
基于FCM与KKT条件的增量学习方法
2014-01-29 07:19张国兵郎荣玲
电子设计工程 2014年10期
张国兵,郎荣玲
(北京航空航天大学 电子信息工程学院,北京 100191)
增量学习方法(incremental learning approach)是一种得到广泛应用的智能化数据挖掘与知识学习方法。其思想是当样本逐步积累时,能够不断地吸收新的知识,从而使精度也随之提高[1]。在学习过程中,大部分方法都是通过相应的手段和算法,丢弃大量无效的样本点,减少算法的计算时间和样本的存储空间,在保证机器学习的效率和精度的条件下,解决了大量样本训练时间长和存储空间不足,以及在线实时增量学习的问题[2]。
在丢弃大量无效样本点过程中,不同算法采用的方式和方法各不相同,目的都是为了最大限度地减少参与训练的样本数量和算法的计算量。但是删减无关样本点稍有不当,就会影响到机器学习的效率和精度,例如Syed等提出的增量学习算法,增量训练由支持向量样本和新样本组成,再训练只需要进行一次即可完成,所有的非支持向量样本点都被抛弃,这种方法极有可能丢失原有的信息[3];郭雪松提出的基于超球结构的支持向量机增量学习算法,利用超球结构,完成对增量学习中训练样本的选取,进而完成分类器的重构,但是该方法的参数值很难确定,导致样本选取覆盖面过大,就会失去原有增量学习的意义,覆盖范围过小,又会遗漏可能成为支持向量的样本点[4]。还有其他学者提出的增量学习方法,都是从不同角度对历史样本点或者新增量样本点进行筛选,提高增量学习的效率和精度。因此,选择合适的样本筛选方法对增量学习起着至关重要的作用。
文中提出了利用模糊聚类方法对历史样本集合进行筛选,最大限度地保留原有的信息量,丢弃无效的样本点[5-6];并利用 KKT(Karush-Kuhn-Tucker)条件对新增样本集进行筛选,保留违背KKT条件的样本点,并将它们筛选后的样本集结合进行增量学习,以便提高机器学习的效率和精度。
1 模糊聚类方法
1.1 FCM
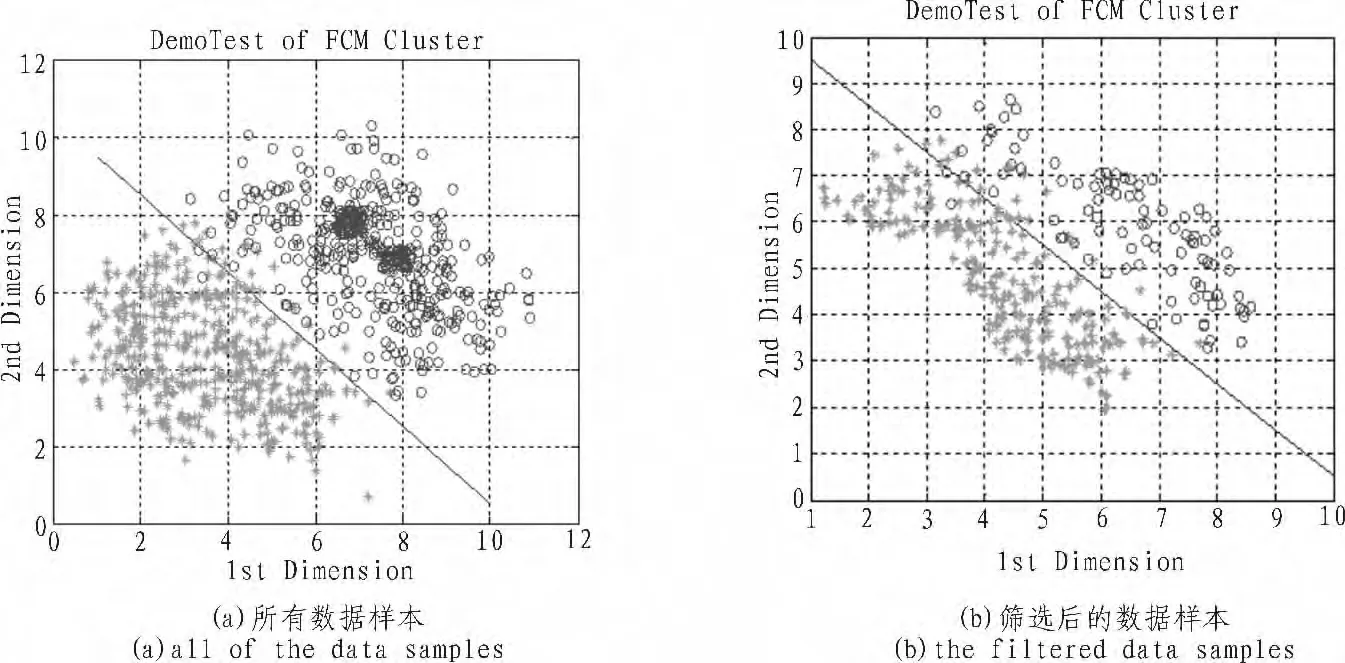
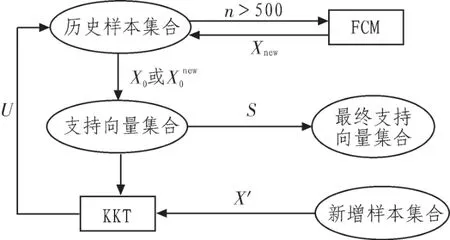
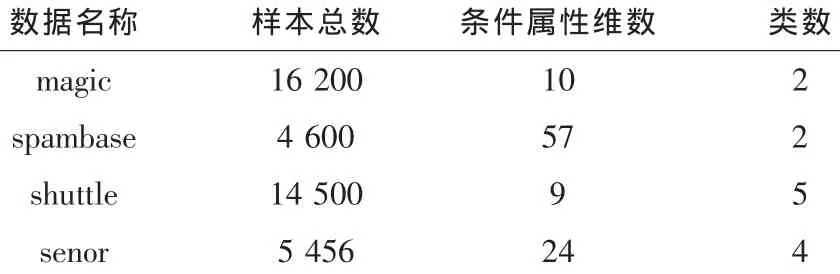
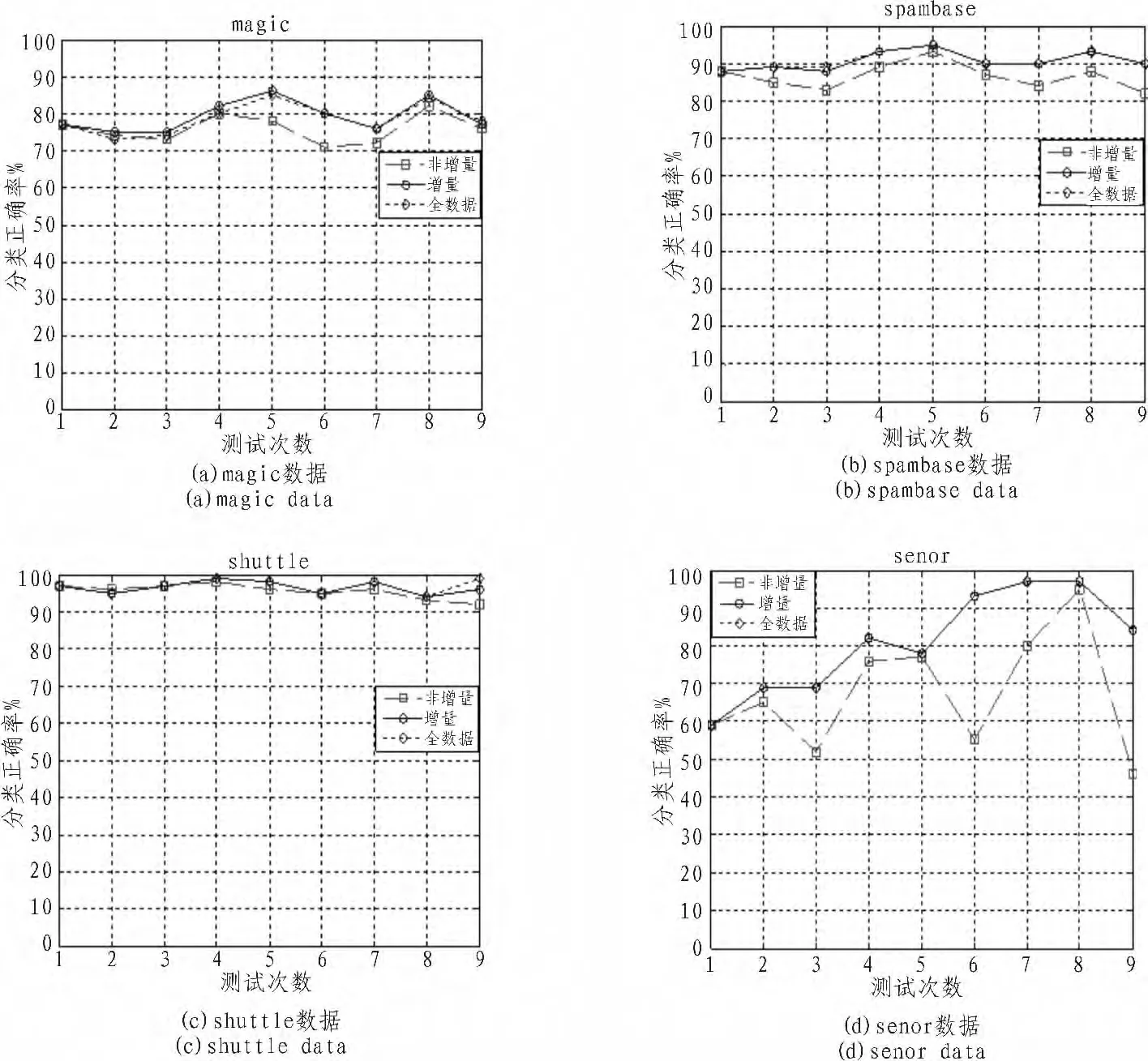
