
一种云环境下的镜像文件存储系统*
2014-02-28 06:16:34王洪发
电信科学 2014年2期
王洪发
(浙江水利水电学院计算机与信息工程系 杭州310018)
1 引言
云计算的本质是按需提供服务给组织或个人[1]。云服务提供商采用的服务方式通常是以虚拟机形式动态分配计算资源给用户使用,例如Amazon Elastic Compute Cloud、OpenStack、Eucalyptus、Nimbus和OpenNebula。然而,随着在一个云池中的虚拟机数量增多,它会引起以下两个问题[2,3]。
·因为虚拟机镜像难以被共享或移动,一台虚拟机很难在不同主机上运行。
·用户的虚拟机镜像和数据是不安全的,因为它们不是分开存储,并且缺乏容灾性和恢复机制。
因此,设计一个虚拟机镜像文件存储系统是非常必要的,更重要地是镜像文件存储系统能够为用户提供可伸缩、高性能、低成本的数据存储池。
目前,在云计算数据中心有3种模式的镜像存储:本地存储、集中共享存储和网络存储。本地存储是最便捷的,但是容量有限,并且镜像文件不能在不同主机之间共享,使得虚拟机迁移变得很困难。集中共享存储能提供优秀的I/O性能和容易的虚拟机迁移,例如使用光纤或Infiniband[4]连接主机和磁盘阵列,但是集中共享存储非常昂贵并且可扩展性不好。网络存储是由许多廉价的存储设备组成,它们之间通过TCP/IP以太网连接,并且使用分布式文件系统或并行文件系统。
在本文中,笔者设计并实现了一个基于Lustre[5]的分布式镜像文件存储系统——IFSpool(image file store pool)。开源实现的Lustre能够提供高I/O性能和优秀的可扩展性和可靠性,并且被成功部署在商业应用环境,而笔者所做的主要工作是在主机服务器和Lustre之间添加存储适配模块。利用IFSpool中紧密的结合队列和缓存机制以及通过协调数据访问顺序来提高I/O吞吐率和减轻启动风暴。实验结果表明IFSpool能有效地满足镜像文件存储的需求。
2 镜像文件存储的需求
传统上,云服务提供商提供3类服务模式[6,7]:基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。
在IaaS模式中,云服务提供商提供虚拟机、存储、网络等服务。在PaaS模式中,云服务提供商提供计算平台和解决方案。通常包括操作系统、编程语言执行环境、数据库和Web服务器。应用程序开发人员无需购买和管理底层硬件和软件层,即可在云平台上开发和运行他们的软件解决方案。在SaaS模式中,云服务提供商提供应用软件服务,云用户通过网络、虚拟桌面或移动终端访问应用软件。
然而,随着在云资源池中虚拟机数量的快速增加,很多问题出现在存储领域,如容量不足、数据安全、吞吐量限制和启动风暴。
Meyer D等[8]提供了一个精心设计的单一存储服务。在这个设计中,存储虚拟机和通用虚拟机被部署在每一个应用程序节点。存储服务遵循POSIX I/O接口,由虚拟化提供的封装,通用虚拟机可以访问不同的存储服务和使用本地磁盘。对于一个小型虚拟机集群,这种存储系统能在共享存储设备和廉价商用本地磁盘上表现出良好的性能,然而,当虚拟机数量超过单个的存储容量时,它甚至不能满足正常的虚拟机I/O存取操作,此外,它不允许用户之间合作共享。
LiaoX F等[9]设计了一个分布式的存储系统VM Store。VM Store采用直接块索引结构来做虚拟机快照,能显著改善虚拟机的启动性能,并通过动态更改存储节点的数量,提供分布式存储的可伸缩性I/O带宽。VM Store还提出了一种智能对象的分区技术的数据预处理策略,这将更有效地消除重复数据,然而,实验结果表明VM Store不适合大规模的VM镜像存储。
