
一种新的数字家庭个性化服务推荐方法
2013-12-23 06:27:20陈冬林纪巧芬
武汉理工大学学报(信息与管理工程版) 2013年3期
陈冬林,纪巧芬,陈 玲,吴 钟
(武汉理工大学 电子商务与智能服务研究中心,湖北武汉430070)
随着数字家庭业务的不断扩展,用户不得不面对信息过载。若不能根据用户的偏好信息及使用服务的历史记录对资源进行适当的推荐,则会降低用户对服务的兴趣。于是基于用户兴趣偏好的个性化推荐系统应运而生,根据用户的兴趣进行个性化推荐,可以提高数字家庭系统用户的满意度和服务的质量。
基于协同过滤的推荐不需要分析对象的属性,可以为用户发现新的兴趣。但随着应用的逐渐深入,一些问题也暴露出来[1-2]。目前的协同过滤技术主要以用户的项目评分作为数据源,但由于评分数据需要用户的额外参与,如果大量用户不提供评价信息将会导致评分矩阵极端稀疏,很难找到与当前用户兴趣相似的用户集,推荐结果难以令人满意[3]。有些则以代表使用与否的0-1值为数据源,如Rij值为1 表示第i 个用户使用了第j 个资源,取值为0 则相反。这种方法虽然考虑了用户的历史行为,但资源的使用与否并不能准确反映用户兴趣。另外,传统协同过滤算法在计算邻居用户时,将用户未评分的项目填充为0,这种方法虽然有效地提高了计算性能,但在项目数量巨大且用户评分数据极端稀疏的情况下,这种填充方法的准确度很低[4]。如果这些问题得不到解决,则基于协同过滤的推荐系统不可能取得好的效果。
针对目前基于协同过滤推荐系统在数据源方面存在的稀疏性和片面性的问题,笔者提出了基于用户消费行为的协同过滤推荐方法。用户使用资源的具体时间、总次数和时间长度在一定程度上反映了用户的兴趣。不同用户群体使用系统的时间不同,而相同时间使用系统的用户偏好则具有一定的相似性。播放次数越多、使用资源时间越长表示用户越感兴趣。基于用户消费行为的协同过滤推荐方法无须用户的额外参与,在一定程度上可实现系统的能动性,并且能动态反映用户偏好的变化,从而避免利用用户评分/评价数据或购买/未购买数据进行推荐的片面性。该方法可为数字家庭用户提供高质量的推荐服务,从而提高用户对数字家庭系统的满意度和忠诚度[5]。
1 基于用户消费行为的协同过滤推荐原理
1.1 推荐原理
用户消费行为数据在一定程度上反映了用户对已使用服务的偏好程度,可以利用相关信息分析当前用户的邻居用户集。推荐的服务资源应尽可能是用户喜欢的,这就涉及到资源的时间有效性。将使用时间引入到计算邻居用户过程中,实现更准确的推荐[6]。基于用户消费行为的协同过滤推荐系统原理如图1 所示,从行为数据库中提取用户消费行为数据,规范处理后建立用户兴趣模型,利用得到的模型进行邻居用户查询,根据最近邻居用户已使用的资源向当前用户推荐。