FCM算法的思想就是使得被划分到同一簇的样本间距离最小,而不同簇之间的距离最大。设X={x1,x2,…xn},xi∈Rh,其中xi为第i个样本,h为样本的特征维数。FCM是把X={x1,x2,…xn}分为 L(2 FCM在聚类过程中要求所聚得的簇能使得指示性价值函数达到最小值。当选择欧几里德距离度量两点之间的距离时示性函数定义为: 其中dij=‖ci-xj‖为第i个簇中心与样本xj间的欧氏距离,m∈[1,∞)是一个加权指数,通常取m=2。 假设样本[9]集合为 X0={x1,x2,…,xn},训练得到的支持向量集合为S0。利用FCM对样本数据集X0进行聚类时,可以得到L个数据簇,一般L≈2*SV/3比较合适。其中包括混合类簇(含有不同类样本点)和单一类簇(只含有同一类样本点)。首先将混合类簇的样本点保留下来,而单一类簇的样本点需要与支持向量集合S0中的样本点进行比较,如果单一类簇中含有支持向量样本点,则该簇中的样本点将被保留,否则该簇中的所有样本点都丢弃。最后将保留的样本集合作为增量学习训练集合的一部分。其样本筛选过程如图1所示:图(a)中表示的是利用random函数仿真的一个两维数据样本的分布图,共分为两类,作为筛选前的数据;图(b)中表示的是筛选后的数据分布图。可见,利用FCM进行样本筛选后,明显有大量无效的样本被淘汰掉,并且能够保留可能成为支持向量的样本点。 图1 数据过滤示意图Fig.1 Data filtering schemes KKT最优化条件是Karush[1939]以及Kuhn和Tucker[1951]先后独立发表出来的,这组最优化条件在Kuhn和Tucker发表之后才逐渐受到重视,KTT条件是指在满足一些有规则的条件下,一个非线性规划(Nonlinear Programming)问题能有最优化解法的一个必要和充分条件。可以得到支持向量机的KKT条件表达式如下: 根据KKT条件,可以将训练样本点划分为3部分:位于正确划分区间隔边界上的样本点集合S(0≤αi≤C);在间隔内的错误支持向量集合E(gi<0);其余的样本点被划分到一个集合 R(gi>0)。 假设历史样本集合为 X0={(x1,y1),(xi,yi),…,(xn,yn)},xi∈Rh,yi∈Y,历史样本集训练得到的支持向量集合为 S0,新增样本集合为 X′={(x1,y1),(xl,yl),…,(xm,ym)},xl∈Rh,yl∈Y,其中h为样本的特征维数,Y为样本的类数。新增样本集中违背KKT条件的样本集合记为U,历史样本集合X0经FCM筛选后的样本集合记为Xnew0,增量学习后的支持向量集合为S。 增量学习实现过程如图2所示。 