Dickens P M和Logan J[10]提出一种新的数据再分配模型,采用“多对多”通信模型能够有效地减少OST(对象存储目标)存储资源的竞争访问,缺点是降低了I/O并行性。
Casale G等[11]提出一种简单性能模型来预测虚拟化应用程序的存储I/O性能整合的影响,并且还定义了对吞吐量、响应时间和混合的读/写请求的简单线性预测模型,但是预测模型的信息来源仅仅基于个人虚拟机隔离实验的信息收集。
为了减轻启动风暴问题,一些虚拟机系统部署在SAN或其他昂贵的存储阵列上,例如VMFS[12]。然而,随着用户的增多,即使使用先进的存储系统降低启动风暴的发生率,系统升级还是变得很困难而且代价也很高。
因此,有必要建立一个专有的镜像文件存储系统。设计这样一个镜像文件存储系统需要考虑3个基本问题。
(1)高I/O吞吐量和高可扩展性
在共享存储中,虚拟机共享同一个物理存储池。当虚拟机总访问负载变得更高时,对I/O访问的竞争量将影响虚拟机的性能。在这种情况下,镜像文件存储必须有高的I/O吞吐量。此外,为存储和管理成千上万的虚拟机镜像,镜像存储池可以在不打断任何操作的前提下通过添加新的存储设备增加容量。
(2)启动优化
在云计算环境中,每个虚拟机将从数据中心主机或共享存储本地文件系统中读取引导信息。在参考文献[9]中,提到在应用程序节点上启动一个虚拟机至少需要10 Mbit/s的I/O带宽,在企业中成百上千台虚拟机并发启动所需要的总带宽将超过存储服务器能力的几倍。
在大多数情况下,虚拟机被部署在企业环境中为企业员工提供相同的使用环境。员工将在上班开始时启动虚拟机并在下班时关闭虚拟机。因此,虚拟机启动或关闭很大程度上是并发操作。为了解决这个问题,结合队列和缓存机制,并通过协调数据访问顺序提高I/O吞吐率和减轻启动风暴,进一步通过使用固态硬盘(SSD)作为缓存队列的存储介质来提高读写性能。
(3)容灾备份
在云计算环境中,失效是一种常见的事。2010年1月,Ruby-on-Rails应用程序托管公司在Amazon EC2托管的22台虚拟机出现故障。据报道由于这次路由器故障所引起的中断影响了托管在该公司的44 000个应用程序的使用[13]。因此,对于存储和管理成千上万的虚拟机镜像的存储系统,容灾备份是一个重要的考虑因素,包括访问控制、灾难恢复工具和冗余的数据存储。所以,分布式存储系统是一个合适的选择。
3 IFSpool设计和实现
本节将描述专有镜像文件存储系统IFSpool的设计和实现,并给出对提高I/O吞吐量和减轻启动风暴的重要改进内容。
3.1 IFSpool的架构
图1展示了IFSpool的高层体系结构。每个部件的详细讨论如下。
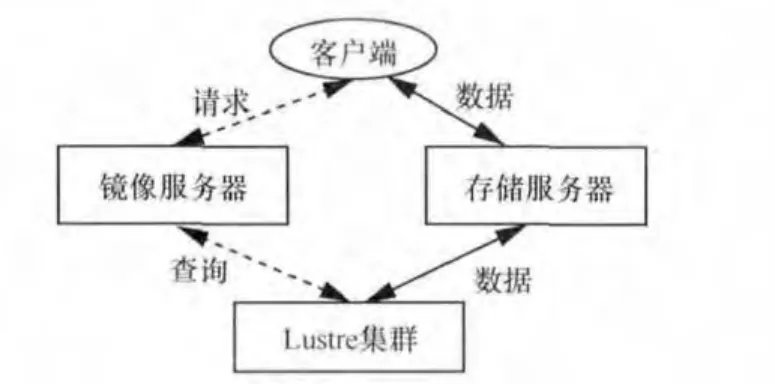
图1 IFSpool体系结构
镜像服务器是客户端与Lustre之间的通信桥梁。镜像服务器提供虚拟机镜像的发现、登记和交付服务。在本文中,采用OpenStack Glance[14]作为IFSpool的镜像服务器。Glance允许上传多种格式的私有和公有的镜像,包括VHD(Hyper-V)、VDI、qcow2(Qemu/KVM)和VMDK(VMware)。
Lustre[5]是一个构建在廉价商用机器上的存储系统。如图2所示,元数据服务器(MDS)存储着每个文件的布局、大小和位置,客户端从MDS获得文件布局,对象存储服务器(OSS)为一个或多个本地对象存储目标(OST)提供文件I/O服务和网络请求处理,OST把文件数据作为数据对象存储在一个或多个OSS上,单个Lustre文件系统通常有多个OSS和OST,为了优化性能,每个文件被分为几个子文件并存储到不同的OST。在Lustre中一个来自客户端的数据访问请求将被分解成几个更小的子请求,然后存储服务器并行访问子请求的数据。
