
关系数据库对象级别检索结果相关性排序算法研究
2014-03-13 01:20裴祥喜崔炳德杨洪侠
河北水利电力学院学报 2014年4期
裴祥喜,李 珉,崔炳德,崔 晶,冯 涛,杨洪侠
(1.河北工程技术高等专科学校,河北 沧州 061001;2.沧州市产权交易中心,河北 沧州 061001)
近年来,由于关系数据库关键词检索可以大大提高关系数据库的易用性,从而引起了国内外专家学者的密切关注。然而关系数据库与网络不同,其有自身独特的结构特点,因此实现关系数据库关键词检索还有一定的难度。本文重点针对关系数据库元组检索、对象构建以及相关性评估等,对相关性排序算法的实现进行了简要说明。
1 关系数据库分析
关系数据库是一种应用数学集合概念的数据库模型,并且用集合的方法来处理数据库中的数据。从构成结构上看,可以将关系数据库看成是一个具备描述性功能的表格,在这个表格中每一列代表一种数据种类,而每一行则包含着这类数据的唯一实体,总结起来关系数据库就是由数据实体集合而构成的一个应用领域。与网络相比关系数据库有其独特之处:
(1)关系数据库中由数据实体组成的元组之间存在一定关系。
(2)数据库中的文本少则是一个单词、数字,多则是一句短语,与网络文本相比关系数据库中的文本多是短文本。由于短文本中单词或者数据出现频率很低,因此这种短文本并不适合关键词频率检索,增加了关系数据库信息检索的难度。
(3)关系数据库中的数据属性值之间隐藏有一定传递关系,同时数据属性值的大小在很大程度上影响着相关性排序。
从以上分析中可以看出,依靠文本关键词出现频率对关系数据库进行检索是不现实的,因此借鉴短文本的分类方法对关系数据数据库中短文本进行相关性排序,然后按照相关性的大小依照检索要求选择想要的文本。这种思路便是关系数据库关键词检索的核心思路,同时也是数据库领域研究研究的热点。然而,实现这一思路的关键在于设计一套适合关系数据库特点的信息检索相关性排序算法。
2 信息检索的相关性排序
信息检索是指通过一定的方法在指定数据库或者其他数据集合中找出符合用户要求数据资料的过程。通常情况下进行信息检索的方法是关键词检索,但是在实际中这种检索方法并不精确且经常出现疏漏,如何提高信息检索方法的精确性一直都是相关研究学者关注的重点。
然而在实际信息检索过程中只能找到与用户要求文档相关的资料,并且这些资料有很多,为确保资料能够最大限度接近用户要求,还需要对所检索出的相关文档进行相关性排序,优先将相关度最高的文档提供给用户。这里便涉及到相关性排序计算模型。
2.1 概率计算模型
计算一个关键词在相关文档和不相关文档中出现的概率,对该词的权重进行估计,然后依据关键词权重对文档与查询相关的概率进行计算,最终对查询文档进行相关性排序。概率计算模型是基于二元值与检索词独立的假设,因而具有比较理想的调整权值,但这种模型没有考虑采用查询式扩展、没有考虑到文档词频特性,同时也忽略了上次查询对检索词概率的影响,因此该模型在实际中的应用效果并不好。
2.2 向量空间模型
分别将文档中的词语以及查询结果看成是一个向量,这样对文档词语向量与查询结果向量进行相关度分析,从而对查询结果进行相关性排序。向量空间模型是一种经典的相关性排序算法,并且其原理简单,直观易懂,容易掌握,然而该模型难以确定标引词权值,并且需要计算大量相似度,导致系统运行速度受到影响。
2.3 链接分析计算模型
链接分析是互联网搜索依赖的重要计算模型,其理论依据是根据某一网页被其它网页所重视的程度来对查询网页进行相关性排序。这种计算模型基于一个普遍的观点:B网页的超链接指向了A网页,那么就认为B网页投了A网页一票,即B网页认为A网页比较重要。这种计算模型采用的算法主要是Page Rank算法。
3 对象级别关系数据库信息检索的相关性排序算法研究
3.1 关系数库信息检索相关性排序算法
随着社会科技的发展,关系数据库信息检索相关性排序方面出现了一系列包括BANKS算法、RETLINE算法、Object Su mmary算法等在内的排序算法,极大的推动了关系数据库的应用普及。虽然这些算法只能进行元组级别关系数据库信息检索相关性排序,但是研究这些算法对研究对象级别数据库相关性排序算法有积极的借鉴意义。在这些关系数据信息检索相关性排序算法中,尤其以BANKS算法最为经典,再加上该算法结果更符合用户要求,下面以BANKS算法为例进行简单分析。
