
PLS-DA模型四种诊断统计量在代谢组学应用中的比较*
2014-03-10 05:25:16哈尔滨医科大学卫生统计学教研室150086柯朝甫武晓岩
中国卫生统计 2014年3期
哈尔滨医科大学卫生统计学教研室(150086) 柯朝甫 武晓岩 李 康
PLS-DA模型四种诊断统计量在代谢组学应用中的比较*
哈尔滨医科大学卫生统计学教研室(150086) 柯朝甫 武晓岩 李 康Δ
目的比较PLS-DA模型四种诊断统计量在代谢组学数据分析中的检验效能和稳定性。方法采用双重交叉验证和置换检验的PLS-DA模型验证策略,并分别使用四种诊断统计量对模拟数据和实际数据进行分析。结果AUC统计量较误判数(率)、Q2和DQ2统计量具有更高的检验效能;同时,AUC统计量与其他三种诊断统计量相比较,具有更高的稳定性。结论AUC统计量是PLS-DA模型验证过程中一种稳定有效的诊断统计量,推荐作为代谢组学研究中进行PLS-DA分析时的首选诊断统计量。
PLS-DA 代谢组学 诊断统计量 双重交叉验证 置换检验
近年来,偏最小二乘判别分析(PLS-DA)在高维组学数据分析中应用十分普遍,特别在代谢组学领域,已成为一种常用的数据分析方法[1-2]。PLS-DA是一种集合了主成分分析、典型相关分析和多元线性回归特点的数据分析方法,与主成分分析相同的是都试图提取出反映数据变异的最大信息,但主成分分析法只考虑自变量矩阵,而偏最小二乘法还需要同时考虑应变量(通常有病编码为1,无病编码为0),即通过自变量数据之间的协方差及与应变量之间的协方差构建正交得分向量(潜变量或主成分)[3]。在建立PLS-DA模型时,需要事先指定用于建模的主成分,不同的主成分数对应着不同的PLS-DA模型,一般按照一定的准则选取前面几个主成分建立PLS-DA模型。
然而,作为一种判别分析方法,PLS-DA在处理高维(如m>1000)、小样本(n<100)的组学数据时很容易产生过拟合现象,实际中为了判断是否产生过拟合可以采用交叉验证、置换检验等方法对模型进行诊断。目前最常用的诊断统计量有误判数(误判率)、受试者工作特征曲线下面积(AUC)、Q2及DQ2[4],这四种诊断统计量在应用上存在一定的差异。本文在简要介绍这四种诊断统计量的基础上,结合模拟实验和实例分析,为如何选择诊断统计量提供一定的依据。
四种诊断统计量
模型验证的最好方法是采用前瞻性外部验证,但在实际中由于样本量不足,验证模型的有效性通常采用交叉验证方法(如5~7折交叉验证),即将整个数据集分为训练数据和测试数据两部分,使用训练数据建立基于一定主成分数的PLS-DA模型并对测试数据预测,这种形式的交叉验证称之为简单交叉验证。但是,建立PLS-DA模型时如果主观选择主成分数,容易产生过拟合现象。为此,针对PLS-DA模型,Westerhuis等提出使用双重交叉验证的方法[5],即将整个数据集随机分为三部分,包括训练数据、验证数据和测试数据,使用训练数据和验证数据建立模型并优化模型参数,然后使用测试数据进行预测。双重交叉验证在建模选择主成分时,通过内嵌在建模数据中的验证数据确定,避免了过拟合的问题。模型评价可以采用下述四种统计量。
1.误判数
通过PLS-DA模型分析,可以获得每个样品的预测类别,通过与真实类别相比较结果分别为真阳性、假阳性、真阴性和假阴性四种结果,误判数为假阳性数目与假阴性数目之和,由此可以算出误判率。在样本例数一定的情况下,误判数直接反映了PLS-DA模型误判的样品例数,简单直观。