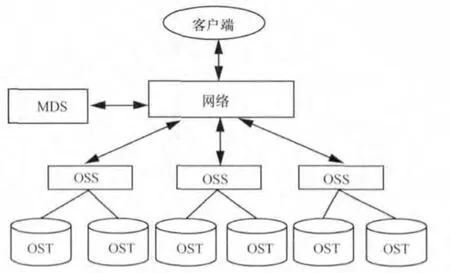
图2 Lustre的体系架构
3.2 存储适配器设计
存储适配器是IFSpool的主要部件,在IFSpool中,客户端也有相对应的部件:元数据客户端(MDC)、对象存储客户端(OSC)和逻辑对象卷(LOV)。MDC是一个客户端接口模块,可以通过它访问MDS。
OSC和OST的关系是一对一的。一组OSC被包装成一个LOV,如图3所示。

图3 Lustre文件系统的文件打开、读取、写入过程
当一个客户端创建、打开或读取一个镜像文件时,它首先获取存储在MDS的元数据信息。在MDS返回镜像文件的位置后,客户端会直接向相关的OST设备发出I/O访问请求。例如,在读取文件之前,客户端将通过MDC向MDS发出查询请求。MDS告诉客户端从
假设有4个虚拟机
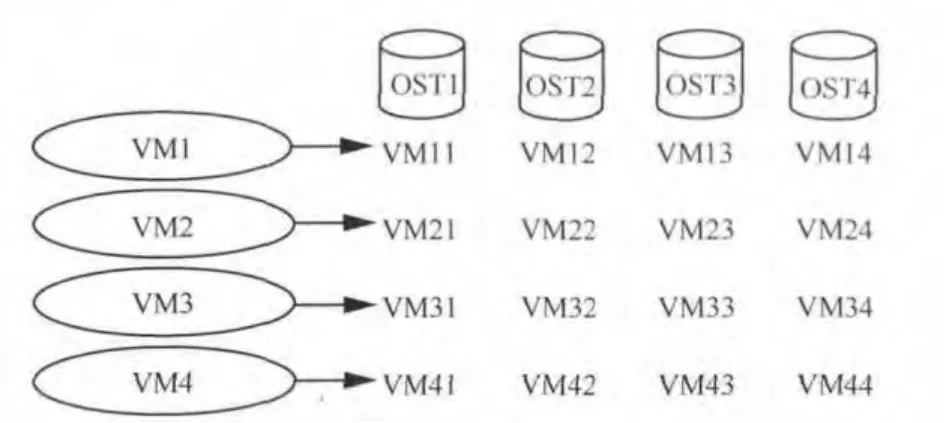
图4 OST的镜像文件视图
假设在某个特定时间这4个虚拟机同时读取镜像文件,这样虚拟机将会同时与每个OST通信,因此会产生相当大的通信开销,而随着虚拟机数量的增加,性能会大幅下降。主要因为虚拟机的随机磁盘访问,而且虚拟机本身也不执行一系列连续的磁盘I/O操作,这将导致随机、无序磁盘查找操作,从而产生额外的磁盘开销和降低了文件访问的并行操作效率。
存储适配器的基本原理是对于每个OST维护一个缓存队列,称为OST队列。这些缓存队列存储于存储适配器服务器上并且维护一个全局散列表,其中散列键也称为OST_ID(每个OST在Lustre集群里有一个对应的身份证号码)。因为适配器服务器的存储介质是SSD,所以缓存队列拥有高速的读写速度。
在IFSpool中,镜像文件是以条带方式存储在几个OST上,并且在OST上一个文件的所有数据被视为一个对象,该对象使用128 bit的标识作为对象ID。与传统的UNIX文件系统不同,MDS的索引节点并不指向数据块,相反它指向一个或多个与对象相关的文件,所以客户端可以通过对象ID并行地读写文件,换句话说,客户机可以通过对象ID直接和OST交换数据。
假设这4个虚拟机同时与这4个OST交换数据。存储适配器首先从虚拟机接收所有数据,然后依据对象ID分派这些数据到相应的OST队列。当已使用空间达到一个阈值时,OST队列中的数据将按序被写回到相应的OST,同样。当从OST上读取数据时,对象首先被分派到相应的OST队列中,然后每个虚拟机依据OST_ID从OST队列取回对象。图5显示了存储适配器模型。
存储适配器的优点是通过结合队列和缓存机制将随机访问变成顺序访问。存储适配器的缓存机制实现是不同于传统的缓存机制,具体地说,存储适配器没有使用替换算法,相反适配器采用有一个阈值来决定什么时候回写数据。对于一个写操作,缓存的功能是将随机写入变成顺序写入,并且把小的数据块合并成大的数据块。对于读操作,依据对象ID将相同的请求合并到一个特定的OST上,读操作的I/O吞吐量可以有效地改善,并且可以以大数据块形式顺序读取这些数据到相应的OST队列上。
存储适配器算法描述如下。
Queue(i)表示存储OST_ID为i的数据对象的队列,队列的范围从0到n-1,n是OST的最大数。存储适配器使用时间片轮转方法为每个队列提供服务。Read_object(p,ost)表示从ost中读取对象p。Insert_object(p,i)表示将数据对象p加入队列i中。Dispatch_object(p,i)表示将队列i中的数据对象p发送到本地驱动程序。
Begin