BANKS算法是一种典型的元组级相关性排序算法,用户通过算法利用关键词对关系数据库进行检索而不需要掌握关系数据库知识以及相关查询语句。这种算法的工作原理是:将元组看成一个个结点,通过对结点属性值的分析查看结点是否符合搜索要求。若结点符合要求便将结点提取出来,由于提取包含关键词的结点有很多,因此检索结果就是众多结点组成的集合。此时为使结果更加符合用户要求,还需要对所提取的结点进行相关性排序。
3.2 对象级别的关系数据库信息检索相关性排序方法
3.2.1 关系数据库对象的构建
对象级别的数据库检索要比元组级别的数据检索更加详细精确,因为元组级别的数据检索结果只是一个个单独的包含关键词的元组,元组之间的关系并没有得到体现,从而导致信息过于分散,一些信息出现丢失,因此搜索结果的准确性得不到保障。
进行对象构建的目的就是将各元组中的分散信息进行整合,以对象为单位进行数据搜索,从而使得关系数据库的信息检索更加符合其自身的结构化特点。
在进行对象构建时,首先要做的是统计包含关键词的元组所在的数据表,其次将数据表通过数据库主外键联系起来,从而明确数据表以及元组之间的关系,最后得到与搜索目标相关的对象。
3.2.2 构建对象规模以及重要性分析
通过对对象级别数据库的分析发现,对象规模以及重要性在很大程度上影响着检索结构相关性排序结果,因此有必要分析数据库对象的规模与重要性。由于元组的规模以及重要性是影响对象规模和重要性的关键因素,因此需要对元组数量规模以及结点间边重要性进行计算。
(1)元组数量规模的计算。在对象级别的数据库检索中元组数量规模会直接影响到对象规模。通常情况下元组规模越大对象规模越大,对象包含的信息越多,搜索结构也就越准确。但是,元组规模过大会造成对象中包含过多无用信息,从而干扰搜索结果的准确性。因此相关性排序方法在计算元组数量规模时要将其控制在合适的范围内,计算公式为:

式中:nmax为最大规模的对象中包含的元组数量。
(2)元组结点重要性的计算。对象级别数据检索相关排序算法更加注重分析相关元组内部属性之间的关系,从而对元组结点的重要性进行重新计算。这样计算重要性的方式可以避免因不含关键词而遗漏的与搜索目标相关的元组,从而提高搜索结果的准确性。元组结点重要性的计算主要集中以下几个方面:评估相关元组内部属性值与关键词的联系,而不是只注重元组之间的关系分析,并且通过分析可以推断出元组内部属性值之间存在的传递关系。该算法不但评估属性值与关键词的相关性,而且还评估两者之间的相似性,从而使搜索结果更加精确;通过信息熵分配元组属性权值,从而计算出相关性最高以及相关性最低的元组属性值。
(3)元组间边计算。由于对象是由元组通过相关关系连接而成的,而元组之间的关系可以被看做是元组之间的有向边,因此在计算对象的重要性时不能忽略元组间边的重要性分析。在分析元组间边重要性时,该算法主要集中计算分析间边的类型数量、间边方向以及间边两端的结点等。
通过以上三点的分析可以总结出计算对象重要性的总公式:
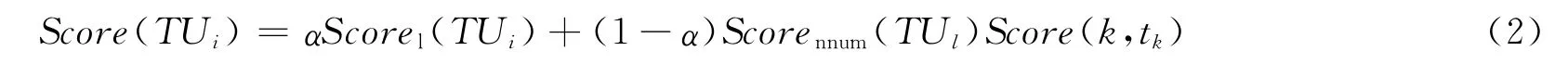
式中:α作为调节因子负责控制元组与间边的相对重要性。
4 结语
对象级别关系数据库信息检索相关排序算法的研究是现阶段数据库信息检索研究的重点,受到众多研究学者的关注并且取得了一定成就。本文率先对关系数据库的定义、结构特点以及信息检索的相关排序进行了详细分析,然后在此基础上对对象级关系数据库信息检索相关排序算法进行了系统研究,为排序算法的实现提供了理论参考。
[1] 张俊,邵仁俊,曾一鸣.对象级别的关系数据库信息检索技术研究[J].计算机科学,2012,39(1):142-145.
[2] 邓承刚,张俊,刘宁.基于属性值分布的关系数据库对象级别检索结果排序算法[J].计算机科学,2013,40(3):219-223.
[3] 邵仁俊,张俊,曾一鸣.DBORank:对象级别的关系数据库信息检索方法[J].计算机科学与探索,2012,6(8):742-744.
猜你喜欢
山东冶金(2022年2期)2022-08-08
电脑报(2021年14期)2021-06-28
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
河北大学学报(自然科学版)(2015年1期)2015-02-27
电信科学(2013年10期)2013-08-10
江西理工大学学报(2013年1期)2013-03-20