2.受试者工作特征曲线下面积
使用PLS-DA模型进行分析,可以得到二分类应变量的偏最小二乘回归结果,并可以根据交叉验证的测试数据计算出受试者工作特征曲线下面积(AUC)[6]。这是一种把灵敏度和特异度结合起来综合评价预测准确度的一种方法,当AUC>0.5时,其值越接近1,说明两组的可区分度越高;同理,当AUC<0.5时,AUC越接近0,说明两组的可区分度越高;当AUC=0.5时,说明两组完全不可区分。
3.Q2统计量
Q2是目前代谢组学研究中应用最多的一种诊断统计量,用来衡量PLS-DA模型的预测效果,是代谢组学中使用最多的诊断统计量,其定义为
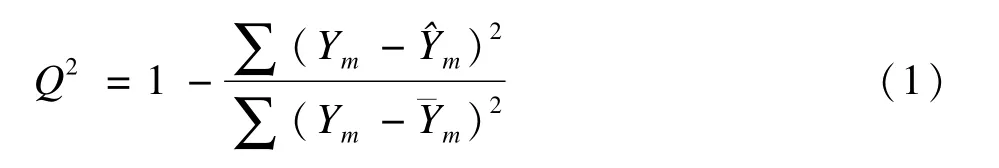
其中Ym为每个样品的真实标签,m为通过交叉验证得到的每个样品的预测值,m为所有样品的平均值为预测残差平方和,它定量地衡量了样品预测值偏离真实标签的程度[7]。Q2的意义和线性回归分析中的决定系数R2相似,区别在于后者反映的是模型的拟合效果,而Q2则通过交叉验证的测试数据计算得到,描述的是模型的预测能力。Q2的取值可以是负值(-∞<Q2≤1),其值越接近1说明模型的预测效果越好,如果其值为负值则表示预测能力差或完全没有预测能力。
4.DQ2统计量
由于PLS-DA是一个线性判别模型,在两组数据情况下(有病=1,正常=0),每个样品的预测值m取值范围并非为[0,1],有可能超出这一范围,这时无论预测是否准确,都会增加预测残差。例如,一个样品的原始标签是1,PLS-DA模型的预测值为2,虽然预测非常准确,但是同样会增加预测残差值使Q2减小。为此,Westerhuis等提出使用DQ2统计量解决这种不合理的现象[8]。
DQ2是对Q2的改进,即当预测值在原始标签的同方向范围以外,则将该样品对残差的贡献视作0,具体定义为

这样,当原始标签为1而PLS-DA模型预测值为2时,该次预测对PRESSD的贡献为0,DQ2值不会因为正确的预测而受到惩罚。由此可见,DQ2更加符合真实预测情况。
模拟实验
实验目的:在接近真实代谢组数据结构和样本量时,比较四种诊断统计量在不同总体参数设置条件下的估计值及标准差,并考核其置换检验的效能。
模拟方法:模拟产生样本量为45的A、B两组数据,变量个数为8,其中A组中各变量服从N(0,1)的正态分布,B组中各变量服从N(μd,1)的正态分布,任意两变量间的相关系数设为ρ=0.5。为了保持代谢组学的实际数据结构,取90例正常人血浆样本得到代谢组学数据Z=(Z1,Z2,…,Z535),并将其随机等分为两组(n1=n2=45),与上面模拟产生的A、B两组差异变量数据合并(图1)。为了模拟病例组数据和对照组数据之间不同程度的差异,每次产生A、B两组数据时分别按照μd=0,0.2,0.4,0.6,…2.0进行设置,合计共产生11次不同差异的模拟数据。
按照上述方法,根据不同的μd取值每种情况模拟1000次,拟合PLS-DA模型,并使用7折双重交叉验证,计算四种诊断统计量的均数及标准差。四种统计量的假设检验采用置换检验方法,原假设H0的统计量分布通过模拟数据和真实数据不断打乱标签形成。
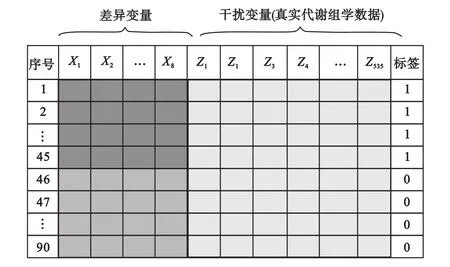
图1 模拟实验数据结构示意图