Writing:on arrival of data object p
Queue(i)=hash(object p);
if(there is nothis object exist in this queue)
{if(no free buffers left Queue(i))
{Queue(i)=must_queue;return-1;}
else{Insert_objcet(p,i);return 1;}}
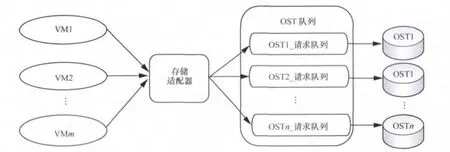
图5 存储适配器模型
return 0;
Reading:on arrival of several object requests
m_Object_ID=merge requests by Object ID;
Read_objcet(m_Objcet_ID,OST_ID);
wait for VMs read.
Dispatch:
While(true)do{
if((threshold value==ture)||(Queue(i)==must))
{if(Queue(i)is not empty)
{get a data object from OST_queue;
Dispatch(p,i);}
else if(there is enough slice left to wait for one requests)
{do{wait for data object p;
Dispatch(p,i);}
While(time slice for Queue(i)is enough)}
else{get next queue for service;}}
End
4 实验结果
4.1 实验环境
计算服务器采用两台联想Think Server TS430 S1280服务 器,Intel Xeon E3-1200 8核处理器,32 GB内存,两块BroadcomNetXtremeⅡ57091Gbit/s以太网卡,6TBSAS6硬盘。
镜像服务器配备一台戴尔电脑,Intel Xeon E7550 4核处理器,8 GB内存,380 GB SATA硬盘。
Lustre集群由4台戴尔电脑组成。每台电脑配置Intel Xeon E7550 4核处理器、4 GB内存、2块500 GB SATA西部数据硬盘。
存储适配服务器配备一台戴尔电脑、一块OCZ Vertex3 60 GB的SSD、一块Highpoint RocketRAID 4320 RAID控制器。
4.2 实验分析
图6和图7分别显示了在使用HDFS、MooseFS、Lustre和IFSpool作为镜像存储池时指定数量的虚拟机平均随机读写速率。从图6和图7看到IFSpool具有更好的I/O吞吐量。Lustre和IFSpool结果进一步确认存储适配器提高了读写速率,这证实了存储适配器能够提高并行数据访问速度和降低通信开销。
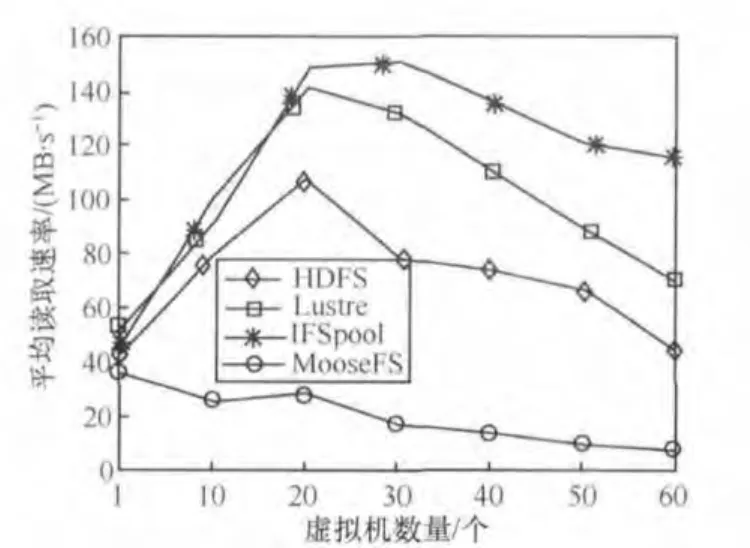
图6 平均读取速率比较
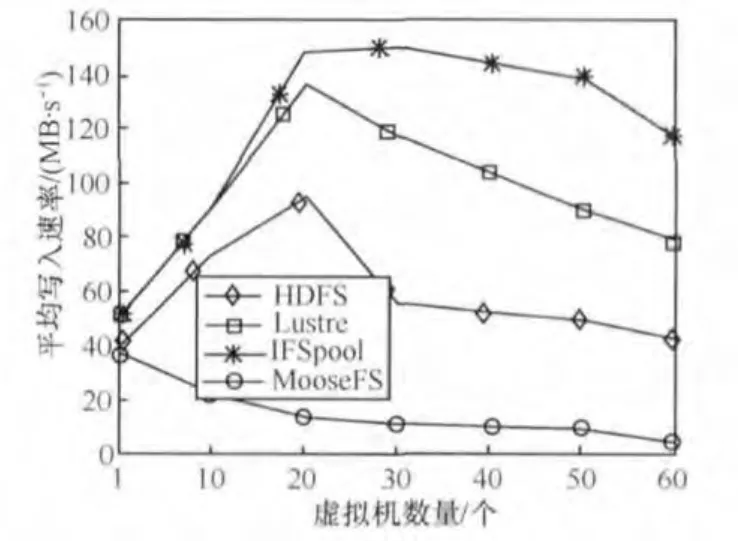
图7 平均写入速率比较
笔者还测试了不同记录大小的I/O性能。在测试环境中有30个虚拟机同时针对IFSpool作随机读写操作。从图8和图9看到存储适配器能提高读写速率,尤其是小的记录,这也证实了存储适配器能提高数据访问速度并行度和有效地减少通信开销。
在图10和图11中,比较了同时启动或关闭特定数量虚拟机所消耗的时间。在实验中,每台虚拟机配置2个VCPU、1 024 MB内存、20 GB磁盘映像和Windows XP,所有虚拟机都是VHD格式,并且都运行在同一台主机服务器上。当登录界面出现时,虚拟机启动完成;当电源关闭时,虚拟机关闭完成。