图2 增量学习实现过程Fig.2 Incremental learning implementation process 根据增量学习实现的过程,可以推导出该增量学习方法的具体步骤: 1)确保X0≠Φ,利用SMO算法对历史样本集合X0进行训练得到支持向量集合S0和KKT条件; 2)利用KKT条件对新增样本集合X′进行判断,将违背KKT条件的样本集合U并入到集合X0; 3)对集合 X0中的样本总数n进行判断,如果n>500(值的大小根据实际需求设置),就利用FCM算法对集合X0进行样本筛选,去掉大量无关的样本点,形成样本集合Xnew0,否则直接进行下一步骤; 4)对集合X0或者Xnew0进行支持向量机训练得到支持向量集合S,若U=0,说明新增样本集中没有新的信息,不需要增量学习,将S0作为最终的支持向量集合,否则S作为最终的支持向量集合; 5)只要有新的样本集增加,就反复重复2)至4)步骤,完成每一阶段的增量学习。 从理论上分析增量学习的结果都会优于非增量训练,而劣于全数据的训练。为了验证模糊聚类与KKT条件结合的增量学习方法的有效性和准确度,本部分从UCI标准数据库中选取4组标准数据进行实验,并且与非增量、全数据训练进行比较分,分析本文的增量学习方法的优势。实验条件为:1:1:1,非增量的训练样本不增加,全数据的训练样本每次增加100。选取的4组实验数据如表1所示,测试结果图3所示。 表1 数据类型Tab.1 Data classes 从实验结果分析,从图3中可以看出增量学习结果具有分类精度较高、稳定性好;与全数据训练的分类准确度相比,基本上与全数据训练的分类准确度相等,并且在magic数据中甚至有的测试超过了全数据训练的分类准确度,在训练时间上明显少于全数据的训练时间。因此,模糊聚类与KKT条件结合的增量学习方法具有很好的增量学习效果。 图3 增量学习的结果Fig.3 Incremental learning results 文中提出的增量学习方法从历史样本和新增样本两个部分对参训样本数据进行筛选,提高了训练速度和节省了存储空间。该算法与增量学习结果的上下边界进行了比较,实验结果证明增量学习的结果几乎与上边界全数据训练的结果拟合,因此模糊聚类与KKT条件结合的增量学习方法是一种非常有效的增量学习方法。 [1]曹杰,刘志镜.基于支持向量机的增量学习算法[J].计算机应用研究,2007(8):50-52.CAO Jie,LIU Zhi-jing.Incremental learning algorithm based on SVM[J].Application Research of Computers,2007(8):50-52. [2]冯国瑜,肖怀铁.一种适于在线学习的增量支持向量数据描述方法[J].信号处理,2012(2):186-192.FENG Guo-yu,XIAO Huai-tie.An incrementalsupport vector data description method for online learning[J].Signal Processing,2012(2):186-192. [3]唐小力,吕宏伟.SVM增量学习算法研究[J].