模拟结果:随着类别间差异的增大,整体上模型分类效果变好。从表1看出:①当8个差异变量的均值相差为1.0时,AUC值已达0.7128,但Q2和DQ2此时分别为0.0206和0.0362;②在差别较小时(μd<1),Q2和DQ2为负值;③当AUC值较大(如大于0.85)时,Q2和DQ2亦显示出较高的判别效果。
图2给出了检验效能结果。结果显示,当一类错误α控制在0.05时,并且在组间差异较小的情况下(μd<1.4),AUC的检验效能最高,其次为误判数(率),DQ2和Q2的检验效能最低。另外,当一类错误α控制在0.01时,AUC在组间具有一定差异情况下(如μd<1.6)的检验效能显著高于另外三个统计量,而误判数(率)则与Q2和DQ2相当。当两组间的差异足够大时(如μd=1.6),AUC、误判数、Q2和DQ2的检验效能在两种情况下均趋近于1。综上所述,AUC与误判数、Q2、DQ2相比较,能够发现微小的组间差异,具有更高的检验效能。
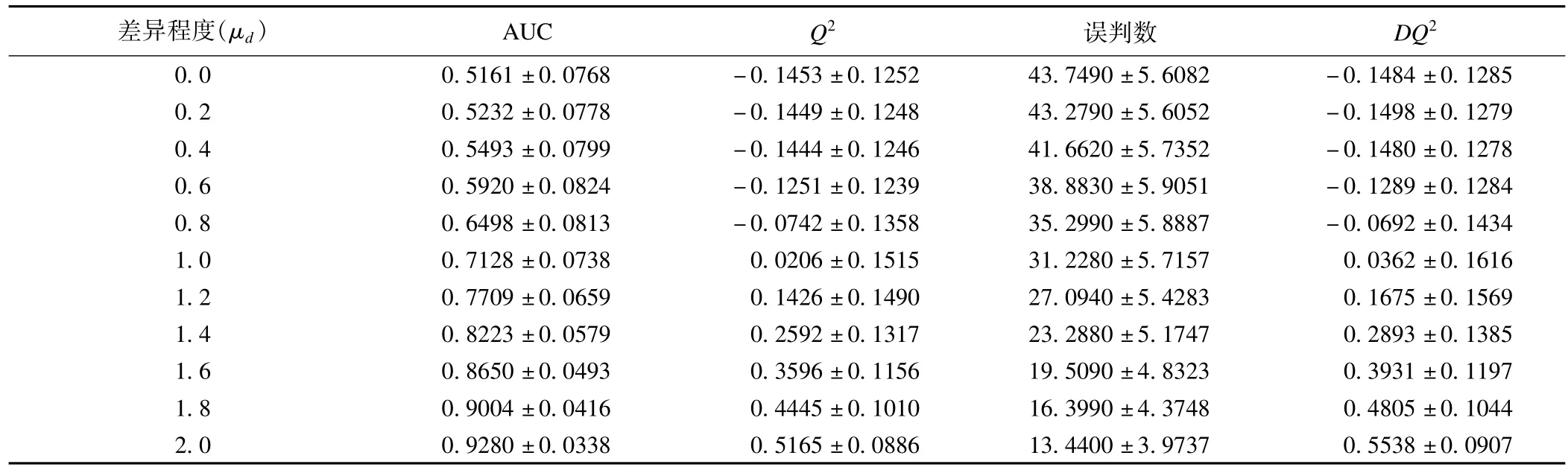
表1 模拟1000次不同组间差异时PLS-DA模型的分类效果(均数±标准差)
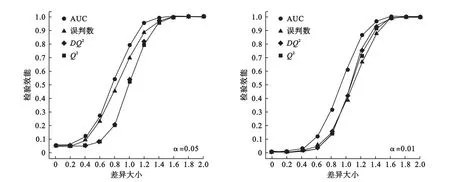
图2 四种PLS-DA诊断统计量在两种不同检验水准时检验效能比较
实例验证
2009年9月至2010年5月期间在哈医大附属肿瘤医院收集了50例卵巢癌患者血浆样本、50例卵巢良性肿瘤血浆样本,经过UPLC-MS-Q-TOF仪器检测分析和预处理后得到535个变量。
对卵巢癌和卵巢良性肿瘤代谢组学数据进行2000次7折PLS-DA双重交叉验证,然后计算四种诊断统计量的各种统计描述指标如均数、标准差等,结果见表2。由表2可见,AUC的均值达到0.8564,Q2和DQ2值都在0.32以上,说明卵巢癌患者与卵巢良性肿瘤患者的血浆代谢轮廓存在较大差异。根据上面的模拟实验可知,当AUC=0.8223(μd=1.4)时,按照α=0.05检验水准,四种诊断统计量的检验效能将均接近1。该实例通过置换检验给出四种诊断统计量的P值,经过2000次置换检验,四种统计量的绝大多数P值小于0.0005,其中AUC统计量均有P<0.0005,另外三种统计量均有P<0.05,说明卵巢癌患者与卵巢良性肿瘤患者的血浆代谢轮廓之间的差异是具有统计学意义的。
为了进一步对四种诊断统计量的稳定性能进行比较,计算2000次7折PLS-DA双重交叉验证后所得四种诊断统计量的变异系数。从图3可以看出,AUC的变异系数明显小于其余三种诊断统计量,说明AUC比其余三个诊断统计量更为稳定。为了更加全面客观地考察四种诊断统计量的变异性,我们基于前20个主成分数依次进行2000次7折PLS-DA简单交叉验证,并计算相应的四种诊断统计量的变异系数(图4)。结果显示,AUC的变异系数均最小,误判数的变异系数略高,而Q2和DQ2在利用前面几个主成分建模时其变异性尚可,而当主成分数大于10时,其变异系数明显增大,Q2的稳定性最差。综上所述,AUC在四个诊断统计量中最为稳定,其他依次为误判数、DQ2和Q2。

表2 2000次双重交叉验证中四种诊断统计量分布的统计描述指标
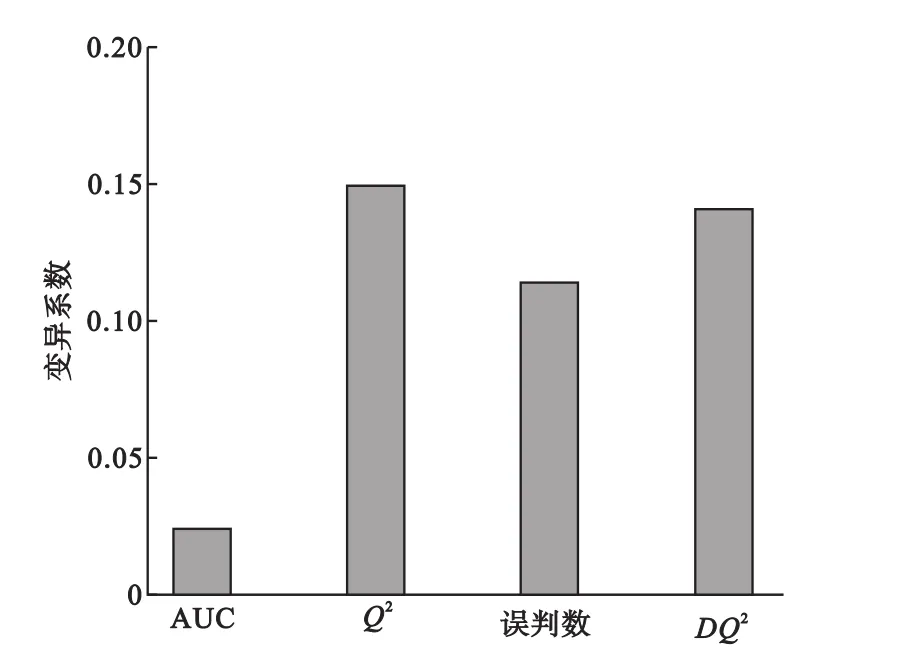
图3 2000次双重交叉验证中四种诊断统计量的变异系数
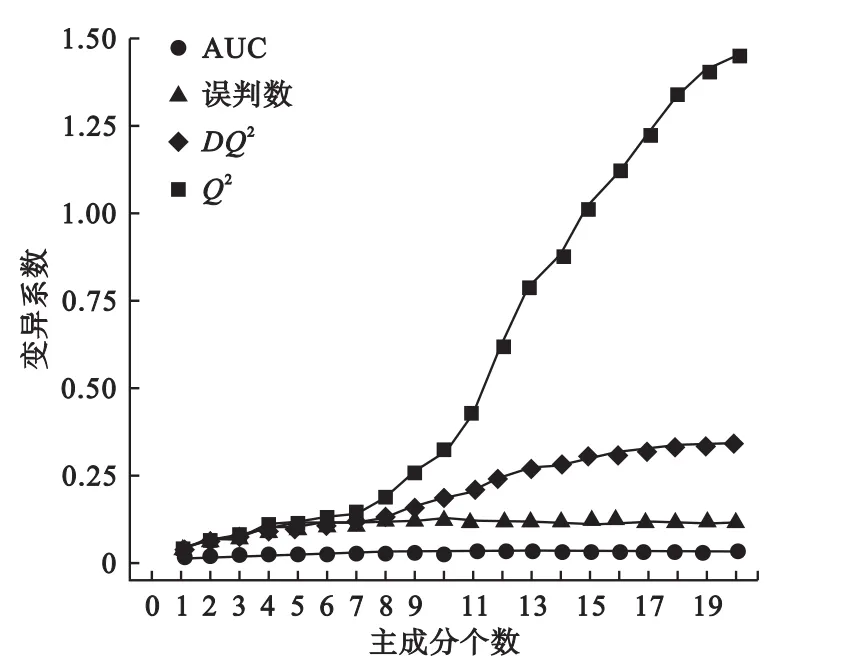
图4 2000次简单交叉验证中四种诊断统计量的变异系数
讨 论