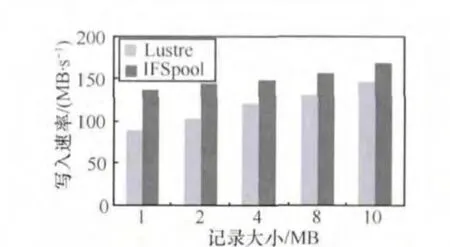
图8 不同大小记录的写入速率比较

图9 不同大小记录的读取速率比较

图10 多台虚拟机同时启动的时间消耗
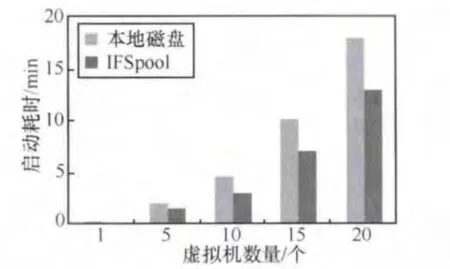
图11 多台虚拟机同时关闭的时间消耗
从图10和图11可以看到当启动或关闭多台虚拟机时,IFSpool能比本地磁盘消耗更少的时间,这是由于IFSpool存在并行访问和缓存机制。
5 结束语
镜像文件存储是云计算的关键部分。如果实现一个高容量、高可伸缩性和高吞吐量的镜像文件存储系统,可以很容易地在不同主机或不同数据中心之间迁移虚拟机以达到负载平衡和节省电能,同时可以通过高I/O吞吐量和高容量存储池来解决启动风暴。在本文中,笔者设计并实现一个基于Lustre的存储系统IFSpool,它可以在无须中断数据访问的前提下,通过添加存储设备来增加存储容量和I/O带宽。IFSpool结合队列和缓存机制,并通过协调数据访问顺序提高I/O吞吐率和减轻启动风暴。实验结果也表明IFSpool是有效的镜像文件存储系统。
此外,当有成千上万的用户时,数据中心会存在大量的冗余数据。未来的工作,将在IFSpool中增加对重复数据删除的支持。
1 Foster I,Zhao Y,Raicu I,et al.Cloud computing and grid computing 360-degree compared.Proceedings of IEEE Grid Computing Environments Workshop,Austin,TX,USA,2008:1~10
2 Wood T,Shenoy P,Venkataramaniand A,et al.Black-box and gray-box strategies for virtual machine migration.Proceedings of the 4th USENIX Conference on Networked Systems Design&Implementation,Cambridge,MA,2007:1~14
3 Shafer J.I/O virtualization bottlenecks in cloud computing today.Proceedings of the 2nd Conference on I/O Virtualization,USENIX Association Berkeley,CA,USA,2010
4 Hansen J G,Jul E.Lithium:virtual machine storage for the cloud.Proceedings of the 1st ACM Symposium on Cloud Computing,New York,NY,USA,2010:15~26
5 Wang F,Oral S,Shipman G,et al.Understanding Lustre file system internals.Technical Report ORNL/TM-2009/117,Oak Ridge National Lab,National Center for Computational Sciences,2009
6 Mell P,Grance T.NIST definition of cloud computing.National Institute of Standards and Technology,2011