图1 基于用户消费行为的协同过滤推荐原理
1.2 推荐过程
1.2.1 用户兴趣模型表示
用户兴趣表示是指收集用户的相关信息,并不断根据用户变化的需求进行自动更新[7]。用户兴趣不是简单基于统计的用户低端数据分析,而是将用户在数字家庭系统中消费行为进行深层次的挖掘。用户的消费行为数据反映了用户兴趣取向,用户对于感兴趣的资源会让系统执行相应的命令,这些数据具有很重要的分析价值。
通过构建一个三维用户兴趣模型表示用户的兴趣度,统计分析用户的行为并进行用户个人兴趣构建,以此为基础为用户提供最满意的推荐[8]。所研究的用户行为不只是用户的单次行为,而是将用户的历史整体行为作为分析研究的对象。用户兴趣度(UID)可以定义为一个三元组:UID= <T,N,L >,其中,T 为用户收看某个资源的时间,即对具体时间根据划分的时间段进行量化形成指标;N 为使用资源的总次数;L 为使用资源的总时间。其主要从用户对某个资源的收看时间、使用次数和使用时长来进行判断,以保证得到的结果是最接近用户兴趣的三维模型。
行为数据库中的3 个指标反映用户兴趣基于以下3 个假设:①在相近的时间看电视的用户具有相同兴趣的可能性要高于不同时间段的用户;②用户对收看次数多的资源的兴趣高于收看次数少的资源;③总的收看时间长的用户表示用户对该类资源比较偏好[9]。
从行为数据库中很容易获得m 个用户对n个资源项的TNL 指标值,及用户收看资源的具体时间、收看次数、时间长度,可以获得用户-资源项TNL 指标矩阵,如表1 所示。

表1 用户-资源项TNL 指标矩阵
为了消除由于各项指标量纲的不同所带来的影响[10],在分析之前需要对评价指标作量化处理,即指标数据的规范化。
对于具体时间指标T,具体时间根据表1 划分的时间段进行赋值,如12:30 属于白天工作时间,赋值时间为1;对于使用次数指标N,根据式(1)计算用户不同时间段使用资源的累计次数,如看了两集电视剧,则累计次数为2;对于时间长度指标L,根据式(2)计算用户使用某个资源与使用所有资源总时间的比例。

式中:ITNLij为第i 个用户对第j 个资源的综合指标值;T′ij,N′ij,L′ij分别为经过规范化的第i 个用户对第j 个资源的TNL 指标值;wT,wN,wL为TNL指标的权重系数,分别是20%,30%和50%。
不同指标在不同程度上反映用户的兴趣度,其中具体的使用时间影响最小[11],使用次数也只能在从一方面上说明用户感兴趣,最重要的是使用资源的总时间,如果不是用户感兴趣的资源,用户一般不可能花费较长时间使用。
通过规范化可以获得用户-资源项TNL 指标矩阵,如表2 所示。

表2 用户-资源项ITNL 指标矩阵
1.2.2 计算相似度
由于相关相似性是基于用户共同评分的项目进行计算,因此,选用相关相似性计算邻居用户[12]。相关相似性度量在共同评分项目较多的情况下较为准确,若在共同评分项目较少时,则偏差比较大。
设经用户i 和用户j 共同评分的项目集合用Iij表示,则用户i 与用户j 之间的相似性sim(i,j)通过Pearson 相关系数度量[13]:
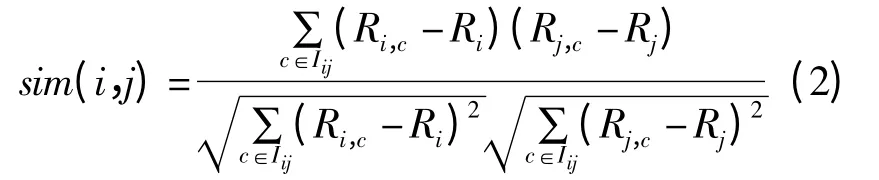
式中:Ri,c为客户i 对项目c 的评分;Ri和Rj分别为客户i 和客户j 对项目的平均评分。
1.2.3 产生推荐列表
通过相似性度量方法可得到目标用户的最近邻居,接着需要产生相应的推荐。设用户u 的最近邻居集合用NBSu 表示,则用户u 对项目i 的预测评分Pu,i可以通过用户u 对最近邻居集合NBSu 中项目的评分得到,计算方法如下[14]:

式中:sim(u,n)为用户u 与用户n 之间的相似性;Rn,i为用户n 对项目i 的评分;Ru和Rn分别为用户u 和用户n 对项目的平均评分。
2 用户消费行为的兴趣模型与数据分析
2.1 使用资源的具体时间
不同用户群体使用电视系统的时间不同,如儿童群体只有在睡醒后才会收看视频,学生群体只有在放学后才有时间使用数字家庭。根据正常的作息把一天时间分为4 个时间段,如表3 所示。

表3 一天中时间段的划分
2.2 使用资源的总次数
使用服务资源的次数越多说明用户对资源越感兴趣,如果不是用户感兴趣的资源,用户在看过之后再看的概率比较小,因此使用的次数不会超过1。

式中:watch(i,u,Ti)为用户u 在Ti时间段使用资源i 的次数;Number 为用户u 使用资源i 的总次数。
2.3 使用资源的总时间
随着用户使用资源时间的累积,用户对资源会越来越了解,使用资源时间越长说明用户对资源越感兴趣。


3 实验结果与分析
数字家庭模拟实验系统中,记录了用户使用服务资源的时间、总次数、总的时间长度。从系统中抽取出用户一定时间内的行为,具体包括用户使用资源的时间、使用某一资源次数、使用某一资源的总时间以及使用电视的总时间。将每个用户的这3 个指标表示为用户-矩阵形式如表4 所示。其中,每个单元格中的第二个数据aij表示用户i 对项目j 的使用次数,如果用户从未使用过某项服务,则记为0,使用的次数越多表示用户对资源的兴趣越大。

表4 用户消费行为数据
使用式(1)对用户行为数据进行规范化处理,规范后的TNL 指标如表5 所示。
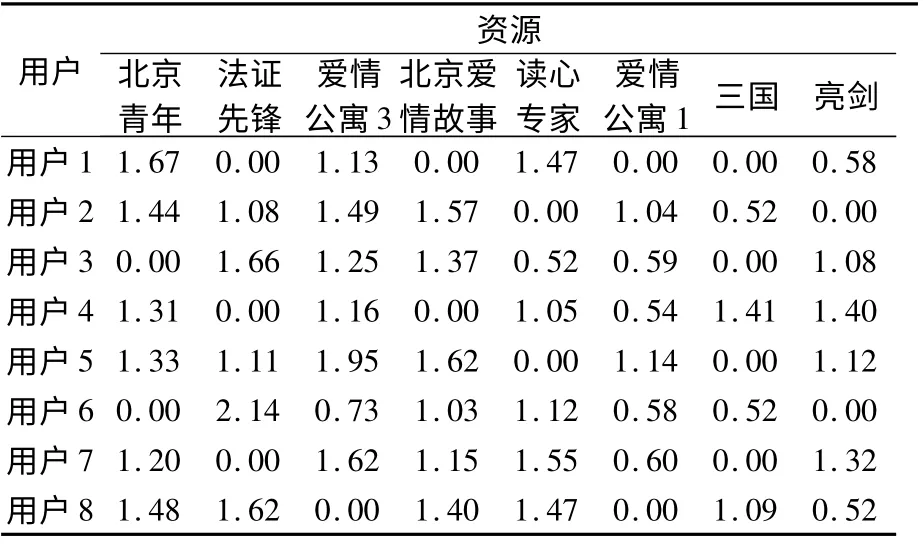
表5 规范后的TNL 指标
在Matlab 软件的命令窗口将用户的行为数据表示为矩阵的形式,其计算邻居用户的界面图如图2 所示。矩阵的行向量表示一个用户的兴趣模型。假设第一个行向量表示要预测其兴趣爱好的当前用户,其他行向量表示当前邻居用户的兴趣模型,用户的数目可以根据需要选择。计算邻居用户时使用误差较小的皮尔逊相关系数公式,测试两个变量之间的相关程度。