AUC、误判数、Q2和DQ2是PLS-DA模型在代谢组学应用中最常用的四种诊断统计量,但如何选用存在一定争议。这四种诊断统计量的特点是,既可以用来衡量两组的分类效果,同时可以通过置换检验的方法做假设检验。另一重要问题,目前计算这些统计量采用的是简单交叉验证方法,通常由主观确定主成分数,容易出现过拟合现象,因此本文推荐使用双重交叉验证方法,即主成分数通过内嵌在建模数据中的验证数据确定,可以使检验结果更加可信。代谢组学研究中,生物样品之间的变异性较大,而各种生物状态之间的差异和相互关系复杂,寻找一种检验效能高而又稳定的诊断统计量具有重要的现实意义。本文通过模拟实验和实例验证的方法对四种诊断统计量在PLS-DA模型验证过程中的检验效能和稳定性进行了研究和比较。结果显示,在检验效能方面,AUC比误判数、Q2和DQ2更容易发现较小的差异,这与Westerhuis等近期的研究结论是一致的[4]。此外,AUC统计量比其他三个诊断统计量具有更高的稳定性。综上所述,AUC是PLS-DA模型验证过程中一种稳定有效的诊断统计量,可作为代谢组学研究中进行PLS-DA分析时的首选诊断统计量。本研究中的双重交叉验证计算程序用R语言编写。
1.Bryan K,Brennan L,Cunningham P.MetaFIND:a feature analysis tool formetabolomics data.BMC Bioinformatics,2008,9(1):470-482.
2.Zhang T,Wu XY,Ke CF,etal.Identification of Potential Biomarkers for Ovarian Cancer by Urinary Metabolomic Profiling.J Proteome Res,2013,12(1):505-516.
3.蒋红卫,夏结来,李园,等.偏最小二乘判别分析在基因微阵列分型中的应用.中国卫生统计,2007,24(4):372-374.
4.Szymanska E,Saccenti E,Smilde AK,et al.Double-check:validation of diagnostic statistics for PLS-DA models in metabolomics studies.Metabolomics,2012,8(Suppl1):3-16.
5.Westerhuis JA,Hoefsloot HCJ,Smit S,etal.Assessmentof PLSDA cross validation.Metabolomics,2008,4(1):81-89.
6.李康,林一帆.评价判别模型诊断效果的AUC分析.中国卫生统计,1996,13(3):9-12.
7.Cruciani G,Baroni M,Clementi S,et al.Predictive ability of regression models.Part I:Standard-deviation of prediction errors(SDEP).Journal of Chemometrics,1992,6(6):335-346.
8.Westerhuis JA,van Velzen EJJ,Hoefsloot HCJ,et al.Discrim inant Q2(DQ2)for improved discrim ination in PLSDA models.Metabolom ics,2008,4(4):293-296.