7 Buyya R,Broberg J,Goscinski A.Cloud Computing:Principles and Paradigms.New York:Wiley Press,2011
8 Meyer D,Aggarwal G,Cully B,et al.Parallax:virtual disks for virtual machines.Proceedings of the ACM SIGOPS/EuroSys European Conference on Computer Systems,Glasgow,Scotland,2008
9 Liao X F,Li H,Jin H,et al.Vmstore:distributed storage system for multiple virtual machines.Science China Information Sciences,2011,54(6):1104~1118
10 Dickens P M,Logan J.A high performance implementation of MPI-IO for a Lustre file system environment.Concurrency and Computation:Practice and Experience,2010
11 C asale G,Kraft S,Krishnamurthy D.A model of storage I/O performance interference in virtualized systems.Proceedings of the 1st Int Workshop on Data Center Performance,Minneapolis,MN,2011
12 Vaghani S B.Virtual machine file system.ACM SIGOPS Operating Systems Review,2010,44(4):57~70
13 Rajagopalan S,Cully B,O’Connor R,et al.SecondSite:Disaster Tolerance as a Service.ACM 978-1-4503-1175-5/12/03,London,England,2012
14 Openstack image-service.http://www.openstack.org/projects/imageservice/
15 Gens F.Defining“Cloud Services”and“Cloud computing”.http://www.fiercetelecom.com/story/defining-cloud-computing-servicesbenefits-and-caveats/2012-03-12,2012
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
电脑爱好者(2018年12期)2018-06-26 16:24:30
电子测试(2017年11期)2017-12-15 08:57:45
水利技术监督(2017年3期)2017-06-09 06:55:34
科技创新与应用(2017年3期)2017-02-18 16:12:50
地矿测绘(2015年3期)2015-12-22 06:27:26
轻兵器(2015年20期)2015-09-10 07:22:44
中国教育信息化(2015年12期)2015-08-24 07:58:36
电脑迷(2015年9期)2015-05-30 22:08:35