图2 Matlab 计算邻居用户的界面图
在Matlab 中使用循环语句计算当前用户与其他每一个用户的相似性,其结果如图3 所示。

图3 Matlab 计算得到的邻居用户的相似度
相关系数是考察两个用户之间的相似程度,相关系数越靠近1,则两者的相关度越强[15]。在图3 中,用户1 与自己的相关系数为1,表示用户与自己的兴趣爱好相同。用户4、7、8 与当前用户的相似度较其他用户更靠近1,表示这3 个用户与当前用户的相似性比较大,是当前用户的邻居用户集。得到用户的邻居用户集后则可以根据式(3)进行推荐。实验表明,与传统协同过滤推荐方法相比,笔者提出的基于用户行为兴趣模型的协同过滤推荐方法具有更高的推荐有效性。
4 结论
个性化服务是一种趋势,应尽可能满足不同背景、不同目的和不同时期的查询请求。若能较好地实现个性化服务资源的推荐,将有效提高用户的满意度,进而扩大数字家庭用户群体。协同过滤算法是实现个性化推荐的代表性算法,现有的协同过滤算法中的稀疏性和不易于用户评分问题,基于用户行为的协同过滤推荐算法可以有效地解决这个问题。在分析现有基于用户评分协同过滤技术存在缺陷的情况下,综合考虑用户使用时间、使用次数和使用长度,建立用户兴趣模型。通过对用户行为数据的选择,进一步改进了传统算法的片面性和局限性,实验结果较好地证明了算法的可行性。
[1] 李聪,梁昌勇,杨善林.电子商务协同过滤稀疏性研究:一个分类视角[J].管理工程学报,2011,25(1):94-100.
[2] 陈冬林,聂规划,刘平峰.基于网页语义相似性的商品隐性评分算法[J]. 系统工程理论与实践,2006,26(11):98-102.
[3] 赵晓煜,黄小原,曹忠鹏.基于客户交易数据的协同过滤推荐方法[J]. 东北大学学报,2009,30(12):1792-1795.
[4] 周军锋,汤显,郭景峰.一种优化的协同过滤推荐算法[J].计算机研究与发展,2004,41(10):1843-1847.
[5] 王茜,王均波.一种改进的协同过滤推荐方法[J].计算机科学,2010,37(6):226-228.
[6] 刘芳先,宋顺林.改进的协同过滤推荐算法[J]. 计算机工程与应用,2011,47(8):72-75.
[7] 曾春,邪春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003,14(5):999-1004.
[8] YEN S J,LEE Y S. An efficient data mining approach for discovering interesting[J].Expert System with Applications,2006,30(3):650-657.
[9] 赵晓煜,黄小原.基于RFM 分析的促销组合策略优化模型[J].中国管理科学,2005,13(1):60-64.
[10]LIU D R,SHIH Y Y. Integrating AHP and data mining for product recommendation based on customer lifetime value[J].The Journal of Systems and Software,2005,77(2):181-191.
[11]张光卫,李德毅,李鹏.基于云模型的协同过滤算法研究[J].软件学报,2007,18(10):2403-2410.
[12]刘枚莲,丛晓琪,杨怀珍.改进邻居集合的个性化推荐算法[J].计算机工程,2009,35(11):196-198.
[13]秦光洁,张颖.基于综合兴趣度的协同过滤推荐算法[J].计算机工程,2009,35(17):81-83.
[14]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[15]TAO Y H,ROSAYEH C C.Simple database marketing tools in customer analysis and retention[J]. International Journal of Information Management,2003,23(2):291-301.
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
商用汽车(2021年4期)2021-10-13 07:16:02
科学大众(2020年23期)2021-01-18 03:09:08
数学物理学报(2020年6期)2021-01-14 01:00:14
汽车观察(2019年2期)2019-03-15 06:00:50
现代园艺(2018年3期)2018-02-10 05:18:17
中学生数理化·中考版(2017年12期)2017-04-18 12:55:03
中国卫生(2016年5期)2016-11-12 13:25:26
中国市场(2016年44期)2016-05-17 05:14:40
现代企业(2015年4期)2015-02-28 18:48:49