(责任编辑:郭海强)
A Com parative Analysis of Four PLS-DA Diagnostic Statistics in the Application of M etabolom ics
Ke Chaofu,Wu Xiaoyan,Li Kang(DepartmentofBiostatistics,HarbinMedicalUniversity(150086),Harbin)
ObjectiveTo compare the statistical power and stability of four PLS-DA diagnostic statistics in the analysis ofmetabolomic data.MethodsThe simulated data and realistic data were analyzed based on the PLS-DA validation strategy of double cross validation and permutation test in conjunction w ith four diagnostic statistics.ResultsAUC showed higher statistical power than misclassification number(rate),Q2andDQ2;in themeanwhile,AUC wasmore stable than the other diagnostic statistics.ConclusionAUC is a stable and effective diagnostic statistic in the validation of PLS-DA models,and is recommended as the preferred diagnostic statistic in the PLS-DA analysis ofmetabolomic studies.
PLS-DA;Metabolom ics;Diagnostic statistic;Double cross validation;Permutation test
*国家支撑项目资助(2011BAI09B02);国家自然科学基金(81172767)
Δ通信作者:李康,likang@ems.hrbmu.edu.cn
猜你喜欢
作文小学高年级(2023年6期)2023-07-14 11:13:38
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
中国外汇(2019年7期)2019-07-13 05:44:56
国际口腔医学杂志(2019年3期)2019-05-31 10:09:26
天然产物研究与开发(2018年2期)2018-04-04 02:01:12
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
计算机工程(2015年8期)2015-07-03 12:19:54
医学研究杂志(2015年11期)2015-06-10 06:44:03
发明与创新(2015年1期)2015-02-27 10:38:26
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