电脑知识与技术,2005(12):160-162.TANG Xiao-li,LU Hong-wei.The research of SVM incremental learning[J].Computer Knowledge and Technology,2005(12):160-162. [4]郭雪松,孙林岩,徐晟.基于超球结构的支持向量机增量学习算法[J].运筹与管理,2007(8):45-49.GUO Xue-song,SUN Lin-yan,XU Sheng.Incremental SVM learning algorithm based on hyper-sphere structure[J].Operations Research and Management Science,2007(8):45-49. [5]郑智洵,杨建刚.大规模训练数据的支持向量机学习新方法[J].计算机工程与设计,2006,27(13):2425-2431.ZHENG Zhi-xun,YANG Jian-gang.New method of SVM learning with large scale training data[J].Computer Engineering and Design,2006,27(13):2425-2431. [6]朱方,顾军华,杨欣伟,等.一种新的支持向量机大规模训练样本集缩减策略[J].计算机应用,2009,29(10):2736-2740.ZHU Fang,GU Jun-hua,YANG Xin-wei,et al.New reduction strategy of large-scale training sample set for SVM[J].Journal of Computer Applications,2009,29(10):2736-2740.

1.2 样本筛选
2 KKT条件
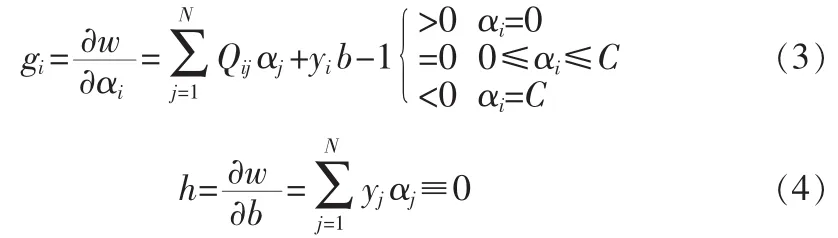
3 增量学习过程
4 实验分析
5 结 论
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
科技创新与应用(2020年6期)2020-02-29
中学生数理化·中考版(2019年9期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
电信科学(2016年9期)2016-06-15
