把整个归一化后的字符区域全部像素作为特征,在图7中把由虚线构成的8个网格作为8个特征数据,再加上A、B、C、D四线组成的“井字线”测得的线段数,总计形成了12个特征数据。
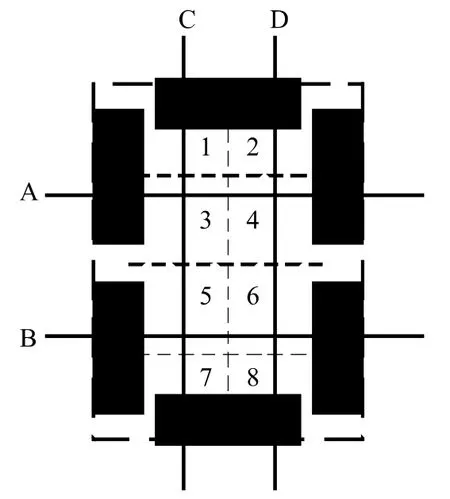
图7 归一化的二值图像
2.6.3 神经网络
利用OpenCV提供的神经网络/多层感知器对特征数据进行训练。本系统采用的神经网络有一个输入层、三个隐层和一个输出层。其中每个隐层各有36个结点,输入层有12个结点,对应归一化后形成的12个特征值,输出层则对应识别的结果。整个训练过程由ANNMLPTrain()函数来完成,它生成的神经网络数据可保存在XML格式的文件中,需要时可用ANNMLPLoad()函数将其调入。
字符识别就是将采集的特征数据经过神经网络/感知器进行预测的过程,其中调用了ANNMPLPredict()函数。感知器根据训练样本得出的神经网络对特征数据运算后,会按匹配的相似度输出一组结果。在此结果中找出相似度最高的作为可能的结果。本方案中设定相似度大于95%才能认为可识别。
2.7 图像识别流程
通过上述六大步骤,被校数字多用表的显示数值可由计算机正确识别,图8描述了整个图像识别的流程。
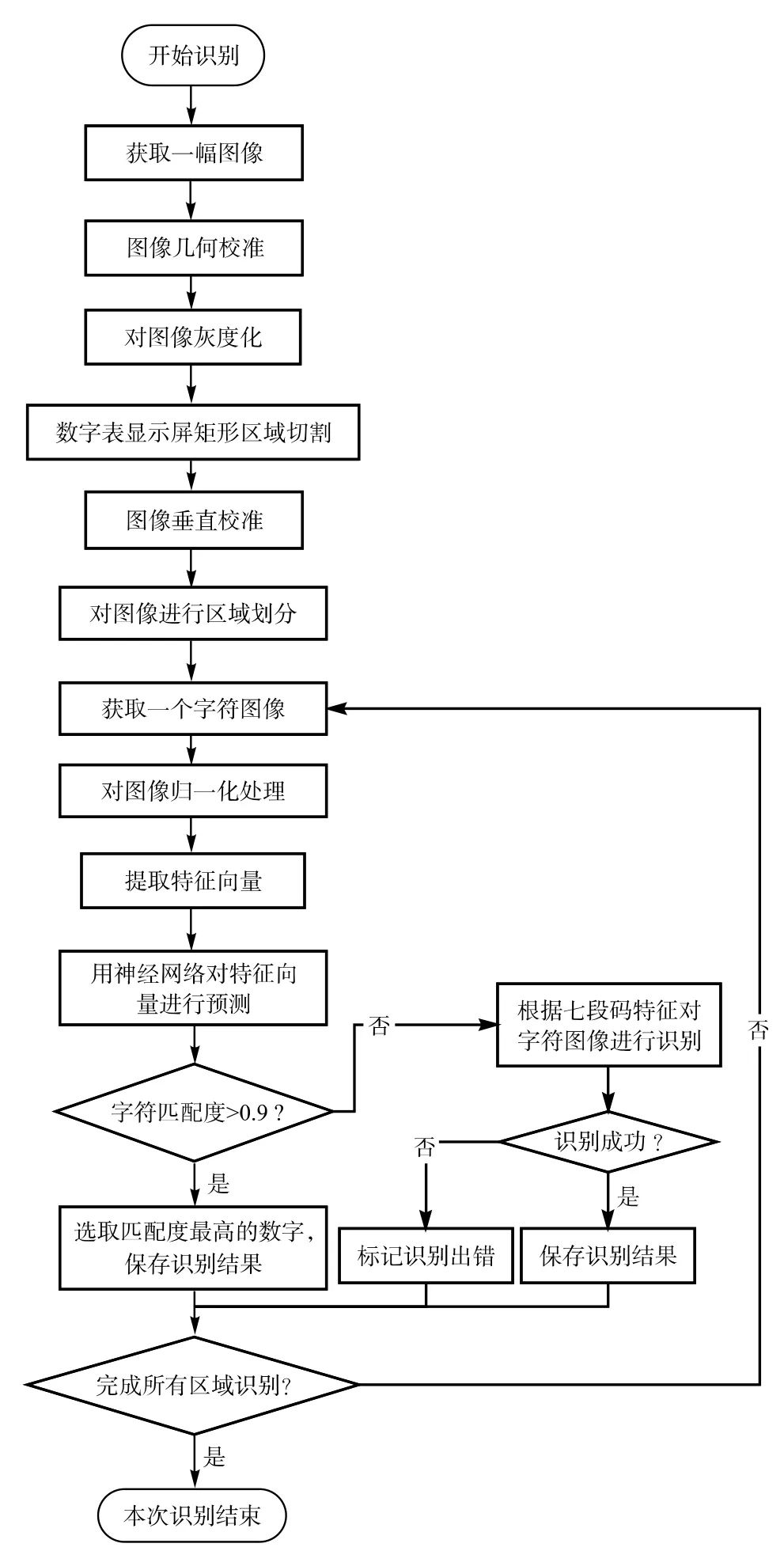
图8 图像识别流程图
3 测试结果
本文研究内容已在无通信口数字多用表泛用型智能化计量辅助装置中得以应用。该套装置是以计算机为控制和操作中心,利用标准多功能源作为程控信号输出,经过网络摄像机采集数字多用表的测量值后,通过计算机对采集到的图像信息进行处理与识别,得到实测数值(图9)。网络摄像机和图像处理系统就是前文所讲的“听”。在对各类数字多用表显示字符的特征值进行学习后,该套装置的图像识别率可达100%。该套装置使用环境对光照度无特殊要求,一般照度大于10 lx就能正常工作。
通过对手持式数字多用表17B的电压参数进行测试,得到表1数据,并与人工测试数据相比较,两者具有较好的一致性。

图9 系统实物图
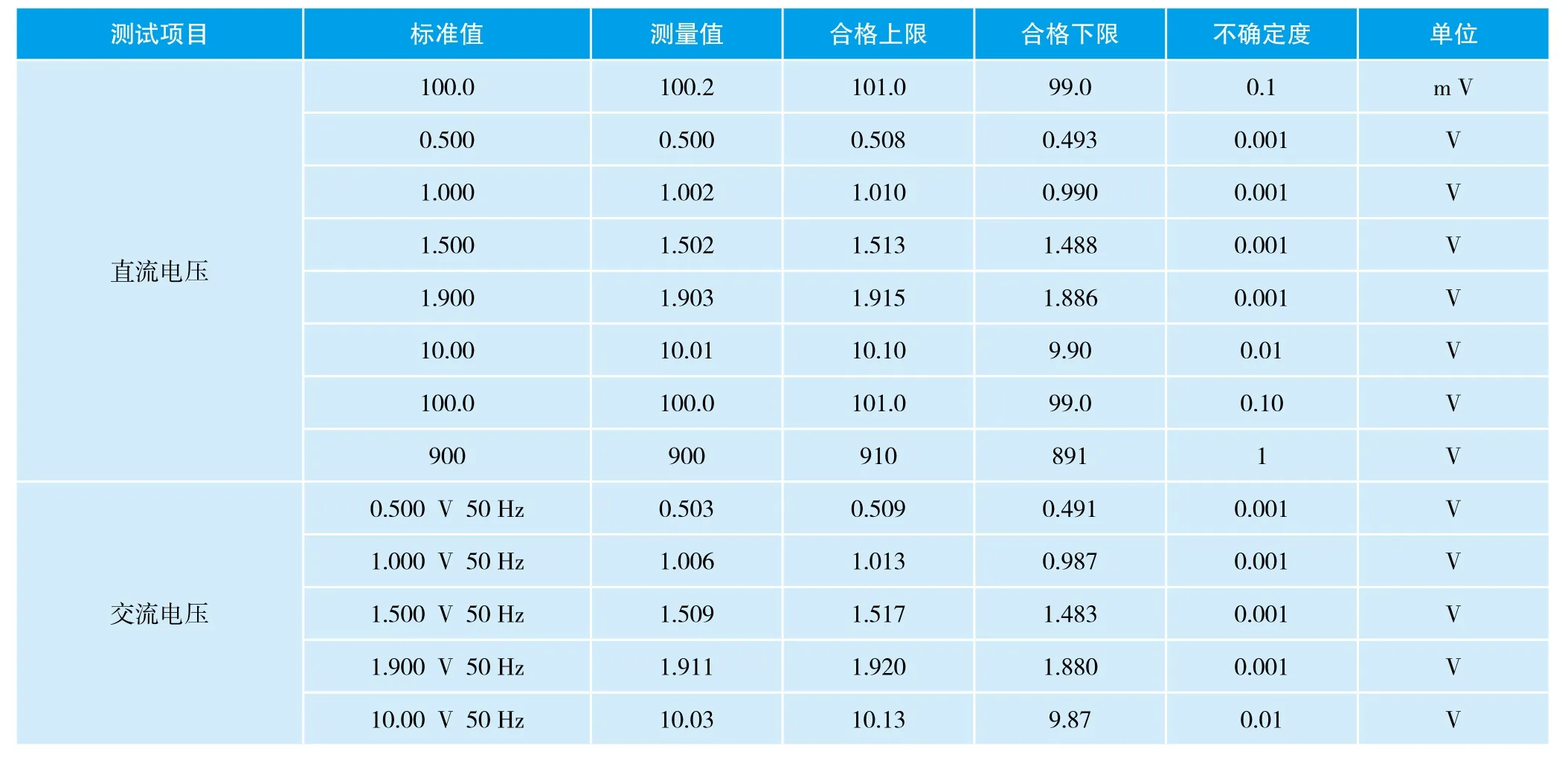
表1 FLUKE17电压参数测试值
4 结语
图像识别技术可以把先前无法自动获取测量数值的障碍得以解决,除了已经能够对手持式或面板式数字仪表开展日常工作的自动校准外,下一步将在此基础上对指针式仪表和远距离测试进行深入的探索。
[1] 白福忠. 视觉测量技术基础[M]. 北京:电子工业出版社,2013.
[2] Gary Bradski, Adrian Kaehler. 学习OpenCV(中文版) [M]. 北京:清华大学出版社,2009.
[3] 晁越,李中健,黄士飞. OpenCV图像处理编程研究[J]. 电子设计工程,2013,21(10):175-177.
[4] 方玫. OpenCV技术在数字图像处理中的应用[J]. 北京教育学院学报(自然科学版),2011, 6(1): 7-11.
[5] 钟亮平,汪伟. 基于CCD和神经网络的LCD数显字符采集与识别[J]. 现代电子技术,2008(1): 164-165.
Auto acquisition system in portable and digital panel meter based on OpenCV
Wang Jiashu1,2,Jiang Ming2,Li Chen2
(1. Shanghai University;2. Shanghai Institute of Quality Inspection and Technical Research)
For the purpose of accomplishing the character recognition, the following steps are to be taken: First, an image/video sensing device is used to acquire the image in the reading area of a portable and digital panel meter based on OpenCV Computer Vision. After geometry correction, adaptive thresholding and pre-processing of the image, Hough Transform is applied to correct the sloping font before splitting up the image vertically then horizontally to realize the image normalization. At last, train the 12 eigenvalues of the seven-segment code to constitute the neural network to ultimately realize the character recognition.
OpenCV;digital meter;auto acquisition system
* 国家质检总局科技计划项目(2012QK285)
猜你喜欢
军事文摘(2022年10期)2022-06-15
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
数字通信世界(2019年3期)2019-04-19
作文大王·低年级(2019年2期)2019-01-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
